 Titelseite > Programmierung > Was ist schneller und günstiger, um Dateien in AWS zu konvertieren: Polar oder Pandas?
Titelseite > Programmierung > Was ist schneller und günstiger, um Dateien in AWS zu konvertieren: Polar oder Pandas?
Was ist schneller und günstiger, um Dateien in AWS zu konvertieren: Polar oder Pandas?
 Durchsuche:980
Durchsuche:980
Beide bieten eine breite Palette an Tools und Vorteilen, die uns irgendwann zweifeln lassen können, welches der beiden wir wählen sollen. Es geht nicht darum, alle Prozesse des Unternehmens so zu ändern, dass Polars zum Einsatz kommen, oder um den „Tod“ von Pandas (dies wird in naher Zukunft nicht passieren). Es geht darum, andere Tools zu kennen, die uns helfen können, Kosten und Zeit in Prozessen zu reduzieren und die gleichen oder bessere Ergebnisse zu erzielen.
Wenn wir Cloud-Dienste nutzen, priorisieren wir bestimmte Faktoren, einschließlich ihrer Kosten. Die Dienste, die ich für diesen Prozess verwende, sind AWS Lambda mit der Python 3.10-Laufzeit und S3 zum Speichern der Rohdatei und der Parquet-konvertierten Datei.
Die Absicht besteht darin, eine CSV-Datei als Rohdaten zu erhalten und sie mit Pandas und Polar zu verarbeiten, um zu überprüfen, welche dieser beiden Bibliotheken uns eine bessere Optimierung von Ressourcen wie Speicher und Gewicht der resultierenden Datei bietet.
Pandas
Es handelt sich um eine Python-Bibliothek, die auf Datenmanipulation und -analyse spezialisiert ist. Sie ist in C geschrieben und wurde erstmals 2008 veröffentlicht.
*Polare *
Es handelt sich um eine auf Datenmanipulation und -analyse spezialisierte Python- und Rust-Bibliothek, die parallele Prozesse ermöglicht, größtenteils in Rust geschrieben ist und 2022 veröffentlicht wurde.
Die Architektur des Prozesses:
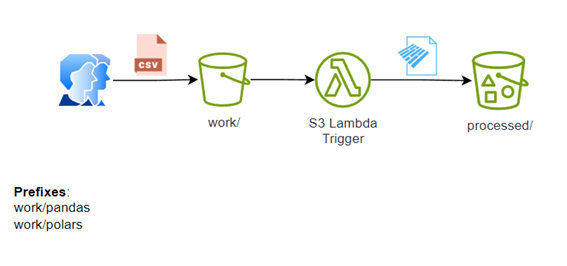
Das Projekt ist einigermaßen einfach, wie in der Architektur gezeigt: Der Benutzer hinterlegt eine CSV-Datei in work/pandas oder work/porlas und startet automatisch den s3-Trigger, um die Datei zu verarbeiten, sie in Parkett umzuwandeln und sie in „processed“ abzulegen.
Verwenden Sie in diesem kleinen Projekt zwei Lambdas mit der folgenden Konfiguration:
Speicher: 2 GB
Kurzlebiger Speicher: 2 GB
Lebensdauer: 600 Sekunden
Anforderungen
Lambda mit Pandas: Pandas, Numpy und Pyarrow
Lambda mit Polaren: Polaren
Der für den Vergleich verwendete Datensatz ist auf kaggle unter dem Namen „Rotten Tomatoes Movie Reviews – 1.44M rows“ verfügbar oder kann hier heruntergeladen werden.
Das vollständige Repository ist auf GitHub verfügbar und kann hier geklont werden.
Größe oder Gewicht
Das von Pandas verwendete Lambda erfordert zwei weitere Plugins zum Erstellen einer Parquet-Datei, in diesem Fall PyArrow und eine bestimmte Version von Numpy für die Version von Pandas, die ich verwendet habe. Als Ergebnis haben wir ein Lambda mit einem Gewicht oder einer Größe von 74,4 MB erhalten, was sehr nahe an der Grenze liegt, die AWS uns für das Gewicht des Lambda zulässt.
Das Lambda mit Polars erfordert kein weiteres Plugin wie PyArrow, was das Leben einfacher macht und die Größe des Lambda auf weniger als die Hälfte reduziert. Infolgedessen hat unser Lambda im Vergleich zum ersten ein Gewicht oder eine Größe von 30,6 MB, was uns Raum gibt, andere Abhängigkeiten zu installieren, die wir möglicherweise für unseren Transformationsprozess benötigen.
Leistung
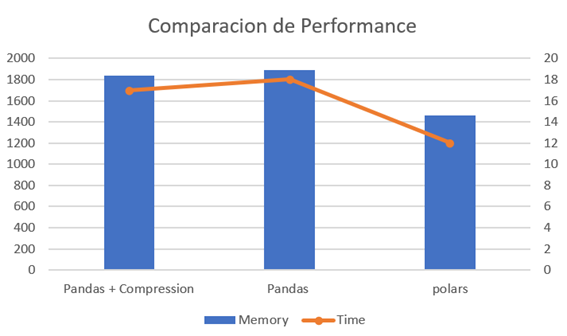
Das Lambda mit Pandas wurde nach der ersten Version für die Verwendung von Komprimierung optimiert, allerdings wurde auch sein Verhalten analysiert.
Pandas
Die Verarbeitung des Datensatzes dauerte 18 Sekunden und es wurden 1894 MB Speicher für die Verarbeitung der CSV-Datei und die Generierung einer Parquet-Datei benötigt. Im Vergleich zu den anderen Versionen verbrauchte diese Version am meisten Zeit und Ressourcen.
Pandas-Komprimierung
Durch das Hinzufügen einer Codezeile konnten wir uns im Vergleich zur Vorgängerversion (Pandas) ein wenig verbessern. Die Verarbeitung des Datensatzes dauerte 17 Sekunden und verbrauchte 1837 MB, was keine wesentliche Verbesserung der Verarbeitungs- und Rechenzeit, sondern der Größe darstellt. der resultierenden Datei.
Polare
Die Verarbeitung desselben Datensatzes dauerte 12 Sekunden und ich habe nur 1462 MB verbraucht. Im Vergleich zu den beiden vorherigen bedeutet das eine Zeitersparnis von 44,44 % und einen geringeren Speicherverbrauch.
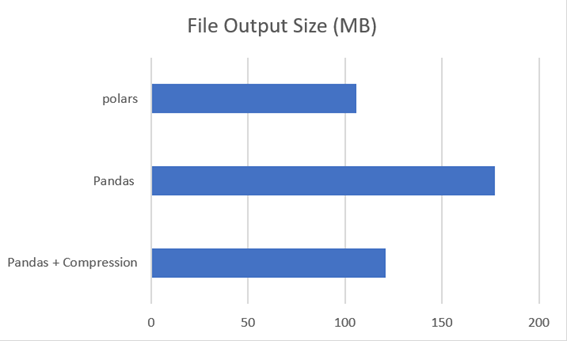
Ausgabedateigröße
Pandas
Das Lambda, in dem kein Komprimierungsprozess eingerichtet wurde, erzeugte eine Parquet-Datei von 177,4 MB.
Pandas-Komprimierung
Beim Konfigurieren der Komprimierung im Lambda erzeuge ich keine 121,1 MB große Parkettdatei. Eine kleine Zeile oder Option hat uns geholfen, die Dateigröße um 31,74 % zu reduzieren. Wenn man bedenkt, dass es sich nicht um eine wesentliche Codeänderung handelt, ist es eine sehr gute Option.
Polare
Polars hat eine 105,8 MB große Datei generiert, die beim Kauf mit der ersten Version von Pandas eine Einsparung von 40,36 % bzw. 12,63 % gegenüber der Pandas-Version mit Komprimierung darstellt.
Abschluss
Es ist nicht notwendig, alle internen Prozesse, die Pandas verwenden, so zu ändern, dass sie jetzt Polars verwenden. Es ist jedoch wichtig zu bedenken, dass uns die Verwendung von Polars nicht nur bei der Bereitstellung hilft, wenn wir über Tausende oder Millionen von Lambda-Ausführungen sprechen Zeit, wird uns aber auch dabei helfen, niedrigere Kosten zu erzielen, da AWS für serverlose Dienste wie Lambda eine zeitbasierte Abrechnung vornimmt.
Wenn wir diese 40,36 % in Millionen von Dateien umrechnen, sprechen wir ebenfalls von GB oder TB, was erhebliche Auswirkungen innerhalb eines Datalake- oder Dataware-Hauses oder sogar in einem Cold-File-Storage hätte.
Die Reduzierung mit Polars wäre nicht nur auf diese beiden Faktoren beschränkt, da sie die Ausgabe von Daten und/oder Objekten von AWS stark beeinträchtigen würde, da es sich um einen kostenpflichtigen Service handelt.
-
 Python Read CSV -Datei UnicodEdeCodeError Ultimate Lösungunicode dekodieren Fehler in der CSV-Datei Reading Wenn versucht wird, eine CSV-Datei mit dem integrierten CSV-Modul zu lesen, können Sie eine...Programmierung Gepostet am 2025-07-03
Python Read CSV -Datei UnicodEdeCodeError Ultimate Lösungunicode dekodieren Fehler in der CSV-Datei Reading Wenn versucht wird, eine CSV-Datei mit dem integrierten CSV-Modul zu lesen, können Sie eine...Programmierung Gepostet am 2025-07-03 -
Warum erscheint mein CSS -Hintergrundbild nicht?Fehlerbehebung: CSS -Hintergrundbild erscheinen nicht Sie haben auf ein Problem gestoßen, bei dem Ihr Hintergrundbild trotz der folgenden Tuto...Programmierung Gepostet am 2025-07-03
-
Gibt es einen Leistungsunterschied zwischen der Verwendung einer For-Each-Schleife und einem Iterator für die Sammlung durchquert in Java?für jede Schleife vs. Iterator: Effizienz in der Sammlung traversal Einführung beim Durchlaufen einer Sammlung in Java, die Auswahl an der...Programmierung Gepostet am 2025-07-03
-
Wie kann man eine generische Hash -Funktion für Tupel in ungeordneten Sammlungen implementieren?generische Hash -Funktion für Tupel in nicht ordnungsgemäßen Sammlungen Die std :: unbestrahlte_Map und std :: unconded_set Container bieten e...Programmierung Gepostet am 2025-07-03
-
Wie kann ich das CSS-Attribut der ": After" -Pseudo-Element mit JQuery effektiv ändern?die Einschränkungen von Pseudo-Elementen in jQuery: Zugriff auf die ": After" selector in Webentwicklung, Pseudo-Elemente mögen &quo...Programmierung Gepostet am 2025-07-03
-
-
Wie überprüfe ich, ob ein Objekt ein spezifisches Attribut in Python hat?Methode zur Bestimmung von Objektattribut -Existenz Diese Anfrage befriedigt eine Methode, um das Vorhandensein eines bestimmten Attributs in ...Programmierung Gepostet am 2025-07-03
-
Wie entferte ich anonyme JavaScript -Ereignishandler sauber?entfernen anonymer Ereignis -Hörer Hinzufügen von anonymen Ereignishörern zu Elementen bieten Flexibilität und Einfachheit, aber wenn es Zeit is...Programmierung Gepostet am 2025-07-03
-
Wie kann ich nach der Bearbeitung von Zellen eine kundenspezifische JTable -Zell -Rendering beibehalten?beibehalten von jtable cell rendering nach cell edit in einem jtable, in dem benutzerdefinierte Zellenwiedergabe implementiert werden, kann di...Programmierung Gepostet am 2025-07-03
-
Warum führt PHPs DateTime :: Modify ('+1 Monat') unerwartete Ergebnisse zu?Monate mit PHP DATETIME: Aufdeckung des beabsichtigten Verhaltens Wenn Sie mit der DateTime -Klasse von PHP die erwarteten Ergebnisse hinzufüg...Programmierung Gepostet am 2025-07-03
-
Warum nicht "Körper {Rand: 0; } `Immer den oberen Rand in CSS entfernen?adressieren die Entfernung von Körperrand in CSS Für Anfänger -Webentwickler kann das Entfernen des Randes des Körperelements eine verwirrende...Programmierung Gepostet am 2025-07-03
-
Wie vereinfachen Javas Map.Enty und SimpleEnry das Schlüsselwertpaarmanagement?Eine umfassende Sammlung für Wertpaare: Einführung von Javas map.Entry und SimpleEnry in Java, wenn eine Sammlung definiert wird, bei der jede...Programmierung Gepostet am 2025-07-03
-
Wie kann ich mehrere Benutzertypen (Schüler, Lehrer und Administratoren) in ihre jeweiligen Aktivitäten in einer Firebase -App umleiten?rot: Wie man mehrere Benutzertypen zu jeweiligen Aktivitäten umleitet Login. Der aktuelle Code verwaltet die Umleitung für zwei Benutzertypen erf...Programmierung Gepostet am 2025-07-03
-
Ursachen und Lösungen für den Ausfall der Gesichtserkennung: Fehler -215Fehlerbehandlung: Auflösen "Fehler: (-215)! Leere () In Funktion DESTECTMULTICALS" In opencv , wenn Sie versuchen, das Erstellen der ...Programmierung Gepostet am 2025-07-03
-
Wie löste ich den Fehler "Der Dateityp nicht erraten, Anwendung/Oktett-Stream ..." in Appengine?appengine statische Datei mime type override In Appengine können statische Datei Handler gelegentlich den richtigen MIME -Typ überschreiben, w...Programmierung Gepostet am 2025-07-03















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









