
import streamlit as stimport numpy as npimport pandas as pdimport joblib
stremlit es una biblioteca de Python que facilita la creación y el intercambio de aplicaciones web personalizadas para proyectos de ciencia de datos y aprendizaje automático.
numpy es una biblioteca de Python fundamental para la computación numérica. Proporciona soporte para matrices y arreglos multidimensionales grandes, junto con una colección de funciones matemáticas para operar en estos arreglos de manera eficiente.
data = { \\\"island\\\": island, \\\"bill_length_mm\\\": bill_length_mm, \\\"bill_depth_mm\\\": bill_depth_mm, \\\"flipper_length_mm\\\": flipper_length_mm, \\\"body_mass_g\\\": body_mass_g, \\\"sex\\\": sex,}input_df = pd.DataFrame(data, index=[0])encode = [\\\"island\\\", \\\"sex\\\"]input_encoded_df = pd.get_dummies(input_df, prefix=encode)Los valores de entrada se recuperan del formulario de entrada creado por Stremlit y las variables categóricas se codifican utilizando las mismas reglas que cuando se creó el modelo. Tenga en cuenta que el orden de cada dato también debe ser el mismo que cuando se creó el modelo. Si el orden es diferente ocurrirá un error al ejecutar un pronóstico usando el modelo.
clf = joblib.load(\\\"penguin_classifier_model.pkl\\\")
\\\"penguin_classifier_model.pkl\\\" es el archivo donde se almacena el modelo previamente guardado. Este archivo contiene un RandomForestClassifier entrenado en formato binario. Al ejecutar este código se carga el modelo en clf, lo que le permite usarlo para predicciones y evaluaciones de nuevos datos.
prediction = clf.predict(input_encoded_df)prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): utiliza el modelo entrenado para predecir la clase para los nuevos datos de entrada codificados, almacenando el resultado en predicción.
clf.predict_proba(input_encoded_df): Calcula la probabilidad para cada clase, almacenando los resultados en predict_proba.
Puedes publicar tu aplicación desarrollada en Internet accediendo a Stremlit Community Cloud (https://streamlit.io/cloud) y especificando la URL del repositorio de GitHub.

Obra de @allison_horst (https://github.com/allisonhorst)
El modelo se entrena utilizando el conjunto de datos Palmer Penguins, un conjunto de datos ampliamente reconocido para practicar técnicas de aprendizaje automático. Este conjunto de datos proporciona información sobre tres especies de pingüinos (Adelia, Barbijo y Gentoo) del Archipiélago Palmer en la Antártida. Las características clave incluyen:
Este conjunto de datos proviene de Kaggle y se puede acceder a él aquí. La diversidad de características lo convierte en una excelente opción para construir un modelo de clasificación y comprender la importancia de cada característica en la predicción de especies.
","image":"http://www.luping.net/uploads/20241006/17282217676702924713227.png","datePublished":"2024-11-02T21:56:21+08:00","dateModified":"2024-11-02T21:56:21+08:00","author":{"@type":"Person","name":"luping.net","url":"https://www.luping.net/articlelist/0_1.html"}} Página delantera > Programación > Implementación de modelos de aprendizaje automático como una aplicación web utilizando Streamlit
Página delantera > Programación > Implementación de modelos de aprendizaje automático como una aplicación web utilizando Streamlit
 Navegar:569
Navegar:569
Un modelo de aprendizaje automático es esencialmente un conjunto de reglas o mecanismos utilizados para hacer predicciones o encontrar patrones en los datos. Para decirlo de manera muy simple (y sin temor a simplificar demasiado), una línea de tendencia calculada utilizando el método de mínimos cuadrados en Excel también es un modelo. Sin embargo, los modelos utilizados en aplicaciones reales no son tan simples: a menudo implican ecuaciones y algoritmos más complejos, no solo ecuaciones simples.
En esta publicación, comenzaré construyendo un modelo de aprendizaje automático muy simple y lanzándolo como una aplicación web muy simple para tener una idea del proceso.
Aquí, me centraré solo en el proceso, no en el modelo de ML en sí. También usaré Streamlit y Streamlit Community Cloud para lanzar fácilmente aplicaciones web Python.
Con scikit-learn, una popular biblioteca de Python para aprendizaje automático, puedes entrenar datos rápidamente y crear un modelo con solo unas pocas líneas de código para tareas simples. Luego, el modelo se puede guardar como un archivo reutilizable con joblib. ¡Este modelo guardado se puede importar/cargar como una biblioteca Python normal en una aplicación web, lo que permite que la aplicación haga predicciones utilizando el modelo entrenado!
URL de la aplicación: https://yh-machine-learning.streamlit.app/
GitHub: https://github.com/yoshan0921/yh-machine-learning.git
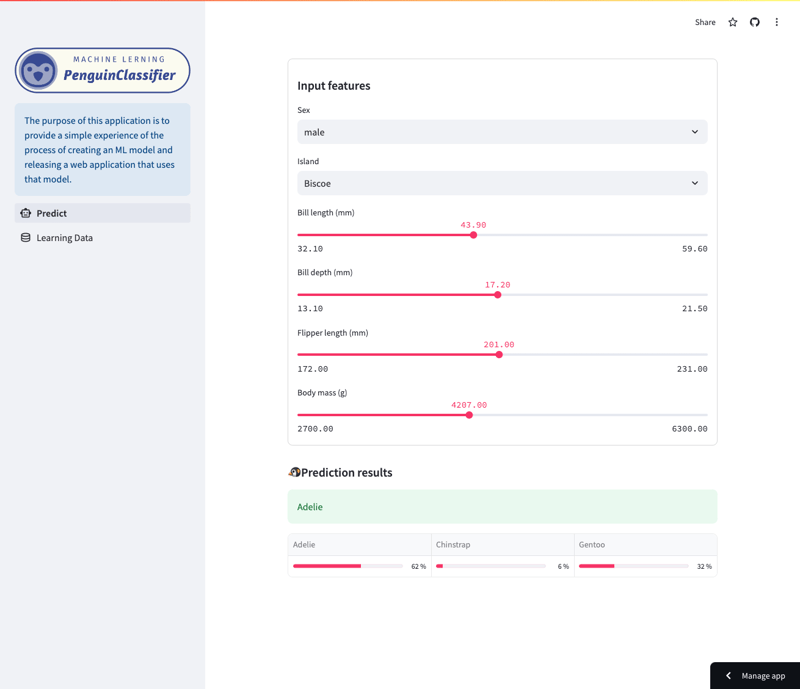
Esta aplicación te permite examinar las predicciones realizadas por un modelo de bosque aleatorio entrenado en el conjunto de datos de Palmer Penguins. (Consulte el final de este artículo para obtener más detalles sobre los datos de entrenamiento).
Específicamente, el modelo predice las especies de pingüinos basándose en una variedad de características, incluyendo especies, islas, longitud del pico, longitud de las aletas, tamaño del cuerpo y sexo. Los usuarios pueden navegar por la aplicación para ver cómo las diferentes características afectan las predicciones del modelo.
Pantalla de predicción
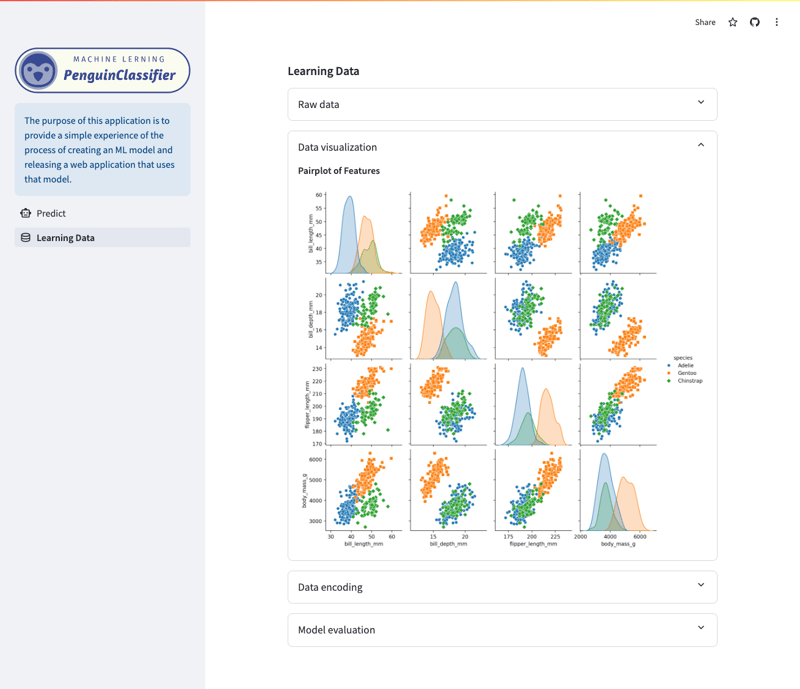
Pantalla de visualización/datos de aprendizaje
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib
pandas es una biblioteca de Python especializada en manipulación y análisis de datos. Admite la carga, el preprocesamiento y la estructuración de datos mediante DataFrames, preparando datos para modelos de aprendizaje automático.
sklearn es una biblioteca Python completa para aprendizaje automático que proporciona herramientas para capacitación y evaluación. En esta publicación, construiré un modelo usando un método de aprendizaje llamado Random Forest.
joblib es una biblioteca de Python que ayuda a guardar y cargar objetos de Python, como modelos de aprendizaje automático, de una manera muy eficiente.
df = pd.read_csv("./dataset/penguins_cleaned.csv")
X_raw = df.drop("species", axis=1)
y_raw = df.species
Cargue el conjunto de datos (datos de entrenamiento) y sepárelo en características (X) y variables objetivo (y).
encode = ["island", "sex"]
X_encoded = pd.get_dummies(X_raw, columns=encode)
target_mapper = {"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
y_encoded = y_raw.apply(lambda x: target_mapper[x])
Las variables categóricas se convierten a un formato numérico utilizando codificación one-hot (X_encoded). Por ejemplo, si "isla" contiene las categorías "Biscoe", "Sueño" y "Torgersen", se crea una nueva columna para cada una (isla_Biscoe, isla_Sueño, isla_Torgersen). Lo mismo se hace con el sexo. Si los datos originales son "Biscoe", la columna island_Biscoe se establecerá en 1 y las demás en 0.
La especie de variable de destino se asigna a valores numéricos (y_encoded).
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y_encoded, test_size=0.3, random_state=1
)
Para evaluar un modelo, es necesario medir el rendimiento del modelo en datos que no se utilizan para el entrenamiento. 7:3 se utiliza ampliamente como práctica general en el aprendizaje automático.
clf = RandomForestClassifier() clf.fit(x_train, y_train)
El método de ajuste se utiliza para entrenar el modelo.
x_train representa los datos de entrenamiento para las variables explicativas y y_train representa las variables objetivo.
Al llamar a este método, el modelo entrenado en función de los datos de entrenamiento se almacena en clf.
joblib.dump(clf, "penguin_classifier_model.pkl")
joblib.dump() es una función para guardar objetos de Python en formato binario. Al guardar el modelo en este formato, el modelo se puede cargar desde un archivo y usarse tal cual sin tener que entrenarlo nuevamente.
import streamlit as st import numpy as np import pandas as pd import joblib
stremlit es una biblioteca de Python que facilita la creación y el intercambio de aplicaciones web personalizadas para proyectos de ciencia de datos y aprendizaje automático.
numpy es una biblioteca de Python fundamental para la computación numérica. Proporciona soporte para matrices y arreglos multidimensionales grandes, junto con una colección de funciones matemáticas para operar en estos arreglos de manera eficiente.
data = {
"island": island,
"bill_length_mm": bill_length_mm,
"bill_depth_mm": bill_depth_mm,
"flipper_length_mm": flipper_length_mm,
"body_mass_g": body_mass_g,
"sex": sex,
}
input_df = pd.DataFrame(data, index=[0])
encode = ["island", "sex"]
input_encoded_df = pd.get_dummies(input_df, prefix=encode)
Los valores de entrada se recuperan del formulario de entrada creado por Stremlit y las variables categóricas se codifican utilizando las mismas reglas que cuando se creó el modelo. Tenga en cuenta que el orden de cada dato también debe ser el mismo que cuando se creó el modelo. Si el orden es diferente ocurrirá un error al ejecutar un pronóstico usando el modelo.
clf = joblib.load("penguin_classifier_model.pkl")
"penguin_classifier_model.pkl" es el archivo donde se almacena el modelo previamente guardado. Este archivo contiene un RandomForestClassifier entrenado en formato binario. Al ejecutar este código se carga el modelo en clf, lo que le permite usarlo para predicciones y evaluaciones de nuevos datos.
prediction = clf.predict(input_encoded_df) prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): utiliza el modelo entrenado para predecir la clase para los nuevos datos de entrada codificados, almacenando el resultado en predicción.
clf.predict_proba(input_encoded_df): Calcula la probabilidad para cada clase, almacenando los resultados en predict_proba.
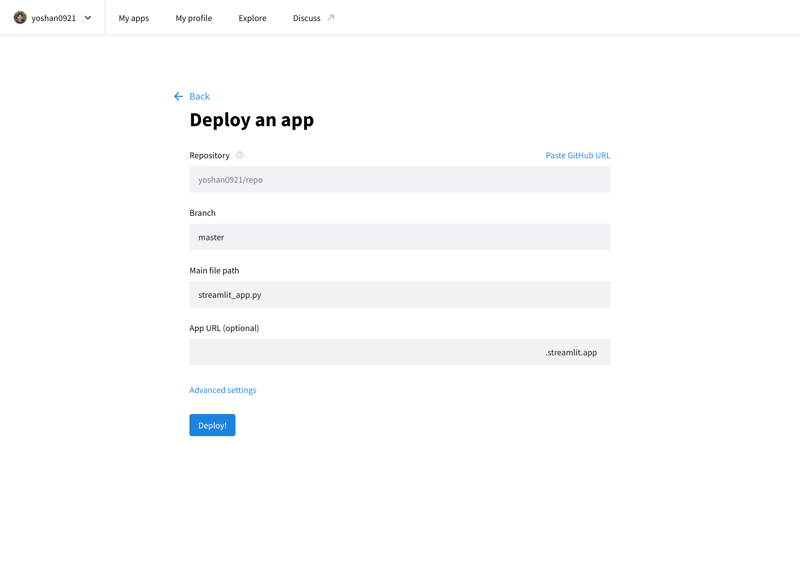
Puedes publicar tu aplicación desarrollada en Internet accediendo a Stremlit Community Cloud (https://streamlit.io/cloud) y especificando la URL del repositorio de GitHub.

Obra de @allison_horst (https://github.com/allisonhorst)
El modelo se entrena utilizando el conjunto de datos Palmer Penguins, un conjunto de datos ampliamente reconocido para practicar técnicas de aprendizaje automático. Este conjunto de datos proporciona información sobre tres especies de pingüinos (Adelia, Barbijo y Gentoo) del Archipiélago Palmer en la Antártida. Las características clave incluyen:
Este conjunto de datos proviene de Kaggle y se puede acceder a él aquí. La diversidad de características lo convierte en una excelente opción para construir un modelo de clasificación y comprender la importancia de cada característica en la predicción de especies.

























Descargo de responsabilidad: Todos los recursos proporcionados provienen en parte de Internet. Si existe alguna infracción de sus derechos de autor u otros derechos e intereses, explique los motivos detallados y proporcione pruebas de los derechos de autor o derechos e intereses y luego envíelos al correo electrónico: [email protected]. Lo manejaremos por usted lo antes posible.
Copyright© 2022 湘ICP备2022001581号-3