
Entropix: Stichprobentechniken zur Maximierung der Inferenzleistung
 Durchsuche:977
Durchsuche:977
Entropix: Stichprobentechniken zur Maximierung der Inferenzleistung
Laut Entropix README verwendet Entropix eine entropiebasierte Sampling-Methode. In diesem Artikel werden die spezifischen Probenahmetechniken basierend auf Entropie und Varentropie erläutert.
Entropie und Varentropie
Beginnen wir mit der Erläuterung von Entropie und Varentropie, da diese Schlüsselfaktoren bei der Bestimmung der Probenahmestrategie sind.
Entropie
In der Informationstheorie ist Entropie ein Maß für die Unsicherheit einer Zufallsvariablen. Die Entropie einer Zufallsvariablen X wird durch die folgende Gleichung definiert:
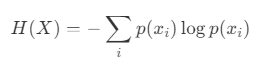
- X: Eine diskrete Zufallsvariable.
- x_i: Der i-te mögliche Zustand von X.
- p(x_i): Die Wahrscheinlichkeit des Zustands x_i.
Die Entropie ist maximiert, wenn die Wahrscheinlichkeitsverteilung gleichmäßig ist. Wenn umgekehrt ein bestimmter Zustand viel wahrscheinlicher ist als andere, nimmt die Entropie ab.
Varentropie
Varentropie, eng verwandt mit der Entropie, repräsentiert die Variabilität im Informationsgehalt. Unter Berücksichtigung des Informationsgehalts I(X), der Entropie H(X) und der Varianz für eine Zufallsvariable X ist Varentropie V E(X) wie folgt definiert:
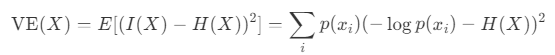
Varentropie wird groß, wenn die Wahrscheinlichkeiten p(x_i) stark variieren. Sie wird klein, wenn die Wahrscheinlichkeiten einheitlich sind – entweder wenn die Verteilung maximale Entropie hat oder wenn ein Wert eine Wahrscheinlichkeit von 1 und alle anderen eine Wahrscheinlichkeit von 0 haben.
Probenahmemethoden
Als nächstes untersuchen wir, wie sich Sampling-Strategien basierend auf Entropie- und Varentropiewerten ändern.
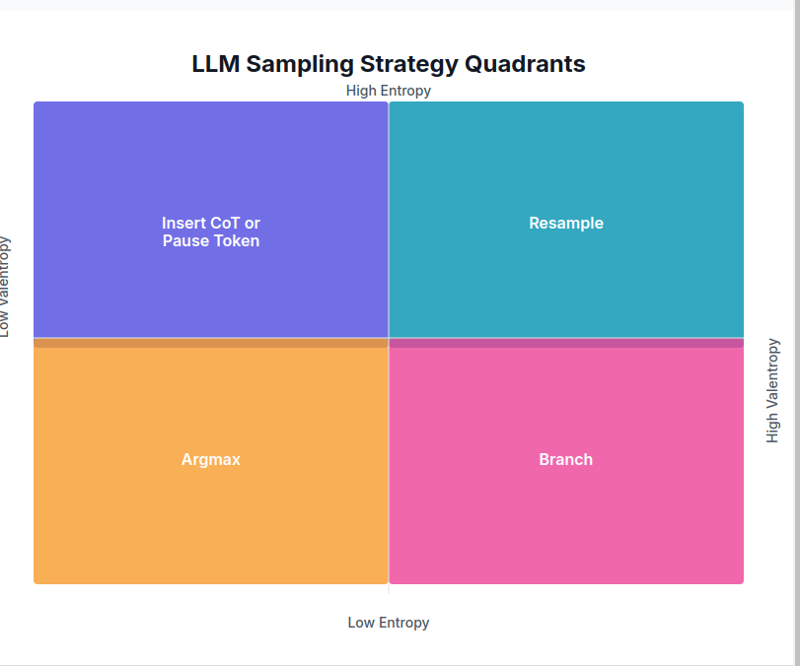
1. Niedrige Entropie, niedrige Varentropie → Argmax
In diesem Szenario hat ein bestimmter Token eine viel höhere Vorhersagewahrscheinlichkeit als die anderen. Da das nächste Token fast sicher ist, wird Argmax verwendet.
if entCode-Link
2. Niedrige Entropie, hohe Varentropie → Zweig
Dies geschieht, wenn ein gewisses Maß an Vertrauen besteht, aber mehrere praktikable Optionen vorhanden sind. In diesem Fall wird die Strategie Branch verwendet, um aus mehreren Auswahlmöglichkeiten Stichproben zu ziehen und das beste Ergebnis auszuwählen.
elif ent 5.0: temp_adj = 1.2 0.3 * interaction_strength top_k_adj = max(5, int(top_k * (1 0.5 * (1 - agreement)))) return _sample(logits, temperature=min(1.5, temperature * temp_adj), top_p=top_p, top_k=top_k_adj, min_p=min_p, generator=generator)Code-Link
Obwohl diese Strategie „Branch“ genannt wird, scheint der aktuelle Code den Sampling-Bereich anzupassen und einen einzelnen Pfad auszuwählen. (Wenn jemand mehr Einblick hat, wäre ich für weitere Erläuterungen dankbar.)
3. Hohe Entropie, niedrige Varentropie → CoT oder Pause-Token einfügen
Wenn die Vorhersagewahrscheinlichkeiten des nächsten Tokens ziemlich einheitlich sind, was darauf hinweist, dass der nächste Kontext nicht sicher ist, wird ein Klärungstoken eingefügt, um die Mehrdeutigkeit aufzulösen.
elif ent > 3.0 and ventCode-Link
4. Hohe Entropie, hohe Varentropie → Neuabtastung
In diesem Fall gibt es mehrere Kontexte und die Vorhersagewahrscheinlichkeiten des nächsten Tokens sind gering. Es wird eine Resampling-Strategie mit einer höheren Temperatureinstellung und einem niedrigeren Top-P verwendet.
elif ent > 5.0 and vent > 5.0: temp_adj = 2.0 0.5 * attn_vent top_p_adj = max(0.5, top_p - 0.2 * attn_ent) return _sample(logits, temperature=max(2.0, temperature * temp_adj), top_p=top_p_adj, top_k=top_k, min_p=min_p, generator=generator)Code-Link
Zwischenfälle
Wenn keine der oben genannten Bedingungen erfüllt ist, wird adaptives Sampling durchgeführt. Es werden mehrere Proben entnommen und der beste Stichprobenwert wird basierend auf Entropie-, Varentropie- und Aufmerksamkeitsinformationen berechnet.
else: return adaptive_sample( logits, metrics, gen_tokens, n_samples=5, base_temp=temperature, base_top_p=top_p, base_top_k=top_k, generator=generator )Code-Link
Referenzen
- Entropix-Repository
- Was macht Entropix?
-
 Wie löste ich den Fehler "Der Dateityp nicht erraten, Anwendung/Oktett-Stream ..." in Appengine?appengine statische Datei mime type override In Appengine können statische Datei Handler gelegentlich den richtigen MIME -Typ überschreiben, w...Programmierung Gepostet am 2025-07-08
Wie löste ich den Fehler "Der Dateityp nicht erraten, Anwendung/Oktett-Stream ..." in Appengine?appengine statische Datei mime type override In Appengine können statische Datei Handler gelegentlich den richtigen MIME -Typ überschreiben, w...Programmierung Gepostet am 2025-07-08 -
Wie kann ich UTF-8-Dateinamen in den Dateisystemfunktionen von PHP bewältigen?Lösung: URL codieren Dateinamen , um dieses Problem zu beheben. Verwenden Sie die Urlencode-Funktion, um den gewünschten Ordnernamen in ein U...Programmierung Gepostet am 2025-07-08
-
Wie beheben Sie die Diskrepanzen für Modulpfade in Go -Mod mithilfe der Richtlinie Ersetzen?überwinden Modulpfad -Diskrepanz in go mod Wenn GO mod verwendet wird, ist es möglich, auf einen Konflikt zu begegnen, bei dem ein Drittanbiet...Programmierung Gepostet am 2025-07-08
-
Python Read CSV -Datei UnicodEdeCodeError Ultimate Lösungunicode dekodieren Fehler in der CSV-Datei Reading Wenn versucht wird, eine CSV-Datei mit dem integrierten CSV-Modul zu lesen, können Sie eine...Programmierung Gepostet am 2025-07-08
-
Können CSS HTML -Elemente basierend auf einem Attributwert finden?html Elemente mit einem Attributwert in CSS In CSS sind es möglich, Elemente zu zielen, die auf bestimmten Attributen basieren, wie im folgend...Programmierung Gepostet am 2025-07-08
-
Python Metaclass -Arbeitsprinzip und Klassenerstellung und -anpassungWas sind Metaklassen in Python? Metaklassen sind dafür verantwortlich, Klassenobjekte in Python zu erstellen. So wie Klassen Instanzen erstellen...Programmierung Gepostet am 2025-07-08
-
Wie fixiere ich \ "mysql_config, die bei der Installation von MySQL-Python auf Ubuntu/Linux nicht gefunden wurden?mySql-python-Installationsfehler: "mysql_config nicht gefunden" versuchen, mySQL-Python auf Ubuntu/Linux zu installieren. Dieser Feh...Programmierung Gepostet am 2025-07-08
-
Wie fahre ich gleichzeitig asynchrone Vorgänge aus und behandeln Fehler in JavaScript ordnungsgemäß?gleichzeitlich erwartet die Operation Execution Der in Frage stehende Code -Snippet begegnet ein Problem, wenn Asynchronous -Operationen ausge...Programmierung Gepostet am 2025-07-08
-
Wie konvertieren Sie eine Pandas -Datenfream -Spalte in das DateTime -Format und filtern nach Datum?pandas dataframe -spalte in datetime format szenario: Daten in einem Pandas DataFrame existieren häufig in verschiedenen Formaten, einschlie...Programmierung Gepostet am 2025-07-08
-
Wie überprüfe ich, ob ein Objekt ein spezifisches Attribut in Python hat?Methode zur Bestimmung von Objektattribut -Existenz Diese Anfrage befriedigt eine Methode, um das Vorhandensein eines bestimmten Attributs in ...Programmierung Gepostet am 2025-07-08
-
Wie kann ich Werte von zwei gleichen Arrays in PHP synchron iterieren und drucken?synchron iterierend und drucken Werte aus zwei Arrays derselben Größe beim Erstellen einer Selectbox unter Verwendung von zwei Arrays gleicher G...Programmierung Gepostet am 2025-07-08
-
Gibt es einen Leistungsunterschied zwischen der Verwendung einer For-Each-Schleife und einem Iterator für die Sammlung durchquert in Java?für jede Schleife vs. Iterator: Effizienz in der Sammlung traversal Einführung beim Durchlaufen einer Sammlung in Java, die Auswahl an der...Programmierung Gepostet am 2025-07-08
-
Wie kann ich mehrere Benutzertypen (Schüler, Lehrer und Administratoren) in ihre jeweiligen Aktivitäten in einer Firebase -App umleiten?rot: Wie man mehrere Benutzertypen zu jeweiligen Aktivitäten umleitet Login. Der aktuelle Code verwaltet die Umleitung für zwei Benutzertypen erf...Programmierung Gepostet am 2025-07-08
-
Wie begrenzt ich den Scroll-Bereich eines Elements in einem dynamisch großen übergeordneten Element?implementieren CSS -Höhenlimits für vertikale Scrolling -Elemente in einer interaktiven Schnittstelle und kontrollieren des Bildlaufverhaltens...Programmierung Gepostet am 2025-07-08
-
Warum können Java nicht generische Arrays erstellen?generic Array Creation error Frage: , wenn wir versuchen, eine Array von generischen Klassen zu erstellen. ArrayList [2]; public static A...Programmierung Gepostet am 2025-07-08















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









