 Página delantera > Programación > K Regresión de vecinos más cercanos, regresión: aprendizaje automático supervisado
Página delantera > Programación > K Regresión de vecinos más cercanos, regresión: aprendizaje automático supervisado
K Regresión de vecinos más cercanos, regresión: aprendizaje automático supervisado
 Navegar:283
Navegar:283
k-Regresión de vecinos más cercanos
La regresión de k-vecinos más cercanos (k-NN) es un método no paramétrico que predice el valor de salida en función del promedio (o promedio ponderado) de los k puntos de datos de entrenamiento más cercanos en el espacio de características. Este enfoque puede modelar eficazmente relaciones complejas en datos sin asumir una forma funcional específica.
El método de regresión k-NN se puede resumir de la siguiente manera:
- Métrica de distancia: el algoritmo utiliza una métrica de distancia (comúnmente distancia euclidiana) para determinar la "cercanía" de los puntos de datos.
- k Vecinos: El parámetro k especifica cuántos vecinos más cercanos se deben considerar al realizar predicciones.
- Predicción: El valor predicho para un nuevo punto de datos es el promedio de los valores de sus k vecinos más cercanos.
Conceptos clave
No paramétrico: a diferencia de los modelos paramétricos, k-NN no asume una forma específica para la relación subyacente entre las características de entrada y la variable objetivo. Esto lo hace flexible a la hora de capturar patrones complejos.
Cálculo de distancia: La elección de la métrica de distancia puede afectar significativamente el rendimiento del modelo. Las métricas comunes incluyen distancias euclidianas, de Manhattan y de Minkowski.
Elección de k: El número de vecinos (k) se puede elegir en función de la validación cruzada. Una k pequeña puede provocar un sobreajuste, mientras que una k grande puede suavizar demasiado la predicción, lo que podría provocar un desajuste.
Ejemplo de regresión de k-vecinos más cercanos
Este ejemplo demuestra cómo utilizar la regresión k-NN con características polinomiales para modelar relaciones complejas mientras se aprovecha la naturaleza no paramétrica de k-NN.
Ejemplo de código Python
1. Importar bibliotecas
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import PolynomialFeatures from sklearn.neighbors import KNeighborsRegressor from sklearn.metrics import mean_squared_error, r2_score
Este bloque importa las bibliotecas necesarias para la manipulación de datos, el trazado y el aprendizaje automático.
2. Generar datos de muestra
np.random.seed(42) # For reproducibility X = np.linspace(0, 10, 100).reshape(-1, 1) y = 3 * X.ravel() np.sin(2 * X.ravel()) * 5 np.random.normal(0, 1, 100)
Este bloque genera datos de muestra que representan una relación con algo de ruido, simulando variaciones de datos del mundo real.
3. Dividir el conjunto de datos
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Este bloque divide el conjunto de datos en conjuntos de entrenamiento y prueba para la evaluación del modelo.
4. Crear entidades polinómicas
degree = 3 # Change this value for different polynomial degrees poly = PolynomialFeatures(degree=degree) X_poly_train = poly.fit_transform(X_train) X_poly_test = poly.transform(X_test)
Este bloque genera características polinómicas a partir de los conjuntos de datos de entrenamiento y prueba, lo que permite que el modelo capture relaciones no lineales.
5. Cree y entrene el modelo de regresión k-NN
k = 5 # Number of neighbors knn_model = KNeighborsRegressor(n_neighbors=k) knn_model.fit(X_poly_train, y_train)
Este bloque inicializa el modelo de regresión k-NN y lo entrena utilizando las características polinómicas derivadas del conjunto de datos de entrenamiento.
6. Hacer predicciones
y_pred = knn_model.predict(X_poly_test)
Este bloque utiliza el modelo entrenado para hacer predicciones en el conjunto de prueba.
7. Trazar los resultados
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='Data Points')
X_grid = np.linspace(0, 10, 1000).reshape(-1, 1)
X_poly_grid = poly.transform(X_grid)
y_grid = knn_model.predict(X_poly_grid)
plt.plot(X_grid, y_grid, color='red', linewidth=2, label=f'k-NN Regression (k={k}, Degree {degree})')
plt.title(f'k-NN Regression (Polynomial Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
Este bloque crea un diagrama de dispersión de los puntos de datos reales versus los valores predichos del modelo de regresión k-NN, visualizando la curva ajustada.
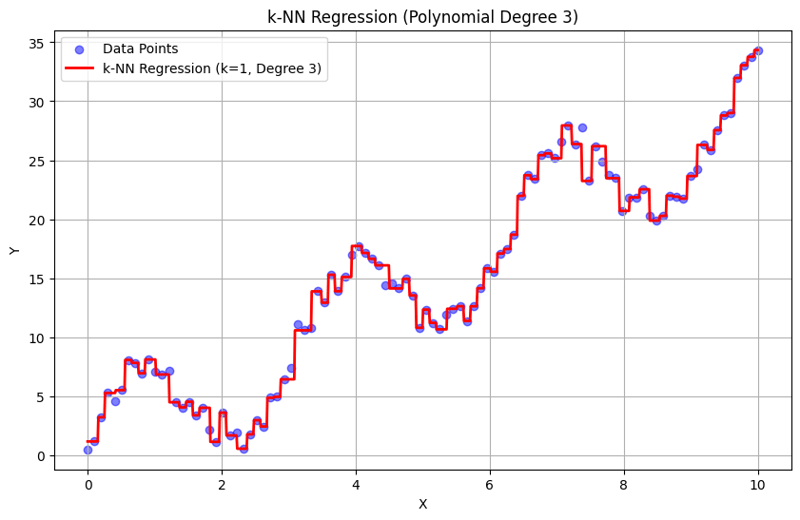
Salida con k = 1:
Salida con k = 10:
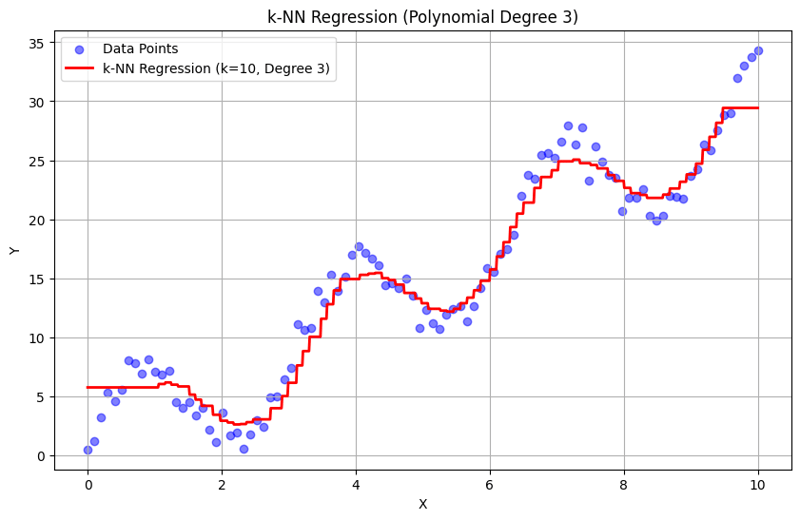
Este enfoque estructurado demuestra cómo implementar y evaluar la regresión de k-vecinos más cercanos con características polinómicas. Al capturar patrones locales mediante el promedio de las respuestas de los vecinos cercanos, la regresión k-NN modela de manera efectiva relaciones complejas en los datos y, al mismo tiempo, proporciona una implementación sencilla. La elección de k y el grado del polinomio influye significativamente en el rendimiento y la flexibilidad del modelo para capturar las tendencias subyacentes.
-
 Fit de objeto: la cubierta falla en IE y Edge, ¿cómo solucionar?Object-Fit: la portada falla en IE y Edge, ¿cómo solucionar? utilizando objeto-fit: cover; en CSS para mantener la altura de imagen consistent...Programación Publicado el 2025-02-07
Fit de objeto: la cubierta falla en IE y Edge, ¿cómo solucionar?Object-Fit: la portada falla en IE y Edge, ¿cómo solucionar? utilizando objeto-fit: cover; en CSS para mantener la altura de imagen consistent...Programación Publicado el 2025-02-07 -
¿Por qué cesan la ejecución de JavaScript cuando se usa el botón de retroceso de Firefox?Problema de historial de navegación: JavaScript deja de ejecutar después de usar el botón de retroceso de Firefox Los usuarios de Firefox pued...Programación Publicado el 2025-02-07
-
¿Puedo usar SVG como contenido de pseudo-elemento en CSS?usando SVGS como pseudo-elemento contenido La propiedad de contenido CSS permite insertar varios tipos de contenido antes o después de un elem...Programación Publicado el 2025-02-07
-
¿Cómo puedo manejar múltiples cargas de archivos con FormData ()?Manejo de múltiples cargas de archivo con formdata () Cuando se trabaja con entradas de archivos, a menudo es necesario manejar múltiples carg...Programación Publicado el 2025-02-07
-
¿Cómo puedo unir tablas de bases de datos con diferentes números de columnas?tablas combinadas con diferentes columnas ]] puede encontrar desafíos al intentar fusionar las tablas de la base de datos con diferentes column...Programación Publicado el 2025-02-07
-
¿Cómo puedo verificar de manera confiable la existencia de columna en una tabla MySQL?determinando la existencia de la columna en una tabla mysql en mysql, verificar la presencia de una columna en una tabla puede ser un poco per...Programación Publicado el 2025-02-07
-
¿Cómo verificar si un objeto tiene un atributo específico en Python?para determinar el atributo de objeto existencia Esta consulta busca un método para verificar la presencia de un atributo específico dentro de...Programación Publicado el 2025-02-07
-
¿Cómo puedo instalar MySQL en Ubuntu sin un mensaje de contraseña?Instalación no interactiva de mySql en ubuntu el método estándar de instalar el servidor MySQL en Ubuntu usando SUDO apt-get Instalar mySql in...Programación Publicado el 2025-02-07
-
¿Cómo garantizar que Hibernate preserva los valores de Enum al asignar a una columna MySQL enum?preservando los valores de enum en Hibernate: Solución de problemas Tipo de columna incorrecta en el reino de la persistencia de datos, asegur...Programación Publicado el 2025-02-07
-
¿Por qué no es una solicitud posterior a capturar la entrada en PHP a pesar del código válido?abordando la solicitud de solicitud de Post en php en el fragmento de código presentado: action='' la intención es capturar la entrada del...Programación Publicado el 2025-02-07
-
¿Cuáles fueron las restricciones al usar Current_Timestamp con columnas de marca de tiempo en MySQL antes de la versión 5.6.5?en columnas de marca de tiempo con currution_timestamp en default o en cláusulas de actualización en versiones mySQL antes de 5.6.5 históricamen...Programación Publicado el 2025-02-07
-
¿Cómo ordenar datos por longitud de cadena en mySQL usando char_length ()?Seleccionando datos mediante la longitud de cadena en mysql para ordenar datos basados en la longitud de cadena en mysql, en lugar de usar s...Programación Publicado el 2025-02-07
-
¿Cómo implementar el manejo de excepciones personalizadas con el módulo de registro de Python?que el manejo de errores personalizados con el módulo de registro de Python asegurando que las excepciones no capturadas se manejen y registre...Programación Publicado el 2025-02-07
-
¿`Exec ()` actualiza las variables locales en Python 3, y si no, cómo se puede hacer?Exec. ¿Puede actualizar las variables locales dentro de una función? El dilema de Python 3 en Python 3, el siguiente fragmento de código no...Programación Publicado el 2025-02-07
-
¿Cómo insertar correctamente las blobs (imágenes) en MySQL usando PHP?Inserte blobs en bases de datos MySQL con php Al intentar almacenar una imagen en una base de datos MySQL, puede encontrar un asunto. Esta gu...Programación Publicado el 2025-02-07















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









