
Cómo utilizar el chat de Nvidia con RTX AI Chatbot en su computadora
 Navegar:799
Navegar:799
Nvidia ha lanzado Chat with RXT, un chatbot de IA que opera en tu PC y ofrece funciones similares a ChatGPT y más. Todo lo que necesitas es una GPU Nvidia RTX y estarás listo para comenzar a usar el nuevo chatbot de IA de Nvidia.
¿Qué es Nvidia Chat con RTX?
Nvidia Chat con RTX es un software de inteligencia artificial que le permite ejecutar un modelo de lenguaje grande (LLM) localmente en su computadora. Entonces, en lugar de conectarse a Internet para usar un chatbot de IA como ChatGPT, puede usar Chat con RTX sin conexión cuando lo desee.
Chat with RTX utiliza TensorRT-LLM, aceleración RTX y un Mistral 7-B LLM cuantificado para proporcionar un rendimiento rápido y respuestas de calidad a la par con otros chatbots de IA en línea. También proporciona generación de recuperación aumentada (RAG), lo que permite que el chatbot lea sus archivos y habilite respuestas personalizadas basadas en los datos que usted proporciona. Esto le permite personalizar el chatbot para brindar una experiencia más personal.
Si quieres probar Nvidia Chat con RTX, aquí te explicamos cómo descargarlo, instalarlo y configurarlo en tu computadora.
Cómo descargar e instalar Chat con RTX

Nvidia ha hecho que ejecutar un LLM localmente en su computadora sea mucho más fácil. Para ejecutar Chat con RTX, solo necesita descargar e instalar la aplicación, tal como lo haría con cualquier otro software. Sin embargo, Chat with RTX tiene algunos requisitos mínimos de especificación para instalar y utilizar correctamente.
GPU RTX serie 30 o serie 40 16 GB de RAM 100 GB de espacio de memoria libre Windows 11Si su PC cumple con los requisitos mínimos del sistema, puede continuar e instalar la aplicación.
Paso 1: Descargue el archivo ZIP Chat with RTX.Descargar: Chat with RTX (Gratis: descarga de 35 GB)Paso 2: Extraiga el archivo ZIP haciendo clic derecho y seleccionando una herramienta de archivo de archivos como 7Zip o haciendo doble clic en el archivo y seleccionando Extraer todo. Paso 3: abra la carpeta extraída y haga doble clic en setup.exe. Siga las instrucciones en pantalla y marque todas las casillas durante el proceso de instalación personalizada. Después de presionar Siguiente, el instalador descargará e instalará LLM y todas las dependencias.
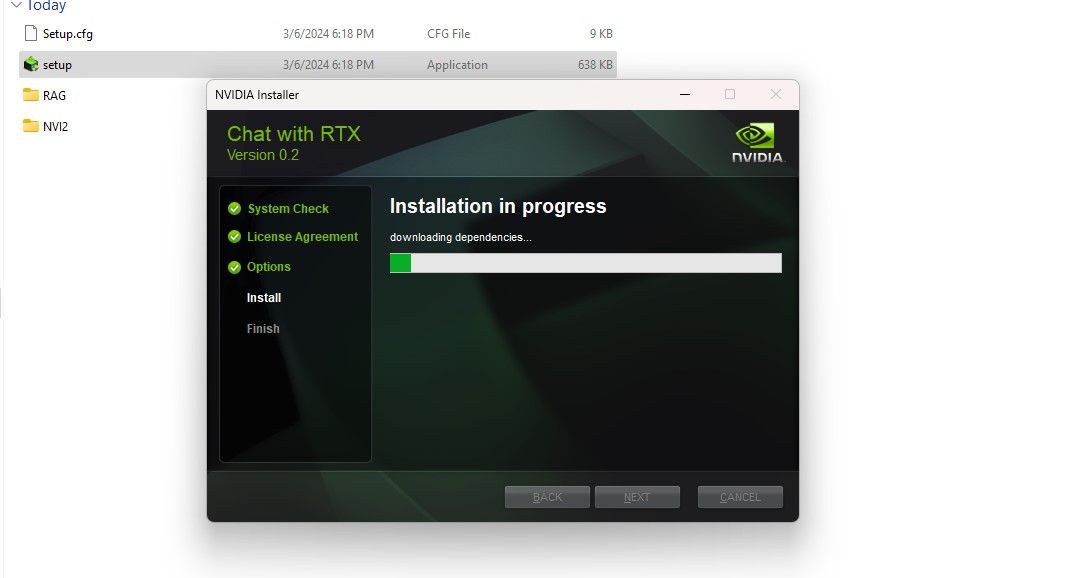
La instalación de Chat with RTX tardará algún tiempo en finalizar, ya que descarga e instala una gran cantidad de datos. Después del proceso de instalación, presione Cerrar y listo. Ahora es el momento de que pruebes la aplicación.
Cómo usar Nvidia Chat con RTX
Aunque puedes usar Chat con RTX como un chatbot de IA en línea normal, te recomiendo encarecidamente que verifiques su funcionalidad RAG, que te permite personalizar su salida según en los archivos a los que da acceso.
Paso 1: Crear carpeta RAG
Para comenzar a usar RAG en Chat con RTX, cree una nueva carpeta para almacenar los archivos que desea que la IA analice.
Después de la creación, coloque sus archivos de datos en la carpeta. Los datos que almacena pueden cubrir muchos temas y tipos de archivos, como documentos, PDF, texto y vídeos. Sin embargo, es posible que desee limitar la cantidad de archivos que coloca en esta carpeta para no afectar el rendimiento. Más datos para buscar significa que Chat with RTX tardará más en devolver respuestas para consultas específicas (pero esto también depende del hardware).
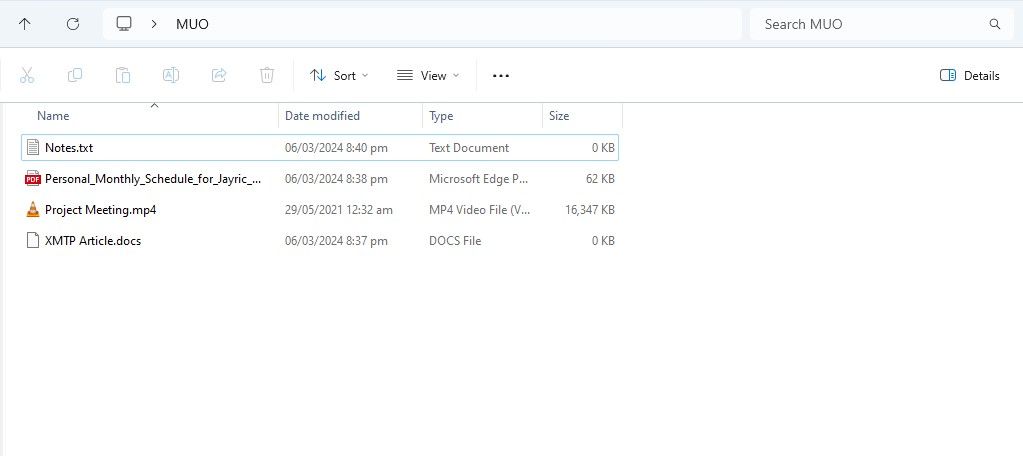
Ahora que tu base de datos está lista, puedes configurar Chat con RTX y comenzar a usarlo para responder tus preguntas y consultas.
Paso 2: Configurar el entorno
Abra Chat con RTX. Debería verse como la imagen de abajo.
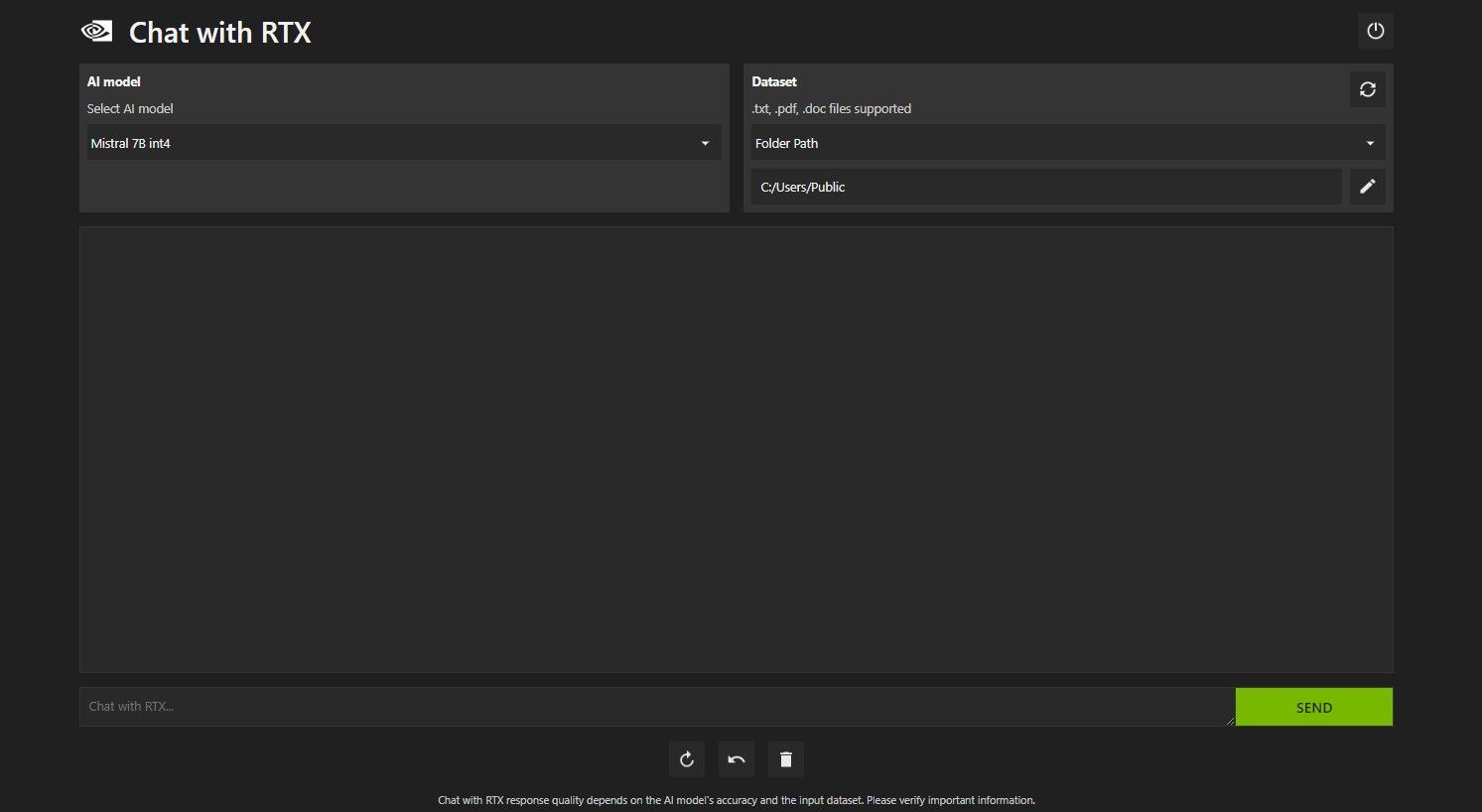
En Conjunto de datos, asegúrese de que la opción Ruta de carpeta esté seleccionada. Ahora haga clic en el ícono de edición a continuación (el ícono del lápiz) y seleccione la carpeta que contiene todos los archivos que desea que Chat with RTX lea. También puede cambiar el modelo de IA si hay otras opciones disponibles (en el momento de escribir este artículo, solo está disponible Mistral 7B).
Ahora estás listo para usar Chat con RTX.
Paso 3: ¡Haga sus preguntas al chat con RTX!
Hay varias formas de consultar Chat con RTX. La primera es utilizarlo como un chatbot de IA normal. Le pregunté a Chat with RTX sobre los beneficios de utilizar un LLM local y quedé satisfecho con su respuesta. No era muy profundo, pero sí lo suficientemente preciso.
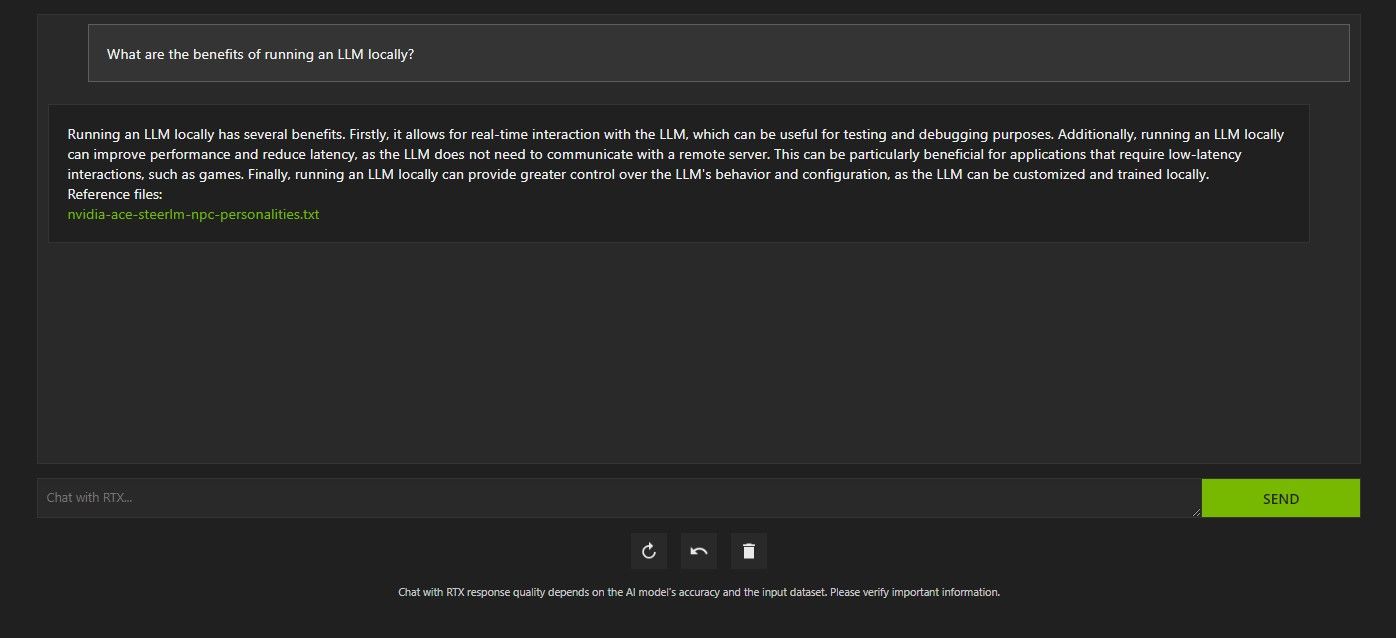
Pero como Chat with RTX es capaz de RAG, también puedes usarlo como un asistente personal de IA.
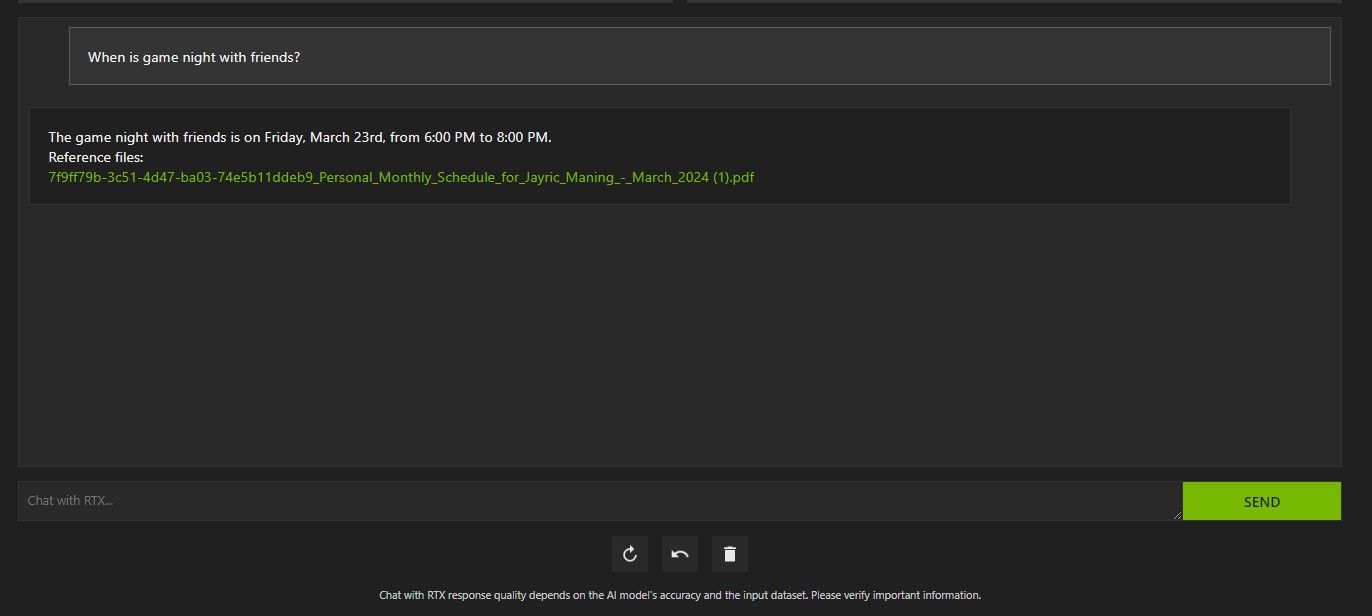
Arriba, utilicé Chat con RTX para preguntar sobre mi agenda. Los datos provienen de un archivo PDF que contiene mi agenda, calendario, eventos, trabajo, etc. En este caso, Chat with RTX extrajo los datos correctos del calendario de los datos; Tendrás que mantener actualizados tus archivos de datos y fechas de calendario para que funciones como esta funcionen correctamente hasta que haya integraciones con otras aplicaciones.
Hay muchas maneras en que puedes utilizar Chat con RAG de RTX para tu ventaja. Por ejemplo, puede usarlo para leer documentos legales y dar un resumen, generar código relevante para el programa que está desarrollando, obtener viñetas destacadas sobre un video que está demasiado ocupado para mirar, ¡y mucho más!
Paso 4: Función adicional
Además de tu carpeta de datos local, puedes usar Chat con RTX para analizar videos de YouTube. Para hacerlo, en Conjunto de datos, cambie la Ruta de la carpeta a la URL de YouTube.
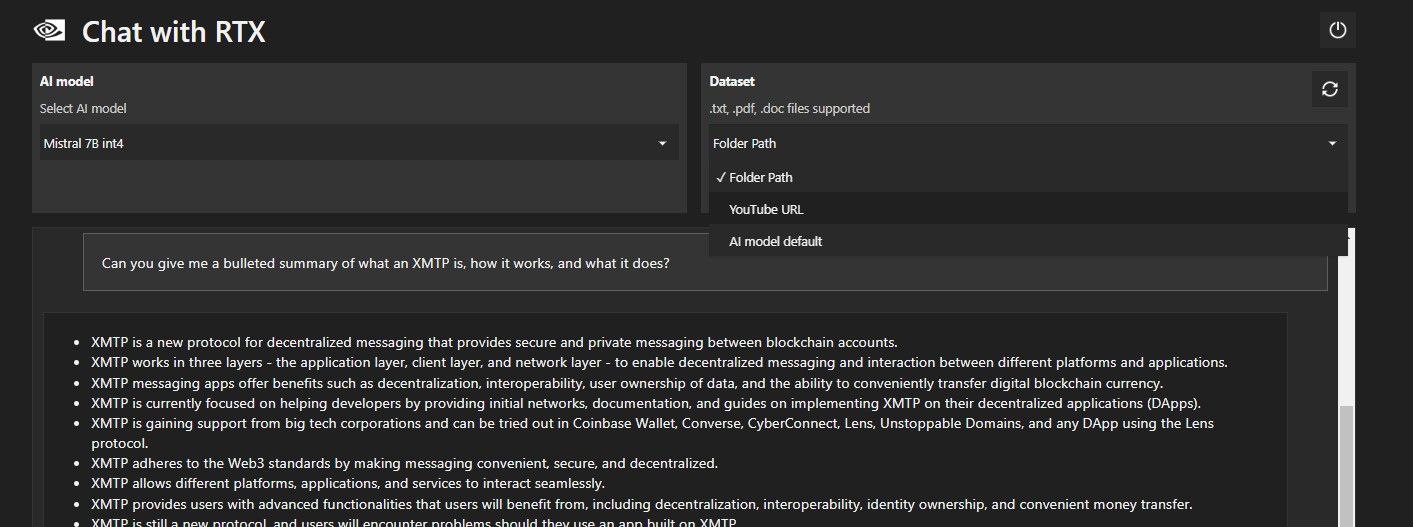
Copie la URL de YouTube que desea analizar y péguela debajo del menú desplegable. ¡Entonces pregunta!
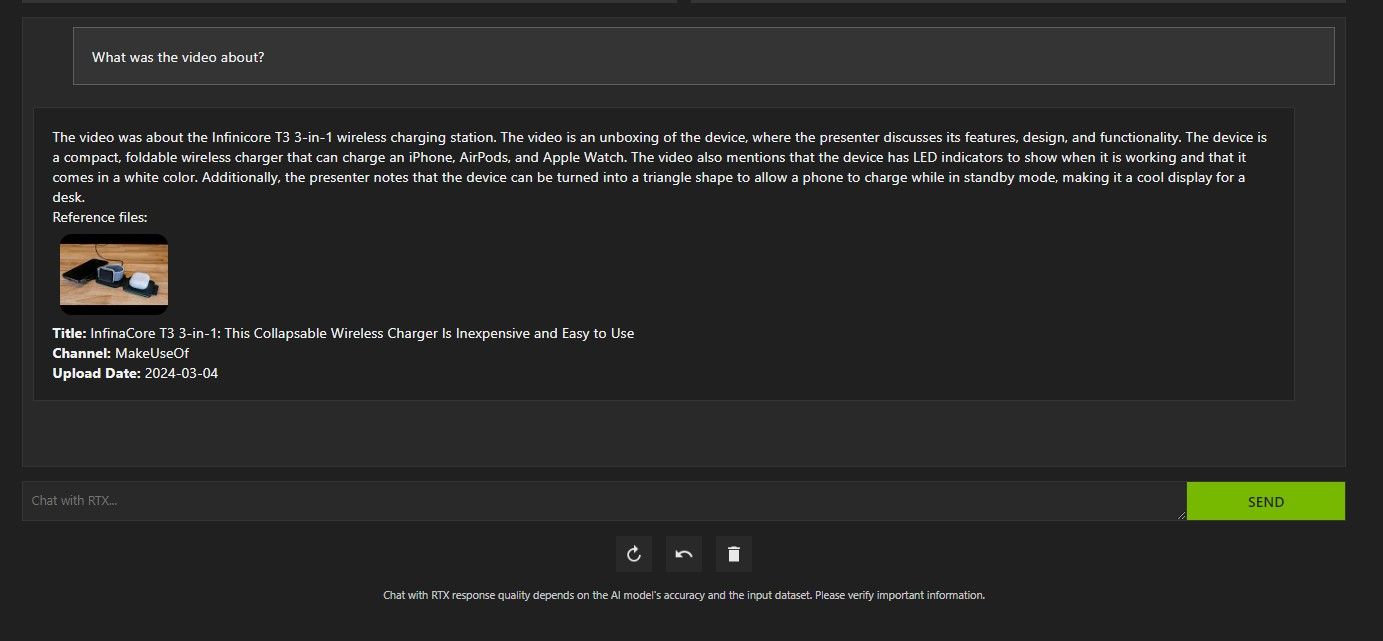
El análisis de video de YouTube de Chat with RTX fue bastante bueno y brindó información precisa, por lo que podría ser útil para investigaciones, análisis rápidos y más.
¿Es bueno el chat de Nvidia con RTX?
ChatGPT proporciona la funcionalidad RAG. Algunos chatbots de IA locales tienen requisitos de sistema significativamente más bajos. Entonces, ¿vale la pena usar Nvidia Chat con RTX?
¡La respuesta es sí! Vale la pena utilizar el chat con RTX a pesar de la competencia.
Uno de los mayores puntos de venta de Nvidia Chat con RTX es su capacidad de usar RAG sin enviar sus archivos a un servidor de terceros. Personalizar los GPT a través de servicios en línea puede exponer sus datos. Pero dado que Chat with RTX se ejecuta localmente y sin conexión a Internet, el uso de RAG en Chat with RTX garantiza que sus datos confidenciales estén seguros y solo sean accesibles en su PC.
En cuanto a otros chatbots de IA que se ejecutan localmente y ejecutan Mistral 7B, Chat with RTX funciona mejor y más rápido. Aunque una gran parte del aumento de rendimiento proviene del uso de GPU de gama alta, el uso de Nvidia TensorRT-LLM y la aceleración RTX hizo que la ejecución de Mistral 7B fuera más rápida en Chat con RTX en comparación con otras formas de ejecutar un LLM optimizado para chat.
Vale la pena señalar que la versión Chat con RTX que estamos usando actualmente es una demostración. Es probable que las versiones posteriores de Chat con RTX estén más optimizadas y ofrezcan mejoras en el rendimiento.
¿Qué pasa si no tengo una GPU RTX serie 30 o 40?
Chatear con RTX es una forma fácil, rápida y segura de ejecutar un LLM localmente sin necesidad de una conexión a Internet. Si también está interesado en ejecutar un LLM o local pero no tiene una GPU RTX serie 30 o 40, puede probar otras formas de ejecutar un LLM localmente. Dos de los más populares serían GPT4ALL y Text Gen WebUI. Pruebe GPT4ALL si desea una experiencia plug-and-play ejecutando localmente un LLM. Pero si tiene una inclinación un poco más técnica, ejecutar LLM a través de Text Gen WebUI le proporcionará un mejor ajuste y flexibilidad.
-
 He abandonado ChatGPT por esta alternativa superior: 3 razones por las cualesVayamos al grano: cambié de ChatGPT a Claude. No es que ChatGPT no sea bueno, lo es. Pero para mis necesidades, Claude tiene algunas ventajas que mar...AI Publicado el 2024-11-02
He abandonado ChatGPT por esta alternativa superior: 3 razones por las cualesVayamos al grano: cambié de ChatGPT a Claude. No es que ChatGPT no sea bueno, lo es. Pero para mis necesidades, Claude tiene algunas ventajas que mar...AI Publicado el 2024-11-02 -
Cómo utilizar ChatGPT de OpenAIAdemás de poder redactar un correo electrónico de trabajo, ChatGPT puede brindarte comentarios sobre tu presentación, sugerir un itinerario para un f...AI Publicado el 2024-11-02
-
GPT-4o lleva GPT-4 a todos, y así es como funcionaEntonces, ¿qué es GPT-4o? ¿Qué es GPT-4o? GPT-4o es el modelo de IA más nuevo del desarrollador de ChatGPT OpenAI, revelado en su evento "Actu...AI Publicado el 2024-11-02
-
Microsoft compra Blizzard, se exploran el arte de la IA y la traducción [Podcast]El podcast de esta semana responde a estas preguntas y reflexiona sobre el impacto de que el gobierno del Reino Unido apruebe la adquisición de Activ...AI Publicado el 2024-11-01
-
Más allá de los LLM: he aquí por qué los modelos de lenguajes pequeños son el futuro de la IALos modelos de lenguajes grandes (LLM) aparecieron en escena con el lanzamiento de ChatGPT de Open AI. Desde entonces, varias empresas también han lan...AI Publicado el 2024-11-01
-
Los 5 mejores generadores de imágenes de IA de código abiertoHay docenas de generadores de texto a imágenes con IA gratuitos y de código abierto disponibles en Internet que se especializan en tipos específicos ...AI Publicado el 2024-09-02
-
OpenAI lanza una tienda GPT personalizada: cómo acceder a ella y usarla ahora mismoOpenAI finalmente ha presentado su muy esperada tienda GPT, que ofrece a los usuarios una selección de GPT personalizados creados por la comunidad Ch...AI Publicado el 2024-09-02
-
¿Qué es Claude 3 y qué puedes hacer con él?Anthropic ha anunciado el lanzamiento de Claude 3, una familia de modelos de IA con el potencial de alterar GPT-4. Tiene un potencial excepcional, pe...AI Publicado el 2024-09-01
-
ChatGPT acaba de agregar una serie de funciones nuevas: estas son las que le interesaránLa actualización ChatGPT de OpenAI a principios de mayo de 2024 fue enorme y aportó un montón de nuevas funciones al chatbot de IA generativa líder e...AI Publicado el 2024-09-01
-
¿Usaste un LLM? Los LAM son los siguientes, pero necesitan trabajoEl auge de los chatbots de IA generativa ha popularizado el término "modelo de lenguaje grande", la tecnología de IA subyacente que trabaja...AI Publicado el 2024-08-31
-
Las 5 mejores formas de utilizar las instrucciones personalizadas de ChatGPTChatGPT tradicionalmente tiene problemas con la personalización y la coherencia de la memoria. Para solucionar este problema, OpenAI introdujo instru...AI Publicado el 2024-08-31
-
La última actualización de ChatGPT le permite crear modelos GPT completamente personalizadosChatGPT, el producto estrella de IA de OpenAI, ha recibido una actualización revolucionaria con un montón de características nuevas. Con varias actua...AI Publicado el 2024-08-29
-
Por qué no deberías confiar en ChatGPT para resumir tu textoHay límites a lo que ChatGPT sabe. Y su programación lo obliga a entregar lo que usted pide, incluso si el resultado es incorrecto. Esto significa qu...AI Publicado el 2024-08-29
-
Copilot vs. Copilot Pro: ¿Cuál es la diferencia? ¿Debería actualizar?Microsoft Copilot ha sido el refugio para aquellos que quieren usar ChatGPT Plus de OpenAI sin desembolsar dinero todos los meses. Y le complacerá s...AI Publicado el 2024-08-28
-
Cómo utilizar el widget ChatGPT en AndroidAntes de continuar, deberás actualizar la aplicación ChatGPT para Android. Si tienes una versión anterior a la 1.2024.052, no podrás crear este práct...AI Publicado el 2024-08-28



![Microsoft compra Blizzard, se exploran el arte de la IA y la traducción [Podcast]](http://www.luping.net/uploads/20240904/172544724466d83c4ca01b0.jpg)











Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









