 Página delantera > Programación > Mejora del rendimiento con análisis estático, inicialización de imágenes y instantáneas de montón
Página delantera > Programación > Mejora del rendimiento con análisis estático, inicialización de imágenes y instantáneas de montón
Mejora del rendimiento con análisis estático, inicialización de imágenes y instantáneas de montón
 Navegar:657
Navegar:657
Desde las estructuras monolíticas hasta el mundo de los sistemas distribuidos, el desarrollo de aplicaciones ha recorrido un largo camino. La adopción masiva de la computación en la nube y la arquitectura de microservicios ha alterado significativamente el enfoque sobre cómo se crean e implementan las aplicaciones de servidor. En lugar de servidores de aplicaciones gigantes, ahora contamos con servicios independientes, implementados individualmente y que entran en acción
cuando sea necesario.
Sin embargo, un nuevo jugador en el bloque que puede afectar este buen funcionamiento podría ser 'arranques en frío'. Los arranques en frío se activan cuando se procesa la primera solicitud en un trabajador recién generado. Esta situación exige la inicialización del tiempo de ejecución del lenguaje y la inicialización de la configuración del servicio antes de procesar la solicitud real. La imprevisibilidad y la ejecución más lenta asociadas con los arranques en frío pueden violar los acuerdos de nivel de servicio de un servicio en la nube. Entonces, ¿cómo se puede contrarrestar esta creciente preocupación?
Imagen nativa: optimización del tiempo de inicio y la huella de memoria
Para combatir las ineficiencias de los arranques en frío, se ha desarrollado un enfoque novedoso que incluye análisis de puntos de destino, inicialización de aplicaciones en el momento de la compilación, instantáneas del montón y compilación anticipada (AOT). Este método opera bajo una suposición de mundo cerrado, lo que requiere que todas las clases de Java estén predeterminadas y sean accesibles en el momento de la compilación. Durante esta fase, un análisis integral de puntos de destino determina todos los elementos del programa accesibles (clases, métodos, campos) para garantizar que solo se compilen los métodos Java esenciales.
El código de inicialización de la aplicación se puede ejecutar durante el proceso de compilación en lugar de en tiempo de ejecución. Esto permite la preasignación de objetos Java y la construcción de estructuras de datos complejas, que luego están disponibles en tiempo de ejecución a través de un "montón de imágenes". Este montón de imágenes está integrado en el ejecutable, lo que proporciona disponibilidad inmediata al iniciar la aplicación. El
La ejecución iterativa de análisis de puntos de destino y creación de instantáneas continúa hasta que se logra un estado estable (punto fijo), optimizando tanto el tiempo de inicio como el consumo de recursos.
Flujo de trabajo detallado
La entrada para nuestro sistema es el código de bytes de Java, que podría originarse en lenguajes como Java, Scala o Kotlin. El proceso trata la aplicación, sus bibliotecas, el JDK y los componentes de VM de manera uniforme para producir un ejecutable nativo específico para un sistema operativo y una arquitectura, denominado "imagen nativa". El proceso de construcción incluye análisis iterativos de puntos de destino y tomas de instantáneas del montón hasta que se alcanza un punto fijo, lo que permite que la aplicación participe activamente a través de devoluciones de llamadas registradas. Estos pasos se conocen colectivamente como proceso de creación de imágenes nativas (Figura 1)
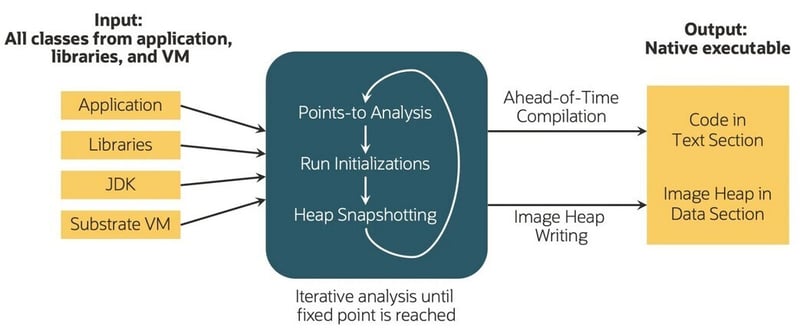
Figura 1: proceso de creación de imágenes nativas (fuente: redhat.com)
Análisis de puntos a
Empleamos un análisis de puntos de destino para determinar la accesibilidad de clases, métodos y campos durante el tiempo de ejecución. El análisis de puntos de acceso comienza con todos los puntos de entrada, como el método principal de la aplicación, y recorre iterativamente todos los métodos transitivamente alcanzables hasta llegar a un punto fijo (Figura 2).
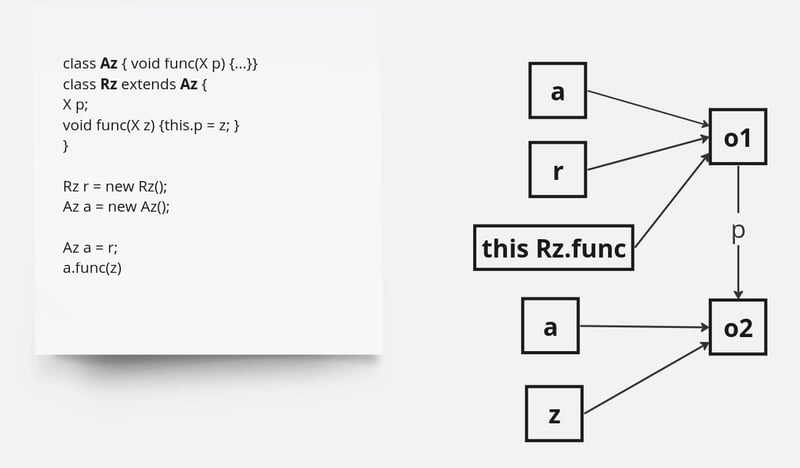
Figura 2: Puntos de análisis
Nuestro análisis de puntos de destino aprovecha la interfaz de nuestro compilador para analizar el código de bytes de Java en la representación intermedia de alto nivel del compilador (IR). Posteriormente, el IR se transforma en un gráfico de tipo-flujo. En este gráfico, los nodos representan instrucciones que operan en tipos de objetos, mientras que los bordes denotan bordes de uso dirigido entre nodos, que apuntan desde la definición hasta el uso. Cada nodo mantiene un estado de tipo, que consta de una lista de tipos que pueden llegar al nodo e información de nulidad. Los estados de tipo se propagan a través de los bordes de uso; Si el estado del tipo de un nodo cambia, este cambio se difunde a todos los usos. Es importante destacar que los estados tipo sólo pueden expandirse; Se pueden agregar nuevos tipos a un estado de tipo, pero los tipos existentes nunca se eliminan. Este mecanismo garantiza que el
El análisis finalmente converge a un punto fijo, lo que lleva a la terminación.
Ejecutar código de inicialización
El análisis de puntos guía la ejecución del código de inicialización cuando llega a un punto fijo local. Este código tiene su origen en dos fuentes distintas: inicializadores de clase y lotes de código personalizado ejecutados en el momento de la compilación a través de una interfaz de funciones:
Inicializadores de clase: Cada clase Java puede tener un inicializador de clase indicado por un método
, que inicializa campos estáticos. Los desarrolladores pueden elegir qué clases inicializar en tiempo de compilación o en tiempo de ejecución. Devoluciones de llamada explícitas: Los desarrolladores pueden implementar código personalizado a través de enlaces proporcionados por nuestro sistema, ejecutándolo antes, durante o después de las etapas de análisis.
Aquí están las API proporcionadas para la integración con nuestro sistema.
API pasiva (consulta el estado del análisis actual)
boolean isReachable(Class> clazz); boolean isReachable(Field field); boolean isReachable(Executable method);
Para obtener más información, consulte QueryReachabilityAccess
API activa (registra devoluciones de llamadas para cambios de estado de análisis):
void registerReachabilityHandler(Consumercallback, Object... elements); void registerSubtypeReachabilityHandler(BiConsumer > callback, Class> baseClass); void registerMethodOverrideReachabilityHandler(BiConsumer callback, Executable baseMethod);
Para obtener más información, consulte BeforeAnalysisAccess
Durante esta fase, la aplicación puede ejecutar código personalizado, como la asignación de objetos y la inicialización de estructuras de datos más grandes. Es importante destacar que el código de inicialización puede acceder al estado actual del análisis de puntos de destino, lo que permite realizar consultas sobre la accesibilidad de tipos, métodos o campos. Esto se logra utilizando los diversos métodos isReachable() proporcionados porDuranteAnalysisAccess. Aprovechando esta información, la aplicación puede construir estructuras de datos optimizadas para los segmentos accesibles de la aplicación.
Instantáneas del montón
Finalmente, la creación de instantáneas del montón construye un gráfico de objetos siguiendo punteros raíz como campos estáticos para crear una vista completa de todos los objetos accesibles. Este gráfico luego completa el
de la imagen nativa.
montón de imágenes, lo que garantiza que el estado inicial de la aplicación se cargue de manera eficiente al iniciarse.
Para generar el cierre transitivo de objetos alcanzables, el algoritmo atraviesa campos de objetos y lee sus valores mediante la reflexión. Es fundamental tener en cuenta que el creador de imágenes opera dentro del entorno Java. Durante este recorrido solo se consideran los campos de instancia marcados como "leídos" por el análisis de puntos de destino. Por ejemplo, si una clase tiene dos campos de instancia pero uno no está marcado como leído, el objeto al que se puede acceder a través del campo no marcado se excluye del montón de imágenes.
Cuando se encuentra un valor de campo cuya clase no ha sido identificada previamente por el análisis de puntos, la clase se registra como un tipo de campo. Este registro garantiza que en iteraciones posteriores del análisis de puntos de destino, el nuevo tipo se propague a todas las lecturas de campo y usos transitivos en el gráfico de flujo de tipos.
El siguiente fragmento de código describe el algoritmo central para la creación de instantáneas del montón:
Declare List worklist := []
Declare Set reachableObjects := []
Function BuildHeapSnapshot(PointsToState pointsToState)
For Each field in pointsToState.getReachableStaticObjectFields()
Call AddObjectToWorkList(field.readValue())
End For
For Each method in pointsToState.getReachableMethods()
For Each constant in method.embeddedConstants()
Call AddObjectToWorkList(constant)
End For
End For
While worklist.isNotEmpty
Object current := Pop from worklist
If current Object is an Array
For Each value in current
Call AddObjectToWorkList(value)
Add current.getClass() to pointsToState.getObjectArrayTypes()
End For
Else
For Each field in pointsToState.getReachableInstanceObjectFields(current.getClass())
Object value := field.read(current)
Call AddObjectToWorkList(value)
Add value.getClass() to pointsToState.getFieldValueTypes(field)
End For
End If
End While
Return reachableObjects
End Function
En resumen, el algoritmo de instantáneas del montón construye eficientemente una instantánea del montón atravesando sistemáticamente los objetos accesibles y sus campos. Esto garantiza que solo se incluyan objetos relevantes en el montón de imágenes, optimizando el rendimiento y el uso de memoria de la imagen nativa.
Conclusión
En conclusión, el proceso de creación de instantáneas del montón juega un papel fundamental en la creación de imágenes nativas. Al atravesar sistemáticamente los objetos accesibles y sus campos, el algoritmo de instantáneas del montón construye un gráfico de objetos que representa el cierre transitivo de los objetos accesibles a partir de punteros raíz, como los campos estáticos. Este gráfico de objetos luego se incrusta en la imagen nativa como el montón de imágenes, sirviendo como montón inicial al iniciar la imagen nativa.
A lo largo del proceso, el algoritmo se basa en el estado del análisis de puntos para determinar qué objetos y campos son relevantes para su inclusión en el montón de imágenes. Se consideran los objetos y campos marcados como "leídos" por el análisis de puntos, mientras que se excluyen las entidades no marcadas. Además, cuando encuentra tipos nunca antes vistos, el algoritmo los registra para su propagación en iteraciones posteriores del análisis de puntos.
En general, la creación de instantáneas del montón optimiza el rendimiento y el uso de la memoria de las imágenes nativas al garantizar que solo se incluyan los objetos necesarios en el montón de imágenes. Este enfoque sistemático mejora la eficiencia y confiabilidad de la ejecución de imágenes nativas.
-
 ¿Por qué no es una solicitud posterior a capturar la entrada en PHP a pesar del código válido?abordando la solicitud de solicitud de la publicación $ _Server ['php_self'];?> "Método =" post "> [&] la intenci...Programación Publicado el 2025-03-15
¿Por qué no es una solicitud posterior a capturar la entrada en PHP a pesar del código válido?abordando la solicitud de solicitud de la publicación $ _Server ['php_self'];?> "Método =" post "> [&] la intenci...Programación Publicado el 2025-03-15 -
¿Por qué no muestra imágenes de Firefox utilizando la propiedad CSS `Content`?Mostrando imágenes con URL de contenido en Firefox Se ha encontrado un problema cuando ciertos navegadores, específicamente Firefox, no muestr...Programación Publicado el 2025-03-15
-
¿Cómo recuperar eficientemente la última fila para cada identificador único en PostgreSQL?postgresql: extrayendo la última fila para cada identificador único en postgresql, puede encontrar situaciones en las que necesita extraer la ...Programación Publicado el 2025-03-15
-
¿Cómo limitar el rango de desplazamiento de un elemento dentro de un elemento principal de tamaño dinámico?implementando límites de altura de CSS para los elementos de desplazamiento vertical en una interfaz interactiva, controlar el comportamiento ...Programación Publicado el 2025-03-15
-
Python Leer el archivo CSV UnicodeDeCodeError Ultimate Solutionunicode decode error en el archivo csv lectura al intentar leer un archivo csv en python usando el modulo CSV incorporado, (unicodeScal No se ...Programación Publicado el 2025-03-15
-
¿Cómo insertar correctamente las blobs (imágenes) en MySQL usando PHP?Inserte blobs en bases de datos MySQL con php Al intentar almacenar una imagen en una base de datos MySQL, puede encontrar un asunto. Esta gu...Programación Publicado el 2025-03-15
-
¿Se pueden apilar múltiples elementos adhesivos uno encima del otro en CSS puro?¿Es posible tener múltiples elementos pegajosos apilados uno encima del otro en CSS puro? El comportamiento deseado se puede ver Aquí: https...Programación Publicado el 2025-03-15
-
¿Puedo migrar mi cifrado de MCRYPT a OpenSSL y descifrar datos cifrados de MCRYPT usando OpenSSL?actualizando mi biblioteca de cifrado de MCRYP En OpenSSL, ¿es posible descifrar datos encriptados con MCRYPT? Dos publicaciones diferentes propo...Programación Publicado el 2025-03-15
-
¿Existe una diferencia de rendimiento entre usar un bucle for-ENTRES y un iterador para la transmisión de recorrido en Java?para cada bucle vs. iterator: eficiencia en la colección traversal introduction cuando la colección en java, la opción, la opción iba entr...Programación Publicado el 2025-03-15
-
¿Por qué cesan la ejecución de JavaScript cuando se usa el botón de retroceso de Firefox?Problema de historial de navegación: JavaScript deja de ejecutar después de usar el botón de retroceso de Firefox Los usuarios de Firefox pued...Programación Publicado el 2025-03-15
-
¿Por qué Microsoft Visual C ++ no implementa correctamente la instanciación de la plantilla de dos fases?El misterio de la plantilla de dos fases "roto" instanciación en Microsoft Visual c declaración de problemas: usuarios comúnmente ...Programación Publicado el 2025-03-15
-
¿Cómo puedo manejar múltiples cargas de archivos con FormData ()?Manejo de múltiples cargas de archivo con formdata () Cuando se trabaja con entradas de archivos, a menudo es necesario manejar múltiples carg...Programación Publicado el 2025-03-15
-
¿Qué método es más eficiente para la detección de Point-in-Polygon: Ray Tracing o Matplotlib \ 's Rath.Contains_Points?Detección eficiente de Point-in-Polygon en python determinando si un punto se encuentra dentro de un polígono es una tarea frecuente en la geome...Programación Publicado el 2025-03-15
-
¿Cómo eliminar los emojis de las cuerdas en Python: una guía para principiantes para solucionar errores comunes?Eliminación de emojis de las cadenas en python el código de python proporcionado para eliminar emojis falla porque contiene errores de sintaxi...Programación Publicado el 2025-03-15
-
¿Cómo recuperar la última biblioteca jQuery de Google API?recuperando la última biblioteca jQuery de Google APIS La URL de jQuery proporcionada en la pregunta es para la versión 1.2.6. Para recuperar ...Programación Publicado el 2025-03-15















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









