
تقييم نموذج تصنيف التعلم الآلي
 تصفح:802
تصفح:802
المخطط
- ما هو الهدف من تقييم النموذج؟
- ما هو الغرض من تقييم النموذج، وما هي بعض منها إجراءات التقييم المشتركة؟
- ما هو استخدام دقة التصنيف وما هي القيود؟
- كيف تصف مصفوفة الارتباك أداء أ المصنف؟
- ما هي المقاييس التي يمكن حسابها من مصفوفة الارتباك؟
Tالهدف من تقييم النموذج هو الإجابة على السؤال؛
كيف أختار بين الموديلات المختلفة؟
تساعد عملية تقييم التعلم الآلي في تحديد مدى موثوقية النموذج وفعاليته في تطبيقه. يتضمن ذلك تقييم عوامل مختلفة مثل أدائها ومقاييسها ودقتها للتنبؤات أو اتخاذ القرار.
بغض النظر عن النموذج الذي تختار استخدامه، فأنت بحاجة إلى طريقة للاختيار بين النماذج: أنواع النماذج المختلفة، ومعلمات الضبط، والميزات. تحتاج أيضًا إلى إجراء تقييم النموذج لتقدير مدى نجاح النموذج في التعميم على البيانات غير المرئية. وأخيرًا، تحتاج إلى إجراء تقييم للاقتران مع الإجراء الخاص بك في إجراءات أخرى لتحديد أداء النموذج الخاص بك.
قبل أن نواصل، دعونا نراجع بعض إجراءات تقييم النماذج المختلفة وكيفية عملها.
إجراءات التقييم النموذجية وكيفية عملها.
-
التدريب والاختبار على نفس البيانات
- تكافئ النماذج المعقدة للغاية التي "تبالغ في احتواء" بيانات التدريب ولا تعمم بالضرورة
-
تقسيم التدريب/الاختبار
- تقسيم مجموعة البيانات إلى قسمين، بحيث يمكن تدريب النموذج واختباره على بيانات مختلفة
- تقدير أفضل للأداء خارج العينة، ولكن لا يزال تقدير "التباين العالي"
- مفيدة بسبب سرعتها وبساطتها ومرونتها
-
التحقق المتبادل من K-fold
- إنشاء تقسيمات تدريب/اختبار "K" بشكل منهجي ومتوسط النتائج معًا
- تقدير أفضل للأداء خارج العينة
- يعمل على تشغيل "K" بشكل أبطأ مرات من تقسيم التدريب/الاختبار.
مما سبق نستنتج أن:
يعد التدريب والاختبار على نفس البيانات سببًا كلاسيكيًا للتجاوز حيث تقوم ببناء نموذج معقد للغاية لن يتم تعميمه على البيانات الجديدة وهذا ليس مفيدًا في الواقع.
يوفر Train_Test_Split تقديرًا أفضل بكثير للأداء خارج العينة.
يعمل التحقق المتبادل من K-fold بشكل أفضل من خلال تقسيم اختبار K Train بشكل منهجي وحساب متوسط النتائج معًا.
باختصار، لا يزال Train_tests_split مربحًا للتحقق من الصحة نظرًا لسرعته وبساطته، وهذا ما سنستخدمه في هذا الدليل التعليمي.
مقاييس تقييم النموذج:
ستحتاج دائمًا إلى مقياس تقييم ليتماشى مع الإجراء الذي اخترته، ويعتمد اختيارك للمقياس على المشكلة التي تعالجها. بالنسبة لمشاكل التصنيف، يمكنك استخدام دقة التصنيف. لكننا سنركز على مقاييس تقييم التصنيف المهمة الأخرى في هذا الدليل.
قبل أن نتعلم أي مقاييس تقييم جديدة، دعونا نراجع دقة التصنيف، ونتحدث عن نقاط القوة والضعف فيه.
دقة التصنيف
لقد اخترنا مجموعة بيانات مرض السكري لهنود بيما لهذا البرنامج التعليمي، والتي تتضمن البيانات الصحية وحالة مرض السكري لـ 768 مريضًا.
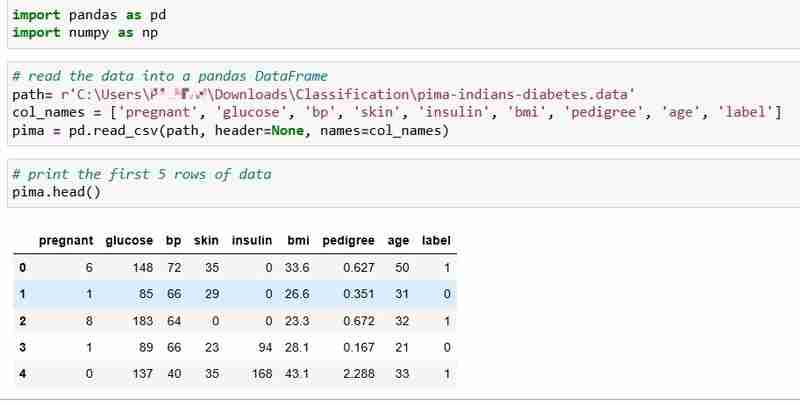
فلنقرأ البيانات ونطبع أول 5 صفوف من البيانات. يشير عمود التسمية إلى 1 إذا كان المرضى مصابين بالسكري و0 إذا كان المرضى غير مصابين بالسكري، وننوي الإجابة على السؤال:
السؤال: هل يمكننا التنبؤ بحالة مرض السكري لدى المريض بالنظر إلى قياساته الصحية؟
نحن نحدد مقاييس الميزات X ومتجه الاستجابة Y. نستخدم Train_test_split لتقسيم X وY إلى مجموعة تدريب واختبار.
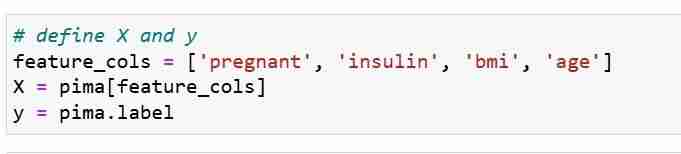
بعد ذلك، نقوم بتدريب نموذج الانحدار اللوجستي على مجموعة التدريب. أثناء خطوة الملاءمة، يتعلم كائن نموذج السجل العلاقة بين X_train وY_train. أخيرًا نقوم بعمل تنبؤات للفصل الدراسي لمجموعات الاختبار.

الآن، قمنا بالتنبؤ بمجموعة الاختبار، ويمكننا حساب دقة التصنيف، وهي ببساطة النسبة المئوية للتنبؤات الصحيحة.
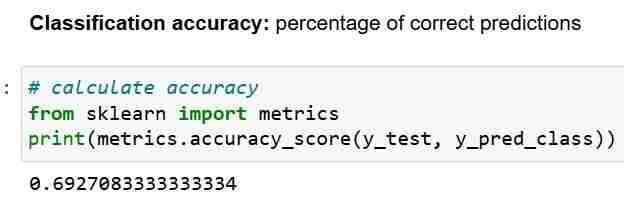
ومع ذلك، في أي وقت تستخدم فيه دقة التصنيف كمقاييس تقييم، من المهم مقارنتها بـ الدقة الخالية، وهي الدقة التي يمكن تحقيقها من خلال التنبؤ دائمًا بالفئة الأكثر شيوعًا.

الدقة الخالية تجيب على السؤال؛ إذا كان النموذج الخاص بي يتنبأ بالفصل السائد بنسبة 100% من الوقت، فكم مرة سيكون صحيحًا؟ في السيناريو أعلاه، 32% من y_test هي 1 (آحاد). بمعنى آخر، النموذج الغبي الذي يتنبأ بأن المرضى مصابون بمرض السكري، سيكون صحيحًا بنسبة 68% من الوقت (وهي الأصفار). وهذا يوفر خط الأساس الذي قد نرغب على أساسه في قياس انحدارنا اللوجستي نموذج.
عندما نقارن الدقة الخالية البالغة 68% ودقة النموذج البالغة 69%، فإن نموذجنا لا يبدو جيدًا جدًا. يوضح هذا أحد نقاط الضعف في دقة التصنيف كمقياس لتقييم النموذج. لا تخبرنا دقة التصنيف بأي شيء عن التوزيع الأساسي لاختبار الاختبار.
في ملخص:
- دقة التصنيف هي أسهل مقياس تصنيف يمكن فهمه
- لكنه لا يخبرك التوزيع الأساسي لقيم الاستجابة
- ولا يخبرك بنوع "أنواع" الأخطاء التي يقوم بها المصنف الخاص بك.
دعونا الآن نلقي نظرة على مصفوفة الارتباك.
مصفوفة الارتباك
مصفوفة الارتباك عبارة عن جدول يصف أداء نموذج التصنيف.
من المفيد مساعدتك على فهم أداء المصنف الخاص بك، ولكنه ليس مقياسًا لتقييم النموذج؛ لذلك لا يمكنك إخبار scikit بتعلم اختيار النموذج الذي يحتوي على أفضل مصفوفة ارتباك. ومع ذلك، هناك العديد من المقاييس التي يمكن حسابها من مصفوفة الارتباك ويمكن استخدامها مباشرة للاختيار بين النماذج.
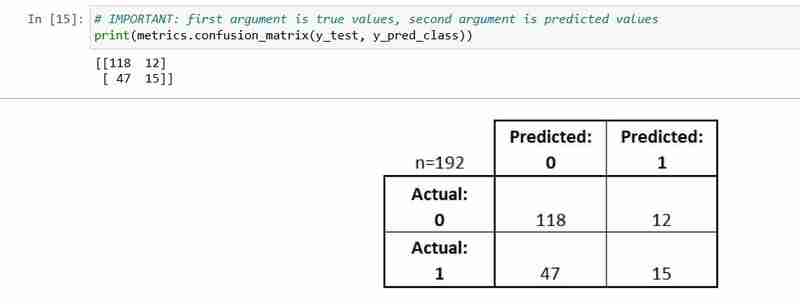
- يتم تمثيل كل ملاحظة في مجموعة الاختبار في مربع واحد بالضبط
- إنها مصفوفة 2x2 لأن هناك فئتان للاستجابة
- التنسيق الموضح هنا هو ليس عالمي
دعونا نشرح بعض مصطلحاته الأساسية.
- الإيجابيات الحقيقية (TP): توقعنا بشكل صحيح أنهم يعانون من مرض السكري
- السلبيات الحقيقية (TN): توقعنا بشكل صحيح أنهم لا مصابون بمرض السكري
- الإيجابيات الكاذبة (FP): لقد توقعنا بشكل غير صحيح أنهم مصابون بمرض السكري ("خطأ من النوع الأول")
- السلبيات الكاذبة (FN): توقعنا بشكل غير صحيح أنهم لا مصابون بمرض السكري ("خطأ من النوع الثاني")
دعونا نرى كيف يمكننا حساب المقاييس
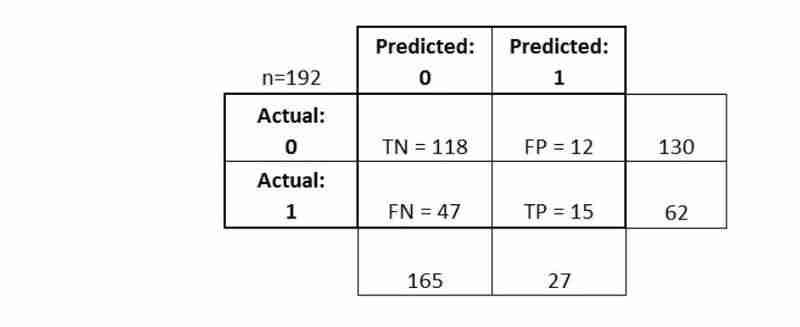


ختاماً:
- تمنحك مصفوفة الارتباك صورة أكثر اكتمالاً عن كيفية أداء المصنف الخاص بك
- يسمح لك أيضًا بحساب مقاييس التصنيف المختلفة، ويمكن لهذه المقاييس توجيه اختيار النموذج الخاص بك
-
 كيفية تحميل الملفات مع معلمات إضافية باستخدام java.net.urlconnection وترميز multipart/form-data؟فيما يلي تفصيل للعملية: multipart/form-data الترميز يتضمن الترميز تقسيم جسم الطلب إلى أجزاء متعددة ، كل منها مسبق بسلسلة حدودية. استيراد java...برمجة نشر في 2025-04-12
كيفية تحميل الملفات مع معلمات إضافية باستخدام java.net.urlconnection وترميز multipart/form-data؟فيما يلي تفصيل للعملية: multipart/form-data الترميز يتضمن الترميز تقسيم جسم الطلب إلى أجزاء متعددة ، كل منها مسبق بسلسلة حدودية. استيراد java...برمجة نشر في 2025-04-12 -
كيف يمكنني استبدال سلاسل متعددة بكفاءة في سلسلة Java؟ومع ذلك ، يمكن أن يكون هذا غير فعال بالنسبة للسلاسل الكبيرة أو عند العمل مع العديد من الأوتار. تتيح لك التعبيرات العادية تحديد أنماط البحث المعقدة ...برمجة نشر في 2025-04-12
-
كيفية تعيين مفاتيح ديناميكي في كائنات JavaScript؟كيفية إنشاء مفتاح ديناميكي لمتغير كائن JavaScript يستخدم النهج الصحيح بين قوسين مربعين: jsObj['key' i] = 'example' 1; لتسديد خاصية مع مفتاح...برمجة نشر في 2025-04-12
-
يقوم إطار YII بسرعة ببناء تطبيقات CRUD ، وهو أمر لا بد منه لخبراء PHPYii框架:快速构建高效CRUD应用的指南 Yii是一个高性能的PHP框架,以其速度、安全性以及对Web 2.0应用的良好支持而闻名。它遵循“约定优于配置”的原则,这意味着只要遵循其规范,就能编写比其他框架少得多的代码(更少的代码意味着更少的bug)。此外,Yii还提供了许多开箱即用的便捷功能,例如...برمجة نشر في 2025-04-12
-
كيفية تحويل المناطق الزمنية بكفاءة في PHP؟تحويل فعال للحيوانات الزمنية في php في PHP ، يمكن أن تكون المناطق الزمنية مهمة مباشرة. سيوفر هذا الدليل طريقة سهلة التنفيذ لتحويل التواريخ والأو...برمجة نشر في 2025-04-12
-
كيفية إدراج النقط (الصور) بشكل صحيح في MySQL باستخدام PHP؟مشكلة. سيوفر هذا الدليل حلولًا لتخزين بيانات الصور الخاصة بك بنجاح. إصدار ImageId ، صورة) القيم ('$ this- & gt ؛ image_id' ، 'fi...برمجة نشر في 2025-04-12
-
لماذا تظهر صورة خلفية CSS الخاصة بي؟توجد ورقة الصورة والأنماط في نفس الدليل ، ومع ذلك ، تظل الخلفية قماشًا أبيض فارغًا. إرفاق اسم ملف الصورة: -صورة الخلفية: url (nickcage.jpg) ؛ إذ...برمجة نشر في 2025-04-12
-
كيفية استرداد الصف الأخير بكفاءة لكل معرف فريد في postgresql؟postgresql: استخراج الصف الأخير لكل معرف فريد في postgresql ، قد تواجه مواقف حيث تحتاج إلى استخراج المعلومات من الصف الأخير المرتبط بكل معرف م...برمجة نشر في 2025-04-12
-
كيف يمكنك استخدام مجموعة من خلال محور البيانات في MySQL؟هنا ، نتعامل مع تحد شائع: تحويل البيانات من الصف إلى الصفوف المستندة إلى الأعمدة باستخدام. لننظر في الاستعلام التالي: حدد البيانات مجموعة بوا...برمجة نشر في 2025-04-12
-
كيفية حل تباينات مسار الوحدة في GO Mod باستخدام توجيه استبدال؟يمكن أن يؤدي ذلك إلى فشل GO MOD TIDY ، كما يتضح من الرسائل المرددة: ` github.com/coreos/etcd/client تم اختبارها بواسطة استيرادات github.com/co...برمجة نشر في 2025-04-12
-
كيف يمكنني اتحاد جداول قاعدة البيانات مع أرقام مختلفة من الأعمدة؟الجداول مجتمعة مع أعمدة مختلفة ] يمكن أن تواجه تحديات عند محاولة دمج جداول قاعدة البيانات بأعمدة مختلفة. تتمثل الطريقة المباشرة في إلحاق القيم ...برمجة نشر في 2025-04-12
-
هل يمكن تكديس عناصر لزجة متعددة فوق بعضها البعض في CSS النقي؟هنا: https://webthemez.com/demo/sticky-multi-header-scroll/index.html فقط أفضل استخدام CSS النقي ، بدلاً من تنفيذ JavaScript. لقد جربت قليلاً ...برمجة نشر في 2025-04-12
-
كيفية إضافة قاعدة بيانات MySQL إلى مربع الحوار DataSource في Visual Studio 2012؟إضافة قاعدة بيانات mysql إلى مربع حوار dataSource في Visual Studio 2012 تتناول هذه المقالة هذه المشكلة وتوفر حلًا. على الرغم من تثبيت موصل MyS...برمجة نشر في 2025-04-12
-
كيفية التعامل مع مدخلات المستخدم في الوضع الحصري لشروط جافا؟تستكشف هذه المقالة النهج الصحيح للتعامل مع إدخال المستخدم من لوحة المفاتيح والماوس في هذا الوضع. ومع ذلك ، في وضع كامل الشاشة الحصري ، قد لا تعمل ه...برمجة نشر في 2025-04-12















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









