
أنشئ توصيات \"من أجلك\" باستخدام الذكاء الاصطناعي على Fastly!
 تصفح:284
تصفح:284
انسَ الضجيج؛ أين يقدم الذكاء الاصطناعي قيمة حقيقية؟ دعونا نستخدم الحوسبة المتطورة لتسخير قوة الذكاء الاصطناعي وتقديم تجارب مستخدم أكثر ذكاءً وسريعة وآمنة وموثوقة.
التوصيات موجودة في كل مكان، ويعلم الجميع أن جعل تجارب الويب أكثر تخصيصًا يجعلها أكثر جاذبية ونجاحًا. تعرف صفحتي الرئيسية على أمازون أنني أحب الأثاث المنزلي وأدوات المطبخ والآن الملابس الصيفية:
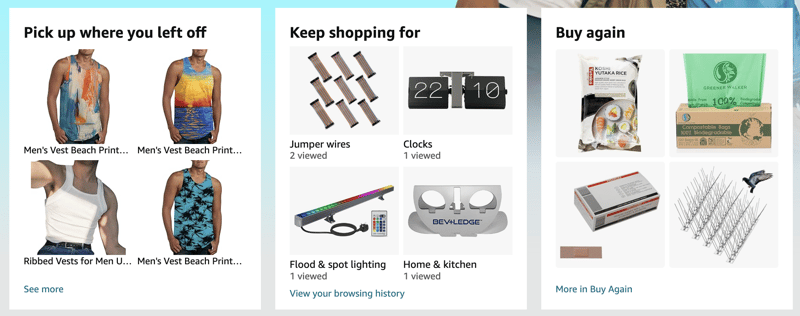
اليوم، تتيح لك معظم المنصات الاختيار بين أن تكون سريعًا أو أن تكون شخصيًا. في Fastly، نعتقد أنك - والمستخدمين لديك - تستحقون الحصول على كليهما. إذا كان خادم الويب الخاص بك ينشئ صفحة في كل مرة، فهي مناسبة لمستخدم نهائي واحد فقط، فلا يمكنك الاستفادة من تخزينها مؤقتًا، وهو ما تفعله شبكات الحافة مثل Fastly بشكل جيد.
إذًا كيف يمكنك الاستفادة من التخزين المؤقت على الحافة، مع جعل المحتوى مخصصًا في نفس الوقت؟ لقد كتبنا كثيرًا من قبل حول كيفية تقسيم طلبات العميل المعقدة إلى عدة طلبات خلفية أصغر حجمًا وقابلة للتخزين المؤقت، وستجد البرامج التعليمية وأمثلة التعليمات البرمجية والعروض التوضيحية في موضوع التخصيص في مركز المطورين الخاص بنا.
ولكن ماذا لو كنت تريد المضي قدمًا وإنشاء بيانات التخصيص على الحافة ؟ "الحافة" - خوادم Fastly التي تتعامل مع حركة مرور موقع الويب الخاص بك، هي أقرب نقطة إلى المستخدم النهائي والتي لا تزال تحت سيطرتك. مكان رائع لإنتاج محتوى خاص بمستخدم واحد.
حالة الاستخدام "من أجلك".
توصيات المنتج عابرة بطبيعتها، ومخصصة لمستخدم فردي ومن المحتمل أن تتغير بشكل متكرر. ولكنها أيضًا لا تحتاج إلى الاستمرار - فنحن لا نحتاج عادةً إلى معرفة ما أوصينا به لكل شخص، فقط ما إذا كانت خوارزمية معينة تحقق تحويلًا أفضل من خوارزمية أخرى. تحتاج بعض خوارزميات التوصية إلى الوصول إلى كمية كبيرة من بيانات الحالة، مثل أكثر المستخدمين تشابهًا معك وتاريخ الشراء أو التقييم، ولكن غالبًا ما يكون من السهل إنشاء هذه البيانات مسبقًا بكميات كبيرة.
في الأساس، عادةً لا يؤدي إنشاء التوصيات إلى إنشاء معاملة، ولا يحتاج إلى أي أقفال في مخزن البيانات الخاص بك، ويستفيد من بيانات الإدخال التي تكون إما متاحة على الفور من جلسة المستخدم الحالية، أو تم إنشاؤها في عملية إنشاء دون اتصال بالإنترنت.
يبدو أنه يمكننا إنشاء توصيات على الحافة!
مثال العالم الحقيقي
دعونا نلقي نظرة على الموقع الإلكتروني لمتحف متروبوليتان للفنون في نيويورك:
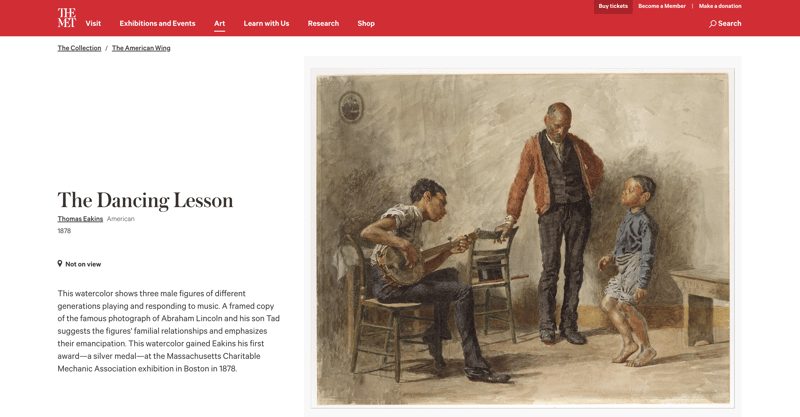
يحتوي كل عنصر من العناصر التي يبلغ عددها 500000 أو نحو ذلك في مجموعة Met على صفحة تحتوي على صورة ومعلومات عنها. كما أن لديها هذه القائمة من الكائنات ذات الصلة:
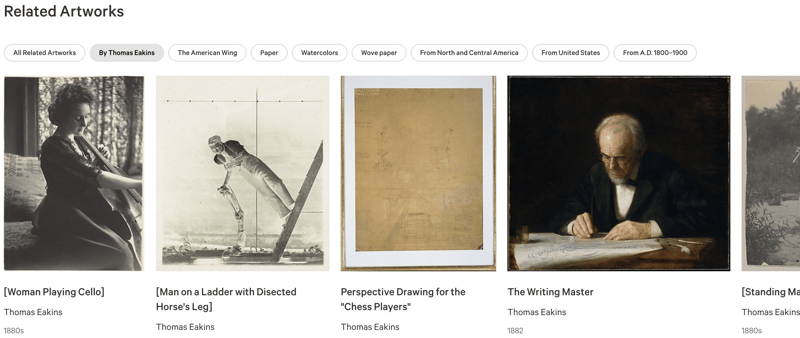
يبدو أن هذا يستخدم نظامًا مباشرًا إلى حد ما من الوجوه لإنشاء هذه العلاقات، ويظهر لي أعمالًا فنية أخرى لنفس الفنان، أو أشياء أخرى في نفس جناح المتحف، أو مصنوعة أيضًا من الورق أو تنشأ في نفس الجناح الفترة الزمنية.
الشيء الجميل في هذا النظام (من وجهة نظر المطور!) هو أنه نظرًا لأنه يعتمد فقط على كائن إدخال واحد، فيمكن إنشاؤه مسبقًا في الصفحة.
ماذا لو أردنا تعزيز ذلك بمجموعة مختارة من التوصيات التي تعتمد على سجل التصفح الشخصي للمستخدم النهائي أثناء تنقله عبر موقع Met، وليس فقط بناءً على هذا الكائن الواحد؟
إضافة توصيات شخصية
هناك العديد من الطرق التي يمكننا من خلالها القيام بذلك، لكنني أردت تجربة استخدام نموذج لغة، نظرًا لأن الذكاء الاصطناعي يحدث في الوقت الحالي، وهو مختلف حقًا عن الطريقة التي تبدو بها آلية الأعمال الفنية ذات الصلة الحالية في Met عمل. وإليكم الخطة:
- قم بتنزيل مجموعة بيانات الوصول المفتوح لمتحف Met.
- قم بتشغيله من خلال نموذج لغة لإنشاء عمليات تضمين متجهة - قوائم أرقام مناسبة لمهام التعلم الآلي.
- أنشئ محرك بحث تشابه الأداء للنصف مليون متجه الناتج (الذي يمثل الأعمال الفنية لمتحف Met) وقم بتحميله إلى متجر KV حتى نتمكن من استخدامه من Fastly Compute.
بمجرد القيام بكل ذلك، يجب أن نكون قادرين على القيام بذلك أثناء تصفحك لموقع Met:
- تتبع الأعمال الفنية التي تزورها في ملف تعريف الارتباط.
- ابحث عن المتجهات المقابلة لتلك الأعمال الفنية.
- احسب المتجه المتوسط الذي يمثل اهتماماتك في التصفح.
- أدخل ذلك في محرك بحث التشابه الخاص بنا للعثور على الأعمال الفنية الأكثر تشابهًا.
- قم بتحميل تفاصيل حول تلك الأعمال الفنية من Met's Object API وقم بزيادة الصفحة بتوصيات مخصصة.
وهذه توصيات مخصصة:

حسنًا، دعونا نقسم ذلك.
إنشاء مجموعة البيانات
مجموعة البيانات الأولية لمتحف Met هي ملف CSV يحتوي على الكثير من الأعمدة وتبدو كما يلي:
Object Number,Is Highlight,Is Timeline Work,Is Public Domain,Object ID,Gallery Number,Department,AccessionYear,Object Name,Title,Culture,Period,Dynasty,Reign,Portfolio,Constituent ID,Artist Role,Artist Prefix,Artist Display Name,Artist Display Bio,Artist Suffix,Artist Alpha Sort,Artist Nationality,Artist Begin Date,Artist End Date,Artist Gender,Artist ULAN URL,Artist Wikidata URL,Object Date,Object Begin Date,Object End Date,Medium,Dimensions,Credit Line,Geography Type,City,State,County,Country,Region,Subregion,Locale,Locus,Excavation,River,Classification,Rights and Reproduction,Link Resource,Object Wikidata URL,Metadata Date,Repository,Tags,Tags AAT URL,Tags Wikidata URL 1979.486.1,False,False,False,1,,The American Wing,1979,Coin,One-dollar Liberty Head Coin,,,,,,16429,Maker," ",James Barton Longacre,"American, Delaware County, Pennsylvania 1794–1869 Philadelphia, Pennsylvania"," ","Longacre, James Barton",American,1794 ,1869 ,,http://vocab.getty.edu/page/ulan/500011409,https://www.wikidata.org/wiki/Q3806459,1853,1853,1853,Gold,Dimensions unavailable,"Gift of Heinz L. Stoppelmann, 1979",,,,,,,,,,,,,,http://www.metmuseum.org/art/collection/search/1,,,"Metropolitan Museum of Art, New York, NY",,, 1980.264.5,False,False,False,2,,The American Wing,1980,Coin,Ten-dollar Liberty Head Coin,,,,,,107,Maker," ",Christian Gobrecht,1785–1844," ","Gobrecht, Christian",American,1785 ,1844 ,,http://vocab.getty.edu/page/ulan/500077295,https://www.wikidata.org/wiki/Q5109648,1901,1901,1901,Gold,Dimensions unavailable,"Gift of Heinz L. Stoppelmann, 1980",,,,,,,,,,,,,,http://www.metmuseum.org/art/collection/search/2,,,"Metropolitan Museum of Art, New York, NY",,,
بسيط بما يكفي لتحويل ذلك إلى عمودين ومعرف وسلسلة:
id,description 1,"One-dollar Liberty Head Coin; Type: Coin; Artist: James Barton Longacre; Medium: Gold; Date: 1853; Credit: Gift of Heinz L. Stoppelmann, 1979" 2,"Ten-dollar Liberty Head Coin; Type: Coin; Artist: Christian Gobrecht; Medium: Gold; Date: 1901; Credit: Gift of Heinz L. Stoppelmann, 1980" 3,"Two-and-a-Half Dollar Coin; Type: Coin; Medium: Gold; Date: 1927; Credit: Gift of C. Ruxton Love Jr., 1967"
الآن يمكننا استخدام حزمة المحولات من مجموعة أدوات Hugging Face AI، وإنشاء تضمينات لكل من هذه الأوصاف. استخدمنا نموذج محولات الجملة/جميع MiniLM-L12-v2، واستخدمنا تحليل المكون الرئيسي (PCA) لتقليل المتجهات الناتجة إلى 5 أبعاد. يمنحك ذلك شيئًا مثل:
[
{
"id": 1,
"vector": [ -0.005544120445847511, -0.030924081802368164, 0.008597176522016525, 0.20186401903629303, 0.0578165128827095 ]
},
{
"id": 2,
"vector": [ -0.005544120445847511, -0.030924081802368164, 0.008597176522016525, 0.20186401903629303, 0.0578165128827095 ]
},
…
]
لدينا نصف مليون منها، لذلك ليس من الممكن تخزين مجموعة البيانات بأكملها داخل ذاكرة تطبيق Edge. ونريد إجراء نوع مخصص من بحث التشابه عبر هذه البيانات، وهو أمر لا يقدمه متجر القيمة الرئيسية التقليدي. نظرًا لأننا نبني تجربة في الوقت الفعلي، فإننا نريد أيضًا تجنب الاضطرار إلى البحث في نصف مليون متجه في المرة الواحدة.
لذا، دعونا نقسم البيانات. يمكننا استخدام تجميع KMeans لتجميع المتجهات المتشابهة مع بعضها البعض. قمنا بتقسيم البيانات إلى 500 مجموعة ذات أحجام مختلفة، وحسبنا نقطة مركزية تسمى "ناقل النقطه الوسطى" لكل مجموعة من تلك المجموعات. إذا قمت برسم هذه المساحة المتجهة في بعدين وقمت بتكبيرها، فقد تبدو كما يلي:
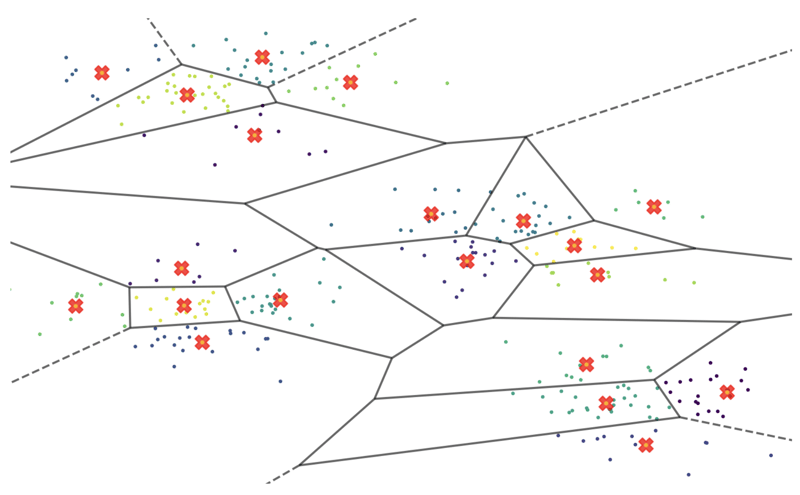
الصلبان الحمراء هي النقاط المركزية الرياضية لكل مجموعة من المتجهات، تسمى النقط الوسطى. يمكنهم العمل مثل مستكشفي الطرق لمساحتنا التي تحتوي على نصف مليون ناقل. على سبيل المثال، إذا أردنا العثور على المتجهات العشرة الأكثر تشابهًا مع متجه معين A، فيمكننا أولاً البحث عن أقرب النقطه الوسطى (من أصل 500)، ثم إجراء بحثنا فقط داخل مجموعتها المقابلة - وهي منطقة أكثر قابلية للإدارة!
لدينا الآن 500 مجموعة بيانات صغيرة وفهرس يعين نقاط النقطه الوسطى لمجموعة البيانات ذات الصلة. بعد ذلك، لتمكين الأداء في الوقت الفعلي، نريد تجميع الرسوم البيانية للبحث مسبقًا بحيث لا نحتاج إلى تهيئتها وإنشائها في وقت التشغيل، ويمكننا استخدام أقل قدر ممكن من وقت وحدة المعالجة المركزية. خوارزمية الجار الأقرب السريعة حقًا هي Hierarchical Navigable Small Worlds (HNSW)، ولها تطبيق Rust خالص، والذي نستخدمه لكتابة تطبيق Edge الخاص بنا. لذلك قمنا بكتابة تطبيق Rust مستقل صغير لإنشاء بنيات الرسم البياني HNSW لكل مجموعة بيانات، ثم استخدمنا bincode لتصدير ذاكرة البنية التي تم إنشاء مثيل لها إلى فقاعة ثنائية.
الآن، يمكن تحميل تلك النقط الثنائية في متجر KV، وربطها بفهرس المجموعة، ويمكن تضمين فهرس المجموعة في تطبيق Edge الخاص بنا.
تتيح لنا هذه البنية تحميل أجزاء من فهرس البحث إلى الذاكرة عند الطلب. وبما أننا لن نضطر مطلقًا إلى البحث في أكثر من بضعة آلاف من المتجهات في المرة الواحدة، فستكون عمليات البحث لدينا دائمًا رخيصة وسريعة.
بناء تطبيق الحافة
يحتاج التطبيق الذي نقوم بتشغيله على الحافة إلى التعامل مع عدة أنواع من الطلبات:
- صفحات HTML: نجلبها من metmuseum.org ونحول الاستجابة لإضافة علامات
- موارد النص والنمط Fastly المشار إليها بواسطة تلك العلامات الإضافية، والتي يمكننا تقديمها مباشرة من الثنائي لتطبيق Edge.
- نقطة نهاية الموصي، التي تقوم بإنشاء التوصيات وإرجاعها ** جميع الطلبات الأخرى (غير HTML): الصور، والنصوص البرمجية وأوراق الأنماط الخاصة بـ Met، والتي نوكلها مباشرة من المجال الخاص بهم دون تغيير.
لقد أنشأنا هذا التطبيق في البداية بلغة JavaScript، ولكن انتهى بنا الأمر بنقل الجزء الموصى به إلى Rust لأننا أحببنا تنفيذ HNSW على مسافة فورية.
يقوم جافا سكريبت من جانب العميل ببعض الأشياء المثيرة للاهتمام:
- باستخدام IntersectionObserver، نقوم بتشغيل حدث عندما يقوم المستخدم بالتمرير لأسفل الصفحة إلى قسم الكائنات ذات الصلة. إنها واجهة برمجة تطبيقات فائقة الكفاءة وأفضل بكثير من استخدام الأساليب القديمة مثل onscroll.
- قم بإجراء جلب إلى نقطة نهاية واجهة برمجة التطبيقات الخاصة بالتوصيات الخاصة بنا (والتي يمكننا بعد ذلك التعامل معها على الحافة وإرجاع معلومات الكائن)
- إنشاء بعض HTML باستخدام قالب مدمج في وظيفة من جانب العميل
- قم بإلحاق HTML بالصفحة وانقل مراقب التقاطع إلى العنصر الجديد بحيث نستمر في تحميل المزيد أثناء التمرير خلال التوصيات.
بهذه الطريقة، يمكننا تسليم حمولة HTML الرئيسية دون استدعاء خوارزمية التوصيات الخاصة بنا، ولكن يتم تسليم التوصيات بسرعة كافية حتى نتمكن من تحميلها أثناء التمرير ومن المؤكد تقريبًا أنها ستكون هناك بحلول الوقت الذي تصل إليه.
أحب القيام بالأشياء بهذه الطريقة لأن الحصول على العرض الأول في الجزء العلوي من الصفحة للمستخدم في أسرع وقت ممكن هو أمر بالغ الأهمية تمامًا. أي شيء لا يمكنك رؤيته إلا إذا قمت بالتمرير، يمكن تحميله لاحقًا، وخاصة إذا كان جزءًا معقدًا من المحتوى المخصص - فلا فائدة من إنشائه إذا لم يكن المستخدم يخطط للتمرير.
إغلاق الأفكار
إذن لديك الآن أفضل ما في كلا العالمين: القدرة على تقديم محتوى مخصص للغاية، تقريبًا لا يتطلب أي عمليات جلب للحظر إلى الأصل، وحمولة HTML محسّنة يتم عرضها بسرعة لا تصدق، مما يسمح لتطبيقك بالاستمتاع بفعالية بقابلية التوسع غير المحدودة وقريبة مرونة مثالية.
إنه ليس الحل الأمثل. سيكون أمرًا رائعًا لو قدمت Fastly المزيد من الميزات ذات المستوى الأعلى لكشف بيانات الحافة عبر آليات استعلام بخلاف البحث البسيط عن المفاتيح (أخبرنا إذا كان ذلك سيساعدك!) وهذه الآلية المحددة بها عيوب واضحة - إذا كان لدي اهتمامات منفصلة بها شيئين أو أكثر مختلفين تمامًا (على سبيل المثال اللوحات الزيتية في القرن التاسع عشر والأمفورا الرومانية القديمة) سأحصل على توصيات من شأنها أن تكون "النقطة الوسطى" الدلالية النظرية بين تلك، وليست نتيجة مفيدة جدًا.
ومع ذلك، نأمل أن يوضح هذا المبدأ القائل بأن معرفة كيفية القيام بالعمل على الحافة غالبًا ما يؤدي إلى فوائد كبيرة من حيث قابلية التوسع والأداء والمرونة.
أخبرنا بما تقوم ببنائه على موقع Community.fastly.com!
-
 ما هي الطريقة الأكثر كفاءة للكشف عن نقطة في polygon: تتبع الأشعة أو matplotlib \'s path.contains_points؟الكشف الفعال في polegon في python تحديد ما إذا كانت النقطة تكمن في مضلع هي مهمة متكررة في الهندسة الحسابية. يعد إيجاد طريقة فعالة لهذه المهمة مف...برمجة نشر في 2025-03-12
ما هي الطريقة الأكثر كفاءة للكشف عن نقطة في polygon: تتبع الأشعة أو matplotlib \'s path.contains_points؟الكشف الفعال في polegon في python تحديد ما إذا كانت النقطة تكمن في مضلع هي مهمة متكررة في الهندسة الحسابية. يعد إيجاد طريقة فعالة لهذه المهمة مف...برمجة نشر في 2025-03-12 -
VS Code & Delve Debug Go Code: دليل تكوين العلامات، قم بالتصحيح مع علامات في رمز الاستوديو المرئي و DEREVE DEBUGGER عند الاستفادة العلامات: لتحديد علامات الإنشاء داخل تكوين التشغيل للمكون الإ...برمجة نشر في 2025-03-12
-
كيفية تعيين مفاتيح ديناميكي في كائنات JavaScript؟كيفية إنشاء مفتاح ديناميكي لمتغير كائن JavaScript يستخدم النهج الصحيح بين قوسين مربعين: jsObj['key' i] = 'example' 1; لتسديد خاصية مع مفتاح...برمجة نشر في 2025-03-12
-
لماذا لا يوجد طلب آخر لالتقاط المدخلات في PHP على الرغم من الرمز الصحيح؟معالجة عطل طلب النشر في php $ _server ['php_self'] ؛؟> "method =" post "> ومع ذلك ، يظل الناتج فارغًا. على الرغم من ...برمجة نشر في 2025-03-12
-
لماذا لا يعرض Firefox صورًا باستخدام خاصية CSS `content`؟يمكن ملاحظة ذلك في فئة CSS المقدمة: . Googlepic { المحتوى: url ('../../ img/googleplusicon.png') ؛ الهامش: -6.5 ٪ ؛ حشو اليمين...برمجة نشر في 2025-03-12
-
\ "بينما (1) مقابل (؛؛): هل يزيل التحسين المترجم اختلافات الأداء؟ \"بينما (1) مقابل (؛؛): هل هناك فرق السرعة؟ حلقات؟ الإجابة: المجمعات: بيرل: 1 أدخل -> 2 2 NextState (Main 2 -e: 1) V -> 3 9 LEAVELOOP VK/2...برمجة نشر في 2025-03-12
-
لارافيل للذهاب: رحلتي وإنشاء غلاية ألياف أليافبعد قضاء أكثر من أربع سنوات منغمس في لارافيل ، أصبحت على دراية كبيرة بالهندسة المعمارية MVC (عرض الطراز-View-Controller). إن بساطتها وهيكلها تجعل ...برمجة نشر في 2025-03-12
-
كيفية حل تباينات مسار الوحدة في GO Mod باستخدام توجيه استبدال؟يمكن أن يؤدي ذلك إلى فشل GO MOD TIDY ، كما يتضح من الرسائل المرددة: ` github.com/coreos/etcd/client تم اختبارها بواسطة استيرادات github.com/co...برمجة نشر في 2025-03-12
-
كيفية استرداد الصف الأخير بكفاءة لكل معرف فريد في postgresql؟postgresql: استخراج الصف الأخير لكل معرف فريد في postgresql ، قد تواجه مواقف حيث تحتاج إلى استخراج المعلومات من الصف الأخير المرتبط بكل معرف م...برمجة نشر في 2025-03-12
-
كائن مناسب: فشل الغطاء في IE و Edge ، كيفية إصلاح؟في CSS للحفاظ على ارتفاع الصور المتسق يعمل بسلاسة عبر المتصفحات. ومع ذلك ، في IE و Edge ، تنشأ قضية غريبة. عند توسيع نطاق المتصفح ، تتغير الصورة في...برمجة نشر في 2025-03-12
-
كيف يمكنك استخراج عنصر عشوائي من صفيف في PHP؟اختيار عشوائي من صفيف في PHP ، يمكن تحقيق عنصر عشوائي من صفيف بسهولة. ضع في اعتبارك المصفوفة التالية: $items = [523, 3452, 334, 31, 5346];برمجة نشر في 2025-03-12
-
هل هناك اختلاف في الأداء بين استخدام حلقة EACH وتكرار لجمع اجتماعي في Java؟تستكشف هذه المقالة اختلافات الكفاءة بين هذين النهجين. يستخدم ITerator داخليًا: قائمة a = new ArrayList () ؛ ل (عدد صحيح عدد صحيح: أ) { intege...برمجة نشر في 2025-03-12
-
كيف يمكنني التعامل مع عمليات تحميل ملفات متعددة باستخدام FormData ()؟معالجة تحميلات متعددة مع تحميلات مع FormData () عند العمل مع مدخلات الملفات ، فغالبًا ما يكون من الضروري التعامل مع تحميلات الملفات المتعددة. ...برمجة نشر في 2025-03-12
-
كيفية إزالة الرموز التعبيرية من الأوتار في بيثون: دليل المبتدئين لتثبيت الأخطاء الشائعة؟إزالة الرموز التعبيرية من سلاسل في python يجب تعيين سلاسل Unicode باستخدام بادئة U '' على Python 2. بالإضافة إلى ذلك ، يجب تمرير علامة ...برمجة نشر في 2025-03-12
-
هل يمكنني ترحيل التشفير الخاص بي من Mcrypt إلى OpenSSL ، وفك تشفير البيانات المشفرة Mcrypt باستخدام OpenSSL؟ترقية مكتبة التشفير الخاصة بي من mcrypt إلى openssl هل يمكنني ترقية مكتبة التشفير الخاصة بي من mcrypt إلى openssl؟ في OpenSSL ، هل من الممكن ف...برمجة نشر في 2025-03-12















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









