 Titelseite > Programmierung > Funktionsauswahl mit dem IAMB-Algorithmus: Ein lockerer Einblick in maschinelles Lernen
Titelseite > Programmierung > Funktionsauswahl mit dem IAMB-Algorithmus: Ein lockerer Einblick in maschinelles Lernen
Funktionsauswahl mit dem IAMB-Algorithmus: Ein lockerer Einblick in maschinelles Lernen
 Durchsuche:999
Durchsuche:999
Also, hier ist die Geschichte: Ich habe kürzlich an einer Schulaufgabe von Professor Zhuang gearbeitet, bei der es um einen ziemlich coolen Algorithmus namens Incremental Association Markov Blanket (IAMB) ging. Nun, ich habe keinen Hintergrund in Datenwissenschaft oder Statistik, das ist also Neuland für mich, aber ich liebe es, etwas Neues zu lernen. Das Ziel? Verwenden Sie IAMB, um Features in einem Datensatz auszuwählen und zu sehen, wie sie sich auf die Leistung eines Modells für maschinelles Lernen auswirken.
Wir gehen die Grundlagen des IAMB-Algorithmus durch und wenden ihn auf den Diabetes-Datensatz der Pima-Indianer aus den Datensätzen von Jason Brownlee an. Dieser Datensatz erfasst Gesundheitsdaten von Frauen und berücksichtigt, ob sie an Diabetes leiden oder nicht. Wir werden IAMB verwenden, um herauszufinden, welche Merkmale (wie BMI oder Glukosespiegel) für die Vorhersage von Diabetes am wichtigsten sind.
Was ist der IAMB-Algorithmus und warum wird er verwendet?
Der IAMB-Algorithmus ist wie ein Freund, der Ihnen hilft, eine Liste der Verdächtigen in einem Rätsel zu bereinigen – es handelt sich um eine Merkmalsauswahlmethode, die darauf ausgelegt ist, nur die Variablen auszuwählen, die für die Vorhersage Ihres Ziels wirklich wichtig sind. In diesem Fall geht es darum, ob jemand Diabetes hat.
- Vorwärtsphase: Fügen Sie Variablen hinzu, die einen starken Bezug zum Ziel haben.
- Rückwärtsphase: Entfernen Sie die Variablen, die nicht wirklich helfen, und stellen Sie sicher, dass nur die wichtigsten übrig bleiben.
Einfacher ausgedrückt hilft uns IAMB dabei, Unordnung in unserem Datensatz zu vermeiden, indem es nur die relevantesten Funktionen auswählt. Dies ist besonders praktisch, wenn Sie die Dinge einfach halten, die Modellleistung steigern und die Trainingszeit verkürzen möchten.
Quelle: Algorithmen für die Markov-Decken-Entdeckung im großen Maßstab
Was ist dieses Alpha-Ding und warum ist es wichtig?
Hier kommt Alpha ins Spiel. In der Statistik ist Alpha (α) der Schwellenwert, den wir festlegen, um zu entscheiden, was als „statistisch signifikant“ gilt. Als Teil der Anweisungen des Professors habe ich einen Alpha-Wert von 0,05 verwendet, was bedeutet, dass ich nur Funktionen beibehalten möchte, bei denen die Wahrscheinlichkeit, dass sie zufällig mit der Zielvariablen verknüpft werden, weniger als 5 % beträgt. Wenn also der p-Wert eines Merkmals kleiner als 0,05 ist, bedeutet dies, dass eine starke, statistisch signifikante Assoziation mit unserem Ziel besteht.
Durch die Verwendung dieses Alpha-Schwellenwerts konzentrieren wir uns nur auf die aussagekräftigsten Variablen und ignorieren alle Variablen, die unseren „Signifikanz“-Test nicht bestehen. Es ist wie ein Filter, der die relevantesten Funktionen behält und das Rauschen ausblendet.
Praktische Anwendung: Verwendung von IAMB für den Diabetes-Datensatz der Pima-Indianer
Hier ist der Aufbau: Der Diabetes-Datensatz der Pima-Indianer enthält Gesundheitsmerkmale (Blutdruck, Alter, Insulinspiegel usw.) und unser Ziel, Ergebnis (ob jemand Diabetes hat).
Zuerst laden wir die Daten und prüfen sie:
import pandas as pd # Load and preview the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv' column_names = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome'] data = pd.read_csv(url, names=column_names) print(data.head())
Implementierung von IAMB mit Alpha = 0,05
Hier ist unsere aktualisierte Version des IAMB-Algorithmus. Wir verwenden p-Werte, um zu entscheiden, welche Features beibehalten werden sollen, sodass nur diejenigen ausgewählt werden, deren p-Werte kleiner als unser Alpha (0,05) sind.
import pingouin as pg
def iamb(target, data, alpha=0.05):
markov_blanket = set()
# Forward Phase: Add features with a p-value alpha
for feature in list(markov_blanket):
reduced_mb = markov_blanket - {feature}
result = pg.partial_corr(data=data, x=feature, y=target, covar=reduced_mb)
p_value = result.at[0, 'p-val']
if p_value > alpha:
markov_blanket.remove(feature)
return list(markov_blanket)
# Apply the updated IAMB function on the Pima dataset
selected_features = iamb('Outcome', data, alpha=0.05)
print("Selected Features:", selected_features)
Als ich dies ausführte, erhielt ich eine verfeinerte Liste von Merkmalen, von denen das IAMB annahm, dass sie am engsten mit den Diabetes-Ergebnissen zusammenhängen. Diese Liste hilft dabei, die Variablen einzugrenzen, die wir zum Erstellen unseres Modells benötigen.
Selected Features: ['BMI', 'DiabetesPedigreeFunction', 'Pregnancies', 'Glucose']
Testen der Auswirkungen von IAMB-ausgewählten Funktionen auf die Modellleistung
Sobald wir unsere ausgewählten Funktionen haben, vergleicht der eigentliche Test die Modellleistung mit allen Funktionen mit IAMB-ausgewählten Funktionen. Hierfür habe ich mich für ein einfaches Gaußsches Naive-Bayes-Modell entschieden, weil es unkompliziert ist und gut mit Wahrscheinlichkeiten zurechtkommt (was mit der gesamten Bayes'schen Atmosphäre übereinstimmt).
Hier ist der Code zum Trainieren und Testen des Modells:
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
# Split data
X = data.drop('Outcome', axis=1)
y = data['Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Model with All Features
model_all = GaussianNB()
model_all.fit(X_train, y_train)
y_pred_all = model_all.predict(X_test)
# Model with IAMB-Selected Features
X_train_selected = X_train[selected_features]
X_test_selected = X_test[selected_features]
model_iamb = GaussianNB()
model_iamb.fit(X_train_selected, y_train)
y_pred_iamb = model_iamb.predict(X_test_selected)
# Evaluate models
results = {
'Model': ['All Features', 'IAMB-Selected Features'],
'Accuracy': [accuracy_score(y_test, y_pred_all), accuracy_score(y_test, y_pred_iamb)],
'F1 Score': [f1_score(y_test, y_pred_all, average='weighted'), f1_score(y_test, y_pred_iamb, average='weighted')],
'AUC-ROC': [roc_auc_score(y_test, y_pred_all), roc_auc_score(y_test, y_pred_iamb)]
}
results_df = pd.DataFrame(results)
display(results_df)
Ergebnisse
So sieht der Vergleich aus:
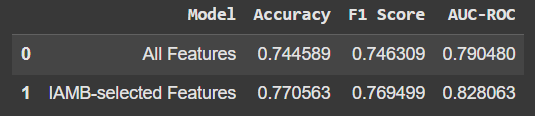
Die Verwendung nur der von IAMB ausgewählten Funktionen führte zu einer leichten Verbesserung der Genauigkeit und anderer Metriken. Es ist kein großer Sprung, aber die Tatsache, dass wir mit weniger Funktionen eine bessere Leistung erzielen, ist vielversprechend. Außerdem bedeutet dies, dass unser Modell nicht auf „Rauschen“ oder irrelevanten Daten basiert.
Wichtige Erkenntnisse
- IAMB eignet sich hervorragend für die Funktionsauswahl: Es hilft dabei, unseren Datensatz zu bereinigen, indem es sich nur auf das konzentriert, was für die Vorhersage unseres Ziels wirklich wichtig ist.
- Weniger ist oft mehr: Manchmal führen weniger Funktionen zu besseren Ergebnissen, wie wir hier mit einer kleinen Steigerung der Modellgenauigkeit gesehen haben.
- Lernen und Experimentieren macht Spaß: Auch ohne fundierte Kenntnisse in der Datenwissenschaft eröffnet das Eintauchen in Projekte wie dieses neue Möglichkeiten, Daten und maschinelles Lernen zu verstehen.
Ich hoffe, dies ist eine freundliche Einführung in IAMB! Wenn Sie neugierig sind, probieren Sie es aus – es ist ein praktisches Werkzeug in der Toolbox für maschinelles Lernen, und vielleicht sehen Sie einige coole Verbesserungen in Ihren eigenen Projekten.
Quelle: Algorithmen für die Markov-Decken-Entdeckung im großen Maßstab
-
 Wie kann ich einheitenlose CSS-Variablen mit unterschiedlichen Einheiten verwenden?So verwenden Sie einheitenlose CSS-Variablen mit FlexibilitätEinheitenlose CSS-Variablen bieten die Möglichkeit, numerische Werte zu speichern, die be...Programmierung Veröffentlicht am 18.11.2024
Wie kann ich einheitenlose CSS-Variablen mit unterschiedlichen Einheiten verwenden?So verwenden Sie einheitenlose CSS-Variablen mit FlexibilitätEinheitenlose CSS-Variablen bieten die Möglichkeit, numerische Werte zu speichern, die be...Programmierung Veröffentlicht am 18.11.2024 -
Ausführen einer Funktion, wenn ein #await-Block in Svelte(Kit) aufgelöst wirdZum Inhalt springen: Über den #await-Block in Svelte Eine Funktion ausführen (auslösen), wenn der #await-Block aufgelöst oder abgelehnt wird Korrigier...Programmierung Veröffentlicht am 18.11.2024
-
Jenseits von „if“-Anweisungen: Wo sonst kann ein Typ mit einer expliziten „bool“-Konvertierung ohne Umwandlung verwendet werden?Kontextuelle Konvertierung in bool ohne Umwandlung zulässigIhre Klasse definiert eine explizite Konvertierung in bool, sodass Sie ihre Instanz „t“ dir...Programmierung Veröffentlicht am 18.11.2024
-
Können Sie mehrere Klassen in einer einzigen Java-Datei haben?Mehrere Klassen in einer Java-DateiIn Java ist es möglich, mehrere Klassen in einer einzigen .java-Datei zu haben. Es kann jedoch nur eine öffentliche...Programmierung Veröffentlicht am 18.11.2024
-
Was ist mit dem Spaltenversatz in Bootstrap 4 Beta passiert?Bootstrap 4 Beta: Die Entfernung und Wiederherstellung des SpaltenversatzesBootstrap 4 führte in seiner Beta-1-Version wesentliche Änderungen an der A...Programmierung Veröffentlicht am 18.11.2024
-
Wie kombiniere ich zwei assoziative Arrays in PHP und behalte dabei eindeutige IDs bei und verarbeite doppelte Namen?Kombinieren assoziativer Arrays in PHPIn PHP ist das Kombinieren zweier assoziativer Arrays zu einem einzigen Array eine häufige Aufgabe. Betrachten S...Programmierung Veröffentlicht am 18.11.2024
-
Wie kann man PDO-Datenbankverbindungen testen und Fehler effektiv behandeln?Testen von PDO-DatenbankverbindungenBei der Entwicklung von Datenbankinstallationen ist es wichtig, die Gültigkeit von Datenbankverbindungen sicherzus...Programmierung Veröffentlicht am 18.11.2024
-
Überschreiben MySQL-Update-Abfragen vorhandene Werte, wenn sie gleich sind?MySQL-Aktualisierungsabfragen: Vorhandene Werte überschreibenIn MySQL kann es beim Aktualisieren einer Tabelle zu einem Szenario kommen, in dem der ne...Programmierung Veröffentlicht am 18.11.2024
-
Warum verwendet der Store von „std::atomic“ XCHG für sequentielle Konsistenz auf x86?Warum der Store von std::atomic XCHG für sequentielle Konsistenz verwendetIm Kontext von std::atomic für x86- und x86_64-Architekturen a Der Speicherv...Programmierung Veröffentlicht am 18.11.2024
-
Warum unterstützt C++ die Rückgabe von Arrays aus Funktionen nicht direkt?Warum C Array-Rückgabefunktionen ablehntDie C-LandschaftIm Gegensatz zu Sprachen wie Java ist dies bei C der Fall Bietet keine direkte Unterstützung f...Programmierung Veröffentlicht am 18.11.2024
-
Okay, hier sind einige Titel, die zum Inhalt des Artikels passen würden: * So beheben Sie den Fehler „-lGL: nicht gefunden“ in Qt * Qt-Kompilierungsfehler: „-lGL: nicht gefunden“ – was zu tun ist * Fehlerbehebung beim Fehler „-lGL: nicht gefunden“ in Qt-Behebung des Fehlers „-lGL: nicht gefunden“ in QtBeim Versuch, ein neu erstelltes Projekt in QtCreator zu kompilieren, kann es bei einigen Benutzern z...Programmierung Veröffentlicht am 18.11.2024
-
Ist die Verwendung der „eval“-Funktion von PHP jemals sicher?Wann (wenn überhaupt) ist eval NICHT böse?Obwohl von der eval-Funktion von PHP oft abgeraten wurde, ist ihr Nutzen in PHP 5.3 umstritten . Trotz des A...Programmierung Veröffentlicht am 18.11.2024
-
Wie behebt man „Unsachgemäß konfiguriert: Fehler beim Laden des MySQLdb-Moduls“ in Django unter macOS?MySQL falsch konfiguriert: Das Problem mit relativen PfadenBeim Ausführen von python manage.py runserver in Django kann der folgende Fehler auftreten:...Programmierung Veröffentlicht am 18.11.2024
-
Wie entmarshaliere ich XML mit dynamischen Attributen in Go?Golang: Unmarshalling von XML mit dynamischen AttributenEinführung:In Go bietet binding/xml eine effiziente und vielseitige Möglichkeit, XML-Daten zu ...Programmierung Veröffentlicht am 18.11.2024
-
Wie kann ich mit MySQL Benutzer mit den heutigen Geburtstagen finden?So identifizieren Sie Benutzer mit den heutigen Geburtstagen mithilfe von MySQLUm mithilfe von MySQL festzustellen, ob heute der Geburtstag eines Benu...Programmierung Veröffentlicht am 18.11.2024















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









