
كيفية تحويل ملفات PDF إلى Markdown باستخدام PyMuPDFM وتقييمه
 تصفح:798
تصفح:798
PyMuPDF4LLM هي مكتبة مصممة لتحويل ملفات PDF إلى تنسيق Markdown. هنا، سأشارك تجربتي في اختبار هذه المكتبة.
تثبيت
ابدأ بتثبيت المكتبة باستخدام الأمر التالي:
pip install pymupdf4llm
الاستخدام
الاستخدام الأساسي بسيط للغاية، حيث يتطلب ثلاثة أسطر فقط من التعليمات البرمجية لتحويل ملف PDF إلى Markdown:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("input.pdf")
print(md_text)
يمكنك تحديد الوسائط لضبط كيفية استخراج المحتوى.
استخراج النص حسب الصفحة
افتراضيًا، يتم تحويل ملف PDF بأكمله إلى مخرج نص واحد. ومع ذلك، يمكنك استخراج النص صفحة تلو الأخرى عن طريق تحديد page_chunks=True.
md_text = pymupdf4llm.to_markdown("input.pdf", page_chunks=True)
استخراج الصور
لاستخراج الصور كملفات، استخدم خيار write_images=True:
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
من الممكن أيضًا تضمين الصور مباشرة في Markdown باستخدام تشفير base64:
md_text = pymupdf4llm.to_markdown("input.pdf", embed_images=True)
تقييم نتائج التحويل
للاختبار، تم استخدام ملفات PDF متنوعة مع عناصر Markdown مختلفة.

تحويل الرأس
يتم تحويل الرؤوس بشكل صحيح إلى تنسيق Markdown. وهذا جزء من النتيجة:
# Sample Markdown Guide This is a sample markdown file that includes various features for quick reference. ## 1. Headers ... ## 3. Lists
نص غامق ومائل
يتم أيضًا تحويل التنسيق الغامق والمائل بشكل صحيح:
**Bold: **Bold Text**** _Italic: *Italic Text*_ **_Bold and Italic: ***Bold and Italic***_**
تحويل القائمة
يتم تحويل القوائم المرتبة في المستوى الأول دون مشاكل، ولكن القوائم المتداخلة والقوائم غير المرتبة لا يتم تحويلها بدقة.
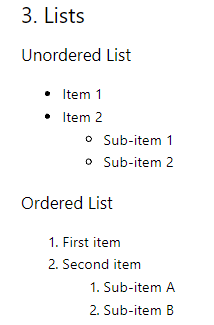
## 3. Lists ### Unordered List Item 1 Item 2 Sub-item 1 Sub-item 2 ### Ordered List 1. First item 2. Second item 1. Sub-item A 2. Sub-item B
تحويل الارتباط
يتم استخراج عناوين URL للروابط، ولكن السطر بأكمله الذي يحتوي على الرابط يصبح رابطًا تشعبيًا، مما ينحرف عن التنسيق الأصلي.
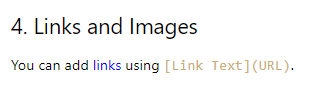
## 4. Links and Images [You can add links using [Link Text](URL).](https://www.example.com/)
استخراج الصور
لا يتم استخراج الصور بشكل افتراضي ولكن يمكن حفظها محليًا باستخدام write_images=True.
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
يتم بعد ذلك الإشارة إلى الصور المحفوظة في Markdown على النحو التالي:
### Image Example

تحويل الجدول
لا يتم تحويل الجداول البسيطة التي لا تحتوي على حدود رأسية بدقة (على الأرجح لأن حدود الأعمدة الغامضة تؤدي إلى معاملة الجداول كنص عادي).

## 5. Tables
**Column 1** **Column 2** **Column 3**
Row 1 Data A Data B
Row 2 Data C Data D
تحويل الكود
يتم تحويل كتل التعليمات البرمجية بشكل صحيح، ولكن لا يتم الاحتفاظ بمواصفات اللغة (على سبيل المثال، بايثون). هناك مشكلات أيضًا في تحويل التعليمات البرمجية المضمنة.

## 6. Code
### Inline Code
Use backticks for inline code: print("Hello, world!")
### Code Block
Use triple backticks for code blocks:
```
def greet(name):
return f"Hello, {name}!"
print(greet("Markdown"))
```
نص متعدد الأسطر
بالنسبة للنص متعدد الأسطر، يتم الاحتفاظ بفواصل الأسطر كما تظهر في ملف PDF الأصلي.

Markdown is a lightweight and versatile markup language favored by developers, writers, and bloggers alike
due to its simplicity in formatting text, enabling users to create readable and well-structured documents—
whether for documentation, blog posts, or articles—without the complexity of HTML, while also offering the
ability to convert content seamlessly into other formats like HTML, PDF, and even slideshows, making it an
ideal choice for projects that require both clarity and flexibility in presentation.
خاتمة
على الرغم من التحديات في تحويل القوائم والروابط بدقة، فإن PyMuPDF4LLM هي أداة مفيدة لتحويل ملفات PDF إلى Markdown. يمكن أن يعمل محليًا دون الحاجة إلى نماذج لغة خارجية، مما يجعله مناسبًا للبيئات التي لا يتوفر فيها الوصول إلى الإنترنت.
-
 كيف يمكنني تكرار القيم والطباعة بشكل متزامن من صفائف متساوية في الحجم في PHP؟تكرار وطباعة بشكل متزامن من صفيفتين من نفس الحجم المصفوفات: foreach (رموز $ كرمز $ وأسماء $ كاسم $) { ... } هذا النهج غير صالح. بدلاً من ...برمجة نشر في 2025-04-05
كيف يمكنني تكرار القيم والطباعة بشكل متزامن من صفائف متساوية في الحجم في PHP؟تكرار وطباعة بشكل متزامن من صفيفتين من نفس الحجم المصفوفات: foreach (رموز $ كرمز $ وأسماء $ كاسم $) { ... } هذا النهج غير صالح. بدلاً من ...برمجة نشر في 2025-04-05 -
كيف يمكنني تصميم المثال الأول لنوع عنصر معين عبر مستند HTML بأكمله؟مطابقة العنصر الأول من نوع معين في المستند بالكامل يمكن أن يكون التصميم الأول من نوع معين عبر مستند HTML بالكامل تحديًا باستخدام CSS وحده. يق...برمجة نشر في 2025-04-05
-
كيفية إدراج النقط (الصور) بشكل صحيح في MySQL باستخدام PHP؟مشكلة. سيوفر هذا الدليل حلولًا لتخزين بيانات الصور الخاصة بك بنجاح. إصدار ImageId ، صورة) القيم ('$ this- & gt ؛ image_id' ، 'fi...برمجة نشر في 2025-04-05
-
كيفية حل تباينات مسار الوحدة في GO Mod باستخدام توجيه استبدال؟يمكن أن يؤدي ذلك إلى فشل GO MOD TIDY ، كما يتضح من الرسائل المرددة: ` github.com/coreos/etcd/client تم اختبارها بواسطة استيرادات github.com/co...برمجة نشر في 2025-04-05
-
\ "بينما (1) مقابل (؛؛): هل يزيل التحسين المترجم اختلافات الأداء؟ \"بينما (1) مقابل (؛؛): هل هناك فرق السرعة؟ حلقات؟ الإجابة: المجمعات: بيرل: 1 أدخل -> 2 2 NextState (Main 2 -e: 1) V -> 3 9 LEAVELOOP VK/2...برمجة نشر في 2025-04-05
-
كيف يمكنني تسلسل النص والقيم بأمان عند بناء استعلامات SQL في GO؟تسلسس النص والقيم في استعلامات sql go نهج tuple غير صالح في GO ، ومحاولة إلقاء المعلمات لأن السلاسل ستؤدي إلى أخطاء عدم التوافق في النوع. يتيح ل...برمجة نشر في 2025-04-05
-
كيف يمكنني تكوين pytesseract للتعرف على أرقام واحدة مع إخراج الأرقام فقط؟لمعالجة هذه المشكلة ، نقوم بالتعمق في تفاصيل خيارات تكوين Tesseract. من أجل التعرف على الأحرف الفردية ، فإن PSM المناسب هو 10. هذا الوضع يعامل الصو...برمجة نشر في 2025-04-05
-
كيف يمكنني إنشاء رخويات ملائمة عناوين URL بكفاءة من سلاسل Unicode في PHP؟صياغة دالة لتوليد سبيكة فعالة تقدم هذه المقالة حلاً موجزًا لتوليد الرخويات بكفاءة ، وتحويل الأحرف الخاصة والأحرف غير ASCII إلى تنسيقات سهلة U...برمجة نشر في 2025-04-05
-
كيفية استخراج النص داخل الأقواس بكفاءة في PHP باستخدام regexأحد الأساليب هو استخدام وظائف معالجة سلسلة PHP ، كما هو موضح أدناه: $ fullString = "تجاهل كل شيء باستثناء هذا (النص)" ؛ ، $ fullstrin...برمجة نشر في 2025-04-05
-
كيفية تجاوز كتل موقع الويب مع طلبات Python ووكلاء المستخدمين المزيفين؟كيفية محاكاة سلوك المتصفح مع طلبات Python ووكلاء المستخدمين المزيفين تعتبر مكتبة طلبات Python أداة قوية لتقديم طلبات HTTP ، لكنها قد تواجه قيود...برمجة نشر في 2025-04-05
-
كيفية الجمع بين البيانات من ثلاثة جداول MySQL في جدول جديد؟الأشخاص والتفاصيل وجداول التصنيف؟ الإجابة: حدد ص.*، د. من الناس ك انضم إلى التفاصيل كـ D على D.Person_id = p.id انضم إلى التصنيف كـ t على t....برمجة نشر في 2025-04-05
-
Python قراءة ملف CSV UnicodedEcodeerror الحل النهائيلا يمكن فك تشفير البايت في الموضع 2-3: مقطوع \ uxxxxxxxxx escart string قم بتعبئة المسار إلى ملف CSV مع وضع صغير "r" للدلالة على سل...برمجة نشر في 2025-04-05
-
كيفية تحويل عمود DataFrame Pandas إلى تنسيق DateTime وتصفية حسب التاريخ؟تحويل عمود DataFrame pandas إلى تنسيق DateTime عند العمل مع البيانات الزمنية ، قد تظهر الطوابع الزمنية في البداية كسلاسل ولكن يجب تحويلها إلى تنس...برمجة نشر في 2025-04-05
-
هل تسمح Java بأنواع عائدات متعددة: نظرة فاحصة على الطرق العامة؟أنواع عائدات متعددة في java: تم الكشف عن المفاهيم الخاطئة getResult (String s) ؛ حيث Foo فئة مخصصة. يبدو أن إعلان الطريقة يضم نوعين من الإرج...برمجة نشر في 2025-04-05
-
كيف ترسل طلب النشر الخام مع حليقة في PHP؟كيفية إرسال طلب النشر الخام باستخدام حليقة في php في PHP ، تعد Curl مكتبة شهيرة لإرسال طلبات HTTP. ستوضح هذه المقالة كيفية استخدام Curl لأداء ...برمجة نشر في 2025-04-05















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









