 Página delantera > Programación > API de datos para Amazon Aurora Serverless con AWS SDK para Java: ¿la parte API vata de Aurora Serverless cumple con DevOps Guru o no?
Página delantera > Programación > API de datos para Amazon Aurora Serverless con AWS SDK para Java: ¿la parte API vata de Aurora Serverless cumple con DevOps Guru o no?
API de datos para Amazon Aurora Serverless con AWS SDK para Java: ¿la parte API vata de Aurora Serverless cumple con DevOps Guru o no?
 Navegar:298
Navegar:298
Introducción
En mi artículo Amazon DevOps Guru para aplicaciones sin servidor: Parte 10 Detección de anomalías en Aurora Serverless v2, aprendimos que DevOps Guru pudo detectar anomalías con éxito con la base de datos PostgreSQL de Aurora (Serverless v2) en el caso de la función Lambda con Java 21 administrado. El tiempo de ejecución se conectó a través de JDBC. Escalamos nuestra base de datos solo de 0,5 a 1 ACU y creamos una carga muy alta en la base de datos al invocar la función Lambda para recuperar el producto por identificación varios cientos de veces simultáneamente durante varios minutos. Vimos que DevOps Guru señaló correctamente la mayor suma de conexiones de bases de datos y la carga constantemente alta de la base de datos (CPU). En este artículo, me gustaría determinar si DevOps Guru detectará la anomalía realizando el mismo experimento pero utilizando Data API para Aurora Serverless v2 con AWS SDK para Java en lugar de JDBC.
Detección de anomalías en Aurora Serverless v2 con API de datos
Veamos nuestra aplicación de muestra y usemos la plantilla SAM para crear infraestructura e implementar la aplicación descrita en la siguiente imagen:
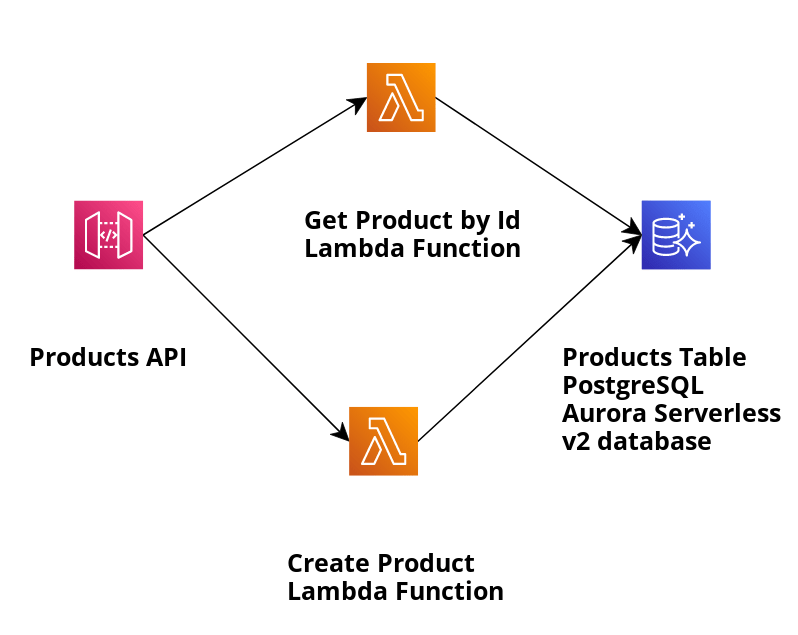
La aplicación crea productos almacenados en la base de datos PostgreSQL de Aurora Serverless v2 y los recupera por identificación mediante Data API. La función Lambda relevante que usaremos para recuperar el producto por su ID es GetProductByIdViaAuroraServerlessV2DataApi y la implementación de su controlador es GetProductByIdViaAuroraServerlessV2DataApiHandler.
Como en el artículo anterior utilizamos la herramienta Hey para realizar la prueba de estrés como esta
hey -z 15m -c 300 -H "X-API-Key: XXXa6XXXX" https://XXX.execute-api.eu-central-1.amazonaws.com/prod/productsWithDataApi/1
En este ejemplo, invocamos el punto final de API Gateway con 300 contenedores simultáneos durante 15 minutos. Detrás del punto final prod/productsWithoutDataApi, se invocará la función Lambda GetProductByIdViaAuroraServerlessV2WithoutDataApi, que recuperará el producto por ID 1 de la base de datos PostgreSQL de Aurora Serverless v2.
Configuramos en nuestra [plantilla SAM]((https://github.com/Vadym79/AWSLambdaJavaAuroraServerlessV2DataApi/blob/master/template.yaml) el clúster de base de datos Aurora para escalar desde una capacidad mínima de 0,5 a una capacidad máxima de 1 ACU (que es tamaño de base de datos muy pequeño) en caso de aumentar la carga con el fin de ahorrar costos.
AuroraServerlessV2Cluster:
Type: 'AWS::RDS::DBCluster'
...
ServerlessV2ScalingConfiguration:
MinCapacity: 0.5
MaxCapacity: 1
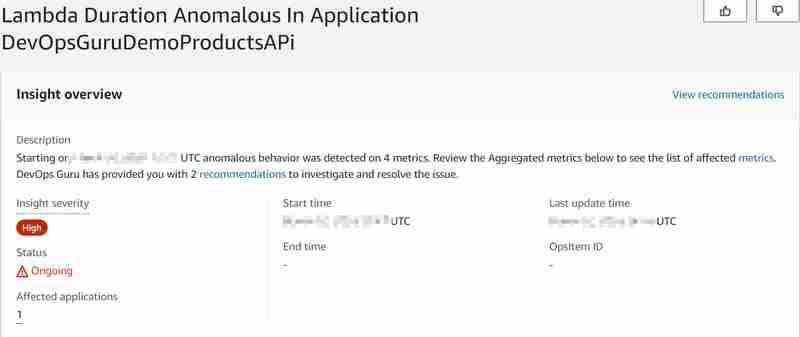
La base de datos Aurora (Serverless v2) administra el número máximo de conexiones de base de datos disponibles proporcionalmente al tamaño de la base de datos (en nuestro caso, la configuración de ACU) también con Data API para Aurora Serverless v2 (que es una gran diferencia con la v1, que se convertirá en sin soporte a finales del año 2024, donde había una cuota estricta de 1000 conexiones de bases de datos por segundo). Para obtener más información, lea la documentación sobre Conexiones máximas para Aurora Serverless v2. Por lo tanto, con el mayor número de invocaciones, esperamos alcanzar pronto el número máximo de conexiones de base de datos disponibles y una alta carga de base de datos (CPU), por lo que la base de datos no podrá responder a las nuevas solicitudes de la función Lambda para recuperar el producto por id (entonces Lambda también se encontrará). Con eso provocaremos la anomalía y nos gustaría saber si DevOps Guru podrá detectarla. Y fue capaz, más o menos... Se generó la siguiente información:
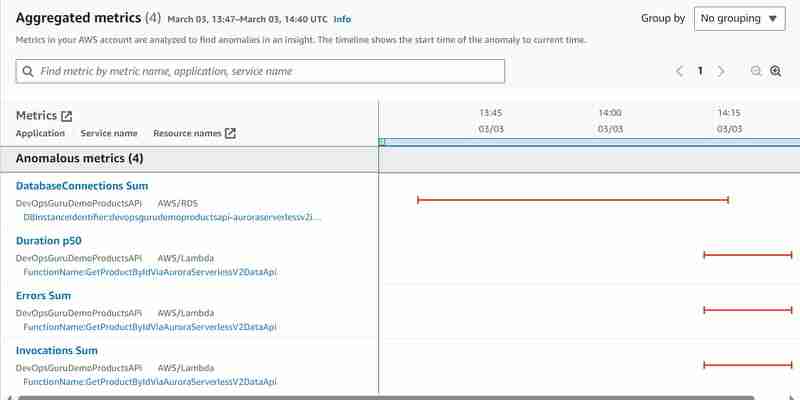
Y se han identificado las siguientes métricas anómalas agregadas:
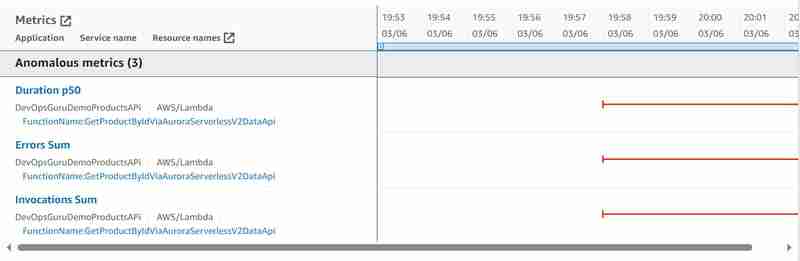
En comparación con las métricas anómalas agregadas identificadas en caso de usar JDBC en lugar de Data API descritas en mi artículo Amazon DevOps Guru para aplicaciones sin servidor - Parte 10 Detección de anomalías en Aurora Serverless v2, desordenamos por completo las métricas anómalas de la base de datos de Aurora: conexión de la base de datos La suma y la base de datos (CPU) se cargan, pero veo correctamente el error en Lambda que se ejecutó en el tiempo definido de 15 segundos porque la base de datos no pudo. responder.
 .
.
Entonces, ¿cuál es la diferencia? Exploremos los dos incidentes que reproducimos en el clúster PostgreSQL de Aurora Serverless v2 con JDBC (API sin datos) y API de datos:
En términos de utilización/escalamiento de ACU, ambos tienen el mismo aspecto:
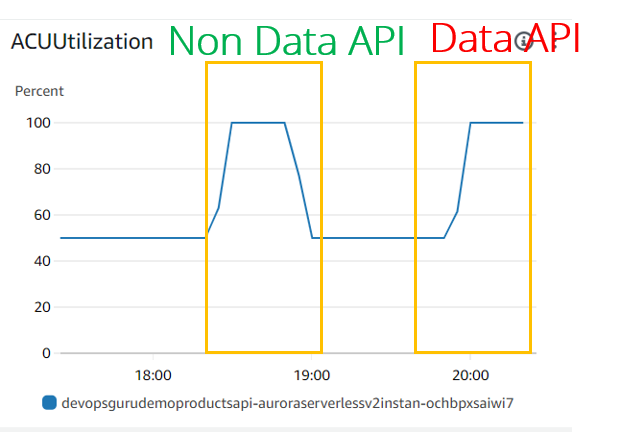
En términos de otras métricas de bases de datos como: utilización de CPU, carga de DB de conexión de base de datos (CPU), existen grandes diferencias:
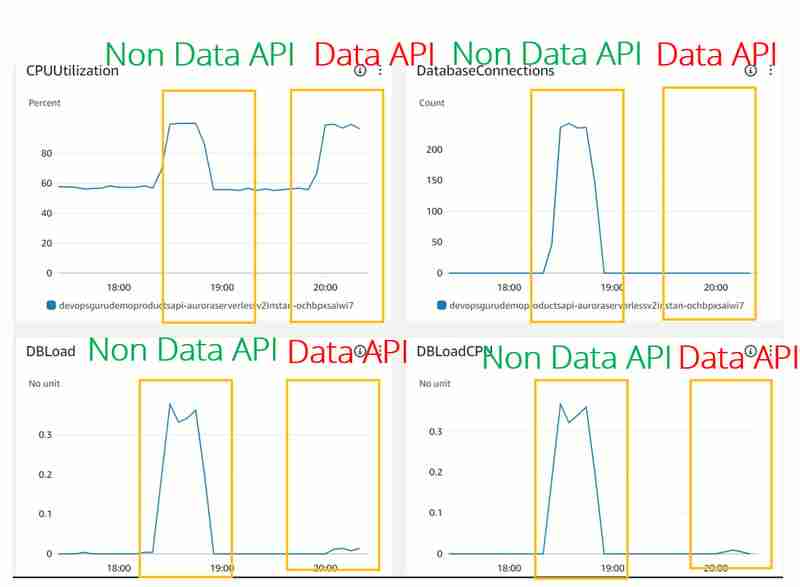
- La utilización de la CPU tiene el mismo aspecto para los casos de JDBC (API sin datos) y API de datos. Pero DevOps Guru parece no considerar esta métrica, ya que no la vimos ni siquiera en el experimento JDBC
- DBLoad(CPU), que es muy bajo para el uso de la API de datos. Parece que para Dat API hay algún Load Balancer frente a la base de datos Aurora Serverless v2 que monitorea el uso de la conexión y protege la base de datos contra sobrecargas.
- La métrica de conexión de base de datos no se muestra (o se muestra como 0) para el uso de la API de datos. La razón de esto es que no administramos la conexión de la base de datos para la API de datos, se hace en el otro lado por nosotros. Por supuesto, todavía juegan un papel importante que aprendimos en Conexiones máximas para Aurora Serverless v2, pero esta métrica parece estar expuesta al exterior en CloudWatch Metrics e incluso DevOps Guru no tiene ningún acceso a los números reales.
Con eso y una DBLoad (CPU) muy baja, no se ha generado información de DevOps Guru para el clúster Aurora Serverless v2 con uso de API de datos en comparación con el caso de uso de JDBC.
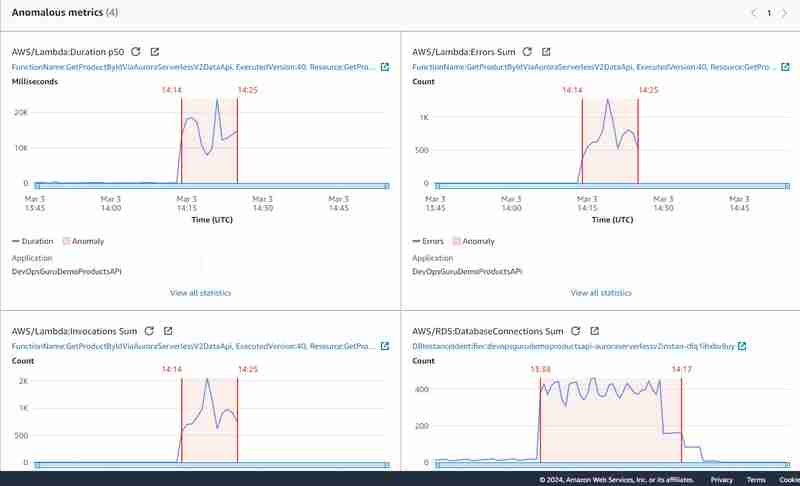
Hice el segundo experimento conectándome directamente al clúster Aurora Serverless v2 y escribí el script para crear la prueba de carga escribiendo el script que recupera el producto por identificación cientos de veces usando la forma estándar (API sin datos). Similar a lo que hicimos con la herramienta hey, pero accediendo a la base de datos directamente en lugar de invocar Api Gateway. Después de cargar la base de datos, comencé el mismo experimento con la herramienta hey como se describe anteriormente y quería ver qué pasaba. Se generó la misma información, pero esta vez con las siguientes métricas anómalas:
Ahora vemos al menos una métrica anómala de suma de conexión de base de datos Aurora Serverless v2 adicional, pero aún faltan métricas DBLoad(CPU).
Las anomalías gráficas se ven así:
Por supuesto, el experimento no fue limpio, ya que hice 2 pruebas de carga una tras otra y parcialmente en paralelo: la primera conectándose a la base de datos directamente sin el uso de API Gateway y la segunda usando Data API. Esto confirmó mi suposición inicial de que las métricas de suma de conexiones de bases de datos son un criterio muy importante para generar información de DevOps Guru para Aurora Serverless v2 (y para RDS en general) y no se exponen en general en caso de usar Data API.
Ya me comuniqué con el equipo de Devops Guru y compartí con ellos mis conocimientos con la expectativa de que mejoren el servicio. O, en primer lugar, exponer la conexión de la base de datos como métrica de CloudWatch se solucionará para el uso de Aurora Serverless v2 con API de datos.
Conclusión
En este artículo, aprendí que DevOps Guru podía detectar anomalías con éxito con la base de datos PostgreSQL Aurora (Serverless v2) en el caso de la función Lambda con el tiempo de ejecución administrado de Java 21 conectado a través de Data API, pero solo podía mostrar las métricas anómalas relacionadas con la función Lambda. se agotó el tiempo de espera porque la base de datos no respondió. La razón principal de esto parece ser que la conexión de la base de datos como métrica de CloudWatch no está expuesta (o siempre se muestra como 0) en caso de utilizar Aurora Serverless v2 con Data API. Las métricas de la base de datos de Aurora Serverless v2 (suma de conexiones de la base de datos) solo se mostraron durante el segundo experimento artificial.
-
 ¿Cómo combino dos matrices asociativas en PHP manteniendo ID únicas y manejando nombres duplicados?Combinando matrices asociativas en PHPEn PHP, combinar dos matrices asociativas en una sola matriz es una tarea común. Considere la siguiente solicitu...Programación Publicado el 2024-11-19
¿Cómo combino dos matrices asociativas en PHP manteniendo ID únicas y manejando nombres duplicados?Combinando matrices asociativas en PHPEn PHP, combinar dos matrices asociativas en una sola matriz es una tarea común. Considere la siguiente solicitu...Programación Publicado el 2024-11-19 -
¿Cómo solucionar \"Configurado incorrectamente: Error al cargar el módulo MySQLdb\" en Django en macOS?MySQL configurado incorrectamente: el problema con las rutas relativasAl ejecutar python Manage.py RunServer en Django, puede encontrar el siguiente e...Programación Publicado el 2024-11-19
-
FormaciónLos métodos son fns que se pueden invocar en objetos Los arreglos son objetos, por lo tanto también tienen métodos en JS. segmento (comienzo):...Programación Publicado el 2024-11-19
-
¿Puedo conducir? Codificación de un alcoholímetroEn Dinamarca, donde vivo, desgraciadamente tenemos un récord en Europa: nuestros hijos son los mayores bebedores de alcohol del continente. Debido a e...Programación Publicado el 2024-11-18
-
¿Por qué mi inserción de Python MySQL no funciona?La inserción de MySQL en Python no funcionaEn Python, utilizar la API de MySQL para conectarse a una base de datos MySQL es un enfoque popular. Sin em...Programación Publicado el 2024-11-18
-
Uso de WebSockets en Go para comunicación en tiempo realCrear aplicaciones que requieran actualizaciones en tiempo real, como aplicaciones de chat, notificaciones en vivo o herramientas colaborativas, requi...Programación Publicado el 2024-11-18
-
Solucionando el error "No se puede utilizar la declaración de importación fuera de un módulo"Como desarrolladores de JavaScript y TypeScript, a menudo nos encontramos con errores inesperados al trabajar con diferentes sistemas de módulos. Un p...Programación Publicado el 2024-11-18
-
¿Cómo conectarse a un contenedor Docker MySQL desde Localhost?Conectarse al contenedor Docker MySQL desde LocalhostPara interactuar con una instancia de MySQL que se ejecuta dentro de un contenedor Docker directa...Programación Publicado el 2024-11-18
-
¿Cómo definir relaciones de amistad en clases de plantilla con diferentes argumentos de plantilla?Profundizando en las plantillas de clase con amigos de clase de plantillaAl definir una clase de árbol binario (BT) y su clase de elemento (BE), es Es...Programación Publicado el 2024-11-18
-
Más allá de las declaraciones "if": ¿dónde más se puede utilizar un tipo con una conversión "bool" explícita sin conversión?Conversión contextual a bool permitida sin conversiónSu clase define una conversión explícita a bool, lo que le permite usar su instancia 't' ...Programación Publicado el 2024-11-18
-
## Creación de un backend CMS robusto: ¿Cómo pueden la estructura OOP y MVC mejorar la gestión de proyectos?Marco central PHP OOP: implementación de una base sólida para un backend CMSComprender la programación orientada a objetos (OOP) es crucial al desarro...Programación Publicado el 2024-11-18
-
¿Cómo se implementa std::string y en qué se diferencia de las cadenas de estilo C?Una exploración de la implementación de std::stringEl enigmático std::string, un componente fundamental de la biblioteca estándar de C, ha provocado c...Programación Publicado el 2024-11-18
-
¿Por qué (0 < 5 < 3) se evalúa como verdadero en JavaScript?El enigma comparativo de JavaScript: descifrar la verdad interna (0 < 5 < 3)En el ámbito de JavaScript, surge una observación peculiar: ¿Por qué la ex...Programación Publicado el 2024-11-18
-
¿Por qué la solicitud POST no captura la entrada en PHP a pesar del código válido?Solucionar el mal funcionamiento de la solicitud POST en PHPEn el fragmento de código presentado:action=''en lugar de:action="<?php echo $_SER...Programación Publicado el 2024-11-18
-
¿Qué pasó con la compensación de columnas en Bootstrap 4 Beta?Bootstrap 4 Beta: eliminación y restauración del desplazamiento de columnasBootstrap 4, en su versión Beta 1, introdujo cambios significativos en la f...Programación Publicado el 2024-11-18















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









