
So realisieren Sie Echtzeit-Sprache mit der Dify-API
 Durchsuche:383
Durchsuche:383
Dify ist eine Open-Source-SaaS-Plattform für die Online-Erstellung von LLM-Workflows. Ich verwende die API, um in meiner App ein dialogorientiertes KI-Erlebnis zu schaffen. Ich hatte Probleme damit, TTS-Streams als API-Antwort zu erhalten und abzuspielen. Hier zeige ich, wie man die Audiostreams verarbeitet und richtig abspielt.
Ich verwende den API-Endpunkt https://api.dify.ai/v1/chat-messages für Text-Chat. Es gibt Audiodaten im selben Stream wie die Textantwort zurück, wenn wir die Text-to-Speach-Funktion in unseren Dify-Apps aktiviert haben.
Klicken Sie auf die Schaltfläche „FUNKTION HINZUFÜGEN“ und fügen Sie die Funktion „Text in Sprache“ hinzu.
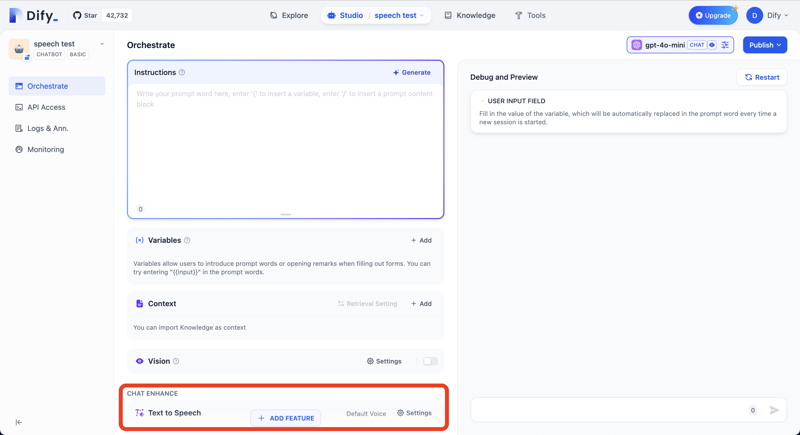
Sie können die Antwort der API mit dem folgenden Curl-Befehl überprüfen.
curl -X POST 'https://api.dify.ai/v1/chat-messages' \
--header 'Authorization: Bearer YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"query": "What are the specs of the iPhone 13 Pro Max?",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": []
}'
Ich demonstriere es in TypeScript/JavaScript, aber Sie können die gleiche Logik auf Ihre Programmiersprache anwenden.
Anatomie gestreamter Daten
Lassen Sie uns zunächst verstehen, welche Art von Daten Dify für die Streams verwendet.
Gestreamtes Datenformat
Dify verwendet das folgende Textdatenformat. Es ähnelt JSON-Zeilen, ist aber nicht genau dasselbe.
data: {"event": "workflow_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "50100b30-e458-4632-ad7d-8dd383823376", "workflow_id": "debdb4fa-dcab-4233-9413-fd6d17b9e36a", "sequence_number": 334, "inputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123"}, "created_at": 1724478014}}
data: {"event": "node_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "bf912f43-29dd-4ee2-aefa-0fabdf379257", "node_id": "1721365917005", "node_type": "start", "title": "\u958b\u59cb", "index": 1, "predecessor_node_id": null, "inputs": null, "created_at": 1724478013, "extras": {}}}
data: {"event": "node_finished", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "bf912f43-29dd-4ee2-aefa-0fabdf379257", "node_id": "1721365917005", "node_type": "start", "title": "\u958b\u59cb", "index": 1, "predecessor_node_id": null, "inputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123", "sys.dialogue_count": 1}, "process_data": null, "outputs": {"sys.query": "What are the specs of the iPhone 13 Pro Max?", "sys.files": [], "sys.conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "sys.user_id": "abc-123", "sys.dialogue_count": 1}, "status": "succeeded", "error": null, "elapsed_time": 0.001423838548362255, "execution_metadata": null, "created_at": 1724478013, "finished_at": 1724478013, "files": []}}
data: {"event": "node_started", "conversation_id": "065fb118-35d4-4524-a067-a70338ece575", "message_id": "3f0fe3cf-5aa1-4f7c-8abe-2505bf07ae8f", "created_at": 1724478014, "task_id": "dacb2d5c-a6f5-44b5-b5a6-de000f24aeba", "workflow_run_id": "50100b30-e458-4632-ad7d-8dd383823376", "data": {"id": "89ed58ab-6157-499b-81b2-92b1336969a5", "node_id": "llm", "node_type": "llm", "title": "LLM", "index": 2, "predecessor_node_id": "1721365917005", "inputs": null, "created_at": 1724478013, "extras": {}}}
...
In der Antwort sendet Dify Textantwort- und Audiodaten.
Beispielzeile einer Textantwort
data: {"event": "message", "conversation_id": "aa13eb24-e90a-4c5d-a36b-756f0e3be8f8", "message_id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "created_at": 1724301648, "task_id": "0643f770-e9d3-408f-b771-bb2e9430b4f9", "id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "answer": "MP"}
Beispielzeile mit Audiodaten
data: {"event": "tts_message", "conversation_id": "aa13eb24-e90a-4c5d-a36b-756f0e3be8f8", "message_id": "5be739a9-09ba-4444-9905-a2f37f8c7a21", "created_at": 1724301648, "task_id": "0643f770-e9d3-408f-b771-bb2e9430b4f9", "audio": "//PkxABhvDm0DVp4ACUUfvWc1CFlh0tR9Oh7LxzHRsGBuGx155x3JqTJiwKKZf8wIcxpMzJU0h4zhgyQwwwIsgWQMAALQMkanBTjfCPgZwFsDOGGIYJoJoJoJoPQPQLYEgAOwM4SMXMW8TcNWGrEPEME0HoIQTg0DQNA0C5k7IOLeJuDnDVi5nWyJwgghAagQwTQQgJAGrDVibiFhqw1YR8HOEjBUA5AcgagQwTQTQQgJAAtgLYKsQ8hZc0PV7OrE4SgQgFIAsAQAwA6H0Uv4t4m4m49Yt4uYOQHIBkAyAqAkAuB0Mm6UeKxDGRrIODkByBqBNBCA1ARwHIEgBVg5wkY41W2GgdEVDFBNe HicQw0ydk7HrHrIWXM62d48ePNfCkNATcTcNWGrCRhqxDxcwMYBwBkByCGC4EILgoJTQUDeW8W8TcTchZ1qBWIYchOBbBCA1AhgSMJGGrFzLmh6fL LeBkAyAZAcgSAXAhB0Kxnj4YDkJwXA6FAzwj8IIJoJoPQXA6EPOcg4R8FOBnCRljRAwlwoh4EUwLhFTCVA MR0R8wyxOhgAwwDgJjBUABMM0hMxBgnTPtMrMBEEcwJQCzIXIdMZMG821DmjDKHJAwLDKHRMQsJkwbwVRoFs//PkxEx5dDnwAZ7wANHgEUFJHGCUCQp3LWCQQYGAATI5QzwHBJF4UFktpfATT2l0goAGNADLOU64HAMCQCK50szABAIkDS2/j8gl6l6Di7QgBEiAfMEADBnyZBgeAWCMK4xvBbhoRZj1M ktsNMTrMNcHEwHQEzAjAHMGQAQwRQZTBHALMGMDkzhh2jGhLtMgsMMwfhOzCnGLMMcKgwOw8pqHMoGtvdDzos0AIAiXIsBAmGsRFtYcBABmB0AUYjQfhhDAfjoCrETAGArMOAJ4iAAMCMFkwXwh5fffuhpYMhyP2bl3MVAJQrSYQDsna7G2 fx/GvyAwUQbTAdAFCAHVKyIAduTXHZZXDjNS57/VeVJ5 JBJ 0kATkCSells8/NBt/2/5Dj1s chDBYSINutNS9FQwDwBWHjgASKRgAAJOyYC4Ao0CMNAKBgB6KK1hYBkAAHROM9mLsknb8avTcB0MerV6jl7llE70egOerRh9WcP/FoHqtVsO/In2f G2tsdnH L/KSSvBQB4OATam27Yi4jiBgBFOpq15bTQU6k1G4LoWo1mMAwDQwlBEzEnKsMkA7c5JYuTOzK2MvAbEysSPTM dOOn1XEzGgIzXzmPODVvs1cyNTJxQ9MsAWwy//PkxDlz7DIMAd7gAek5EwnjcjX9QVN1N0czFyijQKOmMi4IYw8RvzFvCHMHYBQwdQlTRxVNvm8ycGjLYlMTAQ=="}
Wir können JSON-Zeilen von Audiodaten unterscheiden, indem wir die Ereigniseigenschaft überprüfen. Audio-JSON hat tts_message als Wert. Die Audio-MP3-Binärdatei wird in der Audioeigenschaft der JSONs im Base64-Format gespeichert.
Probleme im Umgang mit Daten
Das erste Problem, das wir haben, wenn wir TTS-Audio in Echtzeit abspielen, besteht darin, dass die JSON-Zeilen in Pakete aufgeteilt werden und jedes Paket keine gültigen JSON-Daten enthält, so wie es ist.
Beispielpaket, das in der Mitte geschnitten ist
euimRrhsPMZiMAl BqSZMDmIkQEcDb/8 TEtHm8MhwA3p/p8dA0CCpAxwMMPABoYMIWwUDG6BRmiYZg2G6gRidGanOm5i5iaIYmfkH8Z/FmEopqJGZKXihYEIRxCKYKtlQuMvPjPQIwUVFFECDRnRCYEimGmA6cji41yQMImMEmhaHrVKpCxo2OYx6Q5RcJKAKkah4X6MckHEqdwKgHGHltDUjCy46HMgTCpwodAM8KijREwSSEk5hB4gRGFfC0ouYoeDiYtNREDgKQsTT6EI4egmMMBxpQZmoUJmAAg6YPDmQISgSECAZQOLfAUEQAG/dgxAVkxfFHGorEHB4CS Yugwk2gq8akIwMsZIuIzUSrCAGm1iBnoYA8lcoYSlaIJ5RjCblwbsh8sB3skA7Gcx3zmSOKnXNJO6ObKklhuYjlVL1dSMhgwVJtFzMeWFufNKy3ODmCExBTUUzLjEwMKqqqqqqqqqqqqqqqqqqCIEWFIAA4DAWKkMDDIBA4lBqGDdmZwzAkGJFoYiwEV0IQOQHg1AATJiUM6F0z2fDE6PMvlc6DhTMJ MNH4xWwzBwKMMCgHAwwUFQwjGEgMgovgIBMIMECYxYSDKAwSoMOBC4Ez682pEZIB8kBuiawZEaSnFAjIEwSFRxGUJIXMGRMmfNCPApcKL/8 TEiVdEKlJm5pM9gz0MyScwo04BgqjEFh489MGKVw=="}
Das Paket beginnt in der Mitte einer JSON-Zeile. Wir müssen mehrere Pakete kombinieren, um gültige JSON-Zeilen zu erhalten.
Das zweite Problem besteht darin, dass der Audiodatenblock in einem JSON keine gültigen Audiodaten sind. Die Daten werden in der Mitte von MP3-Frames geschnitten.
Durchführung
Um mit den geteilten Daten von JSON und MP3 umzugehen, müssen wir eine intelligente Methode anwenden. Der Ablauf des Prozesses ist wie folgt:
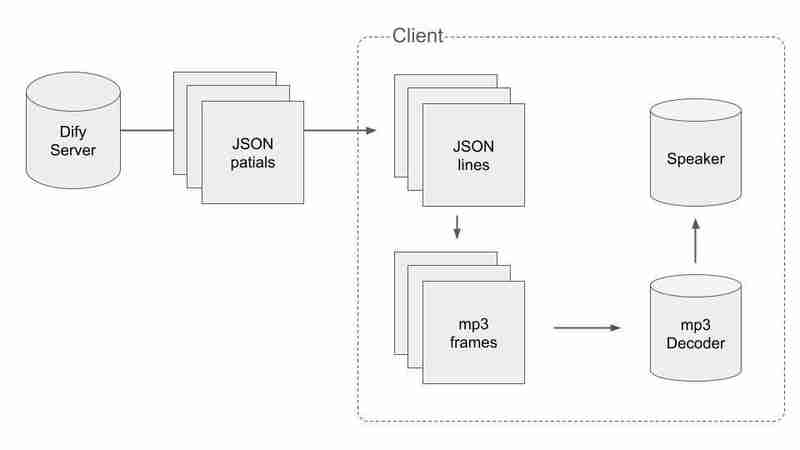
Zuerst müssen wir gültige JSON-Daten abrufen und beim Empfang von Paketen in JSONs aufteilen. Wenn wir ein Paket mit \n am Ende erhalten, können wir sagen, dass die Verkettung der bisher empfangenen Pakete nicht in der Mitte durchtrennt ist. Der Pseudocode sieht so aus.
let packets = []
stream.on('data', (bytes) => {
const text = bytes.toString()
packets.push(text)
if (text.endsWith('\n')) {
// Extract audio data from the packets.
const audioChunks = extractAudioChunks(packets.join(''))
// Clear the packet array
packets = []
}
})
Zweitens müssen wir die Audioblöcke in MP3-Frames aufteilen. Wir fassen die Audioblöcke in einer Binärdatei zusammen und finden darin alle MP3-Frames.
const mp3Frames = [] const binaryToProcess = Buffer.concat([...audioChunks]) let frameStartIndex = 0 for (let i = 0; iDies ist nicht die vollständige Implementierung der Aufteilung in MP3-Frames. Im eigentlichen Prozess müssen wir Fälle berücksichtigen, in denen wir Restbytes haben, wenn wir MP3-Frames aus der Audio-Binärdatei extrahiert haben, und den Rest als Anfang der Audiobytes in der nächsten Iteration verwenden. Bitte überprüfen Sie mein Github-Repo für die vollständige Implementierung.
-
 Wie kann man die Funktionsbeschränkungen von PHP 'Funktionen überwinden?Überwindung von PHP-Funktionsfunktionen Einschränkungen In PHP sind eine Funktion mit demselben Namen mehrmals ein No-no. Der Versuch, dies zu...Programmierung Gepostet am 2025-03-12
Wie kann man die Funktionsbeschränkungen von PHP 'Funktionen überwinden?Überwindung von PHP-Funktionsfunktionen Einschränkungen In PHP sind eine Funktion mit demselben Namen mehrmals ein No-no. Der Versuch, dies zu...Programmierung Gepostet am 2025-03-12 -
Warum hört die Ausführung von JavaScript ein, wenn die Firefox -Rückbutton verwendet wird?Navigational History Problem: JavaScript hört auf, nach der Verwendung von Firefox -Back -Schaltflächen auszuführen. Dieses Problem tritt in ande...Programmierung Gepostet am 2025-03-12
-
Wie extrahieren Sie ein zufälliges Element aus einem Array in PHP?zufällige Auswahl aus einem Array In PHP kann ein zufälliger Element aus einem Array mit Leichtigkeit erreicht werden. Betrachten Sie das folgen...Programmierung Gepostet am 2025-03-12
-
Was waren die Einschränkungen bei der Verwendung von Current_Timestamp mit Zeitstempelspalten in MySQL vor Version 5.6.5?Einschränkungen für Zeitstempelspalten mit Current_Timestamp in Standard- oder Aktualisierungsklauseln in MySQL -Versionen vor 5.6.5 Historisch ...Programmierung Gepostet am 2025-03-12
-
Wie rufe ich die neueste JQuery -Bibliothek von Google APIs ab?abrufen die neueste jQuery -Bibliothek von Google apis Die bereitgestellte jQuery -URL in der Frage ist für Version 1.2.6. Für das Abrufen der...Programmierung Gepostet am 2025-03-12
-
Wie entferte ich anonyme JavaScript -Ereignishandler sauber?entfernen anonymer Ereignis -Hörer Hinzufügen von anonymen Ereignishörern zu Elementen bieten Flexibilität und Einfachheit, aber wenn es Zeit is...Programmierung Gepostet am 2025-03-12
-
Welche Methode ist effizienter für die Erkennung von Punkt-in-Polygon: Strahlenverfolgung oder Matplotlib \ 's path.contains_points?effiziente Punkt-in-Polygon-Erkennung in Python festlegen, ob ein Punkt innerhalb eines Polygons eine häufige Aufgabe in der Computergeometrie i...Programmierung Gepostet am 2025-03-12
-
Können mehrere klebrige Elemente in reinem CSS übereinander gestapelt werden?Ist es möglich, in reinem CSS mehrere klebrige Elemente gestapelt zu haben? Hier: https://webthemez.com/demo/sticky-multi-header-scroll/index.ht...Programmierung Gepostet am 2025-03-12
-
Detaillierte Erläuterung des Einführungs -Tutorials für JQuery Scroll Animation核心要点 基于滚动的动画和特效是一种让网页开发者创建动态交互式网页体验的技术。它们在用户向下滚动页面时触发,并能用CSS和jQuery进行操控和实现。 要创建响应式的基于滚动的特效,必须定义浏览器窗口的宽度和高度属性。如果没有这些属性,当用户调整窗口大小时,特效将无法正常工作。 本教程提供了四个基...Programmierung Gepostet am 2025-03-12
-
Gibt es einen Leistungsunterschied zwischen der Verwendung einer For-Each-Schleife und einem Iterator für die Sammlung durchquert in Java?für jede Schleife vs. Iterator: Effizienz in der Sammlung traversal Einführung beim Durchlaufen einer Sammlung in Java, die Auswahl an der...Programmierung Gepostet am 2025-03-12
-
Wie beheben Sie die Diskrepanzen für Modulpfade in Go -Mod mithilfe der Richtlinie Ersetzen?überwinden Modulpfad -Diskrepanz in go mod Wenn GO mod verwendet wird, ist es möglich, auf einen Konflikt zu begegnen, bei dem ein Drittanbiet...Programmierung Gepostet am 2025-03-12
-
ArrayMethoden sind fns, die auf Objekte aufgerufen werden können Arrays sind Objekte, daher haben sie auch Methoden in js. Slice (Beginn): Ex...Programmierung Gepostet am 2025-03-12
-
Warum erscheint mein CSS -Hintergrundbild nicht?Fehlerbehebung: CSS -Hintergrundbild erscheinen nicht Sie haben auf ein Problem gestoßen, bei dem Ihr Hintergrundbild trotz der folgenden Tuto...Programmierung Gepostet am 2025-03-12
-
Warum wird die Anfrage nicht nach dem Erfassen von Eingaben in PHP trotz gültiger Code erfasst?adressieren nach Anfrage Fehlfunktion in php in dem vorgestellten Code -Snippet: action='' Die Intented -In -Intented -Aufnahme. Die Ausg...Programmierung Gepostet am 2025-03-12
-
Können Sie Klick-Ereignisse in CSS-Pseudoelementen erkennen?klicken Sie auf Ereigniserkennung auf Pseudo-Elements Frage: im vorgesehenen Code, ein Klick-Ereignis, das auf beiden Pseudo-Elementen (ro...Programmierung Gepostet am 2025-03-12















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









