 Página delantera > Programación > Creación de un sistema de búsqueda semántica rápido y eficiente utilizando OpenVINO y Postgres
Página delantera > Programación > Creación de un sistema de búsqueda semántica rápido y eficiente utilizando OpenVINO y Postgres
Creación de un sistema de búsqueda semántica rápido y eficiente utilizando OpenVINO y Postgres
 Navegar:549
Navegar:549

Foto de real-napster en Pixabay
En uno de mis proyectos recientes, tuve que crear un sistema de búsqueda semántica que pudiera escalar con un alto rendimiento y ofrecer respuestas en tiempo real para búsquedas de informes. Usamos PostgreSQL con pgvector en AWS RDS, junto con AWS Lambda, para lograr esto. El desafío era permitir a los usuarios realizar búsquedas mediante consultas en lenguaje natural en lugar de depender de palabras clave rígidas, y al mismo tiempo garantizar que las respuestas duraran menos de 1 o 2 segundos o incluso menos y solo pudieran aprovechar los recursos de la CPU.
En esta publicación, explicaré los pasos que seguí para crear este sistema de búsqueda, desde la recuperación hasta la reclasificación, y las optimizaciones realizadas con OpenVINO y el procesamiento por lotes inteligente para la tokenización.
Descripción general de la búsqueda semántica: recuperación y reclasificación
Los sistemas de búsqueda modernos de última generación generalmente constan de dos pasos principales: recuperación y reclasificación.
1) Recuperación: El primer paso implica recuperar un subconjunto de documentos relevantes según la consulta del usuario. Esto se puede hacer utilizando modelos de incrustaciones previamente entrenados, como las incrustaciones pequeñas y grandes de OpenAI, los modelos Embed de Cohere o las incrustaciones mxbai de Mixbread. La recuperación se centra en reducir el conjunto de documentos midiendo su similitud con la consulta.
Aquí hay un ejemplo simplificado que utiliza la biblioteca de transformadores de oraciones de Huggingface para la recuperación, que es una de mis bibliotecas favoritas para esto:
from sentence_transformers import SentenceTransformer
import numpy as np
# Load a pre-trained sentence transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# Sample query and documents (vectorize the query and the documents)
query = "How do I fix a broken landing gear?"
documents = ["Report 1 on landing gear failure", "Report 2 on engine problems"]
# Get embeddings for query and documents
query_embedding = model.encode(query)
document_embeddings = model.encode(documents)
# Calculate cosine similarity between query and documents
similarities = np.dot(document_embeddings, query_embedding)
# Retrieve top-k most relevant documents
top_k = np.argsort(similarities)[-5:]
print("Top 5 documents:", [documents[i] for i in top_k])
2) Reclasificación: Una vez que se han recuperado los documentos más relevantes, mejoramos aún más la clasificación de estos documentos utilizando un modelo codificador cruzado. Este paso reevalúa cada documento en relación con la consulta con mayor precisión, enfocándose en una comprensión contextual más profunda.
Reclasificar es beneficioso porque agrega una capa adicional de refinamiento al calificar la relevancia de cada documento con mayor precisión.
Aquí hay un ejemplo de código para reclasificar usando cross-encoder/ms-marco-TinyBERT-L-2-v2, un codificador cruzado liviano:
from sentence_transformers import CrossEncoder
# Load the cross-encoder model
cross_encoder = CrossEncoder("cross-encoder/ms-marco-TinyBERT-L-2-v2")
# Use the cross-encoder to rerank top-k retrieved documents
query_document_pairs = [(query, doc) for doc in documents]
scores = cross_encoder.predict(query_document_pairs)
# Rank documents based on the new scores
top_k_reranked = np.argsort(scores)[-5:]
print("Top 5 reranked documents:", [documents[i] for i in top_k_reranked])
Identificación de cuellos de botella: el costo de la tokenización y la predicción
Durante el desarrollo, descubrí que las etapas de tokenización y predicción estaban tardando bastante al manejar 1000 informes con configuraciones predeterminadas para transformadores de oraciones. Esto creó un cuello de botella en el rendimiento, especialmente porque buscábamos respuestas en tiempo real.
A continuación, perfilé mi código usando SnakeViz para visualizar las actuaciones:
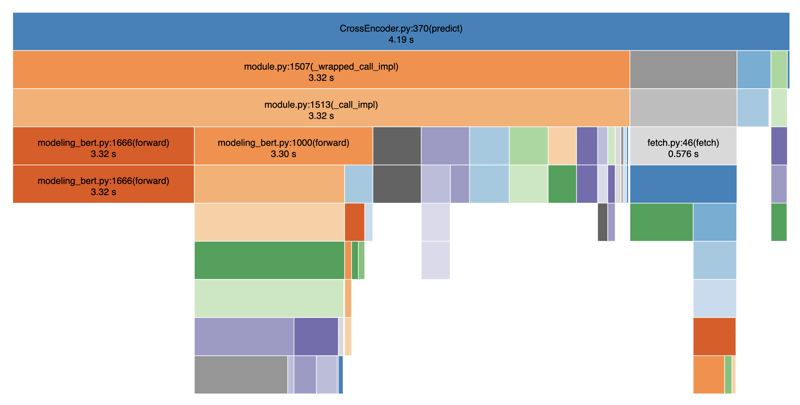
Como puede ver, los pasos de tokenización y predicción son desproporcionadamente lentos, lo que genera retrasos significativos en la entrega de resultados de búsqueda. En general, tomó entre 4 y 5 segundos en promedio. Esto se debe al hecho de que existen operaciones de bloqueo entre los pasos de tokenización y predicción. Si también sumamos otras operaciones como llamadas a bases de datos, filtrado, etc., fácilmente terminamos con 8-9 segundos en total.
Optimización del rendimiento con OpenVINO
La pregunta que enfrenté fue: ¿Podemos hacerlo más rápido? La respuesta es sí, aprovechando OpenVINO, un backend optimizado para la inferencia de CPU. OpenVINO ayuda a acelerar la inferencia de modelos de aprendizaje profundo en hardware Intel, que utilizamos en AWS Lambda.
Ejemplo de código para optimización de OpenVINO
Así es como integré OpenVINO en el sistema de búsqueda para acelerar la inferencia:
import argparse
import numpy as np
import pandas as pd
from typing import Any
from openvino.runtime import Core
from transformers import AutoTokenizer
def load_openvino_model(model_path: str) -> Core:
core = Core()
model = core.read_model(model_path ".xml")
compiled_model = core.compile_model(model, "CPU")
return compiled_model
def rerank(
compiled_model: Core,
query: str,
results: list[str],
tokenizer: AutoTokenizer,
batch_size: int,
) -> np.ndarray[np.float32, Any]:
max_length = 512
all_logits = []
# Split results into batches
for i in range(0, len(results), batch_size):
batch_results = results[i : i batch_size]
inputs = tokenizer(
[(query, item) for item in batch_results],
padding=True,
truncation="longest_first",
max_length=max_length,
return_tensors="np",
)
# Extract input tensors (convert to NumPy arrays)
input_ids = inputs["input_ids"].astype(np.int32)
attention_mask = inputs["attention_mask"].astype(np.int32)
token_type_ids = inputs.get("token_type_ids", np.zeros_like(input_ids)).astype(
np.int32
)
infer_request = compiled_model.create_infer_request()
output = infer_request.infer(
{
"input_ids": input_ids,
"attention_mask": attention_mask,
"token_type_ids": token_type_ids,
}
)
logits = output["logits"]
all_logits.append(logits)
all_logits = np.concatenate(all_logits, axis=0)
return all_logits
def fetch_search_data(search_text: str) -> pd.DataFrame:
# Usually you would fetch the data from a database
df = pd.read_csv("cnbc_headlines.csv")
df = df[~df["Headlines"].isnull()]
texts = df["Headlines"].tolist()
# Load the model and rerank
openvino_model = load_openvino_model("cross-encoder-openvino-model/model")
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-2-v2")
rerank_scores = rerank(openvino_model, search_text, texts, tokenizer, batch_size=16)
# Add the rerank scores to the DataFrame and sort by the new scores
df["rerank_score"] = rerank_scores
df = df.sort_values(by="rerank_score", ascending=False)
return df
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Fetch search results with reranking using OpenVINO"
)
parser.add_argument(
"--search_text",
type=str,
required=True,
help="The search text to use for reranking",
)
args = parser.parse_args()
df = fetch_search_data(args.search_text)
print(df)
Con este enfoque podríamos obtener una aceleración de 2 a 3 veces, reduciendo los 4 a 5 segundos originales a 1 a 2 segundos. El código de trabajo completo está en Github.
Ajuste de velocidad: tamaño de lote y tokenización
Otro factor crítico para mejorar el rendimiento fue optimizar el proceso de tokenización y ajustar el tamaño del lote y la longitud del token. Al aumentar el tamaño del lote (batch_size=16) y reducir la longitud del token (max_length=512), podríamos paralelizar la tokenización y reducir la sobrecarga de las operaciones repetitivas. En nuestros experimentos, descubrimos que un tamaño de lote entre 16 y 64 funcionaba bien, y un valor mayor degradaba el rendimiento. De manera similar, nos decidimos por una longitud máxima de 128, que es viable si la longitud promedio de sus informes es relativamente corta. Con estos cambios, logramos una aceleración general de 8 veces, reduciendo el tiempo de reclasificación a menos de 1 segundo, incluso en la CPU.
En la práctica, esto significó experimentar con diferentes tamaños de lotes y longitudes de tokens para encontrar el equilibrio adecuado entre velocidad y precisión para sus datos. Al hacerlo, vimos mejoras significativas en los tiempos de respuesta, lo que hizo que el sistema de búsqueda fuera escalable incluso con 1000 informes.
Conclusión
Al utilizar OpenVINO y optimizar la tokenización y el procesamiento por lotes, pudimos crear un sistema de búsqueda semántica de alto rendimiento que cumple con los requisitos en tiempo real en una configuración de solo CPU. De hecho, experimentamos una aceleración general de 8 veces. La combinación de recuperación mediante transformadores de oraciones y reclasificación con un modelo de codificador cruzado crea una experiencia de búsqueda poderosa y fácil de usar.
Si está creando sistemas similares con limitaciones en el tiempo de respuesta y los recursos computacionales, le recomiendo explorar OpenVINO y el procesamiento por lotes inteligente para desbloquear un mejor rendimiento.
Esperamos que hayas disfrutado este artículo. Si este artículo te resultó útil, dame un me gusta para que otros también puedan encontrarlo y compártelo con tus amigos. Sígueme en Linkedin para estar al día de mi trabajo. ¡Gracias por leer!
-
 ¿Java permite múltiples tipos de devolución: una mirada más cercana a los métodos genéricos?múltiples tipos de retorno en java: una concepción errónea indicada en el reino de la programación de java, una firma de método de método pued...Programación Publicado el 2025-04-06
¿Java permite múltiples tipos de devolución: una mirada más cercana a los métodos genéricos?múltiples tipos de retorno en java: una concepción errónea indicada en el reino de la programación de java, una firma de método de método pued...Programación Publicado el 2025-04-06 -
¿Puedo migrar mi cifrado de MCRYPT a OpenSSL y descifrar datos cifrados de MCRYPT usando OpenSSL?actualizando mi biblioteca de cifrado de MCRYP En OpenSSL, ¿es posible descifrar datos encriptados con MCRYPT? Dos publicaciones diferentes propo...Programación Publicado el 2025-04-06
-
¿Cómo puedo ejecutar los comandos del aviso del sistema, incluidos los cambios en el directorio, en Java?Ejecutar comandos del aviso del sistema en java problema: en ejecución de los comandos del aviso a través de java puede ser desafiante. Au...Programación Publicado el 2025-04-06
-
¿Cómo puedo unir tablas de bases de datos con diferentes números de columnas?tablas combinadas con diferentes columnas ]] puede encontrar desafíos al intentar fusionar las tablas de la base de datos con diferentes column...Programación Publicado el 2025-04-06
-
¿Qué método es más eficiente para la detección de Point-in-Polygon: Ray Tracing o Matplotlib \ 's Rath.Contains_Points?Detección eficiente de Point-in-Polygon en python determinando si un punto se encuentra dentro de un polígono es una tarea frecuente en la geome...Programación Publicado el 2025-04-06
-
¿Cómo puedo generar eficientemente las babosas amigables con la URL a partir de cuerdas Unicode en PHP?elaborando una función para una generación de babosas eficiente creando babosas, representaciones simplificadas de las cadenas unicode utiliza...Programación Publicado el 2025-04-06
-
¿Cómo puedo mantener la representación de celda JTable personalizada después de la edición de la celda?manteniendo la representación de la celda JTable después de la edición de celda en una jtable, implementar capacidades de representación y edi...Programación Publicado el 2025-04-06
-
¿Cómo simplificar el análisis de JSON en PHP para matrices multidimensionales?Parsing JSON con php tratando de analizar los datos JSON en PHP puede ser un desafío, especialmente cuando se trata de matrices multidimensional...Programación Publicado el 2025-04-06
-
¿Cómo mostrar correctamente la fecha y hora actuales en el formato "DD/MM/YYYY HH: MM: SS.SS" en Java?cómo mostrar la fecha y la hora actuales en "dd/mm/aa radica en el uso de diferentes instancias de SimpleFormat con diferentes patrones de f...Programación Publicado el 2025-04-06
-
¿Cómo se extraen un elemento aleatorio de una matriz en PHP?Selección aleatoria de una matriz en php, la obtención de un elemento aleatorio de una matriz se puede lograr con facilidad. Considere la siguie...Programación Publicado el 2025-04-06
-
¿Cómo insertar correctamente las blobs (imágenes) en MySQL usando PHP?Inserte blobs en bases de datos MySQL con php Al intentar almacenar una imagen en una base de datos MySQL, puede encontrar un asunto. Esta gu...Programación Publicado el 2025-04-06
-
¿Cómo selecciono de manera eficiente columnas en Pandas Dataframes?seleccionando columnas en Pandas Dataframes cuando se trata de tareas de manipulación de datos, se hace necesario seleccionar columnas específ...Programación Publicado el 2025-04-06
-
¿Cómo limitar el rango de desplazamiento de un elemento dentro de un elemento principal de tamaño dinámico?implementando límites de altura de CSS para los elementos de desplazamiento vertical en una interfaz interactiva, controlar el comportamiento ...Programación Publicado el 2025-04-06
-
¿Cómo puedo recuperar eficientemente los valores de atributos de los archivos XML usando PHP?Recuperando valores de atributo de archivos XML en php Todo desarrollador encuentra la necesidad de analizar archivos XML y extraer valores es...Programación Publicado el 2025-04-06
-
Eval () vs. AST.LITERAL_EVAL (): ¿Qué función de Python es más segura para la entrada del usuario?pesando eval () y Ast.literal_eval () en Python Security Al manejar la entrada del usuario, es imperativo priorizar la seguridad. eval (), una...Programación Publicado el 2025-04-06















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









