
Vaya a sync.Pool y la mecánica detrás de él
 Navegar:844
Navegar:844
Este es un extracto de la publicación; la publicación completa está disponible aquí: https://victoriametrics.com/blog/go-sync-pool/
Esta publicación es parte de una serie sobre el manejo de la concurrencia en Go:
- Ir a sincronización.Mutex: modo normal y de inanición
- Ir a sincronizar. WaitGroup y el problema de alineación
- Ir a sync.Pool y la mecánica detrás de él (estamos aquí)
- Go sync.Cond, el mecanismo de sincronización más pasado por alto
En el código fuente de VictoriaMetrics, usamos mucho sync.Pool y, sinceramente, se adapta perfectamente a la forma en que manejamos objetos temporales, especialmente búferes de bytes o divisiones.
Se usa comúnmente en la biblioteca estándar. Por ejemplo, en el paquete encoding/json:
package json
var encodeStatePool sync.Pool
// An encodeState encodes JSON into a bytes.Buffer.
type encodeState struct {
bytes.Buffer // accumulated output
ptrLevel uint
ptrSeen map[any]struct{}
}
En este caso, sync.Pool se utiliza para reutilizar objetos *encodeState, que manejan el proceso de codificación JSON en un bytes.Buffer.
En lugar de simplemente tirar estos objetos después de cada uso, lo que solo le daría más trabajo al recolector de basura, los guardamos en un grupo (sync.Pool). La próxima vez que necesitemos algo similar, simplemente lo tomamos del grupo en lugar de crear uno nuevo desde cero.
También encontrará varias instancias de sync.Pool en el paquete net/http, que se utilizan para optimizar las operaciones de E/S:
package http
var (
bufioReaderPool sync.Pool
bufioWriter2kPool sync.Pool
bufioWriter4kPool sync.Pool
)
Cuando el servidor lee los cuerpos de las solicitudes o escribe respuestas, puede extraer rápidamente un lector o escritor preasignado de estos grupos, omitiendo asignaciones adicionales. Además, los 2 grupos de escritores, *bufioWriter2kPool y *bufioWriter4kPool, están configurados para manejar diferentes necesidades de escritura.
func bufioWriterPool(size int) *sync.Pool {
switch size {
case 2
Muy bien, ya basta de introducción.
Hoy profundizaremos en de qué se trata sync.Pool, su definición, cómo se usa, qué sucede bajo el capó y todo lo que quizás quieras saber.
Por cierto, si quieres algo más práctico, hay un buen artículo de nuestros expertos en Go que muestra cómo usamos sync.Pool en VictoriaMetrics: Técnicas de optimización del rendimiento en bases de datos de series temporales: sync.Pool para operaciones vinculadas a CPU
¿Qué es sync.Pool?
En pocas palabras, sync.Pool in Go es un lugar donde puedes guardar objetos temporales para reutilizarlos más adelante.
Pero aquí está la cuestión: no controlas cuántos objetos permanecen en la piscina, y cualquier cosa que coloques allí se puede retirar en cualquier momento, sin previo aviso y sabrás por qué cuando leas la última sección.
Lo bueno es que el grupo está diseñado para ser seguro para subprocesos, por lo que varias gorutinas pueden acceder a él simultáneamente. No es una gran sorpresa, considerando que es parte del paquete de sincronización.
"¿Pero por qué nos molestamos en reutilizar objetos?"
Cuando tienes muchas rutinas ejecutándose a la vez, a menudo necesitan objetos similares. Imagínese ejecutar go f() varias veces al mismo tiempo.
Si cada gorutina crea sus propios objetos, el uso de memoria puede aumentar rápidamente y esto ejerce presión sobre el recolector de basura porque tiene que limpiar todos esos objetos una vez que ya no son necesarios.
Esta situación crea un ciclo en el que la alta concurrencia conduce a un uso elevado de la memoria, lo que luego ralentiza el recolector de basura. sync.Pool está diseñado para ayudar a romper este ciclo.
type Object struct {
Data []byte
}
var pool sync.Pool = sync.Pool{
New: func() any {
return &Object{
Data: make([]byte, 0, 1024),
}
},
}
Para crear un grupo, puede proporcionar una función New() que devuelva un nuevo objeto cuando el grupo esté vacío. Esta función es opcional; si no la proporciona, el grupo simplemente devuelve cero si está vacío.
En el fragmento anterior, el objetivo es reutilizar la instancia de la estructura Object, específicamente el segmento que contiene.
Reutilizar la porción ayuda a reducir el crecimiento innecesario.
Por ejemplo, si el segmento crece a 8192 bytes durante el uso, puede restablecer su longitud a cero antes de volver a colocarlo en el grupo. La matriz subyacente todavía tiene una capacidad de 8192, por lo que la próxima vez que la necesite, esos 8192 bytes estarán listos para ser reutilizados.
func (o *Object) Reset() {
o.Data = o.Data[:0]
}
func main() {
testObject := pool.Get().(*Object)
// do something with testObject
testObject.Reset()
pool.Put(testObject)
}
El flujo es bastante claro: obtienes un objeto del grupo, lo usas, lo reinicias y luego lo vuelves a colocar en el grupo. Se puede restablecer el objeto antes de devolverlo o inmediatamente después de sacarlo del grupo, pero no es obligatorio, es una práctica común.
Si no eres fanático del uso de afirmaciones de tipo pool.Get().(*Object), hay un par de formas de evitarlo:
- Utilice una función dedicada para obtener el objeto del grupo:
func getObjectFromPool() *Object {
obj := pool.Get().(*Object)
return obj
}
- Crea tu propia versión genérica de sync.Pool:
type Pool[T any] struct {
sync.Pool
}
func (p *Pool[T]) Get() T {
return p.Pool.Get().(T)
}
func (p *Pool[T]) Put(x T) {
p.Pool.Put(x)
}
func NewPool[T any](newF func() T) *Pool[T] {
return &Pool[T]{
Pool: sync.Pool{
New: func() interface{} {
return newF()
},
},
}
}
El contenedor genérico le brinda una forma más segura de trabajar con el grupo, evitando aserciones de tipo.
Solo tenga en cuenta que agrega un poco de sobrecarga debido a la capa adicional de dirección indirecta. En la mayoría de los casos, esta sobrecarga es mínima, pero si estás en un entorno altamente sensible a la CPU, es una buena idea ejecutar pruebas comparativas para ver si vale la pena.
Pero espera, hay más.
sync.Pool y trampa de asignación
Si has notado en muchos ejemplos anteriores, incluidos los de la biblioteca estándar, lo que almacenamos en el grupo normalmente no es el objeto en sí, sino un puntero al objeto.
Déjame explicarte por qué con un ejemplo:
var pool = sync.Pool{
New: func() any {
return []byte{}
},
}
func main() {
bytes := pool.Get().([]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
Estamos usando un grupo de []bytes. Generalmente (aunque no siempre), cuando pasa un valor a una interfaz, es posible que el valor se coloque en el montón. Esto también sucede aquí, no solo con los cortes sino con cualquier cosa que pases a pool.Put() que no sea un puntero.
Si verifica utilizando el análisis de escape:
// escape analysis $ go build -gcflags=-m bytes escapes to heap
Ahora, no digo que nuestra variable bytes se mueva al montón, diría "el valor de los bytes se escapa al montón a través de la interfaz".
Para entender realmente por qué sucede esto, necesitaríamos profundizar en cómo funciona el análisis de escape (lo cual podríamos hacer en otro artículo). Sin embargo, si pasamos un puntero a pool.Put(), no hay asignación adicional:
var pool = sync.Pool{
New: func() any {
return new([]byte)
},
}
func main() {
bytes := pool.Get().(*[]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
Ejecute el análisis de escape nuevamente y verá que ya no hay escapes al montón. Si quieres saber más, hay un ejemplo en el código fuente de Go.
sync.Pool Internos
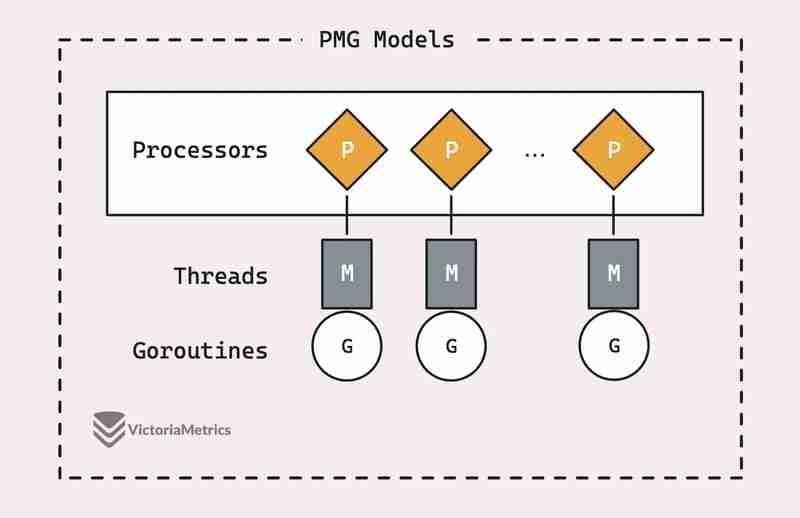
Antes de analizar cómo funciona realmente sync.Pool, vale la pena comprender los conceptos básicos del modelo de programación PMG de Go; esta es realmente la columna vertebral de por qué sync.Pool es tan eficiente.
Hay un buen artículo que desglosa el modelo PMG con algunas imágenes: Modelos PMG en Go
Si hoy te sientes perezoso y buscas un resumen simplificado, te cubro las espaldas:
PMG significa P (pprocesadores lógicos), M (mhilos de máquina) y G (gorrutinas). El punto clave es que cada procesador lógico (P) solo puede tener un subproceso de máquina (M) ejecutándose en cualquier momento. Y para que se ejecute una rutina (G), debe estar adjunta a un hilo (M).
Esto se reduce a 2 puntos clave:
- Si tienes n procesadores lógicos (P), puedes ejecutar hasta n gorutinas en paralelo, siempre y cuando tengas al menos n subprocesos de máquina (M) disponibles.
- En cualquier momento, solo se puede ejecutar una rutina (G) en un solo procesador (P). Entonces, cuando un P1 está ocupado con un G, ningún otro G puede ejecutarse en ese P1 hasta que el G actual se bloquee, finalice o suceda algo más que lo libere.
Pero la cuestión es que una sincronización. El grupo en Go no es solo un grupo grande, en realidad está compuesto por varios grupos 'locales', cada uno de los cuales está vinculado a un contexto de procesador específico, o P, en el que se ejecuta el tiempo de ejecución de Go. gestionando en cualquier momento dado.
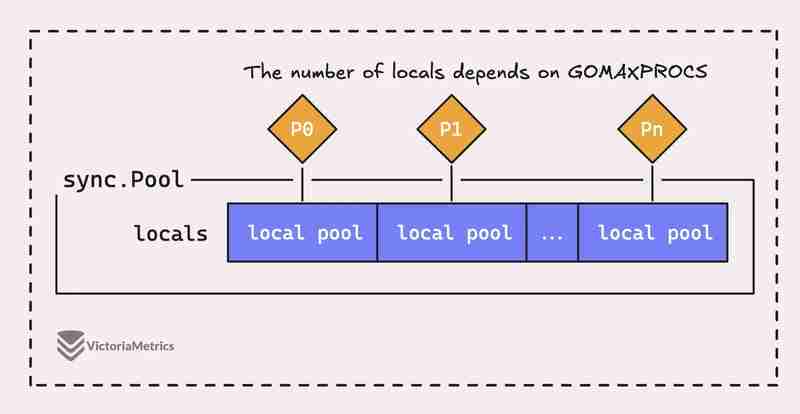
Cuando una gorutina que se ejecuta en un procesador (P) necesita un objeto del grupo, primero verificará su propio grupo P-local antes de buscar en otro lugar.
La publicación completa está disponible aquí: https://victoriametrics.com/blog/go-sync-pool/
-
 ¿Cómo convertir eficientemente las zonas horarias en PHP?Conversión de zona horaria eficiente en php en PHP, el manejo de las zonas horarias puede ser una tarea directa. Esta guía proporcionará un méto...Programación Publicado el 2025-03-28
¿Cómo convertir eficientemente las zonas horarias en PHP?Conversión de zona horaria eficiente en php en PHP, el manejo de las zonas horarias puede ser una tarea directa. Esta guía proporcionará un méto...Programación Publicado el 2025-03-28 -
¿Por qué recibo un error de "no pude encontrar una implementación del patrón de consulta" en mi consulta de Silverlight Linq?Ausencia de implementación del patrón de consulta: Resolver "no se pudo encontrar" errores en una aplicación de Silverlight, un inte...Programación Publicado el 2025-03-28
-
¿Cómo establecer dinámicamente las claves en los objetos JavaScript?cómo crear una clave dinámica para una variable de objeto JavaScript al intentar crear una clave dinámica para un objeto JavaScript, usando esta...Programación Publicado el 2025-03-28
-
Fit de objeto: la cubierta falla en IE y Edge, ¿cómo solucionar?Object-Fit: la portada falla en IE y Edge, ¿cómo solucionar? utilizando objeto-fit: cover; en CSS para mantener la altura de imagen consistent...Programación Publicado el 2025-03-28
-
¿Cómo puedo ejecutar múltiples declaraciones SQL en una sola consulta usando nodo-mysql?múltiple consulta de consulta en nodo-mysql en node.js, la pregunta surge al ejecutar múltiples estaciones sql en una sola consulta utilizando...Programación Publicado el 2025-03-28
-
¿Cómo se extraen un elemento aleatorio de una matriz en PHP?Selección aleatoria de una matriz en php, la obtención de un elemento aleatorio de una matriz se puede lograr con facilidad. Considere la siguie...Programación Publicado el 2025-03-28
-
¿Cómo puede usar los datos de Group by para pivotar en MySQL?pivotando resultados de consulta usando el grupo mySQL mediante en una base de datos relacional, los datos giratorios se refieren al reorganiz...Programación Publicado el 2025-03-28
-
¿Cómo verificar si un objeto tiene un atributo específico en Python?para determinar el atributo de objeto existencia Esta consulta busca un método para verificar la presencia de un atributo específico dentro de...Programación Publicado el 2025-03-28
-
¿Cómo puedo seleccionar programáticamente todo el texto dentro de un DIV en el clic del mouse?seleccionando el texto DIV en el mouse clic pregunta Dado un elemento DIV con contenido de texto, ¿cómo puede el usuario seleccionar programát...Programación Publicado el 2025-03-28
-
¿Cómo manejar la entrada del usuario en el modo exclusivo de pantalla completa de Java?manejo de la entrada del usuario en el modo exclusivo de la pantalla completa en java introducción cuando ejecuta una aplicación Java en mod...Programación Publicado el 2025-03-28
-
¿Por qué el DateTime de PHP :: Modify ('+1 mes') produce resultados inesperados?modificando meses con php datetime: descubrir el comportamiento previsto cuando se trabaja con la clase de datetime de PHP, suma o ritir meses...Programación Publicado el 2025-03-28
-
¿Cómo puede definir variables en plantillas de cuchilla de laravel elegantemente?Definición de variables en plantillas de Blade Laravel con elegancia Comprender cómo asignar variables en plantillas de cuchillas es crucial p...Programación Publicado el 2025-03-28
-
Python Leer el archivo CSV UnicodeDeCodeError Ultimate Solutionunicode decode error en el archivo csv lectura al intentar leer un archivo csv en python usando el modulo CSV incorporado, (unicodeScal No se ...Programación Publicado el 2025-03-28
-
FormaciónLos métodos son fns que se pueden llamar a los objetos Las matrices son objetos, por lo tanto, también tienen métodos en js. Slice (Begi...Programación Publicado el 2025-03-28
-
¿Cómo redirigir múltiples tipos de usuarios (estudiantes, maestros y administradores) a sus respectivas actividades en una aplicación Firebase?rojo: cómo redirigir múltiples tipos de usuarios a las actividades respectivas Comprender el problema en una aplicación de votación basada...Programación Publicado el 2025-03-28















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









