
استخدام مكتبات Faker وPandas Python لإنشاء بيانات اصطناعية للاختبار
 تصفح:772
تصفح:772
مقدمة:
يعد الاختبار الشامل أمرًا ضروريًا للتطبيقات المعتمدة على البيانات، ولكنه يعتمد غالبًا على امتلاك مجموعات البيانات الصحيحة، والتي قد لا تكون متاحة دائمًا. سواء كنت تقوم بتطوير تطبيقات الويب، أو نماذج التعلم الآلي، أو الأنظمة الخلفية، فإن البيانات الواقعية والمنظمة أمر بالغ الأهمية للتحقق المناسب وضمان الأداء القوي. قد يكون الحصول على بيانات العالم الحقيقي محدودًا بسبب مخاوف الخصوصية، أو قيود الترخيص، أو ببساطة عدم توفر البيانات ذات الصلة. هذا هو المكان الذي تصبح فيه البيانات الاصطناعية ذات قيمة.
في هذه المدونة، سنستكشف كيف يمكن استخدام بايثون لإنشاء بيانات تركيبية لسيناريوهات مختلفة، بما في ذلك:
- الجداول المترابطة: تمثل علاقات رأس بأطراف.
- البيانات الهرمية: غالبا ما تستخدم في الهياكل التنظيمية.
- العلاقات المعقدة: مثل علاقات متعدد إلى متعدد في أنظمة التسجيل.
سنستفيد من مكتبات Faker وPandas لإنشاء مجموعات بيانات واقعية لحالات الاستخدام هذه.
مثال 1: إنشاء بيانات اصطناعية للعملاء والطلبات (علاقة رأس بأطراف)
في العديد من التطبيقات، يتم تخزين البيانات في جداول متعددة مع علاقات المفاتيح الخارجية. لنقم بإنشاء بيانات تركيبية للعملاء وطلباتهم. يمكن للعميل تقديم طلبات متعددة، مما يمثل علاقة رأس بأطراف.
إنشاء جدول العملاء
يحتوي جدول العملاء على معلومات أساسية مثل معرف العميل والاسم وعنوان البريد الإلكتروني.
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
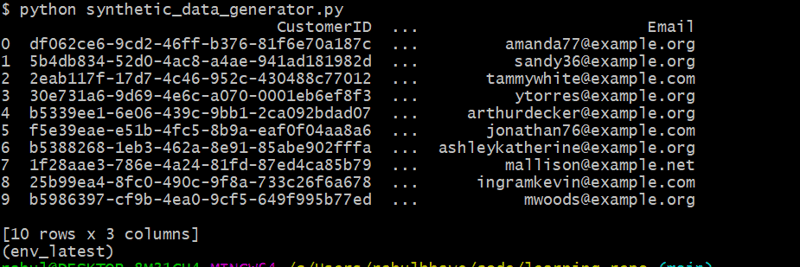
يُنشئ هذا الرمز 10 عملاء عشوائيين يستخدمون Faker لإنشاء أسماء وعناوين بريد إلكتروني واقعية.
إنشاء جدول الطلبات
الآن، نقوم بإنشاء جدول الطلبات، حيث يرتبط كل طلب بالعميل من خلال معرف العميل.
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
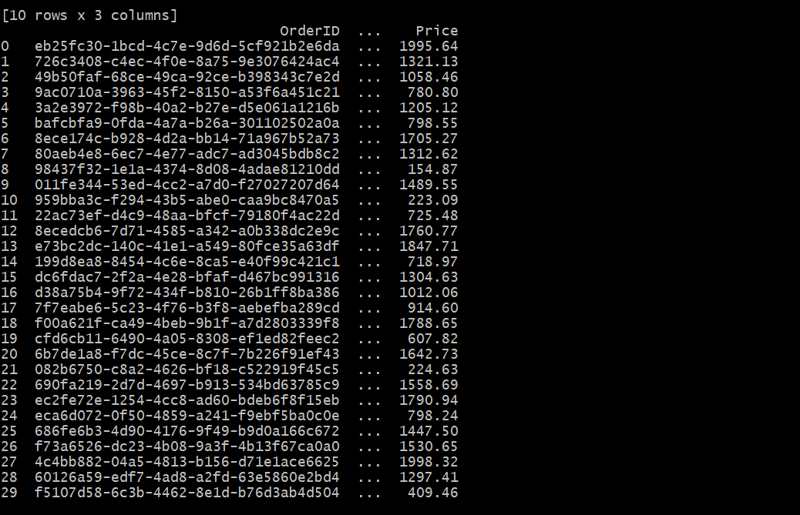
في هذه الحالة، يربط جدول الطلبات كل طلب بعميل يستخدم معرف العميل. يمكن لكل عميل تقديم طلبات متعددة، وتكوين علاقة رأس بأطراف.
مثال 2: إنشاء بيانات هرمية للإدارات والموظفين
غالبًا ما يتم استخدام البيانات الهرمية في الإعدادات التنظيمية، حيث تضم الأقسام العديد من الموظفين. دعونا نحاكي مؤسسة تحتوي على أقسام، كل منها يضم عدة موظفين.
إنشاء جدول الأقسام
يحتوي جدول الأقسام على معرف القسم الفريد والاسم والمدير لكل قسم.
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
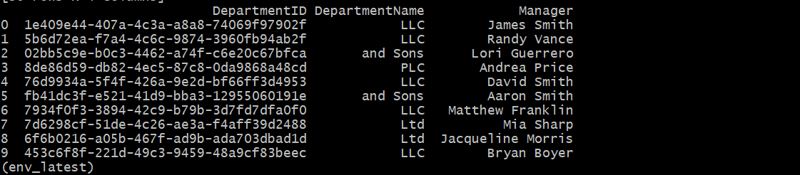
إنشاء جدول الموظفين
بعد ذلك، نقوم بإنشاء جدول الموظفين، حيث يرتبط كل موظف بقسم عبر معرف القسم.
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
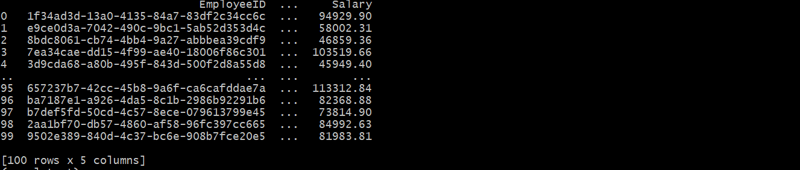
يربط هذا الهيكل الهرمي كل موظف بقسم من خلال معرف القسم، مما يشكل علاقة بين الوالدين والطفل.
مثال 3: محاكاة علاقات متعدد إلى متعدد لعمليات التسجيل في الدورة التدريبية
في بعض السيناريوهات، توجد علاقات متعدد إلى متعدد، حيث يرتبط كيان واحد بالعديد من الكيانات الأخرى. دعونا نحاكي ذلك مع الطلاب المسجلين في دورات متعددة، حيث تضم كل دورة عدة طلاب.
إنشاء جدول المقررات
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
إنشاء جدول الطلاب
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
إنشاء جدول تسجيل المقررات
يصور جدول تسجيلات المقرر الدراسي العلاقة بين متعدد ومتعدد بين الطلاب والدورات التدريبية.
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
في هذا المثال، قمنا بإنشاء جدول ربط لتمثيل علاقات متعدد إلى متعدد بين الطلاب والدورات التدريبية.
خاتمة:
باستخدام Python ومكتبات مثل Faker وPandas، يمكنك إنشاء مجموعات بيانات تركيبية واقعية ومتنوعة لتلبية مجموعة متنوعة من احتياجات الاختبار. تناولنا في هذه المدونة ما يلي:
- الجداول المترابطة: إظهار علاقة رأس بأطراف بين العملاء والطلبات.
- البيانات الهرمية: توضيح العلاقة بين الوالدين والطفل بين الأقسام والموظفين.
- العلاقات المعقدة: محاكاة علاقات متعدد إلى متعدد بين الطلاب والدورات التدريبية.
تضع هذه الأمثلة الأساس لإنشاء بيانات تركيبية مصممة خصيصًا لتلبية احتياجاتك. يمكن أن تؤدي التحسينات الإضافية، مثل إنشاء علاقات أكثر تعقيدًا، أو تخصيص البيانات لقواعد بيانات محددة، أو توسيع نطاق مجموعات البيانات لاختبار الأداء، إلى نقل عملية إنشاء البيانات الاصطناعية إلى المستوى التالي.
توفر هذه الأمثلة أساسًا متينًا لتوليد البيانات الاصطناعية. ومع ذلك، يمكن إجراء المزيد من التحسينات لزيادة التعقيد والخصوصية، مثل:
- بيانات خاصة بقاعدة البيانات: تخصيص إنشاء البيانات لأنظمة قواعد البيانات المختلفة (على سبيل المثال، SQL مقابل NoSQL).
- علاقات أكثر تعقيدًا: إنشاء علاقات متبادلة إضافية، مثل العلاقات الزمنية، أو التسلسلات الهرمية متعددة المستويات، أو القيود الفريدة.
- قياس البيانات: إنشاء مجموعات بيانات أكبر لاختبار الأداء أو اختبار التحمل، مما يضمن قدرة النظام على التعامل مع ظروف العالم الحقيقي على نطاق واسع. من خلال إنشاء بيانات تركيبية مصممة خصيصًا لتلبية احتياجاتك، يمكنك محاكاة الظروف الواقعية لتطوير التطبيقات واختبارها وتحسينها دون الاعتماد على مجموعات البيانات الحساسة أو التي يصعب الحصول عليها.
إذا أعجبك المقال، يرجى مشاركته مع أصدقائك وزملائك. يمكنك التواصل معي على LinkedIn لمناقشة أي أفكار أخرى.
-
 كيف يمكنني استرداد قيم السمات بكفاءة من ملفات XML باستخدام PHP؟عند العمل مع ملف XML يحتوي على سمات مثل المثال المقدم: Stumped. لحل هذا ، يقدم PHP حلًا مباشرًا باستخدام وظيفة SimplexMlelement :: Attribut...برمجة نشر في 2025-04-27
كيف يمكنني استرداد قيم السمات بكفاءة من ملفات XML باستخدام PHP؟عند العمل مع ملف XML يحتوي على سمات مثل المثال المقدم: Stumped. لحل هذا ، يقدم PHP حلًا مباشرًا باستخدام وظيفة SimplexMlelement :: Attribut...برمجة نشر في 2025-04-27 -
كيفية حل \ "رفض تحميل البرنامج النصي ... \" الأخطاء بسبب سياسة أمان محتوى Android \؟تنبع هذه المشكلة من توجيهات سياسة أمان المحتوى (CSP) ، والتي تقيد تحميل الموارد من مصادر غير موثوق بها. ومع ذلك ، يمكن أن يكون حل هذا التحدي واضحًا...برمجة نشر في 2025-04-27
-
كيفية التعامل مع مدخلات المستخدم في الوضع الحصري لشروط جافا؟تستكشف هذه المقالة النهج الصحيح للتعامل مع إدخال المستخدم من لوحة المفاتيح والماوس في هذا الوضع. ومع ذلك ، في وضع كامل الشاشة الحصري ، قد لا تعمل ه...برمجة نشر في 2025-04-27
-
Async void vs. Async Task in ASP.NET: لماذا ترمي طريقة الفراغ Async أحيانًا استثناءات؟ومع ذلك ، يمكن أن يؤدي سوء فهم الاختلافات الرئيسية بين أساليب المهمة ASYNC و ASYNC إلى أخطاء غير متوقعة. يستكشف هذا السؤال لماذا قد تؤدي أساليب الف...برمجة نشر في 2025-04-27
-
كيف يمكنك استخدام مجموعة من خلال محور البيانات في MySQL؟هنا ، نتعامل مع تحد شائع: تحويل البيانات من الصف إلى الصفوف المستندة إلى الأعمدة باستخدام. لننظر في الاستعلام التالي: حدد البيانات مجموعة بوا...برمجة نشر في 2025-04-27
-
كيف يمكنني تخصيص تحسينات التجميع في برنامج التحويل البرمجي GO؟ومع ذلك ، قد يحتاج المستخدمون إلى ضبط هذه التحسينات لمتطلبات معينة. هذا يعني أن المترجم يطبق تلقائيًا التحسينات القائمة على الاستدلال المحدد مسبقً...برمجة نشر في 2025-04-27
-
هل هناك اختلاف في الأداء بين استخدام حلقة EACH وتكرار لجمع اجتماعي في Java؟تستكشف هذه المقالة اختلافات الكفاءة بين هذين النهجين. يستخدم ITerator داخليًا: قائمة a = new ArrayList () ؛ ل (عدد صحيح عدد صحيح: أ) { intege...برمجة نشر في 2025-04-27
-
كيفية إدراج البيانات بكفاءة في جداول MySQL متعددة في معاملة واحدة؟mysql إدراج في جداول متعددة على الرغم من أن الأمر قد يبدو أن استفسارات متعددة من شأنه حل المشكلة ، فإن ربط معرف الدخل التلقائي من جدول المستخدم...برمجة نشر في 2025-04-27
-
لماذا أحصل على خطأ "لا يمكنني العثور على تنفيذ نمط الاستعلام" في استعلام Silverlight LINQ الخاص بي؟يحدث هذا الخطأ عادةً عندما يتم حذف مساحة اسم LINQ أو يفتقر إلى النوع الذي تم الاستعلام عن تطبيقه . في هذه الحالة المحددة ، قد يتطلب tblpersoon الت...برمجة نشر في 2025-04-27
-
كيف يمكنني تسلسل النص والقيم بأمان عند بناء استعلامات SQL في GO؟تسلسس النص والقيم في استعلامات sql go نهج tuple غير صالح في GO ، ومحاولة إلقاء المعلمات لأن السلاسل ستؤدي إلى أخطاء عدم التوافق في النوع. يتيح ل...برمجة نشر في 2025-04-27
-
كيفية الحد من نطاق التمرير لعنصر داخل عنصر الوالد الحجم ديناميكي؟يتضمن أحد هذه السيناريو الحد من نطاق التمرير لعنصر داخل عنصر الوالدين ديناميكيًا. المشكلة: ومع ذلك ، يمتد تمرير الخريطة إلى أجل غير مسمى ، ويتج...برمجة نشر في 2025-04-27
-
\ "بينما (1) مقابل (؛؛): هل يزيل التحسين المترجم اختلافات الأداء؟ \"بينما (1) مقابل (؛؛): هل هناك فرق السرعة؟ حلقات؟ الإجابة: المجمعات: بيرل: 1 أدخل -> 2 2 NextState (Main 2 -e: 1) V -> 3 9 LEAVELOOP VK/2...برمجة نشر في 2025-04-27
-
كيفية تعديل سمة CSS بشكل فعال للعنصر الزائف "بعد" باستخدام jQuery؟فهم قيود العناصر الزائفة في jQuery: الوصول إلى ": بعد" Selector ومع ذلك ، فإن الوصول إلى هذه العناصر ومعالجتها باستخدام jQuery يمكن أن...برمجة نشر في 2025-04-27
-
كيفية تحليل صفائف JSON في GO باستخدام حزمة `json`؟مثال: صفيف [] سلسلة } Func Main () { DataJson: = `[" 1 "،" 2 "،" 3 "]` ` ARR: = jsontype {} unmars...برمجة نشر في 2025-04-27















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









