 Página delantera > Programación > Dominar la segmentación de imágenes: cómo las técnicas tradicionales siguen brillando en la era digital
Página delantera > Programación > Dominar la segmentación de imágenes: cómo las técnicas tradicionales siguen brillando en la era digital
Dominar la segmentación de imágenes: cómo las técnicas tradicionales siguen brillando en la era digital
 Navegar:975
Navegar:975
Introducción
La segmentación de imágenes, uno de los procedimientos más básicos en visión por computadora, permite que un sistema descomponga y analice varias regiones dentro de una imagen. Ya sea que se trate de reconocimiento de objetos, imágenes médicas o conducción autónoma, la segmentación es lo que divide las imágenes en partes significativas.
Aunque los modelos de aprendizaje profundo siguen siendo cada vez más populares en esta tarea, las técnicas tradicionales de procesamiento de imágenes digitales siguen siendo potentes y prácticas. Los enfoques que se revisan en esta publicación incluyen umbralización, detección de bordes, basado en regiones y agrupación mediante la implementación de un conjunto de datos bien reconocido para el análisis de imágenes celulares, el conjunto de datos de imágenes MIVIA HEp-2.
Conjunto de datos de imágenes MIVIA HEp-2
El conjunto de datos de imágenes MIVIA HEp-2 es un conjunto de imágenes de las células utilizadas para analizar el patrón de anticuerpos antinucleares (ANA) a través de las células HEp-2. Consiste en fotografías 2D tomadas mediante microscopía de fluorescencia. Esto lo hace muy adecuado para tareas de segmentación, principalmente aquellas relacionadas con el análisis de imágenes médicas, donde la detección de regiones celulares es más importante.
Ahora, pasemos a las técnicas de segmentación utilizadas para procesar estas imágenes, comparando su rendimiento en función de las puntuaciones de F1.
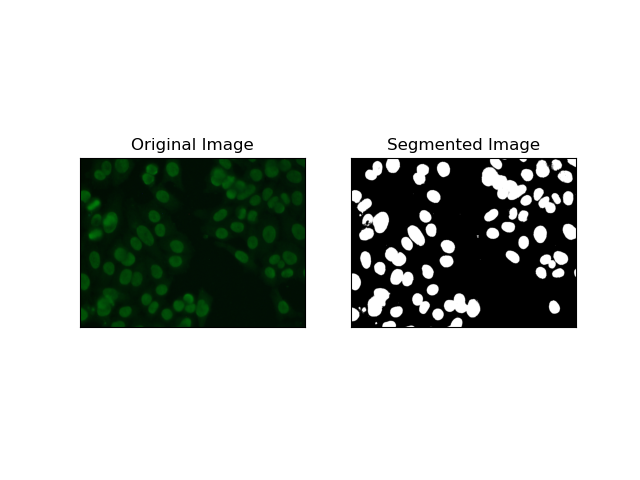
1. Segmentación umbral
El umbral es el proceso mediante el cual las imágenes en escala de grises se convierten en imágenes binarias en función de la intensidad de los píxeles. En el conjunto de datos MIVIA HEp-2, este proceso es útil en la extracción de células en segundo plano. Es simple y efectivo a un nivel relativamente grande, especialmente con método de Otsu, ya que calcula automáticamente el umbral óptimo.
El método de Otsu es un método de umbral automático, en el que intenta encontrar el mejor valor de umbral para producir la variación mínima dentro de la clase, separando así las dos clases: primer plano (celdas) y fondo. El método examina el histograma de la imagen y calcula el umbral perfecto, donde se minimiza la suma de las variaciones de intensidad de píxeles en cada clase.
# Thresholding Segmentation
def thresholding(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return thresh
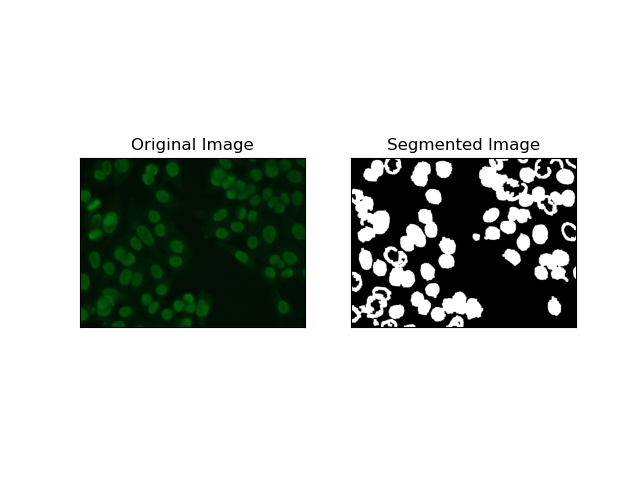
2. Segmentación de detección de bordes
La detección de bordes se refiere a la identificación de límites de objetos o regiones, como los bordes de las celdas en el conjunto de datos MIVIA HEp-2. De los muchos métodos disponibles para detectar cambios abruptos de intensidad, el Canny Edge Detector es el mejor método y, por lo tanto, el más apropiado para detectar límites celulares.
Canny Edge Detector es un algoritmo de varias etapas que puede detectar los bordes detectando áreas de fuertes gradientes de intensidad. El proceso implica suavizado con un filtro gaussiano, cálculo de gradientes de intensidad, aplicación de supresión no máxima para eliminar respuestas espurias y una operación final de doble umbral para retener solo los bordes salientes.
# Edge Detection Segmentation
def edge_detection(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Gaussian blur
gray = cv.GaussianBlur(gray, (3, 3), 0)
# Calculate lower and upper thresholds for Canny edge detection
sigma = 0.33
v = np.median(gray)
lower = int(max(0, (1.0 - sigma) * v))
upper = int(min(255, (1.0 sigma) * v))
# Apply Canny edge detection
edges = cv.Canny(gray, lower, upper)
# Dilate the edges to fill gaps
kernel = np.ones((5, 5), np.uint8)
dilated_edges = cv.dilate(edges, kernel, iterations=2)
# Clean the edges using morphological opening
cleaned_edges = cv.morphologyEx(dilated_edges, cv.MORPH_OPEN, kernel, iterations=1)
# Find connected components and filter out small components
num_labels, labels, stats, _ = cv.connectedComponentsWithStats(
cleaned_edges, connectivity=8
)
min_size = 500
filtered_mask = np.zeros_like(cleaned_edges)
for i in range(1, num_labels):
if stats[i, cv.CC_STAT_AREA] >= min_size:
filtered_mask[labels == i] = 255
# Find contours of the filtered mask
contours, _ = cv.findContours(
filtered_mask, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE
)
# Create a filled mask using the contours
filled_mask = np.zeros_like(gray)
cv.drawContours(filled_mask, contours, -1, (255), thickness=cv.FILLED)
# Perform morphological closing to fill holes
final_filled_image = cv.morphologyEx(
filled_mask, cv.MORPH_CLOSE, kernel, iterations=2
)
# Dilate the final filled image to smooth the edges
final_filled_image = cv.dilate(final_filled_image, kernel, iterations=1)
return final_filled_image
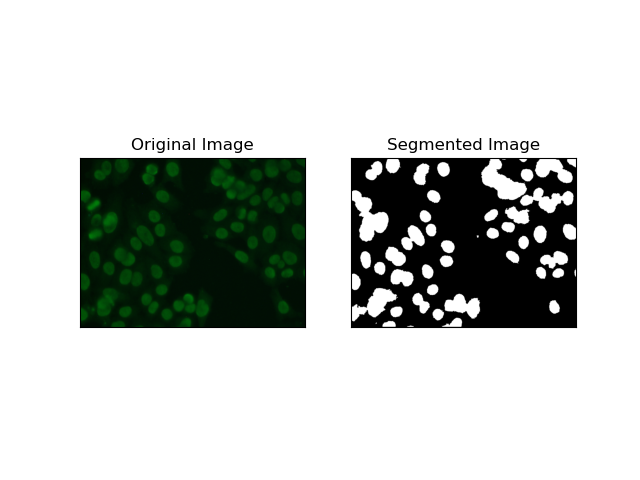
3. Segmentación basada en regiones
La segmentación basada en regiones agrupa píxeles similares en regiones, dependiendo de ciertos criterios como la intensidad o el color. La técnica de Segmentación de cuencas se puede utilizar para ayudar a segmentar imágenes de células HEp-2 para poder detectar aquellas regiones que representan células; considera las intensidades de los píxeles como una superficie topográfica y describe regiones distintivas.
La segmentación de cuencas hidrográficas trata las intensidades de los píxeles como una superficie topográfica. El algoritmo identifica "cuencas" en las que identifica mínimos locales y luego inunda gradualmente estas cuencas para ampliar distintas regiones. Esta técnica es bastante útil cuando se quieren separar objetos en contacto, como en el caso de células en imágenes microscópicas, pero puede ser sensible al ruido. El proceso puede guiarse por marcadores y, a menudo, se puede reducir la segmentación excesiva.
# Region-Based Segmentation
def region_based(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV cv.THRESH_OTSU)
# Apply morphological opening to remove noise
kernel = np.ones((3, 3), np.uint8)
opening = cv.morphologyEx(thresh, cv.MORPH_OPEN, kernel, iterations=2)
# Dilate the opening to get the background
sure_bg = cv.dilate(opening, kernel, iterations=3)
# Calculate the distance transform
dist_transform = cv.distanceTransform(opening, cv.DIST_L2, 5)
# Threshold the distance transform to get the foreground
_, sure_fg = cv.threshold(dist_transform, 0.2 * dist_transform.max(), 255, 0)
sure_fg = np.uint8(sure_fg)
# Find the unknown region
unknown = cv.subtract(sure_bg, sure_fg)
# Label the markers for watershed algorithm
_, markers = cv.connectedComponents(sure_fg)
markers = markers 1
markers[unknown == 255] = 0
# Apply watershed algorithm
markers = cv.watershed(img, markers)
# Create a mask for the segmented region
mask = np.zeros_like(gray, dtype=np.uint8)
mask[markers == 1] = 255
return mask
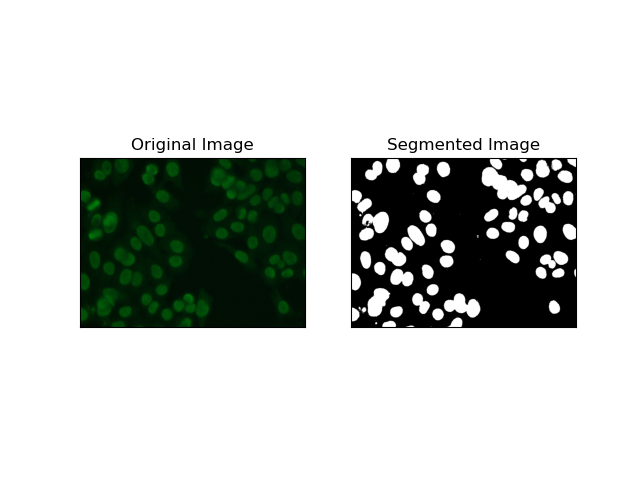
4. Segmentación basada en agrupaciones
Las técnicas de agrupamiento como K-Means tienden a agrupar los píxeles en grupos similares, lo que funciona bien cuando se desea segmentar células en entornos multicolores o complejos, como se ve en las imágenes de células HEp-2. Fundamentalmente, esto podría representar diferentes clases, como una región celular versus un fondo.
K-means es un algoritmo de aprendizaje no supervisado para agrupar imágenes en función de la similitud de color o intensidad de los píxeles. El algoritmo selecciona aleatoriamente K centroides, asigna cada píxel al centroide más cercano y actualiza el centroide de forma iterativa hasta que converge. Es particularmente eficaz para segmentar una imagen que tiene múltiples regiones de interés que son muy diferentes entre sí.
# Clustering Segmentation
def clustering(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Reshape the image
Z = gray.reshape((-1, 3))
Z = np.float32(Z)
# Define the criteria for k-means clustering
criteria = (cv.TERM_CRITERIA_EPS cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# Set the number of clusters
K = 2
# Perform k-means clustering
_, label, center = cv.kmeans(Z, K, None, criteria, 10, cv.KMEANS_RANDOM_CENTERS)
# Convert the center values to uint8
center = np.uint8(center)
# Reshape the result
res = center[label.flatten()]
res = res.reshape((gray.shape))
# Apply thresholding to the result
_, res = cv.threshold(res, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return res
Evaluación de las técnicas utilizando puntuaciones de F1
La puntuación F1 es una medida que combina precisión y recuperación para comparar la imagen de segmentación predicha con la imagen real del terreno. Es la media armónica de precisión y recuperación, que resulta útil en casos de alto desequilibrio de datos, como en conjuntos de datos de imágenes médicas.
Calculamos la puntuación F1 para cada método de segmentación aplanando tanto la verdad fundamental como la imagen segmentada y calculando la puntuación F1 ponderada.
def calculate_f1_score(ground_image, segmented_image):
ground_image = ground_image.flatten()
segmented_image = segmented_image.flatten()
return f1_score(ground_image, segmented_image, average="weighted")
Luego visualizamos las puntuaciones de F1 de diferentes métodos utilizando un gráfico de barras simple:
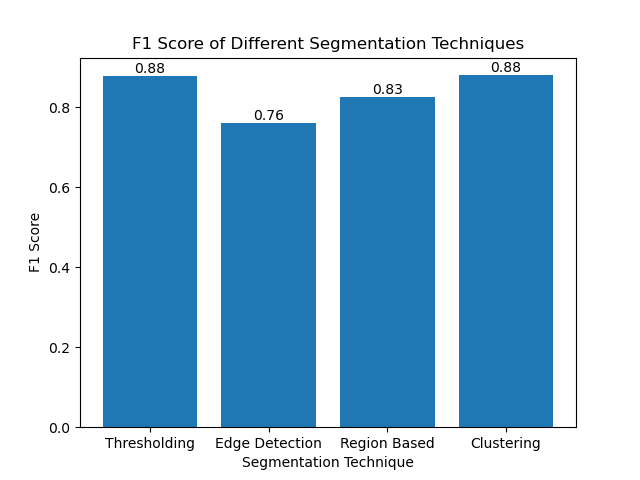
Conclusión
Aunque están surgiendo muchos enfoques recientes para la segmentación de imágenes, las técnicas de segmentación tradicionales como el umbral, la detección de bordes, los métodos basados en regiones y la agrupación pueden ser muy útiles cuando se aplican a conjuntos de datos como el conjunto de datos de imágenes MIVIA HEp-2.
Cada método tiene su punto fuerte:
- El umbral es bueno para la segmentación binaria simple.
- La detección de bordes es una técnica ideal para la detección de límites.
- La segmentación basada en regiones es muy útil para separar los componentes conectados de sus vecinos.
- Los métodos de agrupación son adecuados para tareas de segmentación multirregional.
Al evaluar estos métodos utilizando puntuaciones F1, entendemos las ventajas y desventajas que tiene cada uno de estos modelos. Es posible que estos métodos no sean tan sofisticados como los desarrollados en los modelos más nuevos de aprendizaje profundo, pero aún así son rápidos, interpretables y utilizables en una amplia gama de aplicaciones.
¡Gracias por leer! Espero que esta exploración de las técnicas tradicionales de segmentación de imágenes inspire su próximo proyecto. ¡No dudes en compartir tus pensamientos y experiencias en los comentarios a continuación!
-
 ¿Se pueden apilar múltiples elementos adhesivos uno encima del otro en CSS puro?¿Es posible tener múltiples elementos pegajosos apilados uno encima del otro en CSS puro? El comportamiento deseado se puede ver Aquí: https...Programación Publicado el 2025-07-12
¿Se pueden apilar múltiples elementos adhesivos uno encima del otro en CSS puro?¿Es posible tener múltiples elementos pegajosos apilados uno encima del otro en CSS puro? El comportamiento deseado se puede ver Aquí: https...Programación Publicado el 2025-07-12 -
¿Por qué no `cuerpo {margen: 0; } `¿Siempre elimina el margen superior en CSS?abordando la eliminación del margen del cuerpo en css para desarrolladores web novatos, eliminar el margen del elemento corporal puede ser una...Programación Publicado el 2025-07-12
-
¿Cómo redirigir múltiples tipos de usuarios (estudiantes, maestros y administradores) a sus respectivas actividades en una aplicación Firebase?rojo: cómo redirigir múltiples tipos de usuarios a las actividades respectivas Comprender el problema en una aplicación de votación basada...Programación Publicado el 2025-07-12
-
¿Qué método es más eficiente para la detección de Point-in-Polygon: Ray Tracing o Matplotlib \ 's Rath.Contains_Points?Detección eficiente de Point-in-Polygon en python determinando si un punto se encuentra dentro de un polígono es una tarea frecuente en la geome...Programación Publicado el 2025-07-12
-
¿Cómo repetir eficientemente los caracteres de cadena para la sangría en C#?repitiendo una cadena para la indentación al sangrar una cadena basada en la profundidad de un elemento, es conveniente tener una forma eficie...Programación Publicado el 2025-07-12
-
¿Necesito eliminar explícitamente las asignaciones de montón en C ++ antes de la salida del programa?deleción explícita en c a pesar de la salida del programa cuando trabajan con la asignación de memoria dinámica en c, los desarrolladores a me...Programación Publicado el 2025-07-12
-
¿Cómo crear variables dinámicas en Python?Dynamic Variable Creation en python La capacidad de crear variables dinámicamente puede ser una herramienta poderosa, especialmente cuando se ...Programación Publicado el 2025-07-12
-
¿Cómo recuperar eficientemente la última fila para cada identificador único en PostgreSQL?postgresql: extrayendo la última fila para cada identificador único en postgresql, puede encontrar situaciones en las que necesita extraer la ...Programación Publicado el 2025-07-12
-
¿Por qué no es una solicitud posterior a capturar la entrada en PHP a pesar del código válido?abordando la solicitud de solicitud de la publicación $ _Server ['php_self'];?> "Método =" post "> [&] la intenci...Programación Publicado el 2025-07-12
-
¿Cómo insertar correctamente las blobs (imágenes) en MySQL usando PHP?Inserte blobs en bases de datos MySQL con php Al intentar almacenar una imagen en una base de datos MySQL, puede encontrar un asunto. Esta gu...Programación Publicado el 2025-07-12
-
¿Puedes usar CSS para la salida de la consola de color en Chrome y Firefox?que muestra los colores en la console JavaScript es posible usar la consola de Chrome para mostrar texto coloreado, como rojo para errores, na...Programación Publicado el 2025-07-12
-
¿Cómo recuperar la última biblioteca jQuery de Google API?recuperando la última biblioteca jQuery de Google APIS La URL de jQuery proporcionada en la pregunta es para la versión 1.2.6. Para recuperar ...Programación Publicado el 2025-07-12
-
Guía de visualización de compensación de tiempo local del usuario y zona horaria de la zona horariaque muestra la fecha/hora en el formato local del usuario con el tiempo offset al presentar fechas y tiempos a los usuarios finales, es crucia...Programación Publicado el 2025-07-12
-
¿Por qué recibo un error de \ "clase \ 'Ziparchive \' no encontrado \" después de instalar Archive_Zip en mi servidor Linux?class 'Ziparchive' no encontrado Error al instalar Archive_Zip en Linux Server Sytom: cuando intentan ejecutar un script que utiliza...Programación Publicado el 2025-07-12
-
¿Por qué Microsoft Visual C ++ no implementa correctamente la instanciación de la plantilla de dos fases?El misterio de la plantilla de dos fases "roto" instanciación en Microsoft Visual c declaración de problemas: usuarios comúnmente ...Programación Publicado el 2025-07-12















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









