
How to Use Nvidia\'s Chat With RTX AI Chatbot on Your Computer
 Browse:358
Browse:358
Nvidia has launched Chat with RXT, an AI chatbot that operates on your PC and offers features similar to ChatGPT and more! All you need is an Nvidia RTX GPU, and you're all set to start using Nvidia's new AI chatbot.
What Is Nvidia Chat with RTX?
Nvidia Chat with RTX is an AI software that lets you run a large language model (LLM) locally on your computer. So, instead of going online to use an AI chatbot like ChatGPT, you can use Chat with RTX offline whenever you want.
Chat with RTX uses TensorRT-LLM, RTX acceleration, and a quantized Mistral 7-B LLM to provide fast performance and quality responses on par with other online AI chatbots. It also provides retrieval-augmented generation (RAG), allowing the chatbot to read through your files and enable customized answers based on the data you provide. This allows you to customize the chatbot to provide a more personal experience.
If you want to try out Nvidia Chat with RTX, here's how to download, install, and configure it on your computer.
How to Download and Install Chat with RTX

Nvidia has made running an LLM locally on your computer much easier. To run Chat with RTX, you only need to download and install the app, just as you would with any other software. However, Chat with RTX does have some minimum specification requirements to install and use properly.
RTX 30-Series or 40-Series GPU 16GB RAM 100GB free memory space Windows 11If your PC does pass the minimum system requirement, you can go ahead and install the app.
Step 1: Download the Chat with RTX ZIP file.Download: Chat with RTX (Free—35GB download)Step 2: Extract the ZIP file by right-clicking and selecting a file archive tool like 7Zip or double-clicking the file and selecting Extract All. Step 3: Open the extracted folder and double-click setup.exe. Follow the onscreen instructions and check all the boxes during the custom installation process. After hitting Next, the installer will download and install the LLM and all dependencies.
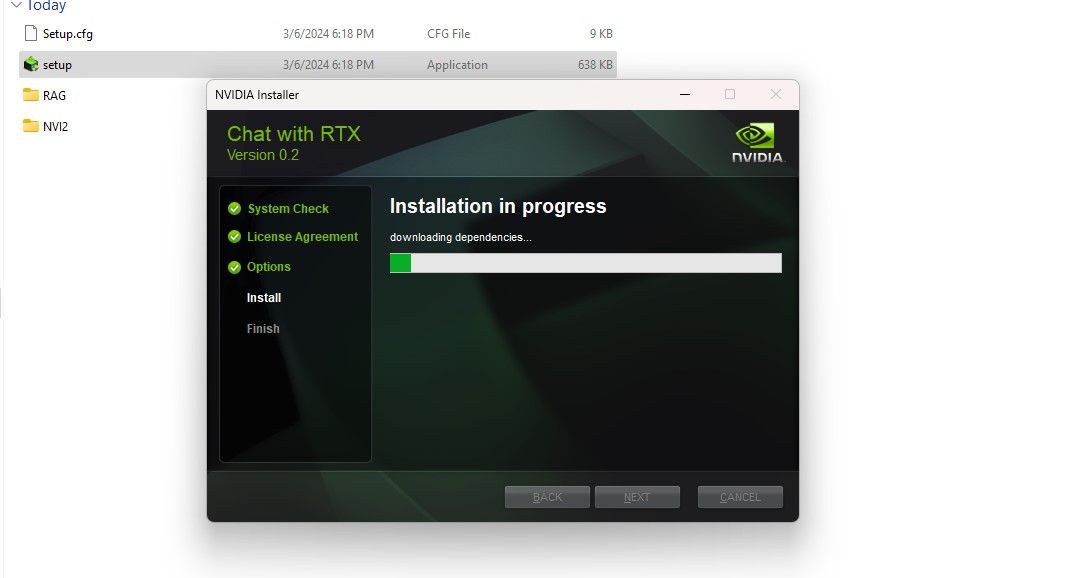
The Chat with RTX installation will take some time to finish as it downloads and installs a large amount of data. After the installation process, hit Close, and you're done. Now, it's time for you to try out the app.
How to Use Nvidia Chat with RTX
Although you can use Chat with RTX like a regular online AI chatbot, I strongly suggest you check its RAG functionality, which enables you to customize its output based on the files you give access to.
Step 1: Create RAG Folder
To start using RAG on Chat with RTX, create a new folder to store the files you want the AI to analyze.
After creation, place your data files into the folder. The data you store can cover many topics and file types, such as documents, PDFs, text, and videos. However, you may want to limit the number of files you place in this folder so as not to affect performance. More data to search through means Chat with RTX will take longer to return responses for specific queries (but this is also hardware-dependent).
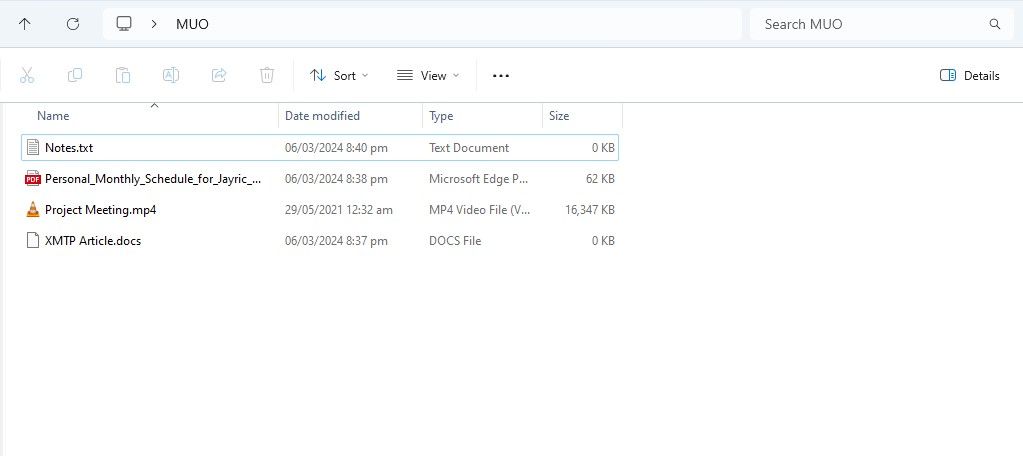
Now your database is ready, you can set up Chat with RTX and start using it to answer your questions and queries.
Step 2: Set Up Environment
Open Chat with RTX. It should look like the image below.
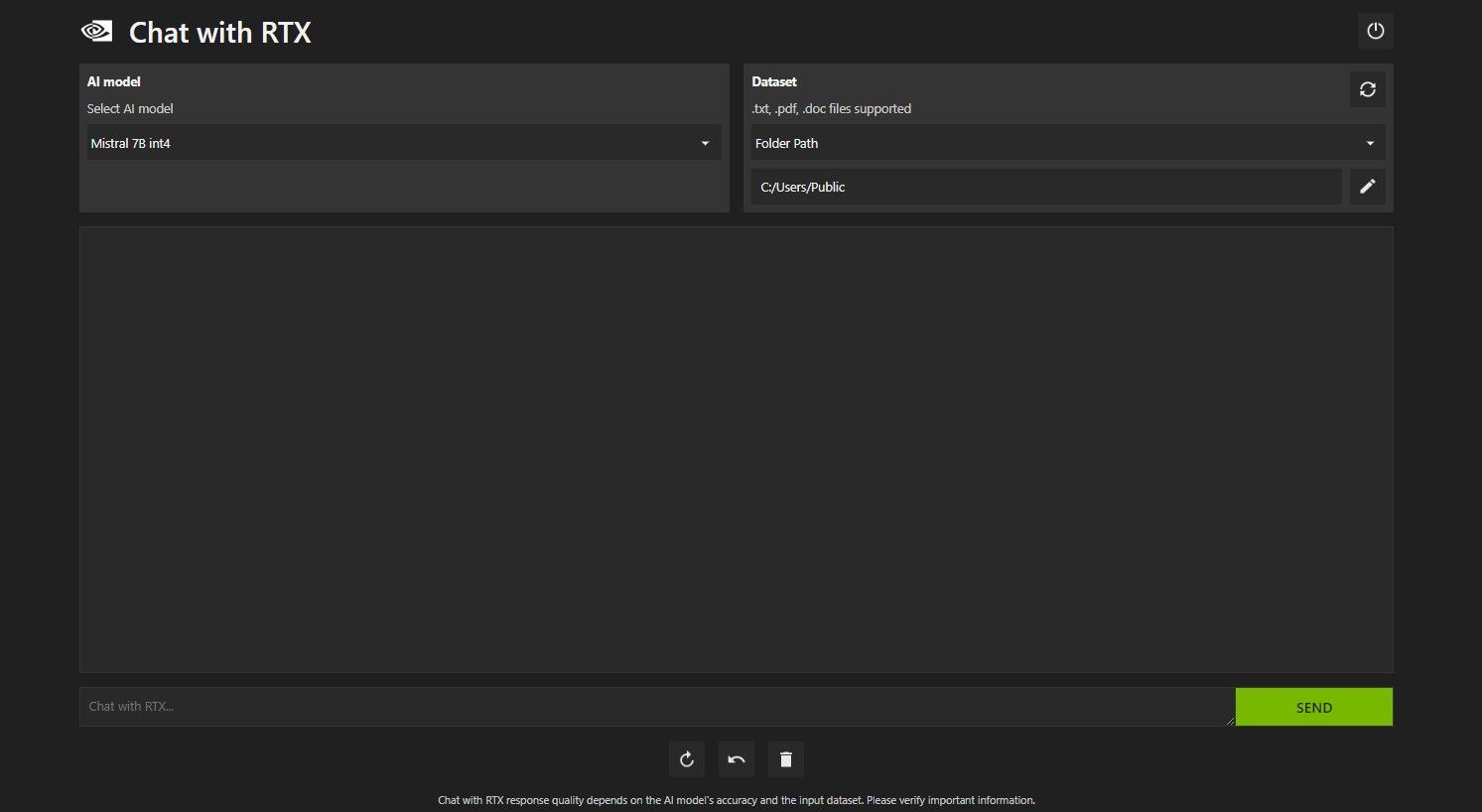
Under Dataset, make sure that the Folder Path option is selected. Now click on the edit icon below (the pen icon) and select the folder containing all the files you want Chat with RTX to read. You can also change the AI model if other options are available (at the time of writing, only Mistral 7B is available).
You are now ready to use Chat with RTX.
Step 3: Ask Chat with RTX Your Questions!
There are several ways to query Chat with RTX. The first one is to use it like a regular AI chatbot. I asked Chat with RTX about the benefits of using a local LLM and was satisfied with its answer. It wasn't enormously in-depth, but accurate enough.
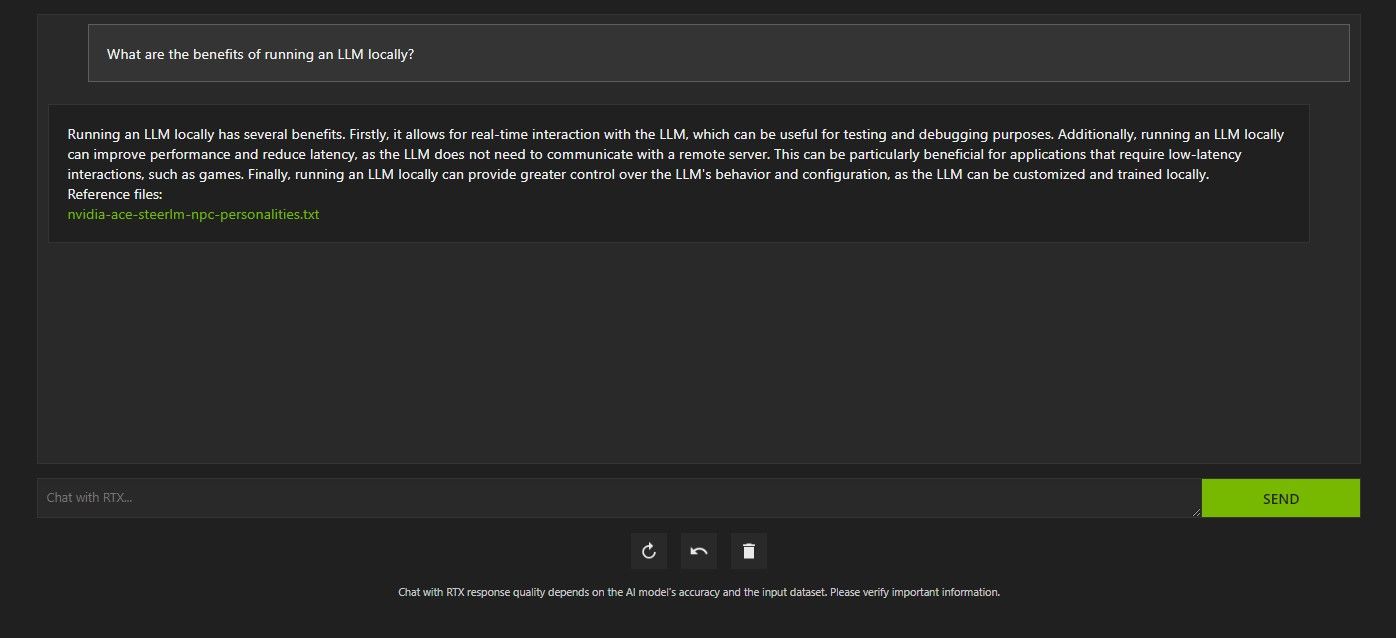
But since Chat with RTX is capable of RAG, you can also use it as a personal AI assistant.
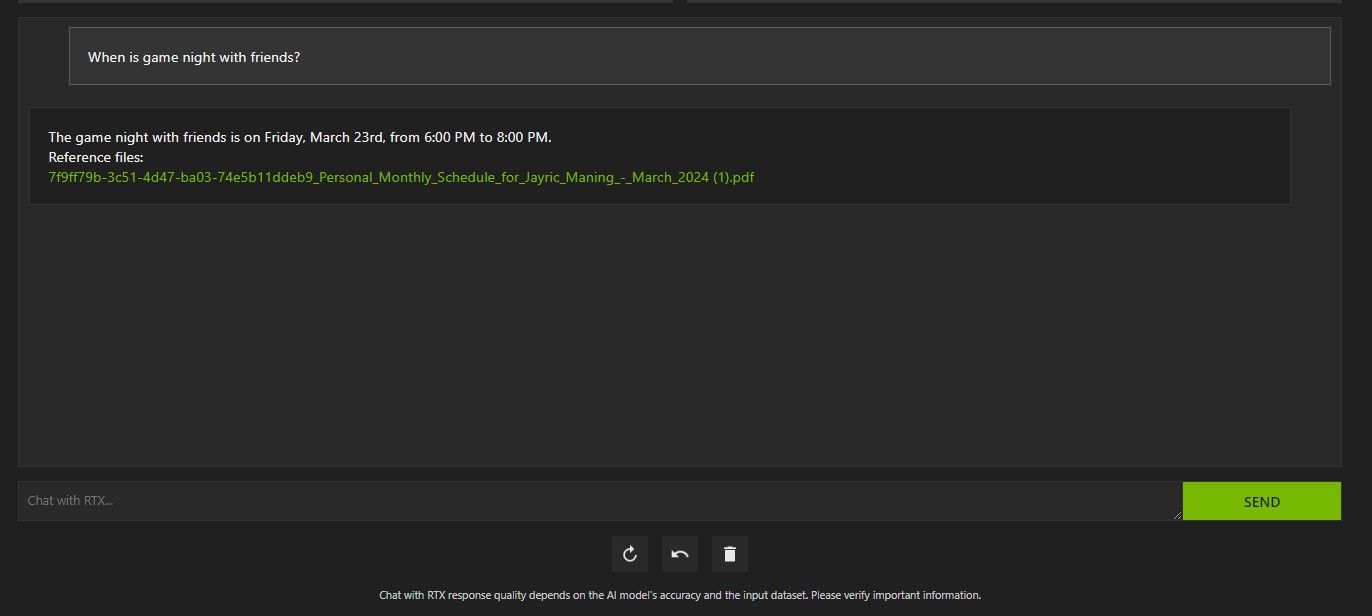
Above, I've used Chat with RTX to ask about my schedule. The data came from a PDF file containing my schedule, calendar, events, work, and so on. In this case, Chat with RTX has pulled the correct calendar data from the data; you'll have to keep your data files and calendar dates updated for features like this to work properly until there are integrations with other apps.
There are many ways you can use Chat with RTX's RAG to your advantage. For example, you can use it to read through legal papers and give a summary, generate code relevant to the program you're developing, get bulleted highlights about a video you're too busy to watch, and so much more!
Step 4: Bonus Feature
In addition to your local data folder, you can use Chat with RTX to analyze YouTube videos. To do so, under Dataset, change the Folder Path to YouTube URL.
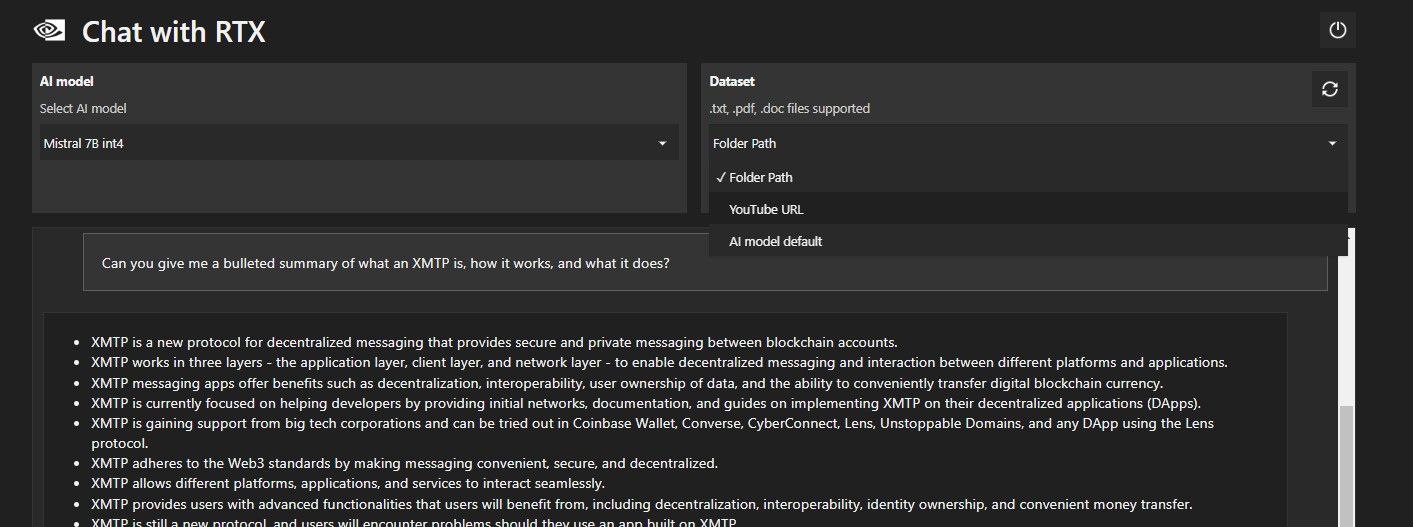
Copy the YouTube URL you want to analyze and paste it below the drop-down menu. Then ask away!
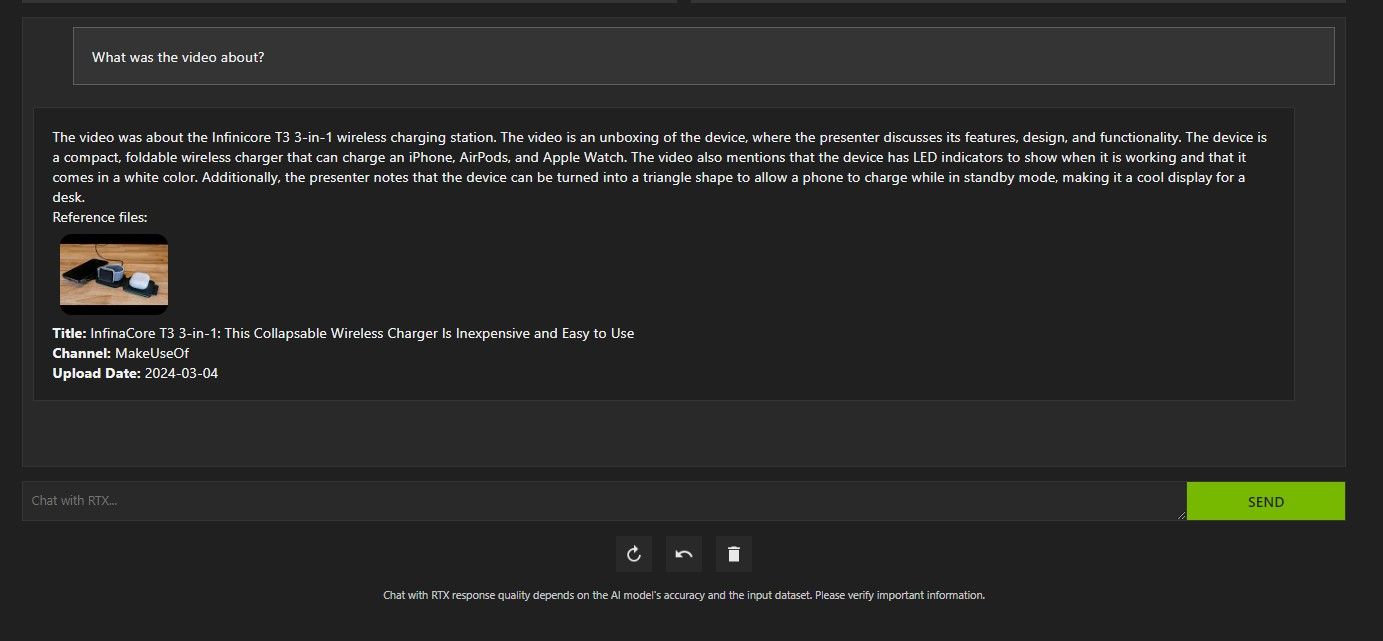
Chat with RTX's YouTube video analysis was pretty good and delivered accurate information, so it could be handy for research, quick analysis, and more.
Is Nvidia's Chat with RTX Any Good?
ChatGPT provides RAG functionality. Some local AI chatbots have significantly lower system requirements. So, is Nvidia Chat with RTX even worth using?
The answer is yes! Chat with RTX is worth using despite the competition.
One of the biggest selling points of using Nvidia Chat with RTX is its ability to use RAG without sending your files to a third-party server. Customizing GPTs through online services can expose your data. But since Chat with RTX runs locally and without an internet connection, using RAG on Chat with RTX ensures your sensitive data is safe and only accessible on your PC.
As for other locally running AI chatbots running Mistral 7B, Chat with RTX performs better and faster. Although a big part of the performance boost comes from using higher-end GPUs, the use of Nvidia TensorRT-LLM and RTX acceleration made running Mistral 7B faster on Chat with RTX when compared to other ways of running a chat-optimized LLM.
It is worth noting that the Chat with RTX version we are currently using is a demo. Later releases of Chat with RTX will likely become more optimized and deliver performance boosts.
What if I Don't Have an RTX 30 or 40 Series GPU?
Chat with RTX is an easy, fast, and secure way of running an LLM locally without the need for an internet connection. If you're also interested in running an LLM or local but don't have an RTX 30 or 40 Series GPU, you can try other ways of running an LLM locally. Two of the most popular ones would be GPT4ALL and Text Gen WebUI. Try GPT4ALL if you want a plug-and-play experience locally running an LLM. But if you're a bit more technically inclined, running LLMs through Text Gen WebUI will provide better fine-tuning and flexibility.
-
 Swarm Intelligence Algorithms: Three Python ImplementationsImagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...AI Posted on 2025-03-24
Swarm Intelligence Algorithms: Three Python ImplementationsImagine watching a flock of birds in flight. There's no leader, no one giving directions, yet they swoop and glide together in perfect harmony. It may...AI Posted on 2025-03-24 -
How to Make Your LLM More Accurate with RAG & Fine-TuningImagine studying a module at university for a semester. At the end, after an intensive learning phase, you take an exam – and you can recall th...AI Posted on 2025-03-24
-
What is Google Gemini? Everything You Need To Know About Google’s ChatGPT RivalGoogle recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members ...AI Posted on 2025-03-23
-
Guide on Prompting with DSPyDSPy: A Declarative Framework for Building and Improving LLM Applications DSPy (Declarative Self-improving Language Programs) revolutionizes LLM appli...AI Posted on 2025-03-22
-
Automate Blog To Twitter ThreadThis article details automating the conversion of long-form content (like blog posts) into engaging Twitter threads using Google's Gemini-2.0 LLM,...AI Posted on 2025-03-11
-
Artificial Immune System (AIS): A Guide With Python ExamplesThis article explores artificial immune systems (AIS), computational models inspired by the human immune system's remarkable ability to identify a...AI Posted on 2025-03-04
-
Try Asking ChatGPT These Fun Questions About YourselfEver wondered what ChatGPT knows about you? How it processes the information you've fed it over time? I've used ChatGPT heaps in different sce...AI Published on 2024-11-22
-
Here\'s How You Can Still Try the Mysterious GPT-2 ChatbotIf you're into AI models or chatbots, you might have seen discussions about the mysterious GPT-2 chatbot and its effectiveness.Here, we explain wh...AI Published on 2024-11-08
-
ChatGPT’s Canvas Mode Is Great: These Are 4 Ways to Use ItChatGPT's new Canvas mode has added an extra dimension to writing and editing in the world's leading generative AI tool. I've been using C...AI Published on 2024-11-08
-
How ChatGPT\'s Custom GPTs Could Expose Your Data and How to Keep It SafeChatGPT's custom GPT feature allows anyone to create a custom AI tool for almost anything you can think of; creative, technical, gaming, custom G...AI Published on 2024-11-08
-
10 Ways ChatGPT Could Help You Land a Job on LinkedInWith 2,600 available characters, the About section of your LinkedIn profile is a great space to elaborate on your background, skills, passions, and f...AI Published on 2024-11-08
-
Check Out These 6 Lesser-Known AI Apps That Provide Unique ExperiencesAt this point, most folks have heard of ChatGPT and Copilot, two pioneering generative AI apps that have led the AI boom.But did you know that heaps o...AI Published on 2024-11-08
-
These 7 Signs Show We\'ve Already Reached Peak AIWherever you look online, there are sites, services, and apps proclaiming their use of AI makes it the best option. I don't know about you, but it...AI Published on 2024-11-08
-
4 AI-Checking ChatGPT Detector Tools for Teachers, Lecturers, and BossesAs ChatGPT advances in power, it's getting harder to tell what's written by a human and what's generated by an AI. This makes it hard for...AI Published on 2024-11-08
-
ChatGPT\'s Advanced Voice Feature Is Rolling Out to More UsersIf you have ever wanted to have a full-blown conversation with ChatGPT, now you can. That is, as long as you pay for the privilege of using ChatGPT. M...AI Published on 2024-11-08















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









