
GPT المحلي مع Ollama وNext.js
 تصفح:602
تصفح:602
مقدمة
مع تطورات الذكاء الاصطناعي اليوم، أصبح من السهل إعداد نموذج ذكاء اصطناعي توليدي على جهاز الكمبيوتر الخاص بك لإنشاء روبوت محادثة.
في هذه المقالة سنرى كيف يمكنك إعداد chatbot على نظامك باستخدام Olma وNext.js
إعداد أولاما
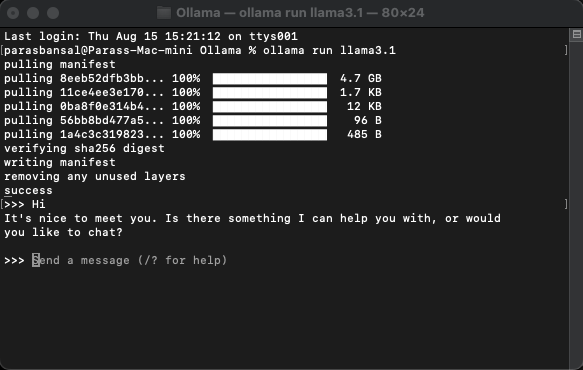
لنبدأ بإعداد Ollama على نظامنا. قم بزيارة ollama.com وقم بتنزيله لنظام التشغيل الخاص بك. سيسمح لنا هذا باستخدام أمر ollama في موجه الأوامر/المحطة.
التحقق من إصدار Ollama باستخدام الأمر ollama -v
اطلع على قائمة العارضات على صفحة مكتبة أولاما.
قم بتنزيل النموذج وتشغيله
لتنزيل نموذج وتشغيله، قم بتشغيل الأمر ollama run
مثال: تشغيل ollama llama3.1 أو تشغيل ollama Gemma2
ستتمكن من الدردشة مع العارضة مباشرة في المحطة.
إعداد تطبيق الويب
الإعداد الأساسي لـ Next.js
- قم بتنزيل وتثبيت أحدث إصدار من Node.js
- انتقل إلى المجلد المطلوب وقم بتشغيل npx create-next-app@latest لإنشاء مشروع Next.js.
- سيتم طرح بعض الأسئلة لإنشاء كود معياري. في هذا البرنامج التعليمي، سنحتفظ بكل شيء بشكل افتراضي.
- افتح المشروع الذي تم إنشاؤه حديثًا في محرر التعليمات البرمجية الذي تختاره. سوف نستخدم رمز VS.
تثبيت التبعيات
هناك عدد قليل من حزم npm التي يجب تثبيتها لاستخدام ollama.
- منظمة العفو الدولية من فيرسل.
- ollama توفر مكتبة Ollama JavaScript أسهل طريقة لدمج مشروع JavaScript الخاص بك مع Ollama.
- يساعد ollama-ai-provider على ربط الذكاء الاصطناعي وأولاما معًا.
- سيتم تنسيق نتائج الدردشة بأسلوب تخفيض السعر، ولتحليل تخفيض السعر سنستخدم حزمة رد فعل تخفيض السعر.
لتثبيت هذه التبعيات، قم بتشغيل npm i ai ollama ollama-ai-provider.
إنشاء صفحة دردشة
تحت app/src يوجد ملف اسمه page.tsx.
دعونا نزيل كل شيء فيه ونبدأ بالمكون الوظيفي الأساسي:
src/app/page.tsx
export default function Home() {
return (
{/* Code here... */}
);
}
لنبدأ باستيراد خطاف useChat من ai/react وreact-markdown
"use client";
import { useChat } from "ai/react";
import Markdown from "react-markdown";
نظرًا لأننا نستخدم خطافًا، فنحن بحاجة إلى تحويل هذه الصفحة إلى مكون عميل.
نصيحة: يمكنك إنشاء مكون منفصل للدردشة واستدعائه في page.tsx للحد من استخدام مكون العميل.
في المكون، احصل على الرسائل والإدخال وhandleInputChange وhandleSubmit من خطاف useChat.
const { messages, input, handleInputChange, handleSubmit } = useChat();
في JSX، قم بإنشاء نموذج إدخال للحصول على مدخلات المستخدم لبدء المحادثة.
الفكرة الجيدة في هذا الأمر هي أننا لسنا بحاجة إلى تصحيح المعالج أو الحفاظ على حالة لقيمة الإدخال، حيث يوفر لنا خطاف useChat ذلك.
يمكننا عرض الرسائل من خلال تكرار مصفوفة الرسائل.
messages.map((m, i) => ({m})
تبدو النسخة المصممة بناءً على دور المرسل كما يلي:
{messages.length ? ( messages.map((m, i) => { return m.role === "user" ? (You) : ({m.content} AI); }) ) : ({m.content} )}Local AI Chat
دعونا نلقي نظرة على الملف بأكمله
src/app/page.tsx
"use client";
import { useChat } from "ai/react";
import Markdown from "react-markdown";
export default function Home() {
const { messages, input, handleInputChange, handleSubmit } = useChat();
return (
);
}
وبهذا يكون الجزء الأمامي قد اكتمل. الآن دعونا نتعامل مع واجهة برمجة التطبيقات.
التعامل مع واجهة برمجة التطبيقات
لنبدأ بإنشاء مسار Route.ts داخل التطبيق/api/chat.
استنادًا إلى اصطلاح التسمية Next.js، سيسمح لنا بالتعامل مع الطلبات على localhost:3000/api/chat endpoint.
src/app/api/chat/route.ts
import { createOllama } from "ollama-ai-provider";
import { streamText } from "ai";
const ollama = createOllama();
export async function POST(req: Request) {
const { messages } = await req.json();
const result = await streamText({
model: ollama("llama3.1"),
messages,
});
return result.toDataStreamResponse();
}
يستخدم الكود أعلاه بشكل أساسي ollama و vercel ai لتدفق البيانات مرة أخرى كاستجابة.
- يقوم createOllama بإنشاء مثيل للolma الذي سيتواصل مع النموذج المثبت على النظام.
- وظيفة POST هي معالج المسار على نقطة نهاية /api/chat باستخدام طريقة النشر.
- يحتوي نص الطلب على قائمة بجميع الرسائل السابقة. لذا من الجيد الحد منه وإلا سيتدهور الأداء بمرور الوقت. في هذا المثال، تأخذ دالة ollama "llama3.1" كنموذج لتوليد الاستجابة بناءً على مصفوفة الرسائل.
الذكاء الاصطناعي التوليدي على نظامك
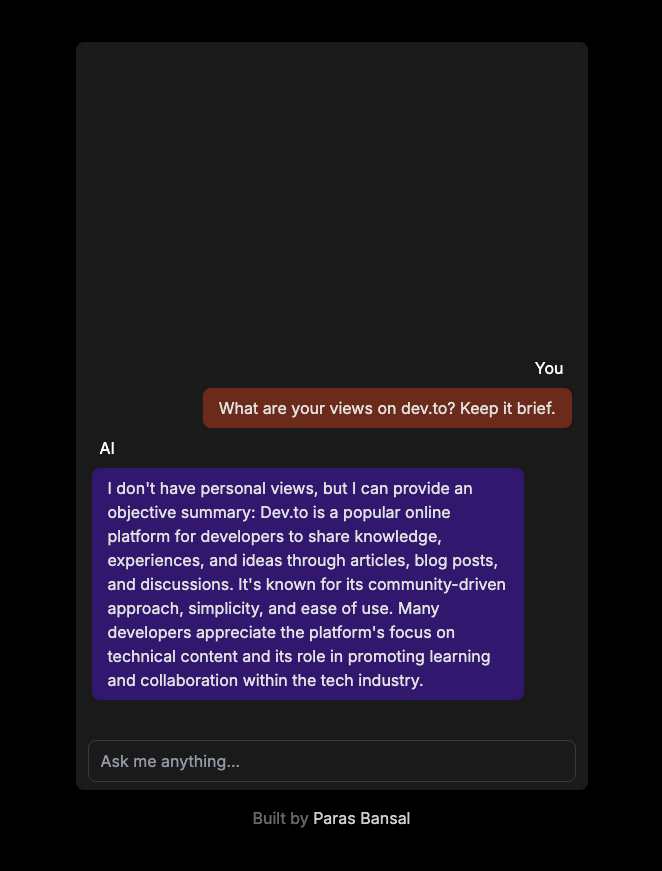
قم بتشغيل npm run dev لبدء الخادم في وضع التطوير.
افتح المتصفح وانتقل إلى localhost:3000 لرؤية النتائج.
إذا تم تكوين كل شيء بشكل صحيح، فستتمكن من التحدث إلى برنامج الدردشة الآلي الخاص بك.
يمكنك العثور على الكود المصدري هنا: https://github.com/parasbansal/ai-chat
أخبرني إذا كانت لديك أي أسئلة في التعليقات، وسأحاول الإجابة عليها.
-
 كيف تجعل TypeScript جافا سكريبت أكثر موثوقية في المشاريع واسعة النطاق.مقدمة تُستخدم JavaScript على نطاق واسع في تطوير الويب ويتم تطبيقها الآن في مشاريع أكبر عبر مختلف الصناعات. ومع ذلك، مع نمو هذه المشاريع، تصب...برمجة تم النشر بتاريخ 2024-11-05
كيف تجعل TypeScript جافا سكريبت أكثر موثوقية في المشاريع واسعة النطاق.مقدمة تُستخدم JavaScript على نطاق واسع في تطوير الويب ويتم تطبيقها الآن في مشاريع أكبر عبر مختلف الصناعات. ومع ذلك، مع نمو هذه المشاريع، تصب...برمجة تم النشر بتاريخ 2024-11-05 -
كيفية التحقق من كلمات مرور المستخدم بشكل آمن باستخدام وظيفة pass_verify الخاصة بـ PHP؟فك تشفير كلمات المرور المشفرة باستخدام PHP تقوم العديد من التطبيقات بتخزين كلمات مرور المستخدم بشكل آمن باستخدام خوارزميات التشفير مثلpassword...برمجة تم النشر بتاريخ 2024-11-05
-
تعلم جزء Vue بناء تطبيق الطقسكان الغوص في Vue.js بمثابة اكتشاف أداة مفضلة جديدة في مجموعة أدوات DIY - بديهية ومرنة وقوية بشكل مدهش. كان مشروعي الجانبي الأول لاستخدام Vue هو تط...برمجة تم النشر بتاريخ 2024-11-05
-
مكون بطاقة معاينة NFT؟ أكملت للتو مشروعي الأخير: "مكون بطاقة معاينة NFT" باستخدام HTML وCSS! ؟ التحقق من ذلك واستكشاف الكود على GitHub. التعليقات مرحب بها! ؟ جيث...برمجة تم النشر بتاريخ 2024-11-05
-
كيف يمكن لتطبيقات Android الاتصال بـ Microsoft SQL Server 2008؟ربط تطبيقات Android بـ Microsoft SQL Server 2008 يمكن لتطبيقات Android الاتصال بسلاسة بخوادم قواعد البيانات المركزية، بما في ذلك Microsoft SQL...برمجة تم النشر بتاريخ 2024-11-05
-
فيما يلي بعض خيارات العناوين المبنية على الأسئلة، والتي تركز على القضية الأساسية: * C++ std :: اختياري: لماذا لا يوجد تخصص للأنواع المرجعية؟ (مباشر وفي صلب الموضوع) * أنواع المراجع في C++ std::optionاختياري في لغة C: لماذا لا يوجد تخصص للأنواع المرجعية؟ على الرغم من وجود تخصص للأنواع المرجعية في المكتبات مثل Boost، فإن C مكتبة القياسية std...برمجة تم النشر بتاريخ 2024-11-05
-
تقييم نموذج تصنيف التعلم الآليالمخطط ما هو الهدف من تقييم النموذج؟ ما هو الغرض من تقييم النموذج، وما هي بعض منها إجراءات التقييم المشتركة؟ ما هو استخدام دقة التصنيف وما ه...برمجة تم النشر بتاريخ 2024-11-05
-
كيفية القضاء على فيروس Eval-Base64_Decode PHP وحماية موقع الويب الخاص بك؟كيفية التخلص من Eval-Base64_Decode مثل ملفات الفيروسات PHPالفيروسات التي تستخدم تقنيات eval-base64_decode، مثل تلك التي لقد وصفت، يمكن أن يكون مصدر إز...برمجة تم النشر بتاريخ 2024-11-05
-
كيفية الترتيب في Serp في 4صفحات تصنيف محرك البحث (SERP) هي المكان الذي تتنافس فيه مواقع الويب على الرؤية وحركة المرور. في عام 2024، سيظل التصنيف العالي على Google ومحركات ا...برمجة تم النشر بتاريخ 2024-11-05
-
كيفية مشاركة القفل بين العمليات في بايثون باستخدام المعالجة المتعددةمشاركة القفل بين العمليات في بايثون عند محاولة استخدامpool.map() لاستهداف وظيفة ذات معلمات متعددة، بما في ذلك كائن Lock()، يكون الأمر كذلك حاسم ...برمجة تم النشر بتاريخ 2024-11-05
-
الفرق بين readonly وconst في Type Scriptتتشابه هاتان الميزتان من حيث أنهما غير قابلتين للتنازل. هل يمكنك شرح ذلك بالضبط؟ وفي هذا المقال سأشارككم الاختلافات بينهما. const يمنع إعا...برمجة تم النشر بتاريخ 2024-11-05
-
كيفية تكرار بناء جملة حلقة C/C++ في بايثون باستخدام وظيفة النطاق؟للحلقة في بايثون: توسيع بناء جملة حلقة C/C في البرمجة، حلقة for هي بناء أساسي للتكرار على التسلسلات. بينما تستخدم C/C صيغة تهيئة حلقة محددة، ت...برمجة تم النشر بتاريخ 2024-11-05
-
تطلق TechEazy Consulting برنامجًا تدريبيًا شاملاً لـ Java وSpring Boot وAWS مع تدريب داخلي مجانييسر شركة TechEazy Consulting الإعلان عن إطلاق برنامجنا التدريبي الشامل المصمم للمبتدئين والمبتدئين والمحترفين الذين يتطلعون إلى التحول إلى تطوير ا...برمجة تم النشر بتاريخ 2024-11-05
-
Polyfills - حشو أم فجوة كبيرة؟ (الجزء الأول)منذ بضعة أيام، تلقينا رسالة ذات أولوية في دردشة Teams في مؤسستنا، والتي نصها: تم العثور على ثغرة أمنية - تم اكتشاف Polyfill JavaScript - HIGH. ول...برمجة تم النشر بتاريخ 2024-11-05
-
عوامل التحول والتخصيصات المختصرة للبت1. مشغلي نقل البت : التحول إلى اليمين. >>>: التحول الأيمن غير الموقع (مبطن صفر). 2. بناء الجملة العام لمشغلي التحول القيمة > num-bits: ينقل بتات القيم...برمجة تم النشر بتاريخ 2024-11-05















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









