
构建常规等变 CNN 的原则
 浏览:892
浏览:892
The one principle is simply stated as 'Let the kernel rotate' and we will focus in this article on how you can apply it in your architectures.
Equivariant architectures allow us to train models which are indifferent to certain group actions.
To understand what this exactly means, let us train this simple CNN model on the MNIST dataset (a dataset of handwritten digits from 0-9).
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.cl1 = nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, padding=1)
self.max_1 = nn.MaxPool2d(kernel_size=2)
self.cl2 = nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, padding=1)
self.max_2 = nn.MaxPool2d(kernel_size=2)
self.cl3 = nn.Conv2d(in_channels=16, out_channels=16, kernel_size=7)
self.dense = nn.Linear(in_features=16, out_features=10)
def forward(self, x: torch.Tensor):
x = nn.functional.silu(self.cl1(x))
x = self.max_1(x)
x = nn.functional.silu(self.cl2(x))
x = self.max_2(x)
x = nn.functional.silu(self.cl3(x))
x = x.view(len(x), -1)
logits = self.dense(x)
return logits
| Accuracy on test | Accuracy on 90-degree rotated test |
|---|---|
| 97.3% | 15.1% |
Table 1: Test accuracy of the SimpleCNN model
As expected, we get over 95% accuracy on the testing dataset, but what if we rotate the image by 90 degrees? Without any countermeasures applied, the results drop to just slightly better than guessing. This model would be useless for general applications.
In contrast, let us train a similar equivariant architecture with the same number of parameters, where the group actions are exactly the 90-degree rotations.
| Accuracy on test | Accuracy on 90-degree rotated test |
|---|---|
| 96.5% | 96.5% |
Table 2: Test accuracy of the EqCNN model with the same amount of parameters as the SimpleCNN model
The accuracy remains the same, and we did not even opt for data augmentation.
These models become even more impressive with 3D data, but we will stick with this example to explore the core idea.
In case you want to test it out for yourself, you can access all code written in both PyTorch and JAX for free under Github-Repo, and training with Docker or Podman is possible with just two commands.
Have fun!
So What is Equivariance?
Equivariant architectures guarantee stability of features under certain group actions. Groups are simple structures where group elements can be combined, reversed, or do nothing.
You can look up the formal definition on Wikipedia if you are interested.
For our purposes, you can think of a group of 90-degree rotations acting on square images. We can rotate an image by 90, 180, 270, or 360 degrees. To reverse the action, we apply a 270, 180, 90, or 0-degree rotation respectively. It is straightforward to see that we can combine, reverse, or do nothing with the group denoted as C4 . The image visualizes all actions on an image.
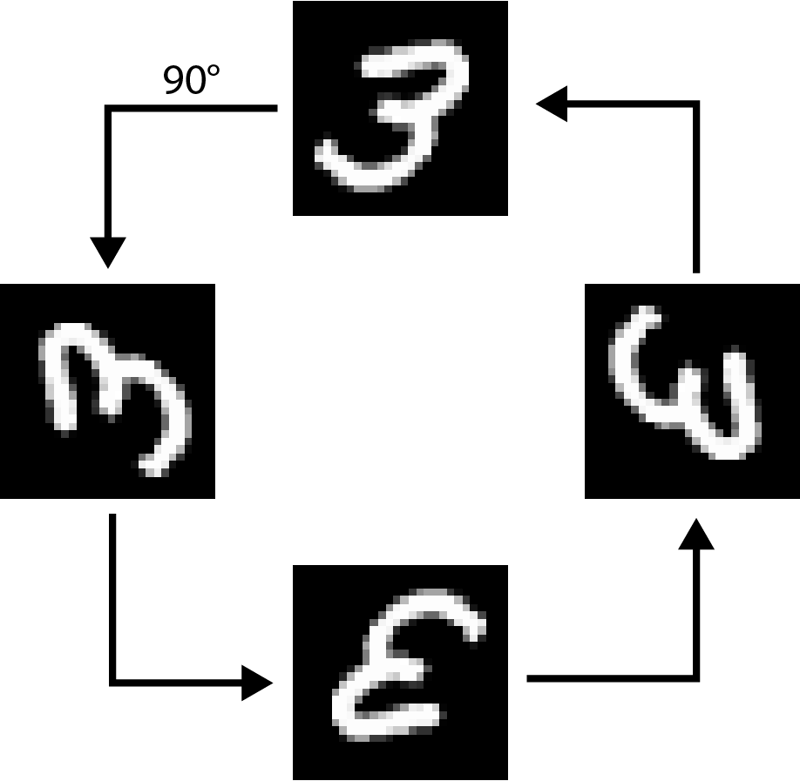
Figure 1: Rotated MNIST image by 90°, 180°, 270°, 360°, respectively
Now, given an input image
x
, our CNN model classifier
fθ
, and an arbitrary 90-degree rotation
g
, the equivariant property can be expressed as
fθ(rotate x by g)=fθ(x)
Generally speaking, we want our image-based model to have the same outputs when rotated.
As such, equivariant models promise us architectures with baked-in symmetries. In the following section, we will see how our principle can be applied to achieve this property.
How to Make Our CNN Equivariant
The problem is the following: When the image rotates, the features rotate too. But as already hinted, we could also compute the features for each rotation upfront by rotating the kernel.
We could actually rotate the kernel, but it is much easier to rotate the feature map itself, thus avoiding interference with PyTorch's autodifferentiation algorithm altogether.
So, in code, our CNN kernel
x = nn.functional.silu(self.cl1(x))
now acts on all four rotated images:
x_0 = x x_90 = torch.rot90(x, k=1, dims=(2, 3)) x_180 = torch.rot90(x, k=2, dims=(2, 3)) x_270 = torch.rot90(x, k=3, dims=(2, 3)) x_0 = nn.functional.silu(self.cl1(x_0)) x_90 = nn.functional.silu(self.cl1(x_90)) x_180 = nn.functional.silu(self.cl1(x_180)) x_270 = nn.functional.silu(self.cl1(x_270))
Or more compactly written as a 3D convolution:
self.cl1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(1, 3, 3)) ... x = torch.stack([x_0, x_90, x_180, x_270], dim=-3) x = nn.functional.silu(self.cl1(x))
The resulting equivariant model has just a few lines more compared to the version above:
class EqCNN(nn.Module):
def __init__(self):
super(EqCNN, self).__init__()
self.cl1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(1, 3, 3))
self.max_1 = nn.MaxPool3d(kernel_size=(1, 2, 2))
self.cl2 = nn.Conv3d(in_channels=8, out_channels=16, kernel_size=(1, 3, 3))
self.max_2 = nn.MaxPool3d(kernel_size=(1, 2, 2))
self.cl3 = nn.Conv3d(in_channels=16, out_channels=16, kernel_size=(1, 5, 5))
self.dense = nn.Linear(in_features=16, out_features=10)
def forward(self, x: torch.Tensor):
x_0 = x
x_90 = torch.rot90(x, k=1, dims=(2, 3))
x_180 = torch.rot90(x, k=2, dims=(2, 3))
x_270 = torch.rot90(x, k=3, dims=(2, 3))
x = torch.stack([x_0, x_90, x_180, x_270], dim=-3)
x = nn.functional.silu(self.cl1(x))
x = self.max_1(x)
x = nn.functional.silu(self.cl2(x))
x = self.max_2(x)
x = nn.functional.silu(self.cl3(x))
x = x.squeeze()
x = torch.max(x, dim=-1).values
logits = self.dense(x)
return logits
But why is this equivariant to rotations?
First, observe that we get four copies of each feature map at each stage. At the end of the pipeline, we combine all of them with a max operation.
This is key, the max operation is indifferent to which place the rotated version of the feature ends up in.
To understand what is happening, let us plot the feature maps after the first convolution stage.
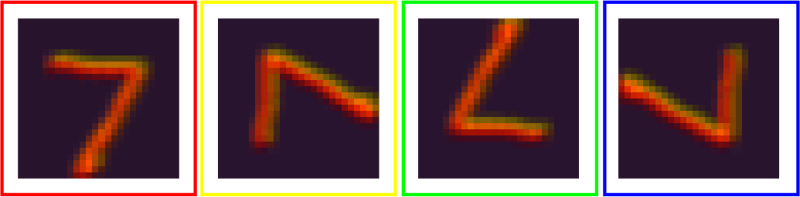
Figure 2: Feature maps for all four rotations
And now the same features after we rotate the input by 90 degrees.
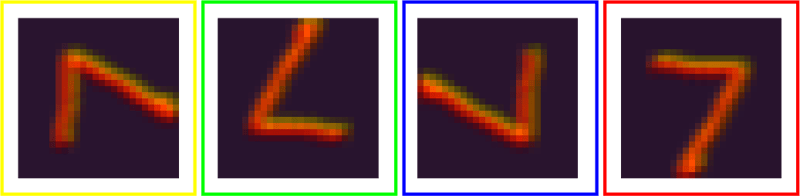
Figure 3: Feature maps for all four rotations after the input image was rotated
I color-coded the corresponding maps. Each feature map is shifted by one. As the final max operator computes the same result for these shifted feature maps, we obtain the same results.
In my code, I did not rotate back after the final convolution, since my kernels condense the image to a one-dimensional array. If you want to expand on this example, you would need to account for this fact.
Accounting for group actions or "kernel rotations" plays a vital role in the design of more sophisticated architectures.
Is it a Free Lunch?
No, we pay in computational speed, inductive bias, and a more complex implementation.
The latter point is somewhat solved with libraries such as E3NN, where most of the heavy math is abstracted away. Nevertheless, one needs to account for a lot during architecture design.
One superficial weakness is the 4x computational cost for computing all rotated feature layers. However, modern hardware with mass parallelization can easily counteract this load. In contrast, training a simple CNN with data augmentation would easily exceed 10x in training time. This gets even worse for 3D rotations where data augmentation would require about 500x the training amount to compensate for all possible rotations.
Overall, equivariance model design is more often than not a price worth paying if one wants stable features.
What is Next?
Equivariant model designs have exploded in recent years, and in this article, we barely scratched the surface. In fact, we did not even exploit the full C4 group yet. We could have used full 3D kernels. However, our model already achieves over 95% accuracy, so there is little reason to go further with this example.
Besides CNNs, researchers have successfully translated these principles to continuous groups, including SO(2) (the group of all rotations in the plane) and SE(3) (the group of all translations and rotations in 3D space).
In my experience, these models are absolutely mind-blowing and achieve performance, when trained from scratch, comparable to the performance of foundation models trained on multiple times larger datasets.
Let me know if you want me to write more on this topic.
Further References
In case you want a formal introduction to this topic, here is an excellent compilation of papers, covering the complete history of equivariance in Machine Learning.
AEN
I actually plan to create a deep-dive, hands-on tutorial on this topic. You can already sign up for my mailing list, and I will provide you with free versions over time, along with a direct channel for feedback and Q&A.
See you around :)
-
 如何使用Python有效地以相反顺序读取大型文件?在python 中,如果您使用一个大文件,并且需要从最后一行读取其内容,则在第一行到第一行,Python的内置功能可能不合适。这是解决此任务的有效解决方案:反向行读取器生成器 == ord('\ n'): 缓冲区=缓冲区[:-1] ...编程 发布于2025-03-28
如何使用Python有效地以相反顺序读取大型文件?在python 中,如果您使用一个大文件,并且需要从最后一行读取其内容,则在第一行到第一行,Python的内置功能可能不合适。这是解决此任务的有效解决方案:反向行读取器生成器 == ord('\ n'): 缓冲区=缓冲区[:-1] ...编程 发布于2025-03-28 -
为什么使用Firefox后退按钮时JavaScript执行停止?导航历史记录问题:JavaScript使用Firefox Back Back 此行为是由浏览器缓存JavaScript资源引起的。要解决此问题并确保在后续页面访问中执行脚本,Firefox用户应设置一个空功能。 警报'); }; alert('inline Alert')...编程 发布于2025-03-28
-
如何将来自三个MySQL表的数据组合到新表中?mysql:从三个表和列的新表创建新表 答案:为了实现这一目标,您可以利用一个3-way Join。 选择p。*,d.content作为年龄 来自人为p的人 加入d.person_id = p.id上的d的详细信息 加入T.Id = d.detail_id的分类法 其中t.taxonomy =...编程 发布于2025-03-28
-
为什么不````''{margin:0; }`始终删除CSS中的最高边距?在CSS 问题:不正确的代码: 全球范围将所有余量重置为零,如提供的代码所建议的,可能会导致意外的副作用。解决特定的保证金问题是更建议的。 例如,在提供的示例中,将以下代码添加到CSS中,将解决余量问题: body H1 { 保证金顶:-40px; } 此方法更精确,避免了由全局保证金重置引...编程 发布于2025-03-28
-
如何使用node-mysql在单个查询中执行多个SQL语句?Multi-Statement Query Support in Node-MySQLIn Node.js, the question arises when executing multiple SQL statements in a single query using the node-mys...编程 发布于2025-03-28
-
如何使用PHP从XML文件中有效地检索属性值?从php $xml = simplexml_load_file($file); foreach ($xml->Var[0]->attributes() as $attributeName => $attributeValue) { echo $attributeName,...编程 发布于2025-03-28
-
如何在Java中执行命令提示命令,包括目录更改,包括目录更改?在java 通过Java通过Java运行命令命令可能很具有挑战性。尽管您可能会找到打开命令提示符的代码段,但他们通常缺乏更改目录并执行其他命令的能力。 solution:使用Java使用Java,使用processBuilder。这种方法允许您:启动一个过程,然后将其标准错误重定向到其标准输出。...编程 发布于2025-03-28
-
如何解决由于Android的内容安全策略而拒绝加载脚本... \”错误?Unveiling the Mystery: Content Security Policy Directive ErrorsEncountering the enigmatic error "Refused to load the script..." when deployi...编程 发布于2025-03-28
-
在程序退出之前,我需要在C ++中明确删除堆的堆分配吗?在C中的显式删除 在C中的动态内存分配时,开发人员通常会想知道是否有必要在heap-procal extrable exit exit上进行手动调用“ delete”操作员,但开发人员通常会想知道是否需要手动调用“ delete”操作员。本文深入研究了这个主题。 在C主函数中,使用了动态分配变量(H...编程 发布于2025-03-28
-
如何在全高布局中有效地将Flexbox和垂直滚动结合在一起?在全高布局中集成flexbox和垂直滚动传统flexbox方法(旧属性)使用新的FlexBox properties 试图将全新的FlexBox属性应用于全高和可滚动的设计引入限制。使用高度的解决方法:0px; on a wrapper element is unreliable and crea...编程 发布于2025-03-28
-
如何有效地转换PHP中的时区?在PHP 利用dateTime对象和functions DateTime对象及其相应的功能别名为时区转换提供方便的方法。例如: //定义用户的时区 date_default_timezone_set('欧洲/伦敦'); //创建DateTime对象 $ dateTime = ne...编程 发布于2025-03-28
-
为什么我在Silverlight Linq查询中获得“无法找到查询模式的实现”错误?查询模式实现缺失:解决“无法找到”错误在Silverlight应用程序中,尝试使用LINQ建立LINQ连接以错误而实现的数据库”,无法找到查询模式的实现。”当省略LINQ名称空间或查询类型缺少IEnumerable 实现时,通常会发生此错误。 解决问题来验证该类型的质量是至关重要的。在此特定实例中...编程 发布于2025-03-28
-
如何从Python中的字符串中删除表情符号:固定常见错误的初学者指南?从python import codecs import codecs import codecs 导入 text = codecs.decode('这狗\ u0001f602'.encode('utf-8'),'utf-8') 印刷(文字)#带有...编程 发布于2025-03-28
-
可以在纯CS中将多个粘性元素彼此堆叠在一起吗?[2这里: https://webthemez.com/demo/sticky-multi-header-scroll/index.html </main> <section> { display:grid; grid-template-...编程 发布于2025-03-28















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









