 الصفحة الأمامية > برمجة > ClassiSage: نموذج تصنيف سجل HDFS المستند إلى Terraform IaC الآلي AWS SageMaker
الصفحة الأمامية > برمجة > ClassiSage: نموذج تصنيف سجل HDFS المستند إلى Terraform IaC الآلي AWS SageMaker
ClassiSage: نموذج تصنيف سجل HDFS المستند إلى Terraform IaC الآلي AWS SageMaker
 تصفح:501
تصفح:501
ClassiSage
A Machine Learning model made with AWS SageMaker and its Python SDK for Classification of HDFS Logs using Terraform for automation of infrastructure setup.
Link: GitHub
Language: HCL (terraform), Python
Content
- Overview: Project Overview.
- System Architecture: System Architecture Diagram
- ML Model: Model Overview.
- Getting Started: How to run the project.
- Console Observations: Changes in instances and infrastructure that can be observed while running the project.
- Ending and Cleanup: Ensuring no additional charges.
- Auto Created Objects: Files and Folders created during execution process.
- Firstly follow the Directory Structure for better project setup.
- Take major reference from the ClassiSage's Project Repository uploaded in GitHub for better understanding.
Overview
- The model is made with AWS SageMaker for Classification of HDFS Logs along with S3 for storing dataset, Notebook file (containing code for SageMaker instance) and Model Output.
- The Infrastructure setup is automated using Terraform a tool to provide infrastructure-as-code created by HashiCorp
- The data set used is HDFS_v1.
- The project implements SageMaker Python SDK with the model XGBoost version 1.2
System Architecture
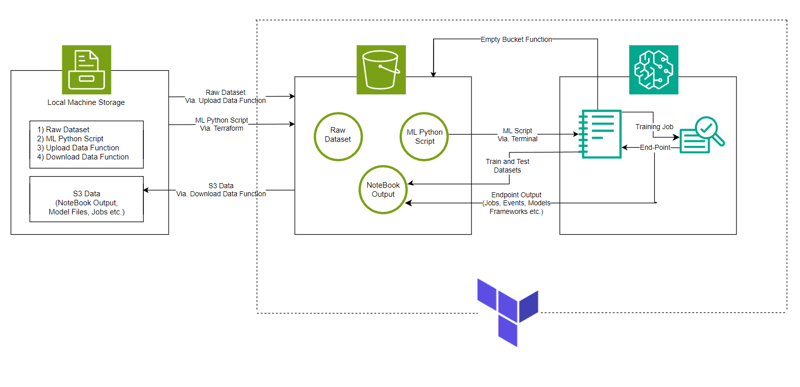
ML Model
- Image URI
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')

- Initializing Hyper Parameter and Estimator call to the container
hyperparameters = {
"max_depth":"5", ## Maximum depth of a tree. Higher means more complex models but risk of overfitting.
"eta":"0.2", ## Learning rate. Lower values make the learning process slower but more precise.
"gamma":"4", ## Minimum loss reduction required to make a further partition on a leaf node. Controls the model’s complexity.
"min_child_weight":"6", ## Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting.
"subsample":"0.7", ## Fraction of training data used. Reduces overfitting by sampling part of the data.
"objective":"binary:logistic", ## Specifies the learning task and corresponding objective. binary:logistic is for binary classification.
"num_round":50 ## Number of boosting rounds, essentially how many times the model is trained.
}
# A SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=container, # Points to the XGBoost container we previously set up. This tells SageMaker which algorithm container to use.
hyperparameters=hyperparameters, # Passes the defined hyperparameters to the estimator. These are the settings that guide the training process.
role=sagemaker.get_execution_role(), # Specifies the IAM role that SageMaker assumes during the training job. This role allows access to AWS resources like S3.
train_instance_count=1, # Sets the number of training instances. Here, it’s using a single instance.
train_instance_type='ml.m5.large', # Specifies the type of instance to use for training. ml.m5.2xlarge is a general-purpose instance with a balance of compute, memory, and network resources.
train_volume_size=5, # 5GB # Sets the size of the storage volume attached to the training instance, in GB. Here, it’s 5 GB.
output_path=output_path, # Defines where the model artifacts and output of the training job will be saved in S3.
train_use_spot_instances=True, # Utilizes spot instances for training, which can be significantly cheaper than on-demand instances. Spot instances are spare EC2 capacity offered at a lower price.
train_max_run=300, # Specifies the maximum runtime for the training job in seconds. Here, it's 300 seconds (5 minutes).
train_max_wait=600) # Sets the maximum time to wait for the job to complete, including the time waiting for spot instances, in seconds. Here, it's 600 seconds (10 minutes).
- Training Job
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
- Deployment
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')

- Validation
from sagemaker.serializers import CSVSerializer
import numpy as np
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
# Drop the label column from the test data
test_data_features = test_data_final.drop(columns=['Label']).values
# Set the content type and serializer
xgb_predictor.serializer = CSVSerializer()
xgb_predictor.content_type = 'text/csv'
# Perform prediction
predictions = xgb_predictor.predict(test_data_features).decode('utf-8')
y_test = test_data_final['Label'].values
# Convert the predictions into a array
predictions_array = np.fromstring(predictions, sep=',')
print(predictions_array.shape)
# Converting predictions them to binary (0 or 1)
threshold = 0.5
binary_predictions = (predictions_array >= threshold).astype(int)
# Accuracy
accuracy = accuracy_score(y_test, binary_predictions)
# Precision
precision = precision_score(y_test, binary_predictions)
# Recall
recall = recall_score(y_test, binary_predictions)
# F1 Score
f1 = f1_score(y_test, binary_predictions)
# Confusion Matrix
cm = confusion_matrix(y_test, binary_predictions)
# False Positive Rate (FPR) using the confusion matrix
tn, fp, fn, tp = cm.ravel()
false_positive_rate = fp / (fp tn)
# Print the metrics
print(f"Accuracy: {accuracy:.8f}")
print(f"Precision: {precision:.8f}")
print(f"Recall: {recall:.8f}")
print(f"F1 Score: {f1:.8f}")
print(f"False Positive Rate: {false_positive_rate:.8f}")
Getting Started
- Clone the repository using Git Bash / download a .zip file / fork the repository.
- Go to your AWS Management Console, click on your account profile on the Top-Right corner and select My Security Credentials from the dropdown.
- Create Access Key: In the Access keys section, click on Create New Access Key, a dialog will appear with your Access Key ID and Secret Access Key.
- Download or Copy Keys: (IMPORTANT) Download the .csv file or copy the keys to a secure location. This is the only time you can view the secret access key.
- Open the cloned Repo. in your VS Code
- Create a file under ClassiSage as terraform.tfvars with its content as
# terraform.tfvars access_key = "" secret_key = " " aws_account_id = " "
- Download and install all the dependancies for using Terraform and Python.
In the terminal type/paste terraform init to initialize the backend.
Then type/paste terraform Plan to view the plan or simply terraform validate to ensure that there is no error.
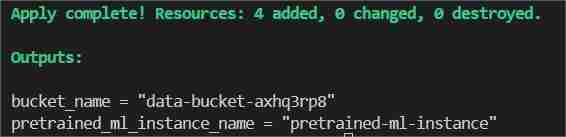
Finally in the terminal type/paste terraform apply --auto-approve
This will show two outputs one as bucket_name other as pretrained_ml_instance_name (The 3rd resource is the variable name given to the bucket since they are global resources ).
- After Completion of the command is shown in the terminal, navigate to ClassiSage/ml_ops/function.py and on the 11th line of the file with code
output = subprocess.check_output('terraform output -json', shell=True, cwd = r'' #C:\Users\Saahen\Desktop\ClassiSage
and change it to the path where the project directory is present and save it.
- Then on the ClassiSage\ml_ops\data_upload.ipynb run all code cell till cell number 25 with the code
# Try to upload the local CSV file to the S3 bucket
try:
print(f"try block executing")
s3.upload_file(
Filename=local_file_path,
Bucket=bucket_name,
Key=file_key # S3 file key (filename in the bucket)
)
print(f"Successfully uploaded {file_key} to {bucket_name}")
# Delete the local file after uploading to S3
os.remove(local_file_path)
print(f"Local file {local_file_path} deleted after upload.")
except Exception as e:
print(f"Failed to upload file: {e}")
os.remove(local_file_path)
to upload dataset to S3 Bucket.
- Output of the code cell execution

- After the execution of the notebook re-open your AWS Management Console.
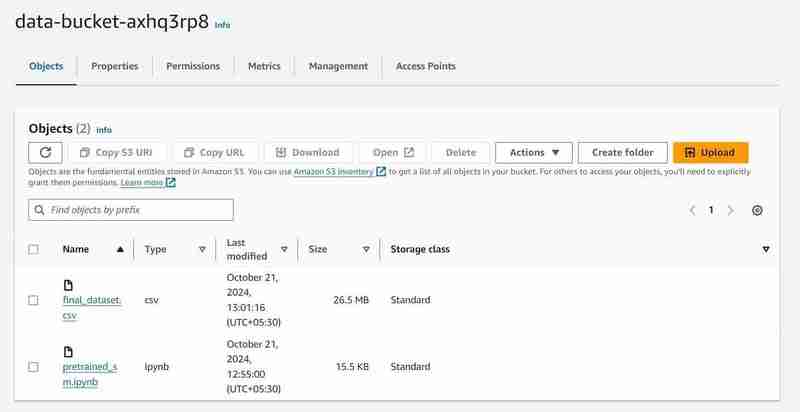
- You can search for S3 and Sagemaker services and will see an instance of each service initiated (A S3 bucket and a SageMaker Notebook)
S3 Bucket with named 'data-bucket-' with 2 objects uploaded, a dataset and the pretrained_sm.ipynb file containing model code.
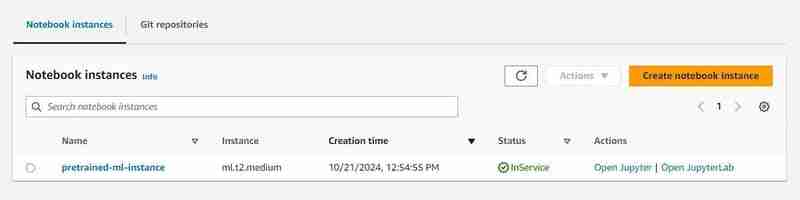
- Go to the notebook instance in the AWS SageMaker, click on the created instance and click on open Jupyter.
- After that click on new on the top right side of the window and select on terminal.
- This will create a new terminal.
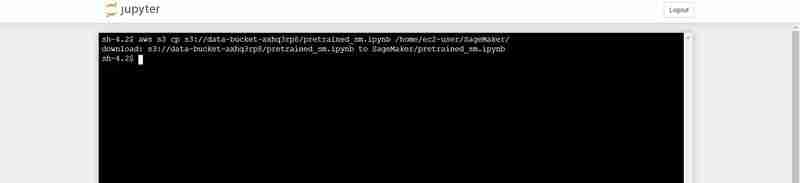
- On the terminal paste the following (Replacing with the bucket_name output that is shown in the VS Code's terminal output):
aws s3 cp s3:///pretrained_sm.ipynb /home/ec2-user/SageMaker/
Terminal command to upload the pretrained_sm.ipynb from S3 to Notebook's Jupyter environment
- Go Back to the opened Jupyter instance and click on the pretrained_sm.ipynb file to open it and assign it a conda_python3 Kernel.
- Scroll Down to the 4th cell and replace the variable bucket_name's value by the VS Code's terminal output for bucket_name = "
"
# S3 bucket, region, session
bucket_name = 'data-bucket-axhq3rp8'
my_region = boto3.session.Session().region_name
sess = boto3.session.Session()
print("Region is " my_region " and bucket is " bucket_name)
Output of the code cell execution

- On the top of the file do a Restart by going to the Kernel tab.
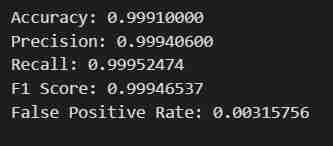
- Execute the Notebook till code cell number 27, with the code
# Print the metrics
print(f"Accuracy: {accuracy:.8f}")
print(f"Precision: {precision:.8f}")
print(f"Recall: {recall:.8f}")
print(f"F1 Score: {f1:.8f}")
print(f"False Positive Rate: {false_positive_rate:.8f}")
- You will get the intended result. The data will be fetched, split into train and test sets after being adjusted for Labels and Features with a defined output path, then a model using SageMaker's Python SDK will be Trained, Deployed as a EndPoint, Validated to give different metrics.
Console Observation Notes
Execution of 8th cell
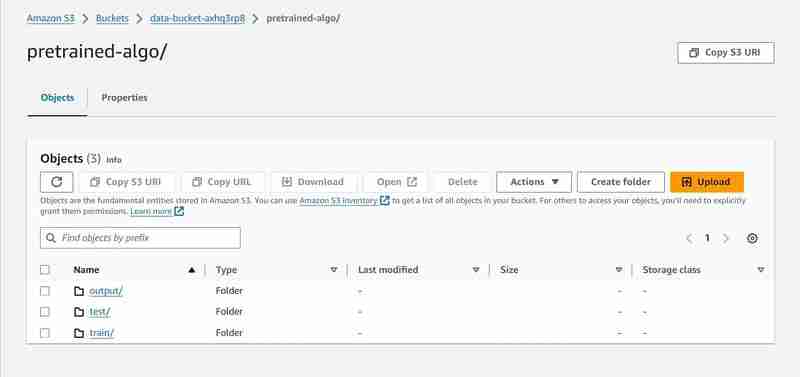
# Set an output path where the trained model will be saved
prefix = 'pretrained-algo'
output_path ='s3://{}/{}/output'.format(bucket_name, prefix)
print(output_path)
- An output path will be setup in the S3 to store model data.
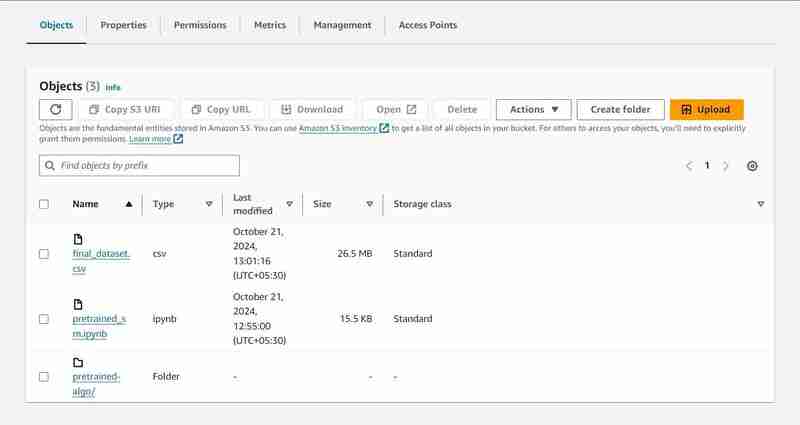
Execution of 23rd cell
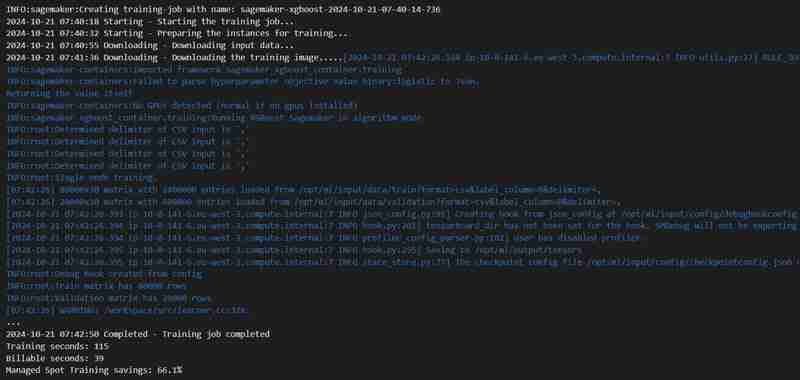
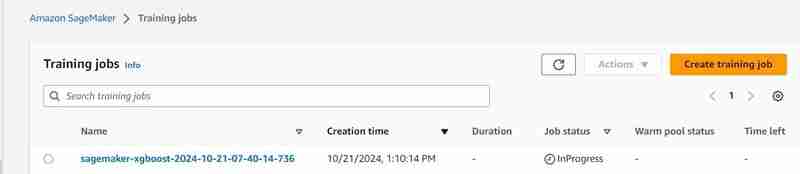
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
- A training job will start, you can check it under the training tab.
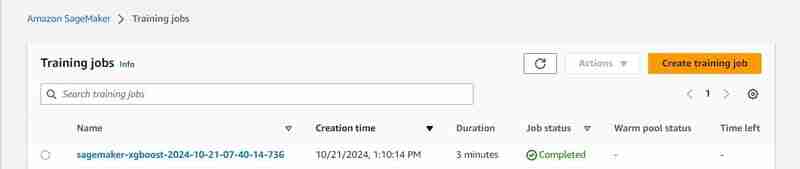
- After some time (3 mins est.) It shall be completed and will show the same.
Execution of 24th code cell
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')
- An endpoint will be deployed under Inference tab.
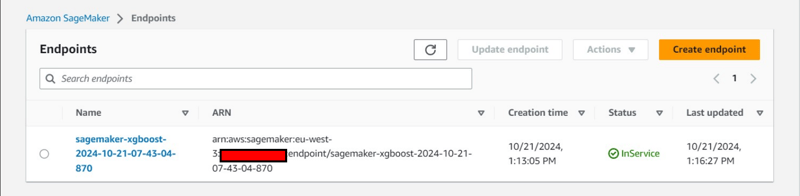
Additional Console Observation:
- Creation of an Endpoint Configuration under Inference tab.
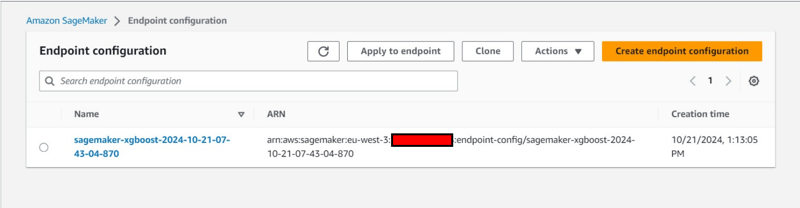
- Creation of an model also under under Inference tab.
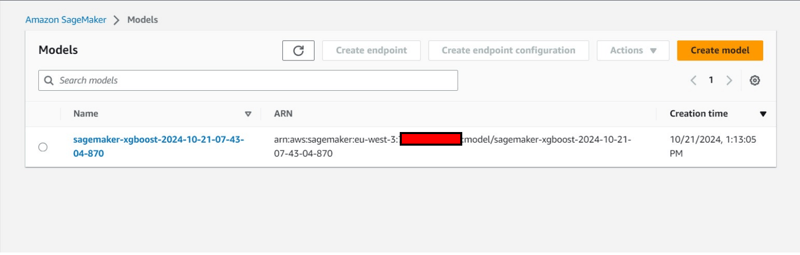
Ending and Cleanup
- In the VS Code comeback to data_upload.ipynb to execute last 2 code cells to download the S3 bucket's data into the local system.
- The folder will be named downloaded_bucket_content. Directory Structure of folder Downloaded.
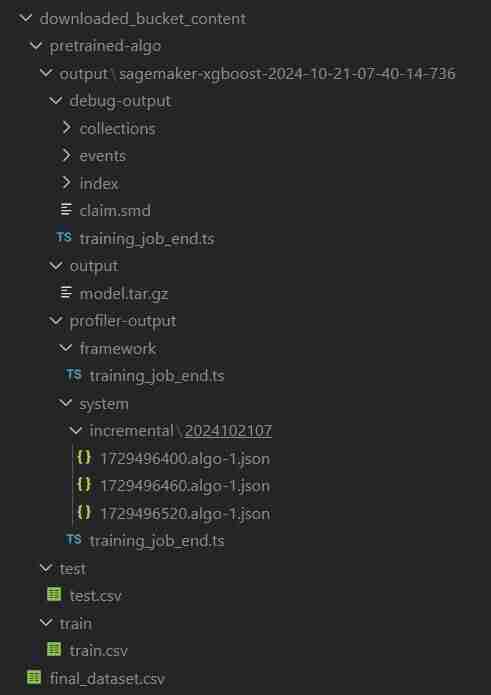
- You will get a log of downloaded files in the output cell. It will contain a raw pretrained_sm.ipynb, final_dataset.csv and a model output folder named 'pretrained-algo' with the execution data of the sagemaker code file.
- Finally go into pretrained_sm.ipynb present inside the SageMaker instance and execute the final 2 code cells. The end-point and the resources within the S3 bucket will be deleted to ensure no additional charges.
- Deleting The EndPoint
sagemaker.Session().delete_endpoint(xgb_predictor.endpoint)

- Clearing S3: (Needed to destroy the instance)
bucket_to_delete = boto3.resource('s3').Bucket(bucket_name)
bucket_to_delete.objects.all().delete()
- Come back to the VS Code terminal for the project file and then type/paste terraform destroy --auto-approve
- All the created resource instances will be deleted.
Auto Created Objects
ClassiSage/downloaded_bucket_content
ClassiSage/.terraform
ClassiSage/ml_ops/pycache
ClassiSage/.terraform.lock.hcl
ClassiSage/terraform.tfstate
ClassiSage/terraform.tfstate.backup
NOTE:
If you liked the idea and the implementation of this Machine Learning Project using AWS Cloud's S3 and SageMaker for HDFS log classification, using Terraform for IaC (Infrastructure setup automation), Kindly consider liking this post and starring after checking-out the project repository at GitHub.
-
 إتقان العلاقات الثنائية الاتجاه بين شخصين بخطوات: تعزيز كفاءة Spring Data JPAإطلاق العنان لقوة العلاقات الثنائية الاتجاه بين شخصين في هذا الدليل المتعمق، سنستكشف تعقيدات الارتباطات الفردية المتبادلة وعمليات CRUD ودور MappedBy ...برمجة تم النشر بتاريخ 2024-11-07
إتقان العلاقات الثنائية الاتجاه بين شخصين بخطوات: تعزيز كفاءة Spring Data JPAإطلاق العنان لقوة العلاقات الثنائية الاتجاه بين شخصين في هذا الدليل المتعمق، سنستكشف تعقيدات الارتباطات الفردية المتبادلة وعمليات CRUD ودور MappedBy ...برمجة تم النشر بتاريخ 2024-11-07 -
استخدام مكتبات Faker وPandas Python لإنشاء بيانات اصطناعية للاختبارمقدمة: يعد الاختبار الشامل أمرًا ضروريًا للتطبيقات المعتمدة على البيانات، ولكنه يعتمد غالبًا على امتلاك مجموعات البيانات الصحيحة، والتي قد لا تكون متا...برمجة تم النشر بتاريخ 2024-11-07
-
اذهب هتمكس وSSE سبيل المثاليوضح هذا المثال كيفية استبدال بعض الكتل في الحدث، على سبيل المثال "تم تغيير المنشور بالمعرف 1" (تم التغيير بعد 1) وتشغيل تحميل المحتوى ع...برمجة تم النشر بتاريخ 2024-11-07
-
المشاكل والأخطاء الحالية في تجريف الويب في بايثون وحيل لحلها!Introduction Greetings! I'm Max, a Python developer from Ukraine, a developer with expertise in web scraping, data analysis, and processing. ...برمجة تم النشر بتاريخ 2024-11-07
-
هل يمكن لخصائص نموذج Django تحسين تصفية الاستعلام؟هل يمكن لخصائص النموذج تحسين تصفية الاستعلام في جانغو؟ إحدى الميزات الرئيسية للبرمجة الموجهة للكائنات في جانغو هي القدرة على التعريف خصائص الن...برمجة تم النشر بتاريخ 2024-11-07
-
عزز كفاءة تطبيقك باستخدام GraphQL وReact: نظرة عميقةهل تتطلع إلى تبسيط عملية تطوير التطبيق الخاص بك؟ قد يكون الجمع بين GraphQL وReact هو التغيير الذي تحتاجه. في مقالتنا الأخيرة، نستكشف كيف تعمل هذه ...برمجة تم النشر بتاريخ 2024-11-07
-
كيفية إجراء مطابقة غامضة لعناوين البريد الإلكتروني وأرقام الهواتف باستخدام Elasticsearch؟مطابقة غامضة للبريد الإلكتروني أو الهاتف باستخدام Elasticsearch يوفر Elasticsearch إمكانات مدمجة للمطابقة الغامضة لعناوين البريد الإلكتروني وأرق...برمجة تم النشر بتاريخ 2024-11-07
-
خطواتك الأولى في عرض WebA البسيطWeb3 موجود بالتأكيد لتبقى. تنمو شبكات مثل Bitcoin وEthereum وSolana والعديد من الشبكات الأخرى بسرعة، إلى جانب جميع التطبيقات التي يتم إنشاؤها فوقها. إ...برمجة تم النشر بتاريخ 2024-11-07
-
عبارات التحكم في الحلقة في بايثون: استراحة، متابعة، تمريرفي بايثون، لدينا 3 عبارات للتحكم في الحلقة: Break، continue، pass. استراحة عندما يتحقق الشرط، تنكسر الحلقة وتخرج من الحلقة. for i in range...برمجة تم النشر بتاريخ 2024-11-07
-
كيفية تحديد تنسيق تسميات التجزئة لقيم الفاصلة العائمة في Matplotlib؟تنسيق تسميات التجزئة لقيم الفاصلة العائمة في matplotlib، يمكنك تحديد تنسيق تسميات التجزئة لقيم الفاصلة العائمة لعرض منازل عشرية محددة أو منع الع...برمجة تم النشر بتاريخ 2024-11-07
-
كيفية تخزين واسترجاع المصفوفات بكفاءة باستخدام PHP؟كيفية تخزين واسترجاع المصفوفات باستخدام PHP يمكن أن يكون تخزين واسترجاع المصفوفات في PHP مهمة شائعة لأغراض مختلفة. على الرغم من أنه قد لا تكون...برمجة تم النشر بتاريخ 2024-11-07
-
كيف يمكنني تحديد خاصية عشوائية من كائن JavaScript بإيجاز؟تحديد خاصية عشوائية من كائن JavaScript بإيجاز في JavaScript، الكائنات هي أزواج ذات قيمة أساسية مخزنة في جدول التجزئة. يتطلب استرداد خاصية معينة ...برمجة تم النشر بتاريخ 2024-11-07
-
لماذا يستخدم sync.Once atomic.StoreUint32 بدلاً من المهمة القياسية؟ترتيب الذاكرة الذرية بشكل متزامن. مرة واحدة أثناء استكشاف الكود المصدري للمزامنة. ذات مرة، عثرنا على السبب الكامن وراء استخدام الذري. StoreUin...برمجة تم النشر بتاريخ 2024-11-07
-
لماذا لا يمكنني تهيئة الخصائص ذات الوظائف المجهولة في PHP؟تهيئة الخاصية بوظائف مجهولة: لماذا وكيف؟ كما هو مذكور في مقتطف الكود أدناه، تهيئة خاصية بوظيفة مجهولة خلال يؤدي تعريف الفئة إلى ظهور "خطأ...برمجة تم النشر بتاريخ 2024-11-07
-
[فلاتيرون SE] اليوم 24مرحبًا بكم جميعًا، فيش هنا، ستكون هذه أول مشاركة لي على مدونتي على الإطلاق! أفعل هذا بناءً على طلب معلمتي الرائعة في مدرسة فلاتيرون. سأحاول إنشاء...برمجة تم النشر بتاريخ 2024-11-07














![[فلاتيرون SE] اليوم 24](http://www.luping.net/uploads/20240904/172541881066d7cd3a66437.jpg)
دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









