 Titelseite > Programmierung > Optimierung des Web-Scrapings: Scraping von Authentifizierungsdaten mit JSDOM
Titelseite > Programmierung > Optimierung des Web-Scrapings: Scraping von Authentifizierungsdaten mit JSDOM
Optimierung des Web-Scrapings: Scraping von Authentifizierungsdaten mit JSDOM
 Durchsuche:133
Durchsuche:133
Als Scraping-Entwickler müssen wir manchmal Authentifizierungsdaten wie temporäre Schlüssel extrahieren, um unsere Aufgaben auszuführen. So einfach ist es jedoch nicht. Normalerweise handelt es sich dabei um HTML- oder XHR-Netzwerkanfragen, aber manchmal werden die Authentifizierungsdaten berechnet. In diesem Fall können wir entweder die Berechnung zurückentwickeln, was viel Zeit in Anspruch nimmt, um Skripte zu entschleieren, oder das JavaScript ausführen, das sie berechnet. Normalerweise verwenden wir einen Browser, aber das ist teuer. Crawlee bietet Unterstützung für die parallele Ausführung von Browser Scraper und Cheerio Scraper, was jedoch im Hinblick auf die Rechenressourcennutzung sehr komplex und teuer ist. JSDOM hilft uns, Seiten-JavaScript mit weniger Ressourcen als ein Browser und etwas schneller als Cheerio auszuführen.
In diesem Artikel wird ein neuer Ansatz besprochen, den wir in einem unserer Actors verwenden, um die Authentifizierungsdaten aus dem TikTok Ads Creative Center zu erhalten, die von Browser-Webanwendungen generiert werden, ohne den Browser tatsächlich auszuführen, sondern stattdessen JSDOM zu verwenden.
Analyse der Website
Wenn Sie diese URL besuchen:
https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pc/en
Sie sehen eine Liste der Hashtags mit ihrem Live-Ranking, der Anzahl ihrer Beiträge, einem Trenddiagramm, Erstellern und Analysen. Sie können auch feststellen, dass wir die Branche filtern, den Zeitraum festlegen und mithilfe eines Kontrollkästchens filtern können, ob der Trend neu in den Top 100 ist oder nicht.
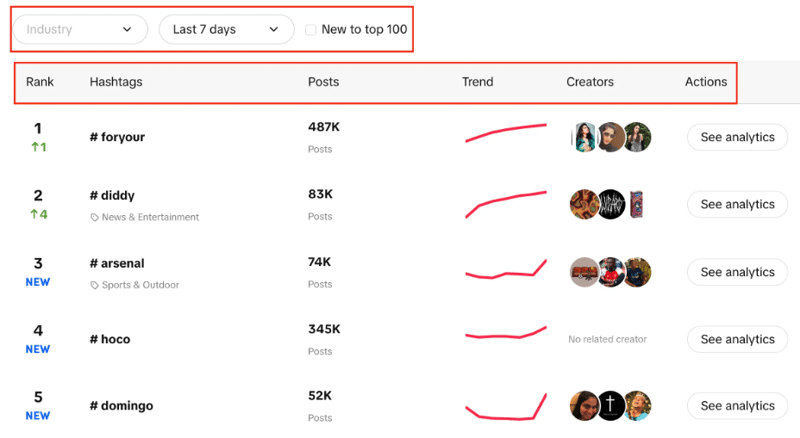
Unser Ziel hier ist es, mit den angegebenen Filtern die Top 100 Hashtags aus der Liste zu extrahieren.
Die beiden möglichen Ansätze sind die Verwendung von CheerioCrawler und der zweite Ansatz ist browserbasiertes Scraping. Cheerio liefert schnellere Ergebnisse, funktioniert aber nicht mit JavaScript-gerenderten Websites.
Cheerio ist hier nicht die beste Option, da das Creative Center eine Webanwendung und die Datenquelle eine API ist, sodass wir nur die Hashtags abrufen können, die ursprünglich in der HTML-Struktur vorhanden waren, aber nicht jeden der 100, die wir benötigen.
Der zweite Ansatz kann darin bestehen, Bibliotheken wie Puppeteer, Playwright usw. zu verwenden, um browserbasiertes Scraping durchzuführen und die Automatisierung zum Scrapen aller Hashtags zu nutzen, aber aufgrund früherer Erfahrungen dauert eine so kleine Aufgabe viel Zeit.
Jetzt kommt der neue Ansatz, den wir entwickelt haben, um diesen Prozess viel besser als browserbasiert zu machen und dem CheerioCrawler-basierten Crawlen sehr nahe zu kommen.
JSDOM-Ansatz
Bevor ich mich eingehend mit diesem Ansatz befasse, möchte ich Alexey Udovydchenko, Web Automation Engineer bei Apify, für die Entwicklung dieses Ansatzes danken. Ein großes Lob an ihn!
Bei diesem Ansatz werden wir API-Aufrufe an https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list durchführen, um die erforderlichen Daten zu erhalten.
Bevor wir diese API aufrufen, benötigen wir einige erforderliche Header (Authentifizierungsdaten), daher rufen wir zunächst https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad auf /de.
Wir beginnen diesen Ansatz mit der Erstellung einer Funktion, die die URL für den API-Aufruf für uns erstellt, den Aufruf durchführt und die Daten abruft.
export const createStartUrls = (input) => {
const {
days = '7',
country = '',
resultsLimit = 100,
industry = '',
isNewToTop100,
} = input;
const filterBy = isNewToTop100 ? 'new_on_board' : '';
return [
{
url: `https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list?page=1&limit=50&period=${days}&country_code=${country}&filter_by=${filterBy}&sort_by=popular&industry_id=${industry}`,
headers: {
// required headers
},
userData: { resultsLimit },
},
];
};
In der obigen Funktion erstellen wir die Start-URL für den API-Aufruf, die verschiedene Parameter enthält, über die wir zuvor gesprochen haben. Nachdem die URL gemäß den Parametern erstellt wurde, wird die Datei „creative_radar_api“ aufgerufen und alle Ergebnisse abgerufen.
Aber es wird nicht funktionieren, bis wir die Header bekommen. Erstellen wir also eine Funktion, die zunächst mithilfe von sessionPool und ProxyConfiguration eine Sitzung erstellt.
export const createSessionFunction = async (
sessionPool,
proxyConfiguration,
) => {
const proxyUrl = await proxyConfiguration.newUrl(Math.random().toString());
const url =
'https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en';
// need url with data to generate token
const response = await gotScraping({ url, proxyUrl });
const headers = await getApiUrlWithVerificationToken(
response.body.toString(),
url,
);
if (!headers) {
throw new Error(`Token generation blocked`);
}
log.info(`Generated API verification headers`, Object.values(headers));
return new Session({
userData: {
headers,
},
sessionPool,
});
};
In dieser Funktion besteht das Hauptziel darin, https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en aufzurufen und im Gegenzug Header zu erhalten. Um die Header abzurufen, verwenden wir die Funktion getApiUrlWithVerificationToken.
Bevor ich fortfahre, möchte ich erwähnen, dass Crawlee JSDOM mithilfe des JSDOM-Crawlers nativ unterstützt. Es bietet ein Framework für das parallele Crawlen von Webseiten mithilfe einfacher HTTP-Anfragen und der jsdom-DOM-Implementierung. Es verwendet rohe HTTP-Anfragen zum Herunterladen von Webseiten und ist sehr schnell und effizient hinsichtlich der Datenbandbreite.
Sehen wir uns an, wie wir die Funktion getApiUrlWithVerificationToken erstellen werden:
const getApiUrlWithVerificationToken = async (body, url) => {
log.info(`Getting API session`);
const virtualConsole = new VirtualConsole();
const { window } = new JSDOM(body, {
url,
contentType: 'text/html',
runScripts: 'dangerously',
resources: 'usable' || new CustomResourceLoader(),
// ^ 'usable' faster than custom and works without canvas
pretendToBeVisual: false,
virtualConsole,
});
virtualConsole.on('error', () => {
// ignore errors cause by fake XMLHttpRequest
});
const apiHeaderKeys = ['anonymous-user-id', 'timestamp', 'user-sign'];
const apiValues = {};
let retries = 10;
// api calls made outside of fetch, hack below is to get URL without actual call
window.XMLHttpRequest.prototype.setRequestHeader = (name, value) => {
if (apiHeaderKeys.includes(name)) {
apiValues[name] = value;
}
if (Object.values(apiValues).length === apiHeaderKeys.length) {
retries = 0;
}
};
window.XMLHttpRequest.prototype.open = (method, urlToOpen) => {
if (
['static', 'scontent'].find((x) =>
urlToOpen.startsWith(`https://${x}`),
)
)
log.debug('urlToOpen', urlToOpen);
};
do {
await sleep(4000);
retries--;
} while (retries > 0);
await window.close();
return apiValues;
};
In dieser Funktion erstellen wir eine virtuelle Konsole, die CustomResourceLoader verwendet, um den Hintergrundprozess auszuführen und den Browser durch JSDOM zu ersetzen.
Für dieses spezielle Beispiel benötigen wir drei obligatorische Header, um den API-Aufruf durchzuführen, und zwar „anonymous-user-id“, „timestamp“ und „user-sign“.
Mit XMLHttpRequest.prototype.setRequestHeader prüfen wir, ob die genannten Header in der Antwort enthalten sind oder nicht. Wenn ja, nehmen wir den Wert dieser Header und wiederholen die Wiederholungsversuche, bis wir alle Header erhalten.
Dann ist der wichtigste Teil, dass wir XMLHttpRequest.prototype.open verwenden, um die Authentifizierungsdaten zu extrahieren und Aufrufe zu tätigen, ohne tatsächlich Browser zu verwenden oder die Bot-Aktivität offenzulegen.
Am Ende von createSessionFunction wird eine Sitzung mit den erforderlichen Headern zurückgegeben.
Kommen wir nun zu unserem Hauptcode: Wir verwenden CheerioCrawler und prenavigationHooks, um die Header, die wir von der früheren Funktion erhalten haben, in den requestHandler einzufügen.
const crawler = new CheerioCrawler({
sessionPoolOptions: {
maxPoolSize: 1,
createSessionFunction: async (sessionPool) =>
createSessionFunction(sessionPool, proxyConfiguration),
},
preNavigationHooks: [
(crawlingContext) => {
const { request, session } = crawlingContext;
request.headers = {
...request.headers,
...session.userData?.headers,
};
},
],
proxyConfiguration,
});
Schließlich führen wir im Anforderungshandler den Aufruf mithilfe der Header durch und stellen sicher, wie viele Aufrufe erforderlich sind, um die gesamte Datenverarbeitungs-Paginierung abzurufen.
async requestHandler(context) {
const { log, request, json } = context;
const { userData } = request;
const { itemsCounter = 0, resultsLimit = 0 } = userData;
if (!json.data) {
throw new Error('BLOCKED');
}
const { data } = json;
const items = data.list;
const counter = itemsCounter items.length;
const dataItems = items.slice(
0,
resultsLimit && counter > resultsLimit
? resultsLimit - itemsCounter
: undefined,
);
await context.pushData(dataItems);
const {
pagination: { page, total },
} = data;
log.info(
`Scraped ${dataItems.length} results out of ${total} from search page ${page}`,
);
const isResultsLimitNotReached =
counter
Hier ist es wichtig zu beachten, dass wir diesen Code so erstellen, dass wir beliebig viele API-Aufrufe durchführen können.
In diesem speziellen Beispiel haben wir nur eine Anfrage und eine einzelne Sitzung gestellt, aber Sie können bei Bedarf auch mehr machen. Wenn der erste API-Aufruf abgeschlossen ist, wird der zweite API-Aufruf erstellt. Auch hier können Sie bei Bedarf weitere Anrufe tätigen, aber wir haben um zwei aufgehört.
Zur Verdeutlichung sehen Sie hier, wie der Codefluss aussieht:
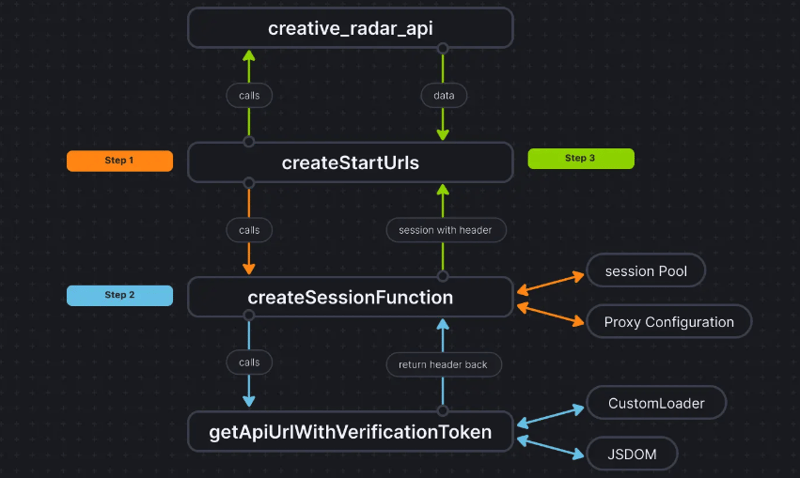
Abschluss
Dieser Ansatz hilft uns, eine dritte Möglichkeit zu finden, die Authentifizierungsdaten zu extrahieren, ohne tatsächlich einen Browser zu verwenden, und die Daten an CheerioCrawler weiterzuleiten. Dadurch wird die Leistung erheblich verbessert und der RAM-Bedarf um 50 % reduziert. Und während die browserbasierte Scraping-Leistung zehnmal langsamer ist als bei reinem Cheerio, ist JSDOM nur drei- bis viermal langsamer und damit zwei- bis dreimal schneller als browserbasierte Scraping-Leistung. basierendes Schaben.
Die Codebasis des Projekts ist hier bereits hochgeladen. Der Code ist als Apify Actor geschrieben; Mehr dazu finden Sie hier, Sie können es aber auch ohne Apify SDK ausführen.
Wenn Sie Zweifel oder Fragen zu diesem Ansatz haben, kontaktieren Sie uns auf unserem Discord-Server.
-
 Warum gibt es Streifen in meinem linearen Gradientenhintergrund und wie kann ich sie beheben?die Hintergrundstreifen aus linearem Gradienten Beim Einsatz der Linear-Gradient-Eigenschaft für einen Hintergrund können Sie auffällige Strei...Programmierung Gepostet am 2025-04-08
Warum gibt es Streifen in meinem linearen Gradientenhintergrund und wie kann ich sie beheben?die Hintergrundstreifen aus linearem Gradienten Beim Einsatz der Linear-Gradient-Eigenschaft für einen Hintergrund können Sie auffällige Strei...Programmierung Gepostet am 2025-04-08 -
Wie überprüfe ich, ob ein Objekt ein spezifisches Attribut in Python hat?Methode zur Bestimmung von Objektattribut -Existenz Diese Anfrage befriedigt eine Methode, um das Vorhandensein eines bestimmten Attributs in ...Programmierung Gepostet am 2025-04-08
-
Wie kombinieren Sie Daten aus drei MySQL -Tabellen zu einer neuen Tabelle?mySql: Erstellen einer neuen Tabelle aus Daten und Spalten von drei Tabellen Frage: Wie können ich eine neue Tabelle erstellen. Aus den Pe...Programmierung Gepostet am 2025-04-08
-
Wie vereinfachte ich JSON-Parsen in PHP für mehrdimensionale Arrays?JSON mit PHP versuchen, JSON-Daten in PHP zu analysieren, kann eine Herausforderung sein, insbesondere im Umgang mit mehrdimensionalen Arrays. U...Programmierung Gepostet am 2025-04-08
-
Wie kann ich nach der Bearbeitung von Zellen eine kundenspezifische JTable -Zell -Rendering beibehalten?beibehalten von jtable cell rendering nach cell edit in einem jtable, in dem benutzerdefinierte Zellenwiedergabe implementiert werden, kann di...Programmierung Gepostet am 2025-04-08
-
Wie umgeht ich Website -Blöcke mit Pythons Anfragen und gefälschten Benutzeragenten?wie man das Browserverhalten mit Pythons Anfragen und gefälschten Benutzeragenten simuliert Python -Anfragen sind ein mächtiges Tool, um HTTP ...Programmierung Gepostet am 2025-04-08
-
Warum hört die Ausführung von JavaScript ein, wenn die Firefox -Rückbutton verwendet wird?Navigational History Problem: JavaScript hört auf, nach der Verwendung von Firefox -Back -Schaltflächen auszuführen. Dieses Problem tritt in ande...Programmierung Gepostet am 2025-04-08
-
Wie kann ich UTF-8-Dateinamen in den Dateisystemfunktionen von PHP bewältigen?Lösung: URL codieren Dateinamen , um dieses Problem zu beheben. Verwenden Sie die Urlencode-Funktion, um den gewünschten Ordnernamen in ein U...Programmierung Gepostet am 2025-04-08
-
Python Read CSV -Datei UnicodEdeCodeError Ultimate Lösungunicode dekodieren Fehler in der CSV-Datei Reading Wenn versucht wird, eine CSV-Datei mit dem integrierten CSV-Modul zu lesen, können Sie eine...Programmierung Gepostet am 2025-04-08
-
Können Sie CSS verwenden, um die Konsolenausgabe in Chrom und Firefox zu färben?Farben in JavaScript console Ist es möglich, Chromes Konsole zu verwenden, um farbigen Text wie rot für Fehler, orange für Kriege und grün für...Programmierung Gepostet am 2025-04-08
-
Warum bekomme ich nach der Installation von Archive_zip auf meinem Linux -Server eine "Klasse" ziparchive \ 'nicht gefunden?class 'ziparchive' kein Fehler gefunden, während Archive_zip auf Linux Server Symptom installiert wird: beim Versuch, ein Skript zu ...Programmierung Gepostet am 2025-04-08
-
Muss ich vor dem Programm Exit explizit Heap -Zuordnungen in C ++ löschen?explizites Löschen in C trotz des Programms exit Wenn Sie mit einer dynamischen Speicherzuweisung in C arbeiten, fragen sich Entwickler oft, o...Programmierung Gepostet am 2025-04-08
-
Wie kann ich mit dem Python -Verständnis Wörterbücher effizient erstellen?Python Dictionary Verständnis In Python bieten Dictionary -Verständnisse eine kurze Möglichkeit, neue Wörterbücher zu generieren. Während sie de...Programmierung Gepostet am 2025-04-08
-
Warum erscheint mein CSS -Hintergrundbild nicht?Fehlerbehebung: CSS -Hintergrundbild erscheinen nicht Sie haben auf ein Problem gestoßen, bei dem Ihr Hintergrundbild trotz der folgenden Tuto...Programmierung Gepostet am 2025-04-08
-
Wie kann man sich geweigert, das Skript zu laden ... \ "Fehler aufgrund der Inhaltssicherheitsrichtlinie von Android?enthüllen die mystery: Inhaltssicherheit Richtlinienfehler begegnen dem rätselhaften Fehler ", das Skript zu laden ..." beim Bereits...Programmierung Gepostet am 2025-04-08















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









