
Cómo descargar e instalar Llama 2 localmente
 Navegar:907
Navegar:907
Con eso en mente, hemos creado una guía paso a paso sobre cómo usar Text-Generation-WebUI para cargar un Llama 2 LLM cuantificado localmente en su computadora.
Por qué instalar Llama 2 localmente
Hay muchas razones por las que las personas eligen ejecutar Llama 2 directamente. Algunos lo hacen por cuestiones de privacidad, otros por personalización y otros por capacidades fuera de línea. Si está investigando, perfeccionando o integrando Llama 2 para sus proyectos, es posible que acceder a Llama 2 a través de API no sea para usted. El objetivo de ejecutar un LLM localmente en su PC es reducir la dependencia de herramientas de inteligencia artificial de terceros y utilizar la inteligencia artificial en cualquier momento y lugar, sin preocuparse por la filtración de datos potencialmente confidenciales a empresas y otras organizaciones.
Dicho esto, comencemos con la guía paso a paso para instalar Llama 2 localmente.
Paso 1: Instalar la herramienta de compilación Visual Studio 2019
Para simplificar las cosas, usaremos un instalador de un solo clic para Text-Generation-WebUI (el programa utilizado para cargar Llama 2 con GUI) . Sin embargo, para que este instalador funcione, debe descargar la herramienta de compilación de Visual Studio 2019 e instalar los recursos necesarios.
Descargar: Visual Studio 2019 (gratis)
Continúe y descargue la edición comunitaria del software. Ahora instale Visual Studio 2019, luego abra el software. Una vez abierto, marque la casilla Desarrollo de escritorio con C y presione instalar.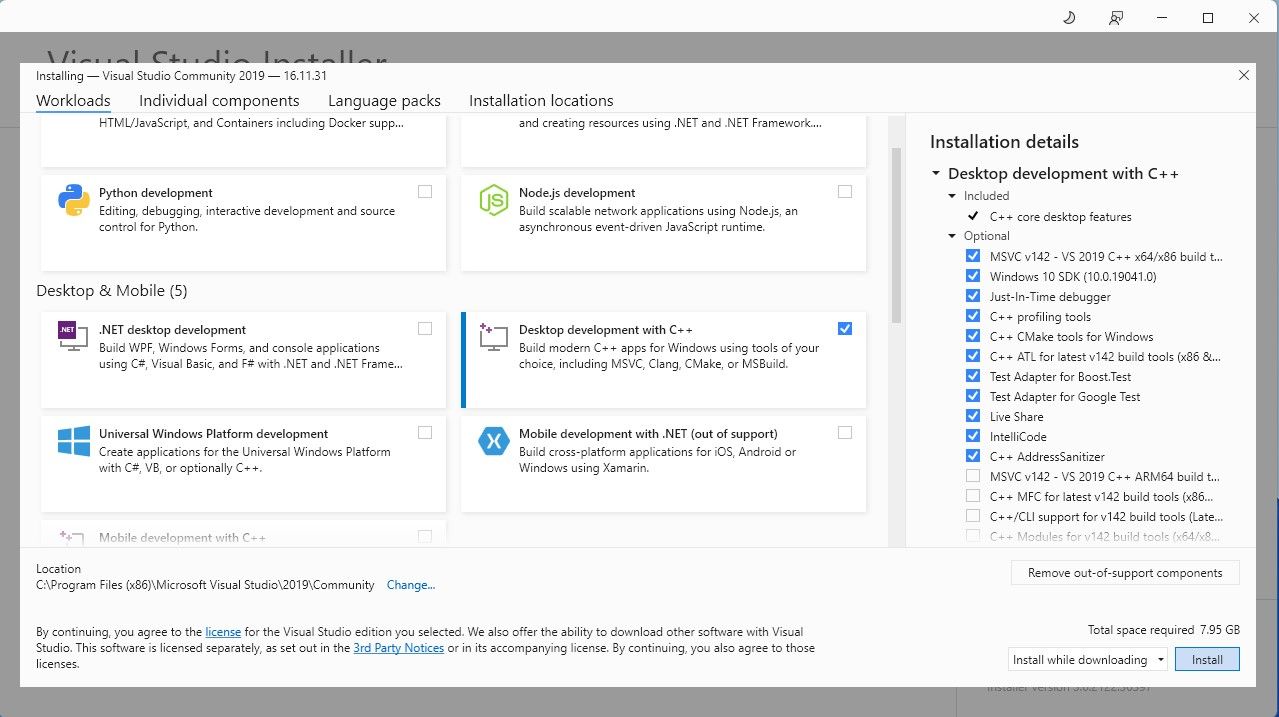
Ahora que tiene instalado el desarrollo de escritorio con C, es hora de descargar el instalador de un solo clic de Text-Generation-WebUI.
Paso 2: Instalar Text-Generation-WebUI
El instalador de un solo clic de Text-Generation-WebUI es un script que crea automáticamente las carpetas necesarias y configura el entorno de Conda y todos los requisitos necesarios para ejecutar un modelo de IA.
Para instalar el script, descargue el instalador de un solo clic haciendo clic en Código > Descargar ZIP.
Descargar: Instalador Text-Generation-WebUI (gratis)
Una vez descargado, extraiga el archivo ZIP en su ubicación preferida y luego abra la carpeta extraída. Dentro de la carpeta, desplácese hacia abajo y busque el programa de inicio apropiado para su sistema operativo. Ejecute los programas haciendo doble clic en el script apropiado. Si está en Windows, seleccione el archivo por lotes start_windows para MacOS, seleccione el script de shell start_macos para Linux, el script de shell start_linux.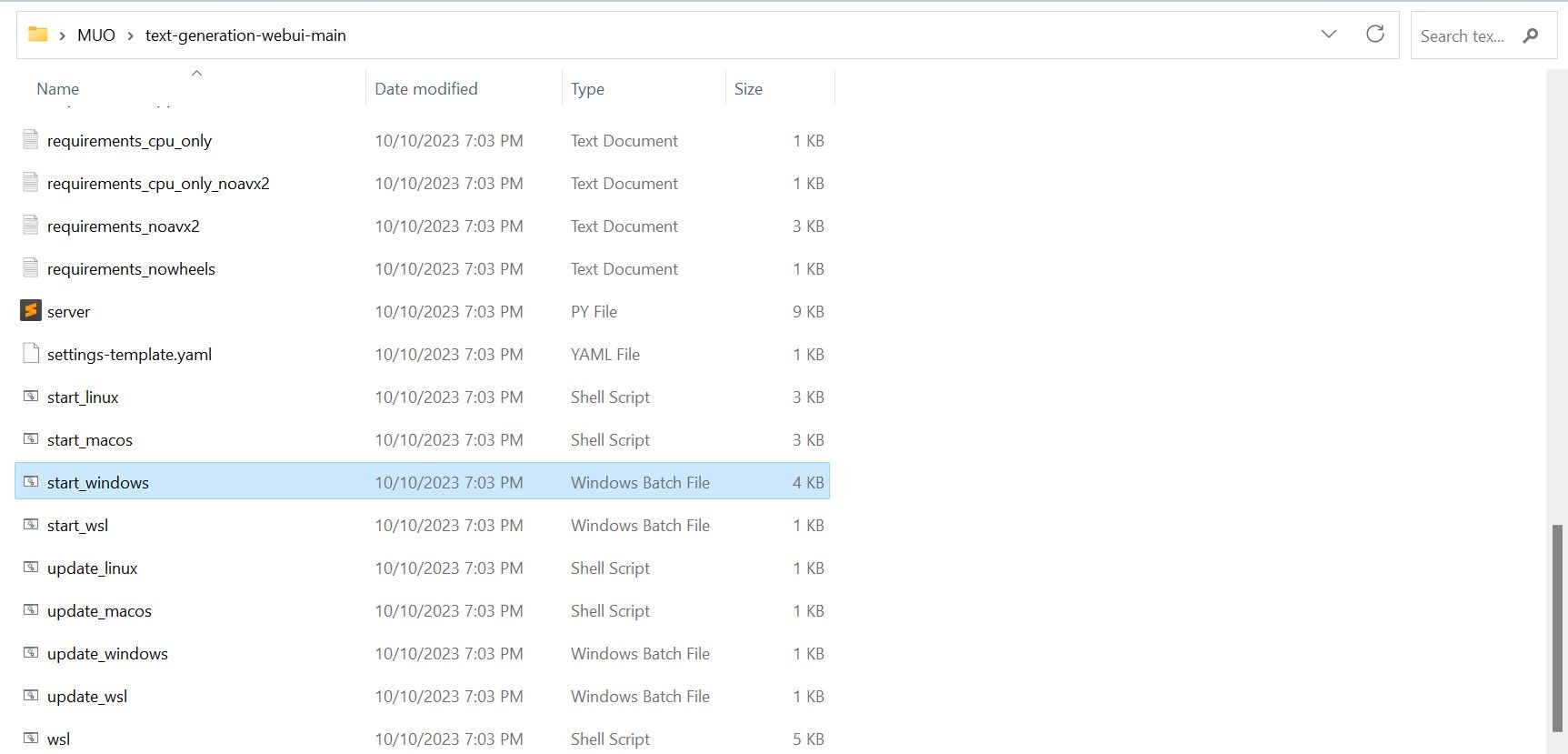
Su antivirus puede crear una alerta; esto está bien. El mensaje es solo un falso positivo del antivirus al ejecutar un archivo por lotes o un script. Haga clic en Ejecutar de todos modos. Se abrirá una terminal e iniciará la configuración. Al principio, la configuración se detendrá y le preguntará qué GPU está utilizando. Seleccione el tipo apropiado de GPU instalado en su computadora y presione Enter. Para aquellos que no tienen una tarjeta gráfica dedicada, seleccione Ninguno (quiero ejecutar modelos en modo CPU). Tenga en cuenta que ejecutar en modo CPU es mucho más lento en comparación con ejecutar el modelo con una GPU dedicada.
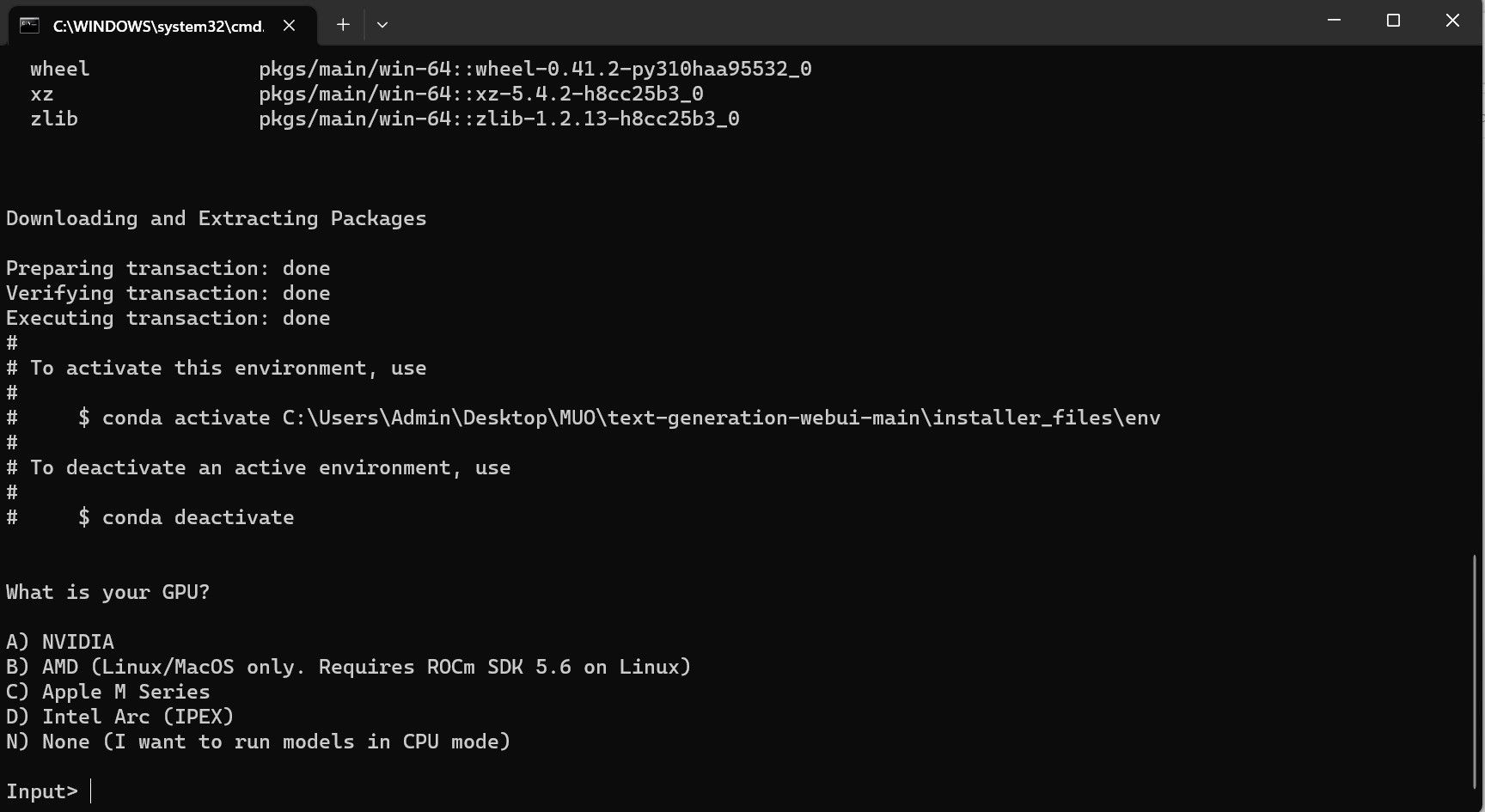 Una vez que se completa la configuración, ahora puede iniciar Text-Generation-WebUI localmente. Puede hacerlo abriendo su navegador web preferido e ingresando la dirección IP proporcionada en la URL.
Una vez que se completa la configuración, ahora puede iniciar Text-Generation-WebUI localmente. Puede hacerlo abriendo su navegador web preferido e ingresando la dirección IP proporcionada en la URL.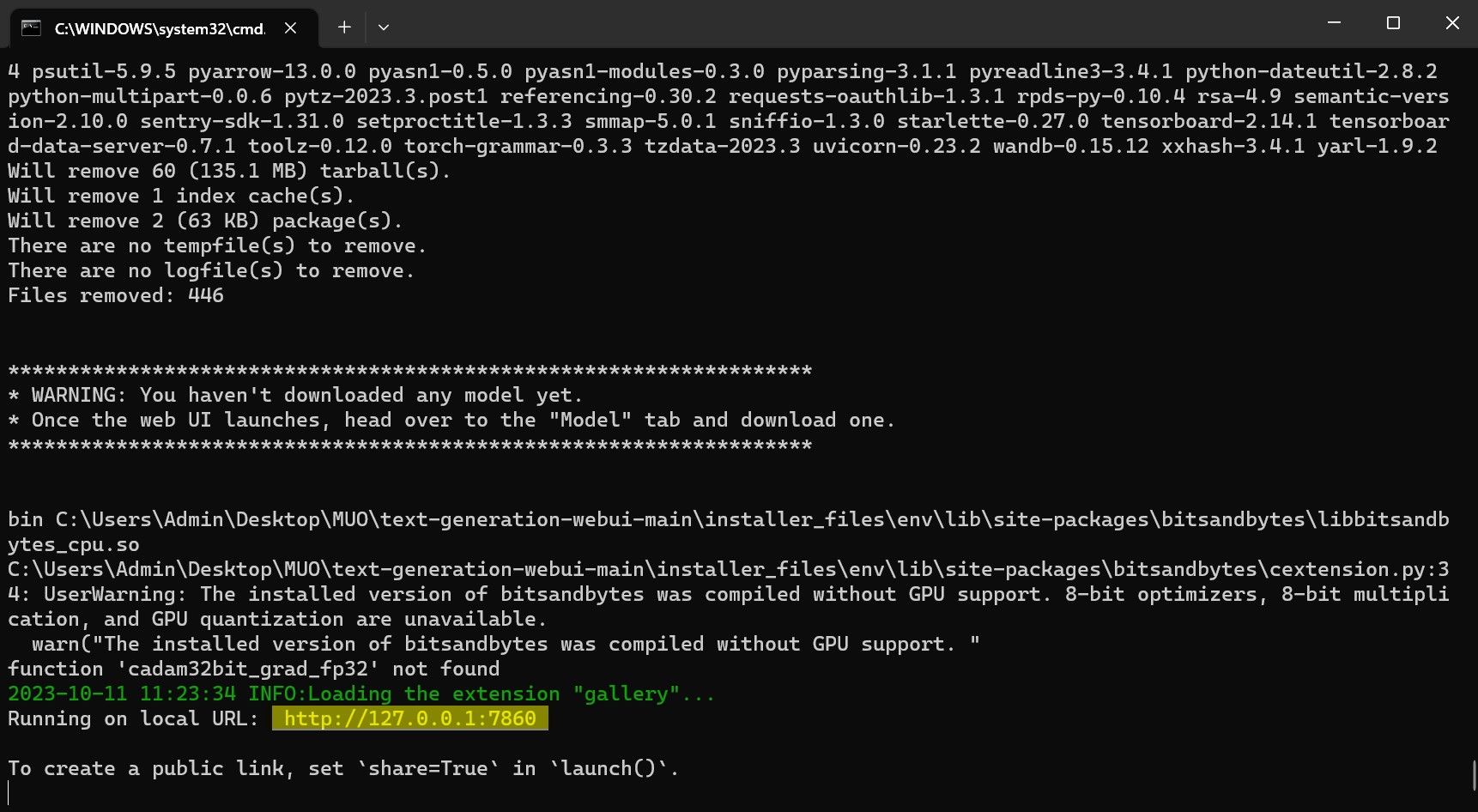 La WebUI ya está lista para su uso.
La WebUI ya está lista para su uso.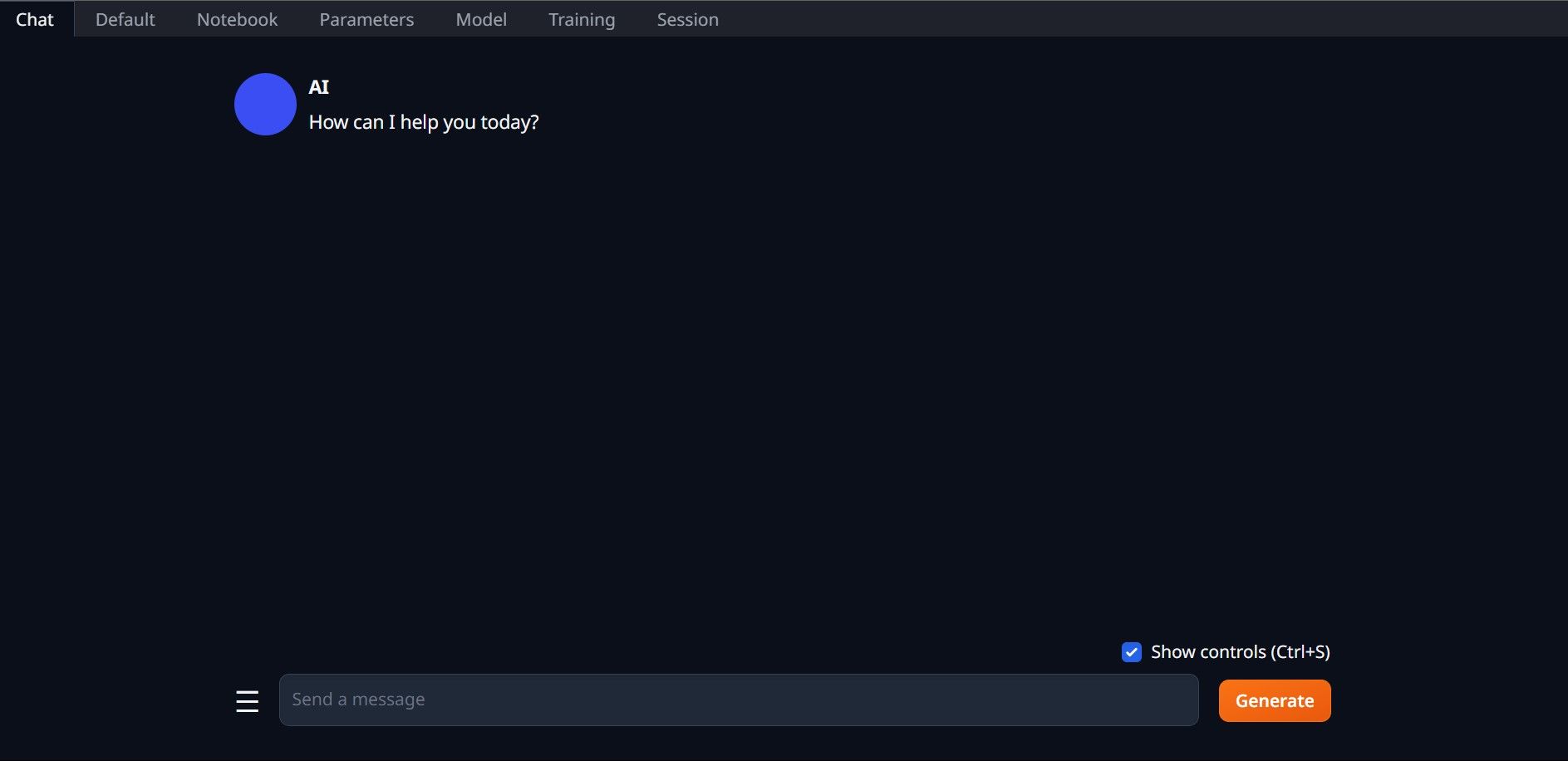
Sin embargo, el programa es solo un cargador de modelos. Descarguemos Llama 2 para que se inicie el cargador de modelos.
Paso 3: Descargue el modelo Llama 2
Hay bastantes cosas a considerar al decidir qué iteración de Llama 2 necesita. Estos incluyen parámetros, cuantificación, optimización de hardware, tamaño y uso. Toda esta información se encontrará indicada en el nombre del modelo.
Parámetros: el número de parámetros utilizados para entrenar el modelo. Los parámetros más grandes hacen que los modelos sean más capaces, pero a costa del rendimiento. Uso: Puede ser estándar o chatear. Un modelo de chat está optimizado para usarse como un chatbot como ChatGPT, mientras que el estándar es el modelo predeterminado. Optimización de hardware: se refiere a qué hardware ejecuta mejor el modelo. GPTQ significa que el modelo está optimizado para ejecutarse en una GPU dedicada, mientras que GGML está optimizado para ejecutarse en una CPU. Cuantización: Denota la precisión de pesos y activaciones en un modelo. Para inferir, una precisión de q4 es óptima. Tamaño: Se refiere al tamaño del modelo específico.Tenga en cuenta que algunos modelos pueden estar organizados de manera diferente y es posible que ni siquiera muestren el mismo tipo de información. Sin embargo, este tipo de convención de nomenclatura es bastante común en la biblioteca de modelos HuggingFace, por lo que aún así vale la pena comprenderla.

En este ejemplo, el modelo se puede identificar como un modelo Llama 2 de tamaño mediano entrenado en 13 mil millones de parámetros optimizados para la inferencia de chat utilizando una CPU dedicada.
Para aquellos que ejecutan una GPU dedicada, elija un modelo GPTQ, mientras que para aquellos que usan una CPU, elija GGML. Si desea chatear con el modelo como lo haría con ChatGPT, elija chatear, pero si desea experimentar con el modelo con todas sus capacidades, use el modelo estándar. En cuanto a los parámetros, sepa que utilizar modelos más grandes proporcionará mejores resultados a expensas del rendimiento. Personalmente, recomendaría que comiences con un modelo 7B. En cuanto a la cuantización, utilice q4, ya que es sólo para inferir.
Descargar:GGML (Gratis)
Descargar:GPTQ (Gratis)
Ahora que sabes qué iteración de Llama 2 necesitas, continúa y descarga el modelo que deseas .
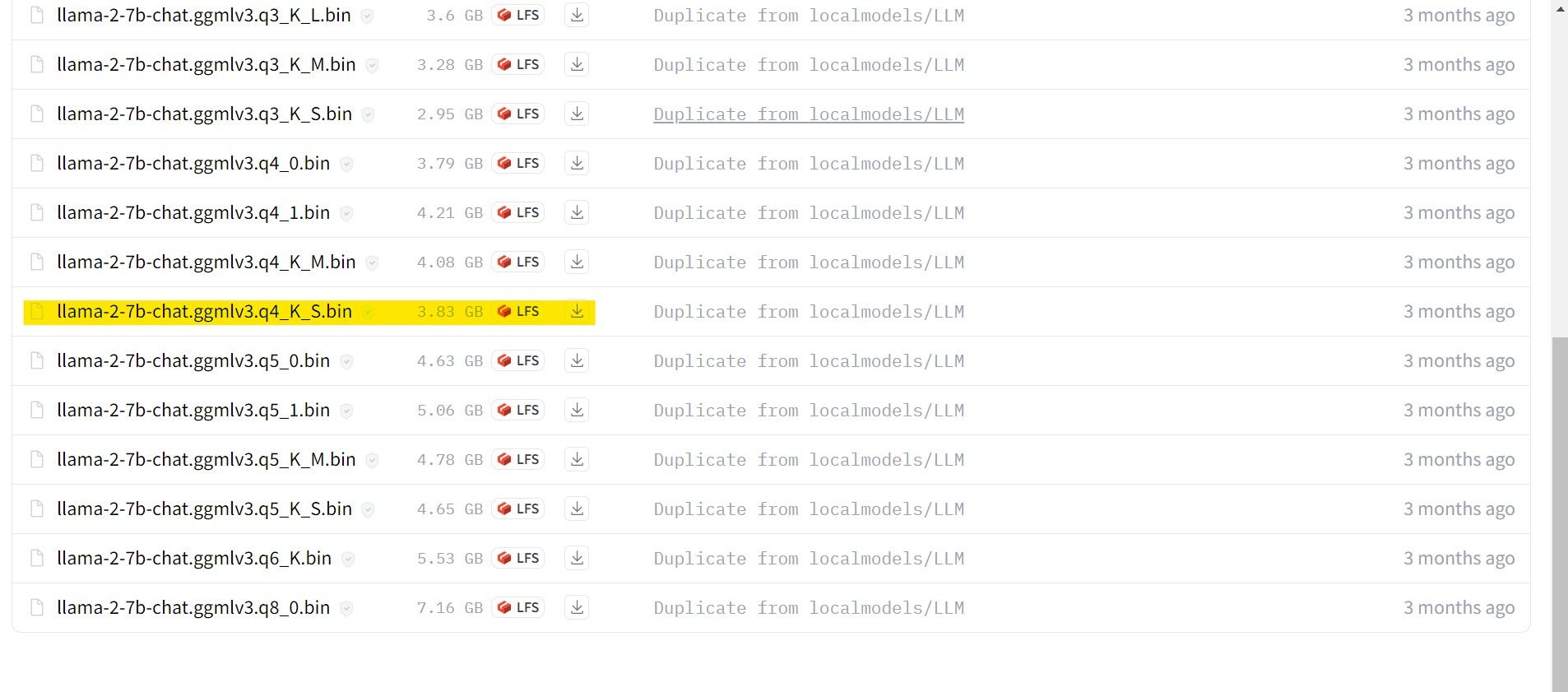
En mi caso, dado que estoy ejecutando esto en una ultrabook, usaré un modelo GGML ajustado para chat, llama-2-7b-chat-ggmlv3.q4_K_S.bin.
Una vez finalizada la descarga, coloque el modelo en text-spawn-webui-main > models.
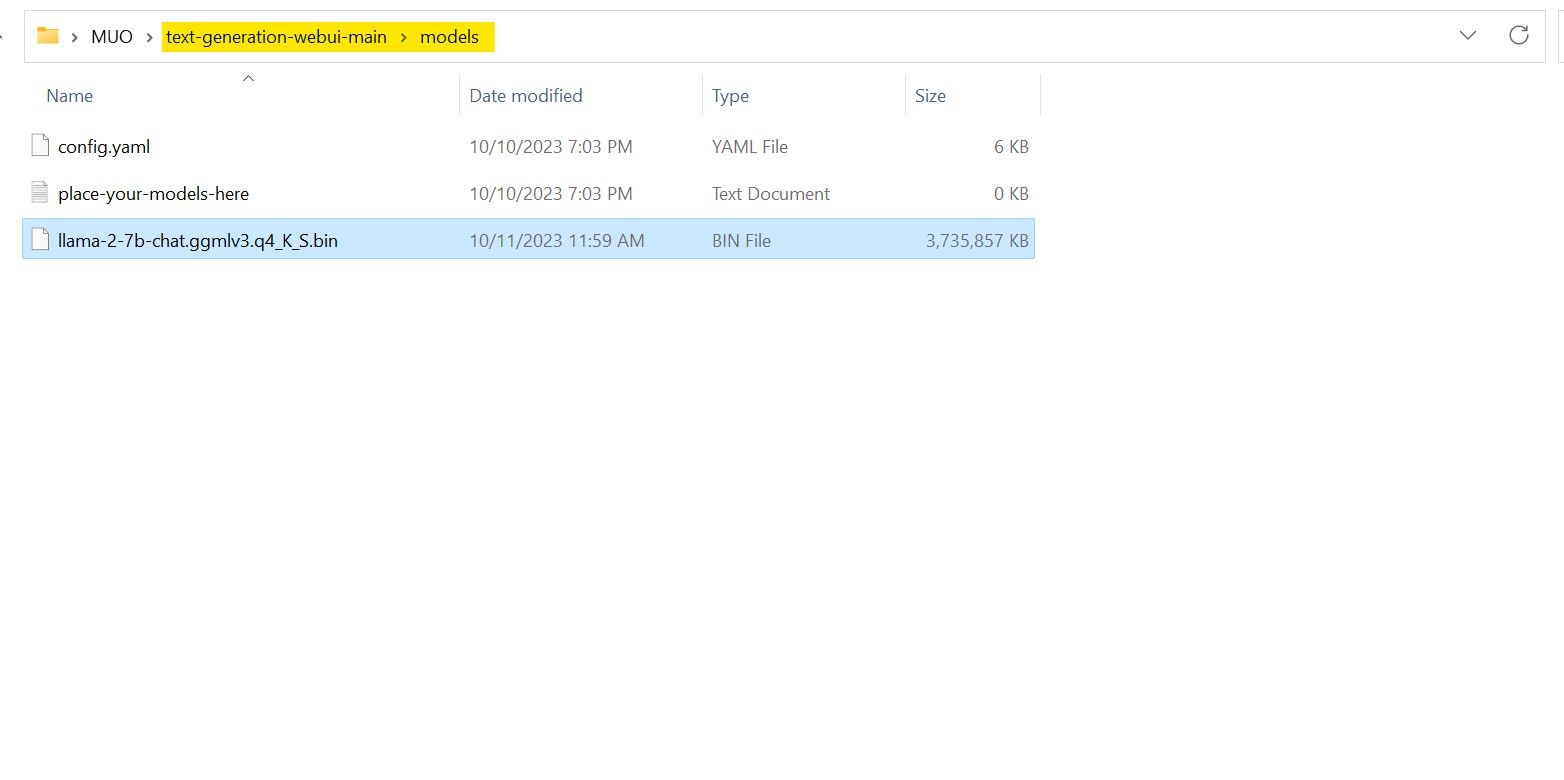
Ahora que ha descargado su modelo y colocado en la carpeta del modelo, es hora de configurar el cargador de modelos.
Paso 4: Configurar la WebUI de generación de texto
Ahora, comencemos la fase de configuración.
Una vez más, abra Text-Generation-WebUI ejecutando el archivo start_(su sistema operativo) (consulte los pasos anteriores anteriores). En las pestañas ubicadas encima de la GUI, haga clic en Modelo. Haga clic en el botón Actualizar en el menú desplegable del modelo y seleccione su modelo. Ahora haga clic en el menú desplegable del cargador de modelos y seleccione AutoGPTQ para aquellos que usan un modelo GTPQ y ctransformers para aquellos que usan un modelo GGML. Finalmente, haga clic en Cargar para cargar su modelo.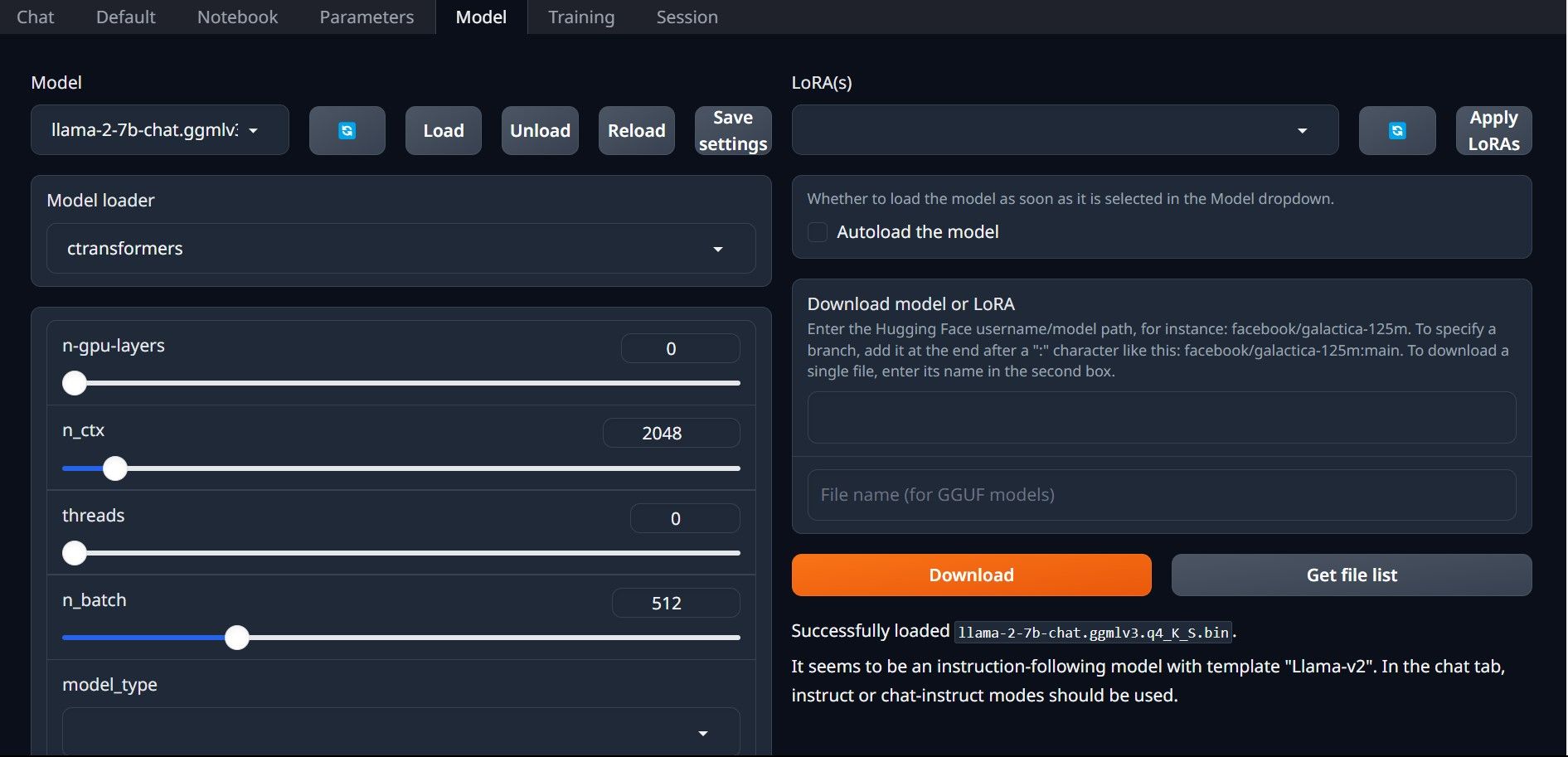 Para usar el modelo, abra la pestaña Chat y comience a probar el modelo.
Para usar el modelo, abra la pestaña Chat y comience a probar el modelo.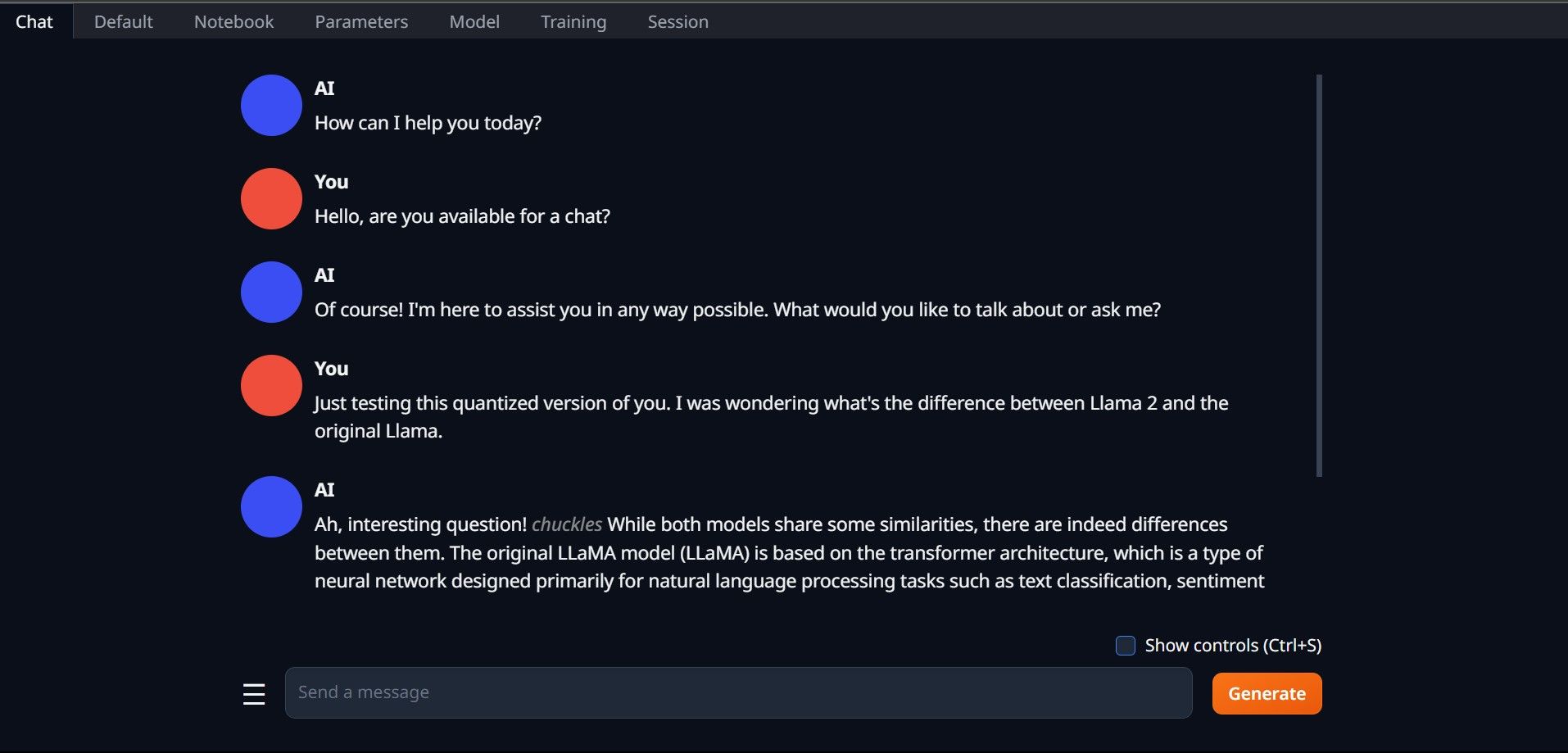
¡Felicitaciones, ha cargado Llama2 exitosamente en su computadora local!
Pruebe otros LLM
Ahora que sabe cómo ejecutar Llama 2 directamente en su computadora usando Text-Generation-WebUI, también debería poder ejecutar otros LLM además de Llama. Sólo recuerde las convenciones de nomenclatura de los modelos y que sólo se pueden cargar versiones cuantificadas de los modelos (normalmente con precisión q4) en las PC normales. Muchos LLM cuantificados están disponibles en HuggingFace. Si desea explorar otros modelos, busque TheBloke en la biblioteca de modelos de HuggingFace y encontrará muchos modelos disponibles.
-
 Deepseek-v3 vs. GPT-4O y Llama 3.3 70b: el modelo de IA más fuerte reveladoThe evolution of AI language models has set new standards, especially in the coding and programming landscape. Leading the c...AI Publicado el 2025-04-18
Deepseek-v3 vs. GPT-4O y Llama 3.3 70b: el modelo de IA más fuerte reveladoThe evolution of AI language models has set new standards, especially in the coding and programming landscape. Leading the c...AI Publicado el 2025-04-18 -
Top 5 Herramientas de presupuesto inteligente de IAdesbloqueando la libertad financiera con AI: aplicaciones de presupuesto superior en India ¿Estás cansado de preguntarte constantemente a dónde va ...AI Publicado el 2025-04-17
-
Explicación detallada de la función de Excel Sumproduct - Escuela de Análisis de DatosFunción Sumproduct de Excel: una potencia de análisis de datos desbloquea la potencia de la función Sumproduct de Excel para el análisis de datos s...AI Publicado el 2025-04-16
-
La investigación en profundidad está completamente abierta, los beneficios del usuario de ChatGPT másInvestigación profunda de Openai: un cambio de juego para AI Research Openai ha desatado una investigación profunda para todos los suscriptores de ...AI Publicado el 2025-04-16
-
Amazon Nova Today Real Experience and Review - Analytics VidhyaAmazon presenta nova: modelos de base de vanguardia para AI y creación de contenido mejoradas El reciente evento de Invent 2024 de Amazon exhibió a...AI Publicado el 2025-04-16
-
5 formas de usar la función de tarea de sincronización de chatgptLas nuevas tareas programadas de Chatgpt: automatizar su día con ai chatgpt recientemente presentó una función de cambio de juego: tareas programad...AI Publicado el 2025-04-16
-
¿Cuál de los tres chatbots de IA responde al mismo aviso es el mejor?con opciones como Claude, ChatGpt y Gemini, elegir un chatbot puede sentirse abrumador. Para ayudar a cortar el ruido, puse los tres a la prueba u...AI Publicado el 2025-04-15
-
Chatgpt es suficiente, no se necesita una máquina de chat de IA dedicadaEn un mundo con nuevos chatbots de IA que se lanzarán a diario, puede ser abrumador decidir cuál es el correcto "uno". Pero en mi experienc...AI Publicado el 2025-04-14
-
Momento de la IA india: competencia con China y Estados Unidos en IA generativaAmbiciones AI de la India: una actualización de 2025 con China y Estados Unidos invirtiendo en gran medida en IA generativa, India está acelerando ...AI Publicado el 2025-04-13
-
Automatizar la importación de CSV a PostgreSQL usando Airflow y DockerEste tutorial demuestra construir una tubería de datos robusta utilizando Apache Airflow, Docker y PostgreSQL para automatizar la transferencia de da...AI Publicado el 2025-04-12
-
Algoritmos de inteligencia de enjambres: implementaciones de tres pythonImagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...AI Publicado el 2025-03-24
-
Cómo hacer que su LLM sea más preciso con el trapo y el ajusteImagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...AI Publicado el 2025-03-24
-
¿Qué es Google Gemini? Todo lo que necesitas saber sobre el rival de chatgpt de GoogleGoogle recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...AI Publicado el 2025-03-23
-
Guía al solicitar con DSPYdspy: un marco declarativo para construir y mejorar las aplicaciones LLM dspy (programas de lenguaje de funcionamiento autoinforme declarativo) rev...AI Publicado el 2025-03-22
-
Automatizar el blog al hilo de TwitterEste artículo Detalles automatizando la conversión de contenido de forma larga (como publicaciones de blog) para involucrar hilos de Twitter utilizan...AI Publicado el 2025-03-11















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









