 Página delantera > AI > Más allá de los LLM: he aquí por qué los modelos de lenguajes pequeños son el futuro de la IA
Página delantera > AI > Más allá de los LLM: he aquí por qué los modelos de lenguajes pequeños son el futuro de la IA
Más allá de los LLM: he aquí por qué los modelos de lenguajes pequeños son el futuro de la IA
 Navegar:708
Navegar:708
Los modelos de lenguajes grandes (LLM) aparecieron en escena con el lanzamiento de ChatGPT de Open AI. Desde entonces, varias empresas también han lanzado sus LLM, pero cada vez más empresas se inclinan por modelos de lenguajes pequeños (SLM).
Los SLM están ganando impulso, pero ¿qué son y en qué se diferencian de los LLM?
¿Qué es un modelo de lenguaje pequeño?
Un modelo de lenguaje pequeño (SLM) es un tipo de modelo de inteligencia artificial con menos parámetros (piense en esto como un valor en el modelo aprendido durante el entrenamiento). Al igual que sus homólogos más grandes, los SLM pueden generar texto y realizar otras tareas. Sin embargo, los SLM utilizan menos conjuntos de datos para el entrenamiento, tienen menos parámetros y requieren menos potencia computacional para entrenarse y ejecutarse.
Los SLM se centran en funcionalidades clave y su tamaño reducido significa que se pueden implementar en diferentes dispositivos, incluidos aquellos que no tienen hardware de alta gama como los dispositivos móviles. Por ejemplo, Nano de Google es un SLM integrado en el dispositivo creado desde cero que se ejecuta en dispositivos móviles. Debido a su pequeño tamaño, Nano puede ejecutarse localmente con o sin conectividad de red, según la empresa.
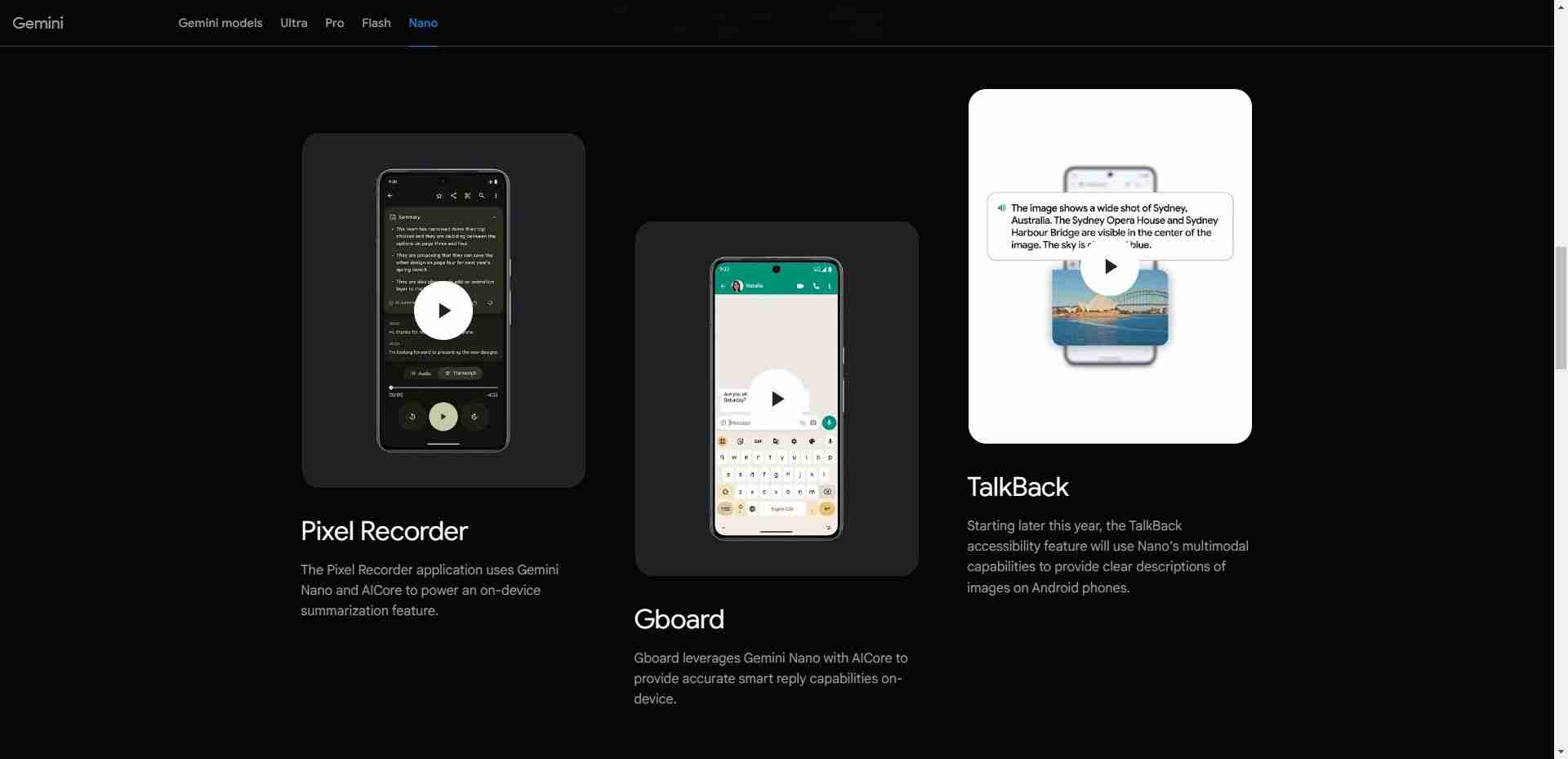
Además de Nano, hay muchos otros SLM de empresas líderes y futuras en el espacio de la IA. Algunos SLM populares incluyen Phi-3 de Microsoft, GPT-4o mini de OpenAI, Claude 3 Haiku de Anthropic, Llama 3 de Meta y Mixtral 8x7B de Mistral AI.
También hay otras opciones disponibles, que podrías pensar que son LLM, pero no lo son. SLM. Esto es especialmente cierto si tenemos en cuenta que la mayoría de las empresas están adoptando el enfoque multimodelo de lanzar más de un modelo lingüístico en su cartera, ofreciendo tanto LLM como SLM. Un ejemplo es GPT-4, que tiene varios modelos, incluidos GPT-4, GPT-4o (Omni) y GPT-4o mini.
Modelos de lenguajes pequeños frente a modelos de lenguajes grandes
Al hablar de SLM, no podemos ignorar a sus grandes contrapartes: los LLM. La diferencia clave entre un SLM y un LLM es el tamaño del modelo, que se mide en términos de parámetros.
Al momento de escribir este artículo, no hay consenso en la industria de la IA sobre la cantidad máxima de parámetros que un modelo no debe exceder para ser considerado un SLM o el número mínimo requerido para ser considerado un LLM. Sin embargo, los SLM suelen tener de millones a unos pocos miles de millones de parámetros, mientras que los LLM tienen más, llegando a billones.
Por ejemplo, GPT-3, que se lanzó en 2020, tiene 175 mil millones de parámetros (y el Se rumorea que el modelo GPT-4 tiene alrededor de 1,76 billones), mientras que los SLM Phi-3-mini, Phi-3-small y Phi-3-medium de Microsoft 2024 miden 3,8, 7 y 14 mil millones de parámetros, respectivamente.
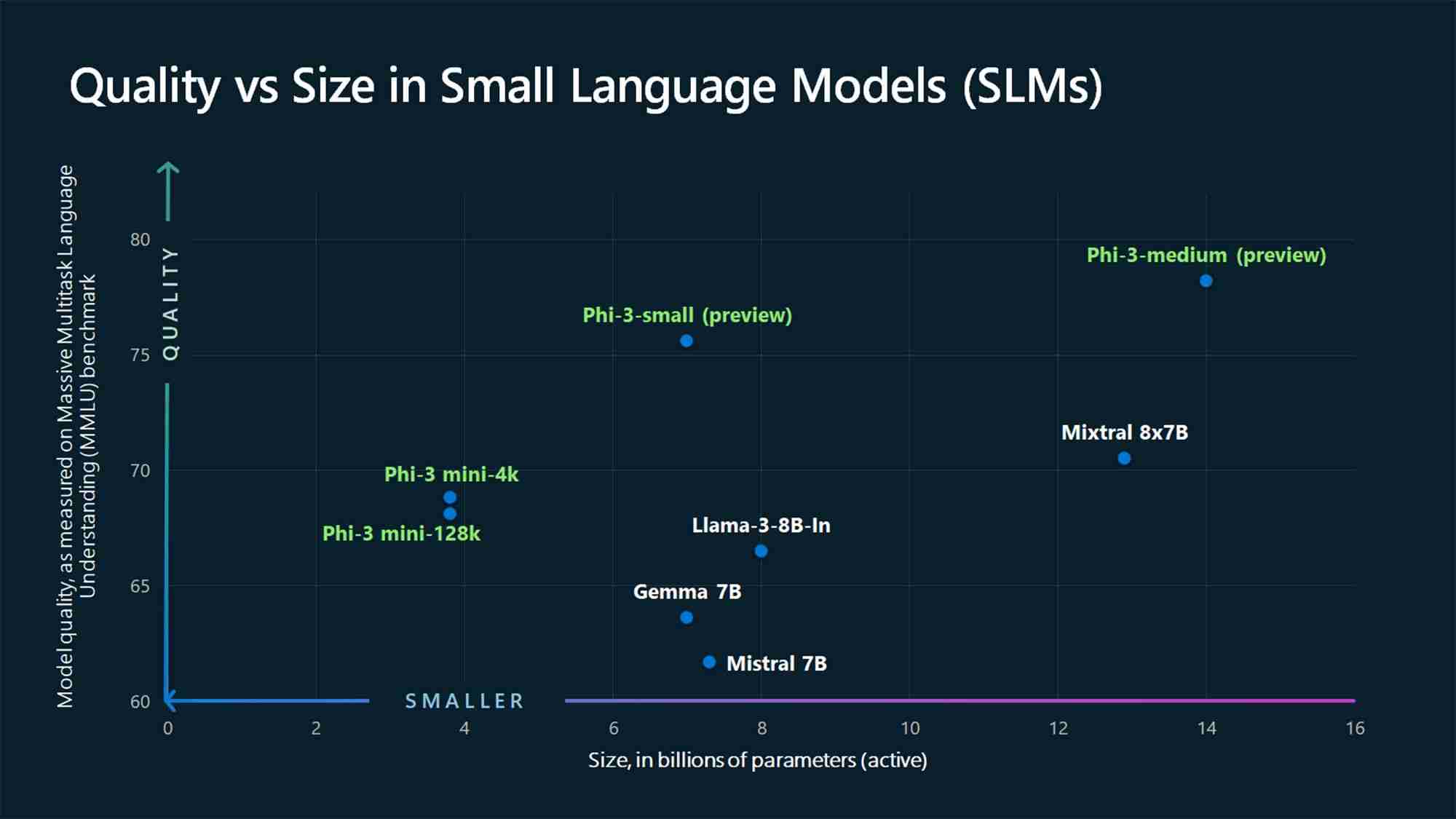
Otro factor diferenciador entre SLM y LLM es la cantidad de datos utilizados para la capacitación. Los SLM se entrenan con cantidades más pequeñas de datos, mientras que los LLM utilizan grandes conjuntos de datos. Esta diferencia también afecta la capacidad del modelo para resolver tareas complejas.
Debido a la gran cantidad de datos utilizados en la capacitación, los LLM son más adecuados para resolver diferentes tipos de tareas complejas que requieren razonamiento avanzado, mientras que los SLM son más adecuados para tareas más simples. tareas. A diferencia de los LLM, los SLM utilizan menos datos de capacitación, pero los datos utilizados deben ser de mayor calidad para lograr muchas de las capacidades que se encuentran en los LLM en un paquete pequeño.
Por qué los modelos de lenguajes pequeños son el futuro
En la mayoría de los casos de uso, los SLM están mejor posicionados para convertirse en los modelos principales utilizados por empresas y consumidores para realizar una amplia variedad de tareas. Claro, los LLM tienen sus ventajas y son más adecuados para ciertos casos de uso, como la resolución de tareas complejas. Sin embargo, los SLM son el futuro para la mayoría de los casos de uso debido a las siguientes razones.
1. Menor costo de capacitación y mantenimiento

Los SLM necesitan menos datos para la capacitación que los LLM, lo que los convierte en la opción más viable para individuos y pequeñas y medianas empresas con datos de capacitación, finanzas o ambos limitados. Los LLM requieren grandes cantidades de datos de capacitación y, por extensión, necesitan enormes recursos computacionales tanto para entrenar como para ejecutarse.
Para poner esto en perspectiva, el CEO de OpenAI, Sam Altman, confirmó que les llevó más de $100 millones entrenar GPT-4 mientras habla en un evento en el MIT (según Wired). Otro ejemplo es el LLM OPT-175B de Meta. Meta dice que fue entrenado utilizando 992 GPU NVIDIA A100 de 80 GB, que cuestan aproximadamente $10,000 por unidad, según CNBC. Eso sitúa el costo en aproximadamente $9 millones, sin incluir otros gastos como energía, salarios y más.
Con tales cifras, no es viable para las pequeñas y medianas empresas formar un LLM. Por el contrario, los SLM tienen una barrera de entrada más baja en cuanto a recursos y su funcionamiento cuesta menos, por lo que más empresas los adoptarán.
2. Mejor rendimiento

El rendimiento es otra área donde los SLM superan a los LLM debido a su tamaño compacto. Los SLM tienen menos latencia y son más adecuados para escenarios donde se necesitan respuestas más rápidas, como en aplicaciones en tiempo real. Por ejemplo, se prefiere una respuesta más rápida en los sistemas de respuesta de voz como los asistentes digitales.
La ejecución en el dispositivo (más sobre esto más adelante) también significa que su solicitud no tiene que viajar a los servidores en línea y regresar a responda a su consulta, lo que generará respuestas más rápidas.
3. Más preciso

Cuando se trata de IA generativa, una cosa permanece constante: basura que entra, basura que sale. Los LLM actuales se han capacitado utilizando grandes conjuntos de datos sin procesar de Internet. Por lo tanto, es posible que no sean precisos en todas las situaciones. Este es uno de los problemas con ChatGPT y modelos similares y por el que no deberías confiar en todo lo que dice un chatbot de IA. Por otro lado, los SLM se entrenan utilizando datos de mayor calidad que los LLM y, por lo tanto, tienen mayor precisión.
Los SLM también se pueden perfeccionar aún más con capacitación enfocada en tareas o dominios específicos, lo que lleva a una mayor precisión en esas áreas en comparación con modelos más grandes y generalizados.
4. Puede ejecutarse en el dispositivo

Los SLM necesitan menos potencia computacional que los LLM y, por lo tanto, son ideales para casos de computación de vanguardia. Se pueden implementar en dispositivos periféricos como teléfonos inteligentes y vehículos autónomos, que no tienen gran poder computacional ni recursos. El modelo Nano de Google puede ejecutarse en el dispositivo, lo que le permite funcionar incluso cuando no se tiene una conexión a Internet activa.
Esta capacidad presenta una situación beneficiosa tanto para las empresas como para los consumidores. En primer lugar, es una ventaja para la privacidad, ya que los datos de los usuarios se procesan localmente en lugar de enviarse a la nube, lo cual es importante a medida que se integra más IA en nuestros teléfonos inteligentes, que contiene casi todos los detalles sobre nosotros. También es una ventaja para las empresas, ya que no necesitan implementar ni ejecutar grandes servidores para manejar tareas de IA.
Los SLM están ganando impulso, con los actores más grandes de la industria, como Open AI, Google, Microsoft, Anthropic y Meta, lanzando dichos modelos. Estos modelos son más adecuados para tareas más simples, que es para lo que la mayoría de nosotros usamos los LLM; por lo tanto, son el futuro.
Pero los LLM no van a ninguna parte. En cambio, se utilizarán para aplicaciones avanzadas que combinen información de diferentes dominios para crear algo nuevo, como en la investigación médica.
-
 8 recomendaciones de API esenciales gratuitas y pagadas para LLMaprovechando el poder de los LLM: una guía para las API para modelos de lenguaje grandes En el panorama comercial dinámico de hoy, las apis (interf...AI Publicado el 2025-04-21
8 recomendaciones de API esenciales gratuitas y pagadas para LLMaprovechando el poder de los LLM: una guía para las API para modelos de lenguaje grandes En el panorama comercial dinámico de hoy, las apis (interf...AI Publicado el 2025-04-21 -
Guía del usuario: modelo Falcon 3-7B InstruceTii's Falcon 3: un salto revolucionario en AI de código abierto La ambiciosa búsqueda de TII de redefinir AI alcanza nuevas alturas con el mode...AI Publicado el 2025-04-20
-
Deepseek-v3 vs. GPT-4O y Llama 3.3 70b: el modelo de IA más fuerte reveladoThe evolution of AI language models has set new standards, especially in the coding and programming landscape. Leading the c...AI Publicado el 2025-04-18
-
Top 5 Herramientas de presupuesto inteligente de IAdesbloqueando la libertad financiera con AI: aplicaciones de presupuesto superior en India ¿Estás cansado de preguntarte constantemente a dónde va ...AI Publicado el 2025-04-17
-
Explicación detallada de la función de Excel Sumproduct - Escuela de Análisis de DatosFunción Sumproduct de Excel: una potencia de análisis de datos desbloquea la potencia de la función Sumproduct de Excel para el análisis de datos s...AI Publicado el 2025-04-16
-
La investigación en profundidad está completamente abierta, los beneficios del usuario de ChatGPT másInvestigación profunda de Openai: un cambio de juego para AI Research Openai ha desatado una investigación profunda para todos los suscriptores de ...AI Publicado el 2025-04-16
-
Amazon Nova Today Real Experience and Review - Analytics VidhyaAmazon presenta nova: modelos de base de vanguardia para AI y creación de contenido mejoradas El reciente evento de Invent 2024 de Amazon exhibió a...AI Publicado el 2025-04-16
-
5 formas de usar la función de tarea de sincronización de chatgptLas nuevas tareas programadas de Chatgpt: automatizar su día con ai chatgpt recientemente presentó una función de cambio de juego: tareas programad...AI Publicado el 2025-04-16
-
¿Cuál de los tres chatbots de IA responde al mismo aviso es el mejor?con opciones como Claude, ChatGpt y Gemini, elegir un chatbot puede sentirse abrumador. Para ayudar a cortar el ruido, puse los tres a la prueba u...AI Publicado el 2025-04-15
-
Chatgpt es suficiente, no se necesita una máquina de chat de IA dedicadaEn un mundo con nuevos chatbots de IA que se lanzarán a diario, puede ser abrumador decidir cuál es el correcto "uno". Pero en mi experienc...AI Publicado el 2025-04-14
-
Momento de la IA india: competencia con China y Estados Unidos en IA generativaAmbiciones AI de la India: una actualización de 2025 con China y Estados Unidos invirtiendo en gran medida en IA generativa, India está acelerando ...AI Publicado el 2025-04-13
-
Automatizar la importación de CSV a PostgreSQL usando Airflow y DockerEste tutorial demuestra construir una tubería de datos robusta utilizando Apache Airflow, Docker y PostgreSQL para automatizar la transferencia de da...AI Publicado el 2025-04-12
-
Algoritmos de inteligencia de enjambres: implementaciones de tres pythonImagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...AI Publicado el 2025-03-24
-
Cómo hacer que su LLM sea más preciso con el trapo y el ajusteImagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...AI Publicado el 2025-03-24
-
¿Qué es Google Gemini? Todo lo que necesitas saber sobre el rival de chatgpt de GoogleGoogle recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...AI Publicado el 2025-03-23















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









