 Titelseite > Programmierung > K Nearest Neighbors Regression, Regression: Überwachtes maschinelles Lernen
Titelseite > Programmierung > K Nearest Neighbors Regression, Regression: Überwachtes maschinelles Lernen
K Nearest Neighbors Regression, Regression: Überwachtes maschinelles Lernen
 Durchsuche:360
Durchsuche:360
k-Nächste-Nachbarn-Regression
Diek-Nearest Neighbors (k-NN)-Regression ist eine nichtparametrische Methode, die den Ausgabewert basierend auf dem Durchschnitt (oder gewichteten Durchschnitt) der k-nächsten Trainingsdatenpunkte im Merkmalsraum vorhersagt. Dieser Ansatz kann komplexe Beziehungen in Daten effektiv modellieren, ohne eine bestimmte funktionale Form anzunehmen.
Die k-NN-Regressionsmethode kann wie folgt zusammengefasst werden:
- Distanzmetrik: Der Algorithmus verwendet eine Distanzmetrik (üblicherweise eine euklidische Distanz), um die „Nähe“ von Datenpunkten zu bestimmen.
- k Nachbarn: Der Parameter k gibt an, wie viele nächste Nachbarn bei Vorhersagen berücksichtigt werden sollen.
- Vorhersage: Der vorhergesagte Wert für einen neuen Datenpunkt ist der Durchschnitt der Werte seiner k nächsten Nachbarn.
Schlüsselkonzepte
Nicht parametrisch: Im Gegensatz zu parametrischen Modellen nimmt k-NN keine spezifische Form für die zugrunde liegende Beziehung zwischen den Eingabemerkmalen und der Zielvariablen an. Dies macht es flexibel bei der Erfassung komplexer Muster.
Entfernungsberechnung: Die Wahl der Entfernungsmetrik kann die Leistung des Modells erheblich beeinflussen. Zu den gängigen Maßen gehören Euklidische, Manhattan- und Minkowski-Entfernungen.
Auswahl von k: Die Anzahl der Nachbarn (k) kann basierend auf einer Kreuzvalidierung ausgewählt werden. Ein kleines k kann zu einer Überanpassung führen, während ein großes k die Vorhersage zu sehr glätten und möglicherweise zu einer Unteranpassung führen kann.
Beispiel für die k-Nächste-Nachbarn-Regression
Dieses Beispiel zeigt, wie man die k-NN-Regression mit Polynommerkmalen verwendet, um komplexe Beziehungen zu modellieren und gleichzeitig die nichtparametrische Natur von k-NN zu nutzen.
Beispiel für einen Python-Code
1. Bibliotheken importieren
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import PolynomialFeatures from sklearn.neighbors import KNeighborsRegressor from sklearn.metrics import mean_squared_error, r2_score
Dieser Block importiert die notwendigen Bibliotheken für Datenmanipulation, Darstellung und maschinelles Lernen.
2. Beispieldaten generieren
np.random.seed(42) # For reproducibility X = np.linspace(0, 10, 100).reshape(-1, 1) y = 3 * X.ravel() np.sin(2 * X.ravel()) * 5 np.random.normal(0, 1, 100)
Dieser Block generiert Beispieldaten, die eine Beziehung mit etwas Rauschen darstellen und reale Datenvariationen simulieren.
3. Teilen Sie den Datensatz auf
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Dieser Block teilt den Datensatz in Trainings- und Testsätze zur Modellbewertung auf.
4. Polynom-Features erstellen
degree = 3 # Change this value for different polynomial degrees poly = PolynomialFeatures(degree=degree) X_poly_train = poly.fit_transform(X_train) X_poly_test = poly.transform(X_test)
Dieser Block generiert Polynommerkmale aus den Trainings- und Testdatensätzen, sodass das Modell nichtlineare Beziehungen erfassen kann.
5. Erstellen und trainieren Sie das k-NN-Regressionsmodell
k = 5 # Number of neighbors knn_model = KNeighborsRegressor(n_neighbors=k) knn_model.fit(X_poly_train, y_train)
Dieser Block initialisiert das k-NN-Regressionsmodell und trainiert es mithilfe der aus dem Trainingsdatensatz abgeleiteten Polynommerkmale.
6. Vorhersagen treffen
y_pred = knn_model.predict(X_poly_test)
Dieser Block verwendet das trainierte Modell, um Vorhersagen zum Testsatz zu treffen.
7. Zeichnen Sie die Ergebnisse auf
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='Data Points')
X_grid = np.linspace(0, 10, 1000).reshape(-1, 1)
X_poly_grid = poly.transform(X_grid)
y_grid = knn_model.predict(X_poly_grid)
plt.plot(X_grid, y_grid, color='red', linewidth=2, label=f'k-NN Regression (k={k}, Degree {degree})')
plt.title(f'k-NN Regression (Polynomial Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
Dieser Block erstellt ein Streudiagramm der tatsächlichen Datenpunkte im Vergleich zu den vorhergesagten Werten aus dem k-NN-Regressionsmodell und visualisiert die angepasste Kurve.
Ausgabe mit k = 1:
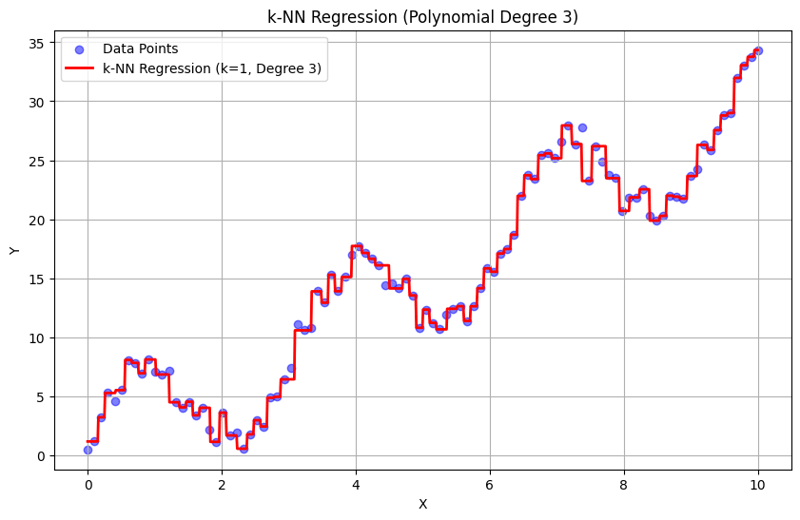
Ausgabe mit k = 10:
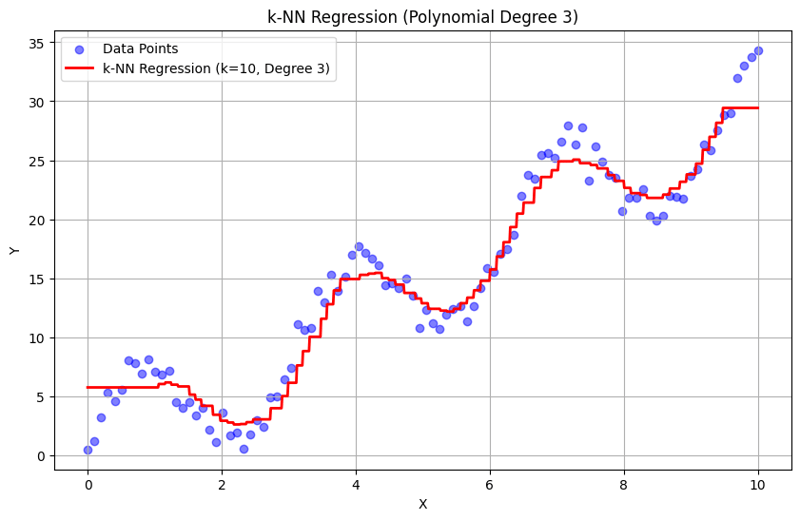
Dieser strukturierte Ansatz zeigt, wie die k-Nearest Neighbors-Regression mit Polynommerkmalen implementiert und ausgewertet wird. Durch die Erfassung lokaler Muster durch Mittelung der Antworten benachbarter Nachbarn modelliert die k-NN-Regression komplexe Beziehungen in Daten effektiv und bietet gleichzeitig eine unkomplizierte Implementierung. Die Wahl von k und Polynomgrad hat erheblichen Einfluss auf die Leistung und Flexibilität des Modells bei der Erfassung zugrunde liegender Trends.
-
 Wie beheben Sie die "ungültige Verwendung der Gruppenfunktion" in MySQL beim Finden der Maximalzahl?wie man die maximale zählende mit mysql in mysql abrufen Wählen Sie max (count (*)) aus der Emp1 -Gruppe nach Namen; ERROR 1111 (HY000): Ungül...Programmierung Gepostet am 2025-07-14
Wie beheben Sie die "ungültige Verwendung der Gruppenfunktion" in MySQL beim Finden der Maximalzahl?wie man die maximale zählende mit mysql in mysql abrufen Wählen Sie max (count (*)) aus der Emp1 -Gruppe nach Namen; ERROR 1111 (HY000): Ungül...Programmierung Gepostet am 2025-07-14 -
Wie kann ich programmgesteuert den gesamten Text in einer DIV auf Mausklick auswählen?programmatisch den Div -Text in Maus auswählen klicken Frage angegeben ein DIV -Element mit Textinhalten, wie kann der Benutzer programmatisch...Programmierung Gepostet am 2025-07-14
-
Können Sie CSS verwenden, um die Konsolenausgabe in Chrom und Firefox zu färben?Farben in JavaScript console Ist es möglich, Chromes Konsole zu verwenden, um farbigen Text wie rot für Fehler, orange für Kriege und grün für...Programmierung Gepostet am 2025-07-14
-
Gibt es einen Leistungsunterschied zwischen der Verwendung einer For-Each-Schleife und einem Iterator für die Sammlung durchquert in Java?für jede Schleife vs. Iterator: Effizienz in der Sammlung traversal Einführung beim Durchlaufen einer Sammlung in Java, die Auswahl an der...Programmierung Gepostet am 2025-07-14
-
Spark DataFrame -Tipps, um konstante Spalten hinzuzufügenErstellen einer konstanten Spalte in einem Spark DataFrame Hinzufügen einer konstanten Spalte zu einem Spark DataFrame mit einem willkürlichen...Programmierung Gepostet am 2025-07-14
-
So laden Sie Dateien mit zusätzlichen Parametern mit java.net.urlconnection und Multipart/Form-Data-Codierung hoch?Dateien mit Http-Anfragen hochladen , um Dateien auf einen HTTP-Server hochzuladen und gleichzeitig zusätzliche Parameter zu senden. Hier ist e...Programmierung Gepostet am 2025-07-14
-
Wie setze ich Tasten in JavaScript -Objekten dynamisch ein?wie man einen dynamischen Schlüssel für eine JavaScript -Objektvariable erstellt beim Versuch, einen dynamischen Schlüssel für ein JavaScript -O...Programmierung Gepostet am 2025-07-14
-
`console.log` zeigt den Grund für die modifizierte Objektwertausnahme anobjekte und console.log: Eine Kuriosität enträtselte Wenn Sie mit Objekten und Console.log arbeiten, können Sie ein merkwürdiges Verhalten auf...Programmierung Gepostet am 2025-07-14
-
Wie kann ich bei der Erstellung von SQL -Abfragen in Go sicher Text und Werte verkettet?concattenieren Text und Werte in Go SQL -Abfragen Bei der Erstellung eines Text -SQL -Abfrages in GO, es gibt bestimmte Syntax -Regeln, die be...Programmierung Gepostet am 2025-07-14
-
Wie erstelle ich in Python dynamische Variablen?dynamische variable Erstellung in Python Die Fähigkeit, dynamisch Variablen zu erstellen, kann ein leistungsstarkes Tool sein, insbesondere we...Programmierung Gepostet am 2025-07-14
-
Python Metaclass -Arbeitsprinzip und Klassenerstellung und -anpassungWas sind Metaklassen in Python? Metaklassen sind dafür verantwortlich, Klassenobjekte in Python zu erstellen. So wie Klassen Instanzen erstellen...Programmierung Gepostet am 2025-07-14
-
Methode zur korrekten Umwandlung von Latin1 -Zeichen in UTF8 in UTF8 MySQL -Tabellekonvertieren Latein1 -Zeichen in einer utf8 -Tabelle in utf8 Sie haben auf ein Problem gestoßen. rufen Sie. Um dies zu lösen, versuchen Sie,...Programmierung Gepostet am 2025-07-14
-
Wie kann ich Zeilen effizient basierend auf zwei Bedingungen in MySQL einfügen oder aktualisieren?in zwei Bedingungen einfügen oder aktualisieren. Bestehende Zeile Wenn eine Übereinstimmung gefunden wird. Lösung: Die Antwort liegt in MyS...Programmierung Gepostet am 2025-07-14
-
Lösen Sie den \\ "String -Wert -Fehler \\" -Ausnahme, wenn MySQL Emoji einfügtdie falsche String -Wert -Ausnahme beheben, wenn er Emoji beim Versuch, eine Zeichenfolge mit Emoji -Zeichen in eine mysql -Datenbank einzufügen...Programmierung Gepostet am 2025-07-14
-
Warum nicht "Körper {Rand: 0; } `Immer den oberen Rand in CSS entfernen?adressieren die Entfernung von Körperrand in CSS Für Anfänger -Webentwickler kann das Entfernen des Randes des Körperelements eine verwirrende...Programmierung Gepostet am 2025-07-14















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









