
Zauberpilze: Nulldaten mit Mage erforschen und behandeln
 Durchsuche:779
Durchsuche:779
Mage ist ein leistungsstarkes Tool für ETL-Aufgaben mit Funktionen, die die Datenexploration und -gewinnung, schnelle Visualisierungen durch Diagrammvorlagen und mehrere andere Funktionen ermöglichen, die Ihre Arbeit mit Daten in etwas Magisches verwandeln.
Bei der Datenverarbeitung kommt es während eines ETL-Prozesses häufig vor, dass fehlende Daten gefunden werden, die in der Zukunft zu Problemen führen können. Abhängig von der Aktivität, die wir mit dem Datensatz ausführen, können Nulldaten ziemlich störend sein.
Um das Fehlen von Daten in unserem Datensatz zu identifizieren, können wir Python und die Pandas-Bibliothek verwenden, um die Daten zu überprüfen, die Nullwerte darstellen. Darüber hinaus können wir Diagramme erstellen, die die Auswirkungen dieser Nullwerte noch deutlicher zeigen Unser Datensatz.
Unsere Pipeline besteht aus 4 Schritten: Beginnend mit dem Laden der Daten, zwei Verarbeitungsschritten und dem Exportieren der Daten.
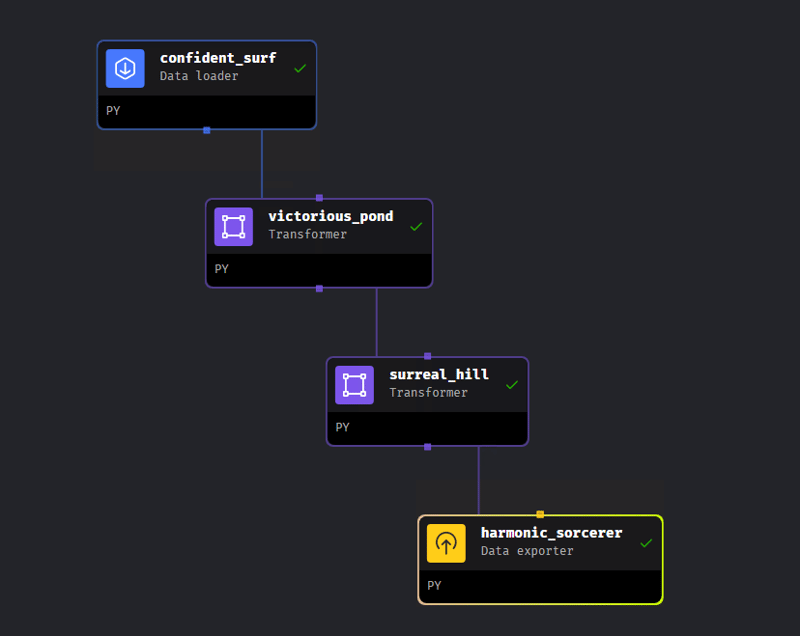
Datenlader
In diesem Artikel verwenden wir den Datensatz: Binary Prediction of Poisonous Mushrooms, der im Rahmen eines Wettbewerbs auf Kaggle verfügbar ist. Nutzen wir den auf der Website verfügbaren Trainingsdatensatz.
Lassen Sie uns einen Data Loader-Schritt mit Python erstellen, um die Daten laden zu können, die wir verwenden werden. Vor diesem Schritt habe ich eine Tabelle in der Postgres-Datenbank erstellt, die ich lokal auf meinem Rechner habe, um die Daten laden zu können. Da die Daten in Postgres vorliegen, verwenden wir die bereits definierte Postgres-Ladevorlage in Mage.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from os import path if 'data_loader' not in globals(): from mage_ai.data_preparation.decorators import data_loader if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @data_loader def load_data_from_postgres(*args, **kwargs): """ Template for loading data from a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ query = 'SELECT * FROM mushroom' # Specify your SQL query here config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: return loader.load(query) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
Innerhalb der Funktion load_data_from_postgres() definieren wir die Abfrage, die wir zum Laden der Tabelle in die Datenbank verwenden. In meinem Fall habe ich die Bankinformationen in der Datei io_config.yaml konfiguriert, wo sie als Standardkonfiguration definiert ist, sodass wir nur den Standardnamen an die Variable config_profile übergeben müssen.
Nach der Ausführung des Blocks verwenden wir die Funktion „Diagramm hinzufügen“, die Informationen über unsere Daten über bereits definierte Vorlagen bereitstellt. Klicken Sie einfach auf das Symbol neben dem Play-Button, im Bild mit einer gelben Linie markiert.

Wir werden zwei Optionen auswählen, um unseren Datensatz weiter zu untersuchen: die Optionen summay_overview und feature_profiles. Durch summary_overview erhalten wir Informationen über die Anzahl der Spalten und Zeilen im Datensatz. Wir können auch die Gesamtzahl der Spalten nach Typ anzeigen, beispielsweise die Gesamtzahl der kategorialen, numerischen und booleschen Spalten. Feature_profiles hingegen stellt beschreibendere Informationen zu den Daten dar, wie zum Beispiel: Typ, Minimalwert, Maximalwert und andere Informationen. Wir können sogar die fehlenden Werte visualisieren, die im Mittelpunkt unserer Behandlung stehen.
Um uns stärker auf fehlende Daten konzentrieren zu können, verwenden wir die Vorlage: % der fehlenden Werte, ein Balkendiagramm mit dem Prozentsatz der fehlenden Daten in jeder Spalte.
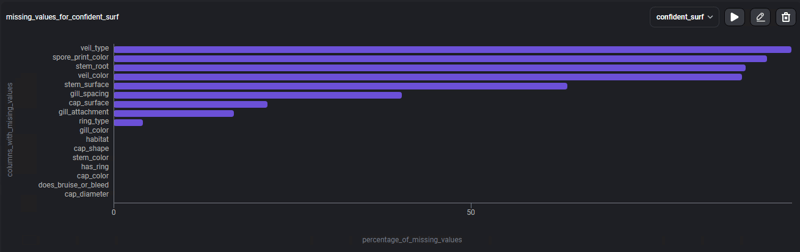
Das Diagramm enthält 4 Spalten, in denen fehlende Werte mehr als 80 % des Inhalts ausmachen, und weitere Spalten, in denen fehlende Werte, jedoch in geringeren Mengen, angezeigt werden. Diese Informationen ermöglichen es uns nun, nach verschiedenen Strategien zu suchen, um damit umzugehen Nulldaten.
Transformer-Drop-Spalten
Für Spalten, die mehr als 80 % Nullwerte haben, besteht die Strategie, die wir verfolgen werden, darin, Spalten im Datenrahmen zu löschen und die Spalten auszuwählen, die wir aus dem Datenrahmen ausschließen möchten. Mithilfe des Blocks TRANSFORMER in der Python-Sprache wählen wir die Option Spaltenentfernung aus.
from mage_ai.data_cleaner.transformer_actions.base import BaseAction from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action from pandas import DataFrame if 'transformer' not in globals(): from mage_ai.data_preparation.decorators import transformer if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @transformer def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame: """ Execute Transformer Action: ActionType.REMOVE Docs: https://docs.mage.ai/guides/transformer-blocks#remove-columns """ action = build_transformer_action( df, action_type=ActionType.REMOVE, arguments=['veil_type', 'spore_print_color', 'stem_root', 'veil_color'], axis=Axis.COLUMN, ) return BaseAction(action).execute(df) @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
Innerhalb der Funktion execute_transformer_action() fügen wir in der Argumentvariablen eine Liste mit den Namen der Spalten ein, die wir aus dem Datensatz ausschließen möchten. Nach diesem Schritt führen Sie einfach den Block aus.
Transformator ergänzt fehlende Werte
Nun verwenden wir für die Spalten, die weniger als 80 % Nullwerte haben, die Strategie Fehlende Werte ausfüllen, da wir in einigen Fällen trotz fehlender Daten diese durch Werte wie ersetzen Abhängig von Ihrem endgültigen Ziel kann es möglicherweise den Datenbedarf decken, ohne viele Änderungen am Datensatz zu verursachen.
Es gibt einige Aufgaben, wie z. B. die Klassifizierung, bei denen das Ersetzen fehlender Daten durch einen für den Datensatz relevanten Wert (Modus, Mittelwert, Median) zum Klassifizierungsalgorithmus beitragen kann, der zu anderen Schlussfolgerungen führen könnte, wenn die Daten gelöscht würden wie in der anderen Strategie, die wir verwendet haben.
Um eine Entscheidung darüber zu treffen, welche Messung wir verwenden werden, verwenden wir erneut die Funktion Diagramm hinzufügen von Mage. Mithilfe der Vorlage Häufigste Werte können wir den Modus und die Häufigkeit dieses Werts in jeder der Spalten visualisieren.
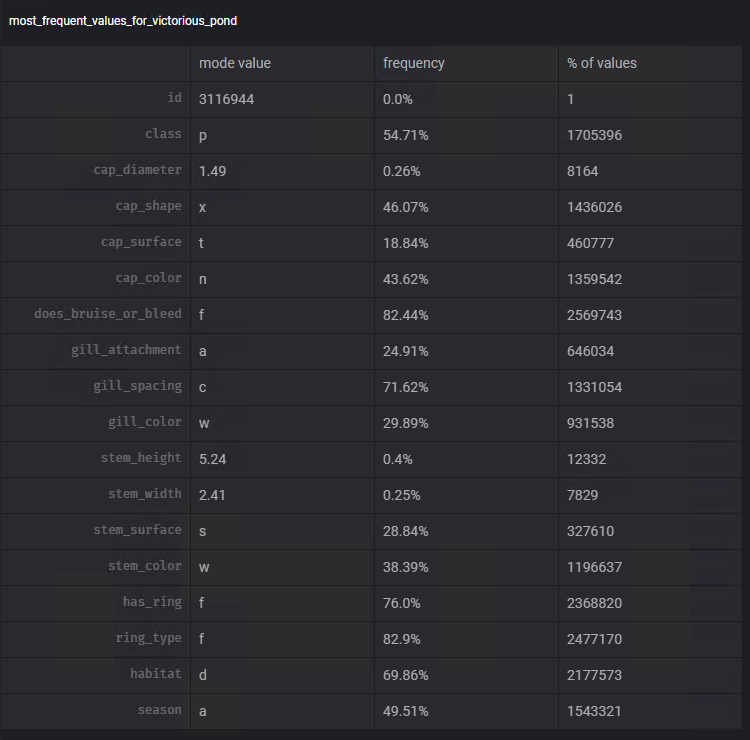
Wir folgen den Schritten, die den vorherigen ähneln, und verwenden den Transformator Füllen Sie fehlende Werte ein, um die Aufgabe des Subtrahierens der fehlenden Daten mithilfe des Modus jeder der Spalten auszuführen: Steam_surface, Gill_spacing, Cap_surface , gill_attachment, ring_type.
from mage_ai.data_cleaner.transformer_actions.constants import ImputationStrategy
from mage_ai.data_cleaner.transformer_actions.base import BaseAction
from mage_ai.data_cleaner.transformer_actions.constants import ActionType, Axis
from mage_ai.data_cleaner.transformer_actions.utils import build_transformer_action
from pandas import DataFrame
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame:
"""
Execute Transformer Action: ActionType.IMPUTE
Docs: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values
"""
action = build_transformer_action(
df,
action_type=ActionType.IMPUTE,
arguments=df.columns, # Specify columns to impute
axis=Axis.COLUMN,
options={'strategy': ImputationStrategy.MODE}, # Specify imputation strategy
)
return BaseAction(action).execute(df)
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
In der Funktion execute_transformer_action() definieren wir die Strategie zum Ersetzen von Daten in einem Python-Wörterbuch. Für weitere Ersatzoptionen greifen Sie einfach auf die Transformer-Dokumentation zu: https://docs.mage.ai/guides/transformer-blocks#fill-in-missing-values.
Datenexporteur
Bei der Durchführung aller Transformationen speichern wir unseren jetzt behandelten Datensatz in derselben Postgres-Datenbank, jetzt jedoch unter einem anderen Namen, damit wir ihn unterscheiden können. Mit dem Block Data Exporter und der Auswahl von Postgres definieren wir das Shema und die Tabelle, in der wir speichern möchten. Dabei berücksichtigen wir, dass die Datenbankkonfigurationen zuvor in der Datei io_config.yaml gespeichert wurden.
from mage_ai.settings.repo import get_repo_path from mage_ai.io.config import ConfigFileLoader from mage_ai.io.postgres import Postgres from pandas import DataFrame from os import path if 'data_exporter' not in globals(): from mage_ai.data_preparation.decorators import data_exporter @data_exporter def export_data_to_postgres(df: DataFrame, **kwargs) -> None: """ Template for exporting data to a PostgreSQL database. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#postgresql """ schema_name = 'public' # Specify the name of the schema to export data to table_name = 'mushroom_clean' # Specify the name of the table to export data to config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader: loader.export( df, schema_name, table_name, index=False, # Specifies whether to include index in exported table if_exists='replace', #Specify resolution policy if table name already exists )
Vielen Dank und bis zum nächsten Mal?
repo -> https://github.com/DeadPunnk/Mushrooms/tree/main
-
 Hacktoberfest-Woche Online-AuktionssystemÜberblick Während der dritten Woche des Hacktoberfests beschloss ich, zu einem kleineren, aber vielversprechenden Projekt beizutragen: einem ...Programmierung Veröffentlicht am 06.11.2024
Hacktoberfest-Woche Online-AuktionssystemÜberblick Während der dritten Woche des Hacktoberfests beschloss ich, zu einem kleineren, aber vielversprechenden Projekt beizutragen: einem ...Programmierung Veröffentlicht am 06.11.2024 -
Wie verbreiten Sie Ausnahmen zwischen Threads in C++ mit „Exception_ptr“?Propagieren von Ausnahmen zwischen Threads in C Die Aufgabe des Propagierens von Ausnahmen zwischen Threads in C entsteht, wenn eine von einem Hauptth...Programmierung Veröffentlicht am 06.11.2024
-
Wie kann man gezackte Kanten in Firefox mit 3D-CSS-Transformationen beheben?Zackige Kanten in Firefox mit 3D-CSS-TransformationenÄhnlich wie das Problem der gezackten Kanten in Chrome mit CSS-Transformationen zeigt Firefox die...Programmierung Veröffentlicht am 06.11.2024
-
Warum stellt die Funktion mail() von PHP eine Herausforderung für die E-Mail-Zustellung dar?Warum die Funktion mail() von PHP nicht ausreicht: Einschränkungen und FallstrickeWährend PHP die Funktion mail() zum Senden von E-Mails bereitstellt,...Programmierung Veröffentlicht am 06.11.2024
-
Optimieren Sie Ihre NumPy-Dateikonvertierungen mit npyConverterWenn Sie mit den .npy-Dateien von NumPy arbeiten und diese in die Formate .mat (MATLAB) oder .csv konvertieren müssen, ist npyConverter das richtige T...Programmierung Veröffentlicht am 06.11.2024
-
Wie deaktiviere ich Eslint-Regeln für eine bestimmte Zeile?Eslint-Regel für eine bestimmte Zeile deaktivierenIn JSHint können Linting-Regeln für eine bestimmte Zeile mithilfe der folgenden Syntax deaktiviert w...Programmierung Veröffentlicht am 06.11.2024
-
Wie füge ich Listen ohne Fehler in Pandas DataFrame-Zellen ein?Einfügen von Listen in Pandas-ZellenProblemIn Python kann der Versuch, eine Liste in eine Zelle eines Pandas-DataFrames einzufügen, zu Fehlern führen ...Programmierung Veröffentlicht am 06.11.2024
-
Was sind die Hauptunterschiede zwischen „plt.plot“, „ax.plot“ und „figure.add_subplot“ in Matplotlib?Unterschiede zwischen Plot, Achsen und Figur in MatplotlibMatplotlib ist eine objektorientierte Python-Bibliothek zum Erstellen von Visualisierungen. ...Programmierung Veröffentlicht am 06.11.2024
-
FireDucks: Holen Sie sich Leistung, die Pandas übersteigt, ohne Lernkosten!Pandas ist eine der beliebtesten Bibliotheken. Als ich nach einer einfacheren Möglichkeit suchte, ihre Leistung zu beschleunigen, entdeckte ich FireDu...Programmierung Veröffentlicht am 06.11.2024
-
CSS-Raster: Verschachtelte RasterlayoutsEinführung CSS Grid ist ein Layoutsystem, das aufgrund seiner Flexibilität und Effizienz bei der Erstellung mehrspaltiger Layouts bei Webentw...Programmierung Veröffentlicht am 06.11.2024
-
Jupyter Notebook für JavaDas leistungsstarke Jupyter Notebook Jupyter Notebooks sind ein hervorragendes Tool, das ursprünglich entwickelt wurde, um Datenwissenschaftl...Programmierung Veröffentlicht am 06.11.2024
-
Wie teile ich Daten zwischen dem Hauptfenster und Threads in PyQt: Direkte Referenz vs. Signale und Slots?Daten zwischen Hauptfenster und Thread in PyQt teilenMultithread-Anwendungen müssen häufig Daten zwischen dem Hauptfenster-Thread und den Arbeitsthrea...Programmierung Veröffentlicht am 06.11.2024
-
Die nützlichsten VS-Code-Verknüpfungen für professionelle Entwickler ?20 nützlichste Verknüpfungen in VS-Code Allgemeine Navigation Befehlspalette: Greifen Sie auf alle verfügbaren Befehle in VS Code zu. Strg-Umschalt-P...Programmierung Veröffentlicht am 06.11.2024
-
Lassen Sie uns mit React eine bessere Zahleneingabe erstellenProgrammierung Veröffentlicht am 06.11.2024
-
Wann sollte „Composer Update“ vs. „Composer Install“ verwendet werden?Erkunden der Unterschiede zwischen Composer-Update und Composer-InstallationComposer, ein beliebter PHP-Abhängigkeitsmanager, bietet zwei Schlüsselbef...Programmierung Veröffentlicht am 06.11.2024















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









