 Titelseite > Programmierung > Umfassende Wetterdatenanalyse mit Python: Temperatur, Niederschlagstrends und Visualisierungen
Titelseite > Programmierung > Umfassende Wetterdatenanalyse mit Python: Temperatur, Niederschlagstrends und Visualisierungen
Umfassende Wetterdatenanalyse mit Python: Temperatur, Niederschlagstrends und Visualisierungen
 Durchsuche:186
Durchsuche:186
-
Wetterdatenanalyse und -vorhersage für verschiedene Städte in Kenia
- Einführung
- Datensatzübersicht
- Explorative Datenanalyse
- Visualisierung wichtiger Wetterfunktionen
- Wetterzustandsanalyse
- Stadtbezogener Niederschlag
- Durchschnittliche Monatstemperatur
- Durchschnittlicher monatlicher Niederschlag
- Korrelation zwischen Wettervariablen
- Fallstudie: Stadtspezifische Trends
- Abschluss
Wetterdatenanalyse und -vorhersage für verschiedene Städte in Kenia
Einführung
In diesem Artikel werde ich Sie durch die Analyse von Wettermustern mit Python führen. Von der Identifizierung von Temperaturtrends bis zur Visualisierung von Niederschlägen ist diese Schritt-für-Schritt-Anleitung perfekt für alle, die sich für den Einsatz datenwissenschaftlicher Techniken zur Wetteranalyse interessieren. Ich werde Code, Datenmanipulation und Visualisierungen untersuchen, um praktische Erkenntnisse zu gewinnen.
In Kenia spielt das Wetter in vielen Bereichen eine entscheidende Rolle, insbesondere in der Landwirtschaft, im Tourismus und bei Outdoor-Aktivitäten. Landwirte, Unternehmen und Veranstaltungsplaner benötigen genaue Wetterinformationen, um Entscheidungen treffen zu können. Allerdings können die Wettermuster in den verschiedenen Regionen erheblich variieren und aktuelle Vorhersagesysteme liefern möglicherweise nicht immer lokalisierte Erkenntnisse.
Ziel dieses Projekts ist es, Echtzeit-Wetterdaten von der OpenWeatherMap-API und der Wetter-API für verschiedene Regionen in ganz Kenia zu sammeln. Diese Daten werden in einer Datenbank gespeichert und mit Python analysiert, um Erkenntnisse zu gewinnen über:-
- Temperaturtrends
- Niederschlagsmuster – Luftfeuchtigkeit und Windverhältnisse
In diesem Projekt analysiere ich einen Datensatz mit Wetterinformationen für verschiedene Städte in Kenia. Der Datensatz umfasst über 3.000 Zeilen mit Wetterbeobachtungen, darunter unter anderem Temperatur, Luftfeuchtigkeit, Druck, Windgeschwindigkeit, Sichtweite und Niederschlag. Mithilfe dieser Erkenntnisse möchten wir genaue, regionalspezifische Wettervorhersagen bereitstellen, die die Entscheidungsfindung in wetterempfindlichen Sektoren wie Landwirtschaft, Tourismus und sogar Management unterstützen können.
Datensatzübersicht
Der Datensatz wurde mithilfe mehrerer Spalten strukturiert:
- Datetime – Zeitstempel, der angibt, wann das Wetter aufgezeichnet wurde.
- Stadt und Land – Ort der Wetterbeobachtung.
- Breitengrad und Längengrad – Geografische Koordinaten des Standorts.
- Temperatur (Celsius) – Die aufgezeichnete Temperatur.
- Luftfeuchtigkeit (%) – Der Prozentsatz der Luftfeuchtigkeit in der Luft.
- Druck (hPa) – Der atmosphärische Druck in Hektopascal.
- Windgeschwindigkeit (m/s) – Die Geschwindigkeit des Windes zu diesem Zeitpunkt.
- Regen (mm) – Die Niederschlagsmenge, gemessen in Millimetern.
- Wolken (%) – Der Prozentsatz der Wolkenabdeckung.
- Wetterzustand und Wetterbeschreibung – Allgemeine und detaillierte Beschreibungen des Wetters (z. B. „Wolken“, „Vereinzelte Wolken“).
So sind die Daten in der Datenbank strukturiert.
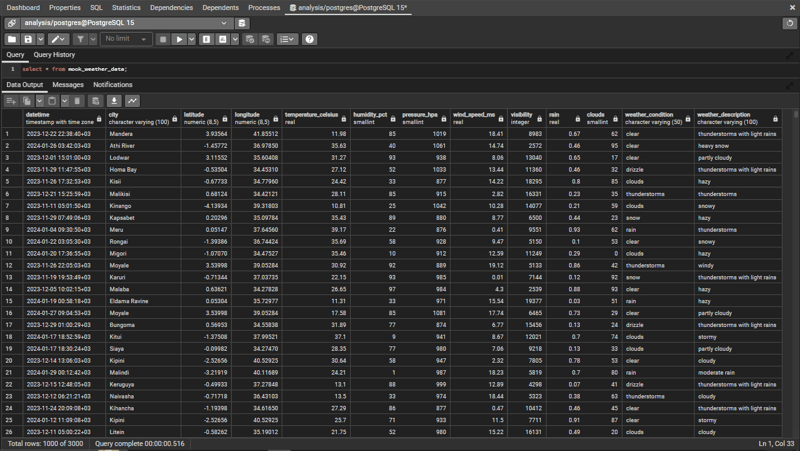
Explorative Datenanalyse
Der erste Schritt der Analyse umfasste die grundlegende Untersuchung der Daten.
_ Datendimensionen – Der Datensatz enthält 3.000 Zeilen und 14 Spalten.
_ Nullwerte – Minimale fehlende Daten, um sicherzustellen, dass der Datensatz für die weitere Analyse zuverlässig ist.
print(df1[['temperature_celsius', 'humidity_pct', 'pressure_hpa', 'wind_speed_ms', 'rain', 'clouds']].describe())
Mit dem obigen Code haben wir zusammenfassende Statistiken für die numerischen Spalten berechnet, die Einblicke in den Bereich, den Mittelwert und die Ausbreitung von Temperatur, Luftfeuchtigkeit, Druck, Niederschlag und Wolken lieferten.
Visualisierung wichtiger Wetterfunktionen
Um ein klareres Verständnis der Wettermerkmale zu erhalten, haben wir verschiedene Verteilungen aufgezeichnet:
Temperaturverteilung
sns.displot(df1['temperature_celsius'], bins=50, kde=True)
plt.title('Temperature Distribution')
plt.xlabel('Temperature (Celsius)')
Diese Verteilung zeigt die allgemeine Temperaturverteilung in den Städten. Das KDE-Liniendiagramm liefert eine glatte Schätzung der Wahrscheinlichkeitsverteilung der Temperatur.
Niederschlagsverteilung
sns.displot(df1['rain'], bins=50, kde=True)
plt.title('Rainfall Distribution')
plt.xlabel('Rainfall (mm/h)')
Dieser Code analysiert die Niederschlagsverteilung in kenianischen Städten.
Luftfeuchtigkeit, Druck und Windgeschwindigkeit
Ähnliche Verteilungsdiagramme für Luftfeuchtigkeit (%), Druck (hPa) und Windgeschwindigkeit (m/s), die jeweils nützliche Einblicke in die liefern Variationen dieser Parameter im gesamten Datensatz.
Wetterzustandsanalyse
Wetterbedingungen (z. B. „Wolken“, „Regen“) wurden gezählt und mithilfe eines Kreisdiagramms visualisiert, um ihre proportionale Verteilung anzuzeigen:
condition_counts = df1['weather_condition'].value_counts()
plt.figure(figsize=(8,8))
plt.pie(condition_counts, labels=condition_counts.index, autopct='%1.1f%%', pctdistance=1.1, labeldistance=0.6, startangle=140)
plt.title('Distribution of Weather Conditions')
plt.axis('equal')
plt.show()
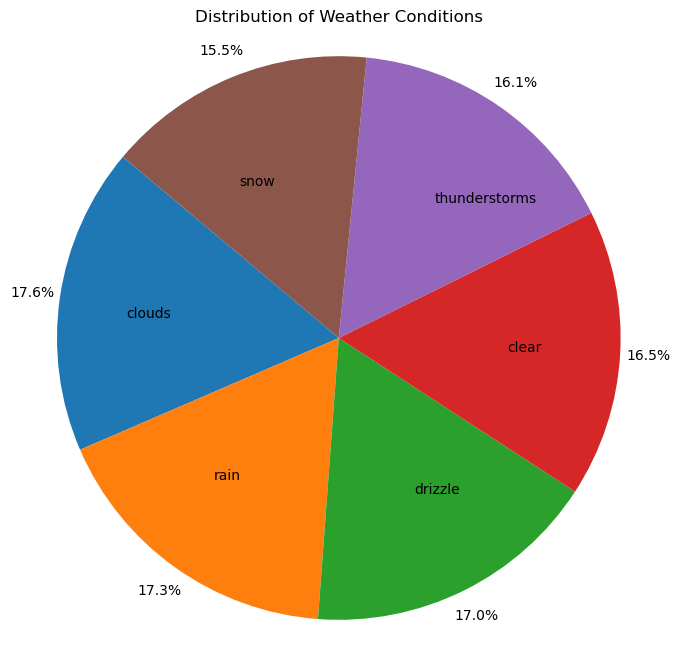
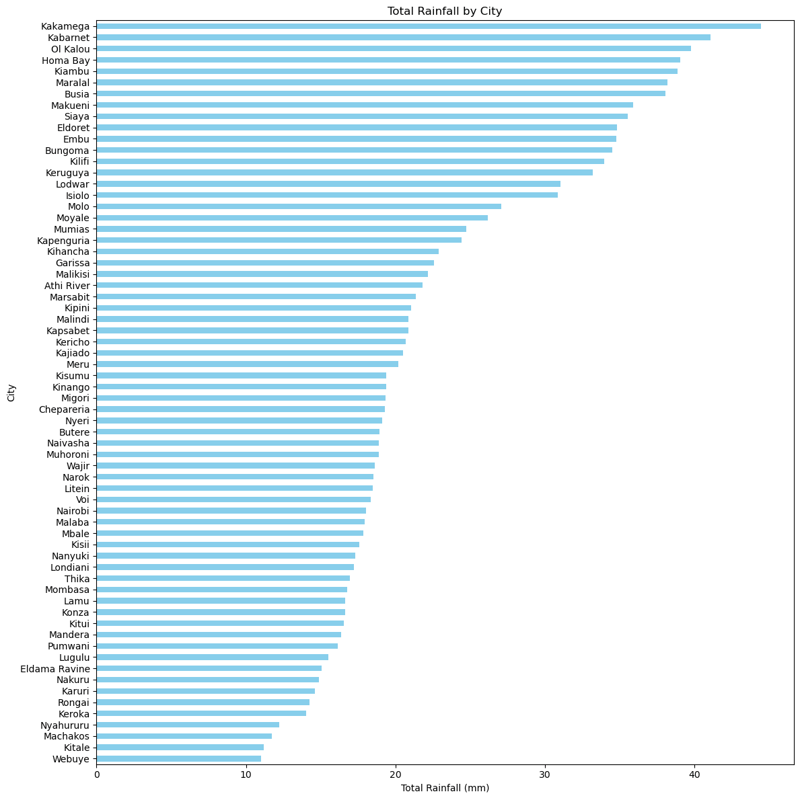
Stadtbezogener Niederschlag
Eine der wichtigsten Analysen war der Gesamtniederschlag pro Stadt:
rainfall_by_city = df1.groupby('city')['rain'].sum().sort_values()
plt.figure(figsize=(12,12))
rainfall_by_city.plot(kind='barh', color='skyblue')
plt.title('Total Rainfall by City')
plt.xlabel('Total Rainfall (mm)')
plt.ylabel('City')
plt.tight_layout()
plt.show()
Dieses Balkendiagramm zeigt, welche Städte im Beobachtungszeitraum den meisten Regen abbekommen haben, wobei einige Ausreißer im Vergleich zu anderen erhebliche Niederschläge zeigten.
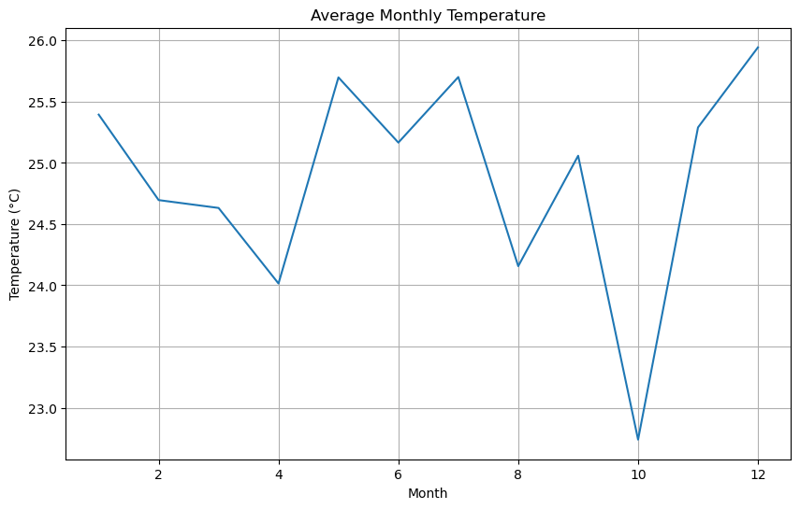
Durchschnittliche monatliche Temperatur
avg_temp_by_month.plot(kind='line')
plt.title('Average Monthly Temperature')
Das Liniendiagramm zeigte Temperaturschwankungen über verschiedene Monate hinweg und zeigte saisonale Veränderungen.
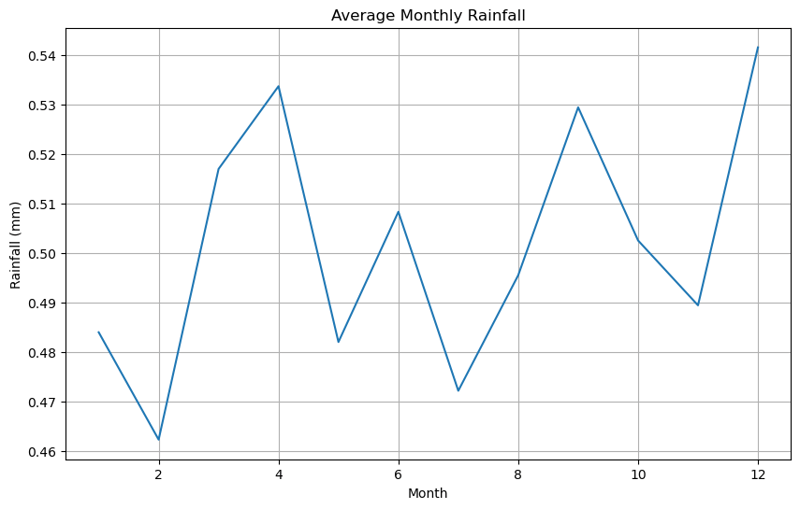
Durchschnittlicher monatlicher Niederschlag
monthly_rain.plot(kind='line')
plt.title('Average Monthly Rainfall')
In ähnlicher Weise wurde der Niederschlag analysiert, um zu beobachten, wie er von Monat zu Monat schwankte.
Wir haben die Daten auch mithilfe von Heatmaps visualisiert, um ein intuitiveres Verständnis der monatlichen Temperatur und des Niederschlags zu erhalten.
Hier sind die Heatmaps für die durchschnittliche monatliche Temperatur und den Niederschlag


Korrelation zwischen Wettervariablen
Als nächstes habe ich die Korrelationsmatrix zwischen den wichtigsten Wettervariablen berechnet:
correlation_matrix = df1[['temperature_celsius', 'humidity_pct', 'pressure_hpa', 'wind_speed_ms', 'rain', 'clouds']].corr()
correlation_matrix
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Between Weather Variables')
Diese Heatmap ermöglichte es uns, Beziehungen zwischen Variablen zu identifizieren. Beispielsweise haben wir erwartungsgemäß eine negative Korrelation zwischen Temperatur und Luftfeuchtigkeit beobachtet.
Fallstudie: Stadtspezifische Trends
Ich habe mich auf einzelne Städte wie Mombasa und Nyeri konzentriert, um ihre einzigartigen Wettermuster zu erkunden:
Mombasa Temperaturtrends
plt.plot(monthly_avg_temp_msa)
plt.title('Temperature Trends in Mombasa Over Time')
Diese Stadt wies im Laufe des Jahres erhebliche Temperaturschwankungen auf.
Nyeri-Niederschlagstrends
plt.plot(monthly_avg_rain_nyr)
plt.title('Rainfall Trends in Nyeri Over Time')
Die Niederschlagsdaten für Nyeri zeigten ein klares saisonales Muster, wobei die Niederschläge in bestimmten Monaten ihren Höhepunkt erreichten.
Abschluss
Diese Analyse bietet einen umfassenden Überblick über die Wetterbedingungen in Großstädten und hebt Temperatur, Niederschlag und andere wichtige Wettervariablen hervor. Durch den Einsatz von Visualisierungen wie Histogrammen, Liniendiagrammen, Kreisdiagrammen und Heatmaps konnten wir aussagekräftige Erkenntnisse aus den Daten gewinnen. Eine weitere Analyse könnte den Vergleich dieser Trends mit historischen Wettermustern oder die Erforschung prädiktiver Modelle zur Vorhersage zukünftiger Wettertrends umfassen.
Das Jupyter Notebook mit dem vollständigen Code für diese Analyse finden Sie in meinem GitHub-Repository.
-
 Wie begrenzt ich den Scroll-Bereich eines Elements in einem dynamisch großen übergeordneten Element?implementieren CSS -Höhenlimits für vertikale Scrolling -Elemente in einer interaktiven Schnittstelle und kontrollieren des Bildlaufverhaltens...Programmierung Gepostet am 2025-04-03
Wie begrenzt ich den Scroll-Bereich eines Elements in einem dynamisch großen übergeordneten Element?implementieren CSS -Höhenlimits für vertikale Scrolling -Elemente in einer interaktiven Schnittstelle und kontrollieren des Bildlaufverhaltens...Programmierung Gepostet am 2025-04-03 -
Wie kann ich mit Decimal.Parse () Zahlen in exponentieller Notation analysieren?analysieren eine Nummer aus exponentieller Notation beim Versuch, eine in exponentielle Notation ausgedrückte String mit Decimal.parse zu anal...Programmierung Gepostet am 2025-04-03
-
Können Sie CSS verwenden, um die Konsolenausgabe in Chrom und Firefox zu färben?Farben in JavaScript console Ist es möglich, Chromes Konsole zu verwenden, um farbigen Text wie rot für Fehler, orange für Kriege und grün für...Programmierung Gepostet am 2025-04-03
-
Warum zeigt keine Firefox -Bilder mithilfe der CSS `Content` -Eigenschaft an?Bilder mit Inhalts -URL in Firefox Es wurde ein Problem aufgenommen, an dem bestimmte Browser, speziell Firefox, nicht die Bilder mit der Inha...Programmierung Gepostet am 2025-04-03
-
Eval () gegen ast.litereral_eval (): Welche Python -Funktion ist für die Benutzereingabe sicherer?wiegen eval () und ast.litereral_eval () in Python Security Bei der Bearbeitung von Benutzereingaben sind es imperativ, die Sicherheit zu prio...Programmierung Gepostet am 2025-04-03
-
Warum bekomme ich nach der Installation von Archive_zip auf meinem Linux -Server eine "Klasse" ziparchive \ 'nicht gefunden?class 'ziparchive' kein Fehler gefunden, während Archive_zip auf Linux Server Symptom installiert wird: beim Versuch, ein Skript zu ...Programmierung Gepostet am 2025-04-03
-
Wie behandle ich den Benutzereingang im exklusiven Modus von Java von Java?verwandeln Benutzereingaben im Vollbildmodus in java Einführung Wenn eine Java -Anwendung im Vollbildmodus exklusiver Modus ausgeführt wird,...Programmierung Gepostet am 2025-04-03
-
Wie benutze ich wie Abfragen mit PDO -Parametern richtig?verwenden wie Abfragen in pdo beim Versuch, wie Abfragen in PDO zu implementieren, können Sie Probleme wie die in der Abfrage unten beschriebe...Programmierung Gepostet am 2025-04-03
-
Python Read CSV -Datei UnicodEdeCodeError Ultimate Lösungunicode dekodieren Fehler in der CSV-Datei Reading Wenn versucht wird, eine CSV-Datei mit dem integrierten CSV-Modul zu lesen, können Sie eine...Programmierung Gepostet am 2025-04-03
-
Wie entferte ich anonyme JavaScript -Ereignishandler sauber?entfernen anonymer Ereignis -Hörer Hinzufügen von anonymen Ereignishörern zu Elementen bieten Flexibilität und Einfachheit, aber wenn es Zeit is...Programmierung Gepostet am 2025-04-03
-
Wie erfasst und streamen Sie Stdout in Echtzeit für die Ausführung von Chatbot -Befehl?Das Problem liegt im traditionellen Ansatz, der alle Stdout sammelt und es als einzige Antwort zurückgibt. Um dies zu überwinden, brauchen wir e...Programmierung Gepostet am 2025-04-03
-
Wie kann ich Kompilierungsoptimierungen im Go -Compiler anpassen?Anpassung von Kompilierungsoptimierungen in Go Compiler Der Standardkompilierungsprozess in Go folgt einer spezifischen Optimierungsstrategie....Programmierung Gepostet am 2025-04-03
-
Wie kann man sich geweigert, das Skript zu laden ... \ "Fehler aufgrund der Inhaltssicherheitsrichtlinie von Android?enthüllen die mystery: Inhaltssicherheit Richtlinienfehler begegnen dem rätselhaften Fehler ", das Skript zu laden ..." beim Bereits...Programmierung Gepostet am 2025-04-03
-
ArrayMethoden sind fns, die auf Objekte aufgerufen werden können Arrays sind Objekte, daher haben sie auch Methoden in js. Slice (Beginn): Ex...Programmierung Gepostet am 2025-04-03
-
Wie umgeht ich Website -Blöcke mit Pythons Anfragen und gefälschten Benutzeragenten?wie man das Browserverhalten mit Pythons Anfragen und gefälschten Benutzeragenten simuliert Python -Anfragen sind ein mächtiges Tool, um HTTP ...Programmierung Gepostet am 2025-04-03















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









