 Página delantera > Programación > Cómo convertir archivos PDF a Markdown usando PyMuPDFM y su evaluación
Página delantera > Programación > Cómo convertir archivos PDF a Markdown usando PyMuPDFM y su evaluación
Cómo convertir archivos PDF a Markdown usando PyMuPDFM y su evaluación
 Navegar:209
Navegar:209
PyMuPDF4LLM es una biblioteca diseñada para convertir archivos PDF al formato Markdown. Aquí compartiré mi experiencia al probar esta biblioteca.
Instalación
Comience instalando la biblioteca usando el siguiente comando:
pip install pymupdf4llm
Uso
El uso básico es bastante simple y requiere solo tres líneas de código para convertir un PDF a Markdown:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("input.pdf")
print(md_text)
Puedes especificar argumentos para ajustar cómo se extrae el contenido.
Extraer texto por página
De forma predeterminada, el PDF completo se convierte en una única salida de texto. Sin embargo, puede extraer texto página por página especificando page_chunks=True.
md_text = pymupdf4llm.to_markdown("input.pdf", page_chunks=True)
Extrayendo imágenes
Para extraer imágenes como archivos, use la opción write_images=True:
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
También es posible incrustar imágenes directamente en Markdown usando codificación base64:
md_text = pymupdf4llm.to_markdown("input.pdf", embed_images=True)
Evaluación de los resultados de la conversión
Para las pruebas, se utilizaron varios archivos PDF con diferentes elementos de Markdown.

Conversión de encabezado
Los encabezados se convierten correctamente al formato Markdown. Aquí está una parte del resultado:
# Sample Markdown Guide This is a sample markdown file that includes various features for quick reference. ## 1. Headers ... ## 3. Lists
Texto en negrita y cursiva
El formato de negrita y cursiva también se convierte correctamente:
**Bold: **Bold Text**** _Italic: *Italic Text*_ **_Bold and Italic: ***Bold and Italic***_**
Conversión de lista
Las listas ordenadas en el primer nivel se convierten sin problemas, pero las listas anidadas y las listas desordenadas no se convierten con precisión.
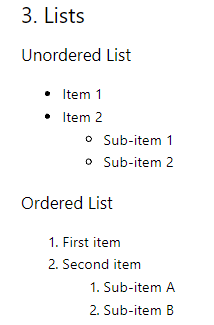
## 3. Lists ### Unordered List Item 1 Item 2 Sub-item 1 Sub-item 2 ### Ordered List 1. First item 2. Second item 1. Sub-item A 2. Sub-item B
Conversión de enlaces
Las URL de los enlaces se extraen, pero toda la línea que contiene el enlace se convierte en un hipervínculo, desviándose del formato original.
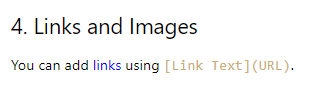
## 4. Links and Images [You can add links using [Link Text](URL).](https://www.example.com/)
Extracción de imágenes
Las imágenes no se extraen de forma predeterminada, pero se pueden guardar localmente con write_images=True.
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
Las imágenes guardadas luego se hacen referencia en Markdown de la siguiente manera:
### Image Example

Conversión de tabla
Las tablas simples sin bordes verticales no se convierten con precisión (probablemente porque los límites de columna ambiguos hacen que las tablas se traten como texto sin formato).

## 5. Tables
**Column 1** **Column 2** **Column 3**
Row 1 Data A Data B
Row 2 Data C Data D
Conversión de código
Los bloques de código se convierten correctamente, pero la especificación del idioma (por ejemplo, Python) no se conserva. La conversión de código en línea también presenta problemas.

## 6. Code
### Inline Code
Use backticks for inline code: print("Hello, world!")
### Code Block
Use triple backticks for code blocks:
```
def greet(name):
return f"Hello, {name}!"
print(greet("Markdown"))
```
Texto de varias líneas
Para texto de varias líneas, los saltos de línea se conservan tal como aparecen en el PDF original.

Markdown is a lightweight and versatile markup language favored by developers, writers, and bloggers alike
due to its simplicity in formatting text, enabling users to create readable and well-structured documents—
whether for documentation, blog posts, or articles—without the complexity of HTML, while also offering the
ability to convert content seamlessly into other formats like HTML, PDF, and even slideshows, making it an
ideal choice for projects that require both clarity and flexibility in presentation.
Conclusión
A pesar de los desafíos para convertir listas y enlaces con precisión, PyMuPDF4LLM es una herramienta útil para convertir archivos PDF a Markdown. Puede funcionar localmente sin necesidad de modelos de lenguaje externos, lo que lo hace adecuado para entornos donde el acceso a Internet no está disponible.
-
 ¿Cómo puedo iterar e imprimir sincrónicamente los valores de dos matrices de igual tamaño en PHP?iterando e imprimiendo los valores de dos matrices del mismo tamaño cuando se crea un Selectbox usando dos matrices de igual tamaño, uno que con...Programación Publicado el 2025-04-06
¿Cómo puedo iterar e imprimir sincrónicamente los valores de dos matrices de igual tamaño en PHP?iterando e imprimiendo los valores de dos matrices del mismo tamaño cuando se crea un Selectbox usando dos matrices de igual tamaño, uno que con...Programación Publicado el 2025-04-06 -
¿Necesito eliminar explícitamente las asignaciones de montón en C ++ antes de la salida del programa?deleción explícita en c a pesar de la salida del programa cuando trabajan con la asignación de memoria dinámica en c, los desarrolladores a me...Programación Publicado el 2025-04-06
-
¿Cómo implementar una función hash genérica para tuplas en colecciones desordenadas?Función hash genérica para tuplas en colecciones no ordenadas los contenedores std :: unordened_map y std :: unordened_set proporcionan una mi...Programación Publicado el 2025-04-06
-
¿Cómo puedo manejar los nombres de archivo UTF-8 en las funciones del sistema de archivos de PHP?manejando los nombres de archivo UTF-8 en las funciones del sistema de archivos de PHP al crear carpetas que contienen caracteres UTF-8 utiliz...Programación Publicado el 2025-04-06
-
¿Cómo puedo generar eficientemente las babosas amigables con la URL a partir de cuerdas Unicode en PHP?elaborando una función para una generación de babosas eficiente creando babosas, representaciones simplificadas de las cadenas unicode utiliza...Programación Publicado el 2025-04-06
-
¿Por qué no `cuerpo {margen: 0; } `¿Siempre elimina el margen superior en CSS?abordando la eliminación del margen del cuerpo en css para desarrolladores web novatos, eliminar el margen del elemento corporal puede ser una...Programación Publicado el 2025-04-06
-
¿Por qué no aparece mi imagen de fondo CSS?Solución de problemas: css La imagen de fondo que no aparece ha encontrado un problema en el que su imagen de fondo no se carga a pesar de las...Programación Publicado el 2025-04-06
-
¿Cómo puedo unir tablas de bases de datos con diferentes números de columnas?tablas combinadas con diferentes columnas ]] puede encontrar desafíos al intentar fusionar las tablas de la base de datos con diferentes column...Programación Publicado el 2025-04-06
-
FormaciónLos métodos son fns que se pueden llamar a los objetos Las matrices son objetos, por lo tanto, también tienen métodos en js. Slice (Begi...Programación Publicado el 2025-04-06
-
¿Cómo convertir eficientemente las zonas horarias en PHP?Conversión de zona horaria eficiente en php en PHP, el manejo de las zonas horarias puede ser una tarea directa. Esta guía proporcionará un méto...Programación Publicado el 2025-04-06
-
¿Cómo puede usar los datos de Group by para pivotar en MySQL?pivotando resultados de consulta usando el grupo mySQL mediante en una base de datos relacional, los datos giratorios se refieren al reorganiz...Programación Publicado el 2025-04-06
-
¿Se pueden apilar múltiples elementos adhesivos uno encima del otro en CSS puro?¿Es posible tener múltiples elementos pegajosos apilados uno encima del otro en CSS puro? El comportamiento deseado se puede ver Aquí: https...Programación Publicado el 2025-04-06
-
¿Cómo analizar los números en notación exponencial usando decimal.parse ()?analizando un número de la notación exponencial cuando intenta analizar una cadena expresada en notación exponencial usando decimal.parse (&qu...Programación Publicado el 2025-04-06
-
¿Cómo limitar el rango de desplazamiento de un elemento dentro de un elemento principal de tamaño dinámico?implementando límites de altura de CSS para los elementos de desplazamiento vertical en una interfaz interactiva, controlar el comportamiento ...Programación Publicado el 2025-04-06
-
¿Cómo selecciono de manera eficiente columnas en Pandas Dataframes?seleccionando columnas en Pandas Dataframes cuando se trata de tareas de manipulación de datos, se hace necesario seleccionar columnas específ...Programación Publicado el 2025-04-06















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









