
بناء نظام بحث دلالي سريع وفعال باستخدام OpenVINO وPostgres
 تصفح:691
تصفح:691

الصورة التقطتها ريل نابستر على بيكساباي
في أحد مشاريعي الأخيرة، كان علي إنشاء نظام بحث دلالي يمكنه التوسع بأداء عالٍ وتقديم استجابات في الوقت الفعلي لعمليات البحث في التقارير. استخدمنا PostgreSQL مع pgvector على AWS RDS، مقترنًا بـ AWS Lambda، لتحقيق ذلك. كان التحدي يتمثل في السماح للمستخدمين بالبحث باستخدام استعلامات اللغة الطبيعية بدلاً من الاعتماد على الكلمات الرئيسية الصارمة، كل ذلك مع ضمان أن تكون الاستجابات أقل من ثانية أو ثانيتين أو حتى أقل ويمكنها فقط الاستفادة من موارد وحدة المعالجة المركزية.
في هذا المنشور، سأشرح الخطوات التي اتخذتها لبناء نظام البحث هذا، بدءًا من الاسترجاع وحتى إعادة الترتيب، والتحسينات التي تم إجراؤها باستخدام OpenVINO والدفعات الذكية للترميز.
نظرة عامة على البحث الدلالي: الاسترجاع وإعادة الترتيب
تتكون أنظمة البحث الحديثة عادةً من خطوتين رئيسيتين: الاسترجاع وإعادة الترتيب.
1) الاسترجاع: تتضمن الخطوة الأولى استرجاع مجموعة فرعية من المستندات ذات الصلة بناءً على استعلام المستخدم. يمكن القيام بذلك باستخدام نماذج التضمين المدربة مسبقًا، مثل عمليات التضمين الصغيرة والكبيرة في OpenAI، أو نماذج التضمين الخاصة بـ Cohere، أو عمليات التضمين mxbai الخاصة بـ Mixbread. يركز الاسترجاع على تضييق نطاق مجموعة المستندات عن طريق قياس مدى تشابهها مع الاستعلام.
إليك مثال مبسط باستخدام مكتبة Huggingface لتحويل الجمل للاسترجاع والتي تعد إحدى مكتباتي المفضلة لهذا:
from sentence_transformers import SentenceTransformer
import numpy as np
# Load a pre-trained sentence transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# Sample query and documents (vectorize the query and the documents)
query = "How do I fix a broken landing gear?"
documents = ["Report 1 on landing gear failure", "Report 2 on engine problems"]
# Get embeddings for query and documents
query_embedding = model.encode(query)
document_embeddings = model.encode(documents)
# Calculate cosine similarity between query and documents
similarities = np.dot(document_embeddings, query_embedding)
# Retrieve top-k most relevant documents
top_k = np.argsort(similarities)[-5:]
print("Top 5 documents:", [documents[i] for i in top_k])
2) إعادة الترتيب: بمجرد استرداد المستندات الأكثر صلة، نقوم بتحسين تصنيف هذه المستندات بشكل أكبر باستخدام نموذج التشفير المتقاطع. تعمل هذه الخطوة على إعادة تقييم كل مستند فيما يتعلق بالاستعلام بشكل أكثر دقة، مع التركيز على الفهم السياقي الأعمق.
تعد إعادة الترتيب مفيدة لأنها تضيف طبقة إضافية من التحسين من خلال تسجيل مدى ملاءمة كل مستند بشكل أكثر دقة.
إليك مثال رمزي لإعادة الترتيب باستخدام برنامج التشفير المتقاطع/ms-marco-TinyBERT-L-2-v2، وهو برنامج تشفير متقاطع خفيف الوزن:
from sentence_transformers import CrossEncoder
# Load the cross-encoder model
cross_encoder = CrossEncoder("cross-encoder/ms-marco-TinyBERT-L-2-v2")
# Use the cross-encoder to rerank top-k retrieved documents
query_document_pairs = [(query, doc) for doc in documents]
scores = cross_encoder.predict(query_document_pairs)
# Rank documents based on the new scores
top_k_reranked = np.argsort(scores)[-5:]
print("Top 5 reranked documents:", [documents[i] for i in top_k_reranked])
تحديد الاختناقات: تكلفة الترميز والتنبؤ
أثناء التطوير، وجدت أن مراحل الترميز والتنبؤ كانت تستغرق وقتًا طويلاً عند التعامل مع 1000 تقرير بالإعدادات الافتراضية لمحولات الجملة. وقد أدى ذلك إلى خلق اختناق في الأداء، خاصة وأننا كنا نهدف إلى الحصول على استجابات في الوقت الفعلي.
أدناه قمت بتوصيف الكود الخاص بي باستخدام SnakeViz لتصور العروض:
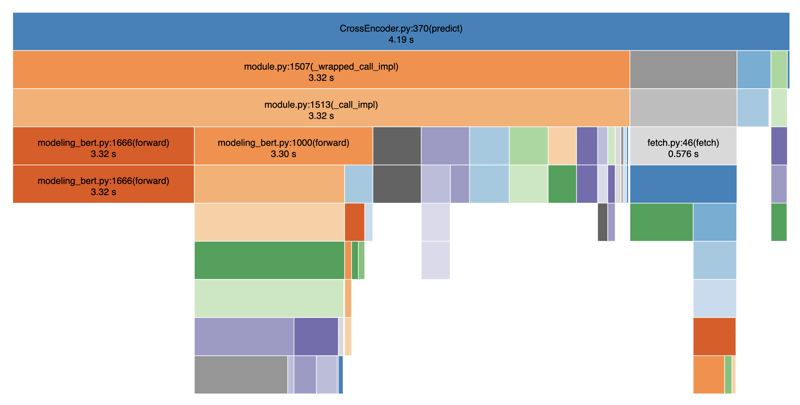
كما ترون، فإن خطوات الترميز والتنبؤ بطيئة بشكل غير متناسب، مما يؤدي إلى تأخيرات كبيرة في عرض نتائج البحث. بشكل عام، استغرق الأمر حوالي 4-5 ثوانٍ في المتوسط. ويرجع ذلك إلى حقيقة وجود عمليات حظر بين خطوات الترميز والتنبؤ. إذا أضفنا أيضًا عمليات أخرى مثل استدعاء قاعدة البيانات والتصفية وما إلى ذلك، فسننتهي بسهولة بإجمالي 8-9 ثوانٍ.
تحسين الأداء باستخدام OpenVINO
السؤال الذي واجهته كان: هل يمكننا جعل الأمر أسرع؟ الإجابة هي نعم، من خلال الاستفادة من OpenVINO، وهي واجهة خلفية محسنة لاستدلال وحدة المعالجة المركزية. يساعد OpenVINO في تسريع استنتاج نماذج التعلم العميق على أجهزة Intel، والتي نستخدمها في AWS Lambda.
مثال التعليمات البرمجية لتحسين OpenVINO
إليك كيفية دمج OpenVINO في نظام البحث لتسريع الاستدلال:
import argparse
import numpy as np
import pandas as pd
from typing import Any
from openvino.runtime import Core
from transformers import AutoTokenizer
def load_openvino_model(model_path: str) -> Core:
core = Core()
model = core.read_model(model_path ".xml")
compiled_model = core.compile_model(model, "CPU")
return compiled_model
def rerank(
compiled_model: Core,
query: str,
results: list[str],
tokenizer: AutoTokenizer,
batch_size: int,
) -> np.ndarray[np.float32, Any]:
max_length = 512
all_logits = []
# Split results into batches
for i in range(0, len(results), batch_size):
batch_results = results[i : i batch_size]
inputs = tokenizer(
[(query, item) for item in batch_results],
padding=True,
truncation="longest_first",
max_length=max_length,
return_tensors="np",
)
# Extract input tensors (convert to NumPy arrays)
input_ids = inputs["input_ids"].astype(np.int32)
attention_mask = inputs["attention_mask"].astype(np.int32)
token_type_ids = inputs.get("token_type_ids", np.zeros_like(input_ids)).astype(
np.int32
)
infer_request = compiled_model.create_infer_request()
output = infer_request.infer(
{
"input_ids": input_ids,
"attention_mask": attention_mask,
"token_type_ids": token_type_ids,
}
)
logits = output["logits"]
all_logits.append(logits)
all_logits = np.concatenate(all_logits, axis=0)
return all_logits
def fetch_search_data(search_text: str) -> pd.DataFrame:
# Usually you would fetch the data from a database
df = pd.read_csv("cnbc_headlines.csv")
df = df[~df["Headlines"].isnull()]
texts = df["Headlines"].tolist()
# Load the model and rerank
openvino_model = load_openvino_model("cross-encoder-openvino-model/model")
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-2-v2")
rerank_scores = rerank(openvino_model, search_text, texts, tokenizer, batch_size=16)
# Add the rerank scores to the DataFrame and sort by the new scores
df["rerank_score"] = rerank_scores
df = df.sort_values(by="rerank_score", ascending=False)
return df
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Fetch search results with reranking using OpenVINO"
)
parser.add_argument(
"--search_text",
type=str,
required=True,
help="The search text to use for reranking",
)
args = parser.parse_args()
df = fetch_search_data(args.search_text)
print(df)
مع هذا الأسلوب يمكننا الحصول على تسريع بمقدار 2-3x مما يقلل الوقت الأصلي من 4-5 ثوانٍ إلى 1-2 ثانية. كود العمل الكامل موجود على جيثب.
الضبط الدقيق للسرعة: حجم الدفعة والترميز
كان هناك عامل حاسم آخر في تحسين الأداء وهو تحسين عملية الترميز وضبط حجم الدفعة و طول الرمز المميز . من خلال زيادة حجم الدفعة (batch_size=16) وتقليل طول الرمز المميز (max_length=512)، يمكننا موازنة عملية الترميز وتقليل الحمل الزائد للعمليات المتكررة. في تجاربنا، وجدنا أن حجم الدُفعة الذي يتراوح بين 16 و64 يعمل بشكل جيد، مع أي شيء أكبر يؤدي إلى انخفاض الأداء. وبالمثل، فقد استقرنا على الحد الأقصى للطول وهو 128، وهو أمر قابل للتطبيق إذا كان متوسط طول تقاريرك قصيرًا نسبيًا. بفضل هذه التغييرات، حققنا سرعة إجمالية قدرها 8x، مما أدى إلى تقليل وقت إعادة الترتيب إلى أقل من ثانية واحدة، حتى على وحدة المعالجة المركزية.
من الناحية العملية، كان هذا يعني تجربة أحجام دفعات مختلفة وأطوال الرموز المميزة للعثور على التوازن الصحيح بين السرعة والدقة لبياناتك. ومن خلال القيام بذلك، شهدنا تحسينات كبيرة في أوقات الاستجابة، مما جعل نظام البحث قابلاً للتوسع حتى مع 1000 تقرير.
خاتمة
من خلال استخدام OpenVINO وتحسين الترميز والتجميع، تمكنا من إنشاء نظام بحث دلالي عالي الأداء يلبي متطلبات الوقت الفعلي على إعداد وحدة المعالجة المركزية فقط. في الواقع، لقد شهدنا تسريعًا إجماليًا بمقدار 8x. يؤدي الجمع بين الاسترجاع باستخدام محولات الجملة وإعادة الترتيب باستخدام نموذج التشفير المتقاطع إلى إنشاء تجربة بحث قوية وسهلة الاستخدام.
إذا كنت تقوم ببناء أنظمة مماثلة مع قيود على وقت الاستجابة والموارد الحسابية، فإنني أوصي بشدة باستكشاف OpenVINO والدفعات الذكية لإطلاق العنان لأداء أفضل.
نأمل أن تكون قد استمتعت بهذا المقال. إذا وجدت هذه المقالة مفيدة، أعطني إعجابًا حتى يتمكن الآخرون من العثور عليها أيضًا، وشاركها مع أصدقائك. تابعني على Linkedin لتبقى على اطلاع بأحدث أعمالي. شكرا على القراءة!
-
 كيفية الجمع بين البيانات من ثلاثة جداول MySQL في جدول جديد؟الأشخاص والتفاصيل وجداول التصنيف؟ الإجابة: حدد ص.*، د. من الناس ك انضم إلى التفاصيل كـ D على D.Person_id = p.id انضم إلى التصنيف كـ t على t....برمجة نشر في 2025-07-14
كيفية الجمع بين البيانات من ثلاثة جداول MySQL في جدول جديد؟الأشخاص والتفاصيل وجداول التصنيف؟ الإجابة: حدد ص.*، د. من الناس ك انضم إلى التفاصيل كـ D على D.Person_id = p.id انضم إلى التصنيف كـ t على t....برمجة نشر في 2025-07-14 -
دليل إنشاء صفحة Fastapi مخصص 404تعتمد الطريقة المناسبة على متطلباتك المحددة. call_next (طلب) إذا كان الاستجابة. status_code == 404: إرجاع RedirectResponse ("https://fasta...برمجة نشر في 2025-07-14
-
ابحث عن طريقة عنصر البرنامج النصي التي تنفذ حاليًا JavaScriptكيفية الرجوع إلى عنصر البرنامج النصي الذي قام بتحميل البرنامج النصي الذي تم تنفيذه حاليًا فهم المشكلة في سيناريوهات معينة ، قد يحتاج المطورون ...برمجة نشر في 2025-07-14
-
كيفية التغلب على قيود وظائف PHP \؟التغلب على قيود دالة PHP إن محاولة القيام بذلك ، كما هو موضح في مقتطف الرمز المقدم ، ستؤدي إلى خطأ "لا يمكن redeclare". $ b) { return ...برمجة نشر في 2025-07-14
-
كيف تسترجع أحدث مكتبة jQuery من Google APIs؟لاسترداد أحدث إصدار ، كان هناك سابقًا بديلًا لاستخدام رقم إصدار معين ، والذي كان لاستخدام بناء الجملة التالي: /latest/jquery.js Budaps &&. للحصول...برمجة نشر في 2025-07-14
-
كيف يمكنني اتحاد جداول قاعدة البيانات مع أرقام مختلفة من الأعمدة؟الجداول مجتمعة مع أعمدة مختلفة ] يمكن أن تواجه تحديات عند محاولة دمج جداول قاعدة البيانات بأعمدة مختلفة. تتمثل الطريقة المباشرة في إلحاق القيم ...برمجة نشر في 2025-07-14
-
كيفية تحويل عمود DataFrame Pandas إلى تنسيق DateTime وتصفية حسب التاريخ؟تحويل عمود DataFrame pandas إلى تنسيق DateTime عند العمل مع البيانات الزمنية ، قد تظهر الطوابع الزمنية في البداية كسلاسل ولكن يجب تحويلها إلى تنس...برمجة نشر في 2025-07-14
-
كيفية تحديد موقع صورة خلفية CSS من اليمين؟وضع صورة الخلفية من اليمين مع CSS في عالم تطوير الويب ، وغالبًا ما يكون من المستحسن وضع صور الخلفية بدقة داخل عناصر. على الرغم من أن وضع صور ا...برمجة نشر في 2025-07-14
-
لماذا يتوقف تنفيذ JavaScript عند استخدام زر عودة Firefox؟مشكلة السجل الملحي: قد يتوقف JavaScript عن التنفيذ بعد استخدام زر عودة Firefox قد يواجه مستخدمو Firefox مشكلة حيث فشل JavaScriptts في الركض عن...برمجة نشر في 2025-07-14
-
كيف يمكنني إنشاء قواميس بكفاءة باستخدام فهم Python؟على الرغم من أنها تشبه إلى حد كبير اختصارات القائمة ، إلا أن هناك بعض الاختلافات الملحوظة. يجب عليك تحديد المفاتيح والقيم بشكل صريح. على سبيل المثا...برمجة نشر في 2025-07-14
-
لماذا تتطلب تعبيرات Lambda متغيرات "نهائية" أو "نهائية صالحة" في جافا؟النهائي. في قصاصة الكود المقدمة: // الرمز المفقود cal.getcomponents (). getComponents ("VTimeZone"). // الرمز المفقود ...برمجة نشر في 2025-07-14
-
هل يمكن أن تعتمد معلمات القالب في وظيفة C ++ 20 الإضافية على معلمات الوظيفة؟compile-time. c 20 وظائف الإضافية ومع ذلك ، يبقى السؤال: هل هذا يعني أن معلمات القالب يمكن أن تعتمد الآن على وسيطات الوظائف؟ تقر الورقة بأن ...برمجة نشر في 2025-07-14
-
طرق الوصول والإدارة لمتغيرات بيئة بيثونالوصول إلى متغيرات البيئة في python بشكل افتراضي ، فإن الوصول إلى المتغير داخل رسم الخرائط يطالب بالمترجم المترجم للبحث في قاموس Python عن قيمته...برمجة نشر في 2025-07-14
-
لماذا تفشل Microsoft Visual C ++ في تنفيذ إنشاء مثيل للقالب ثنائي المراحل بشكل صحيح؟] ما هي الجوانب المحددة للآلية تفشل في العمل كما هو متوقع؟ ومع ذلك ، تنشأ الشكوك فيما يتعلق بما إذا كان هذا الشيك يتحقق مما إذا كان يتم الإعلان عن الأ...برمجة نشر في 2025-07-14
-
كيفية استخراج النص داخل الأقواس بكفاءة في PHP باستخدام regexأحد الأساليب هو استخدام وظائف معالجة سلسلة PHP ، كما هو موضح أدناه: $ fullString = "تجاهل كل شيء باستثناء هذا (النص)" ؛ ، $ fullstrin...برمجة نشر في 2025-07-14















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









