
优化网页抓取:使用 JSDOM 抓取身份验证数据
 浏览:545
浏览:545
作为抓取开发人员,我们有时需要提取临时密钥等身份验证数据来执行我们的任务。然而,事情并没有那么简单。通常,它位于 HTML 或 XHR 网络请求中,但有时,会计算身份验证数据。在这种情况下,我们可以对计算进行逆向工程,这需要花费大量时间来对脚本进行反混淆,或者运行计算它的 JavaScript。通常,我们使用浏览器,但这很昂贵。 Crawlee 支持并行运行浏览器抓取工具和 Cheerio Scraper,但这在计算资源使用方面非常复杂且昂贵。 JSDOM 帮助我们以比浏览器更少的资源运行页面 JavaScript,并且比 Cheerio 略高。
本文将讨论一种新方法,我们在一个 Actor 中使用该方法,从浏览器 Web 应用程序生成的 TikTok 广告创意中心获取身份验证数据,而无需实际运行浏览器,而是使用 JSDOM。
分析网站
当您访问此网址时:
https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pc/en
您将看到主题标签列表,其中包含其实时排名、帖子数量、趋势图、创建者和分析。您还可以注意到,我们可以筛选行业、设置时间段,并使用复选框来筛选趋势是否新进入前 100 名。
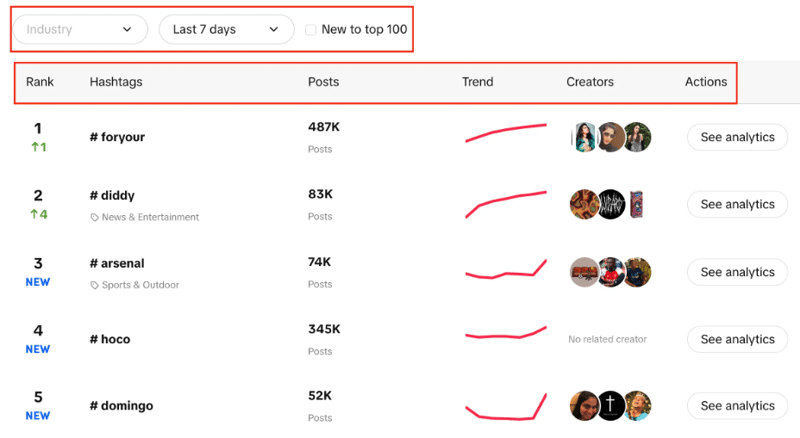
我们的目标是使用给定的过滤器从列表中提取前 100 个主题标签。
两种可能的方法是使用 CheerioCrawler,第二种方法是基于浏览器的抓取。 Cheerio 可以更快地提供结果,但不适用于 JavaScript 渲染的网站。
Cheerio 在这里不是最佳选择,因为 Creative Center 是一个 Web 应用程序,数据源是 API,因此我们只能获取最初出现在 HTML 结构中的主题标签,而不能获取我们需要的 100 个主题标签中的每一个。
第二种方法可以使用 Puppeteer、Playwright 等库来进行基于浏览器的抓取,并使用自动化来抓取所有主题标签,但根据以前的经验,这么小的任务需要花费大量时间。
现在我们开发了新方法,使这个过程比基于浏览器的抓取要好得多,并且非常接近基于 CheerioCrawler 的抓取。
JSDOM 方法
在深入研究这种方法之前,我想感谢 Apify 的 Web 自动化工程师 Alexey Udovydchenko 开发了这种方法。向他致敬!
在此方法中,我们将对 https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list 进行 API 调用以获取所需的数据。
在调用此 API 之前,我们需要一些必需的标头(身份验证数据),因此我们将首先调用 https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad /en.
我们将通过创建一个函数来开始这种方法,该函数将为我们创建 API 调用的 URL,然后进行调用并获取数据。
export const createStartUrls = (input) => {
const {
days = '7',
country = '',
resultsLimit = 100,
industry = '',
isNewToTop100,
} = input;
const filterBy = isNewToTop100 ? 'new_on_board' : '';
return [
{
url: `https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list?page=1&limit=50&period=${days}&country_code=${country}&filter_by=${filterBy}&sort_by=popular&industry_id=${industry}`,
headers: {
// required headers
},
userData: { resultsLimit },
},
];
};
在上面的函数中,我们创建 API 调用的起始 URL,其中包含我们之前讨论过的各种参数。根据参数创建URL后,它将调用creative_radar_api并获取所有结果。
但是在我们获得标头之前它不会起作用。因此,让我们创建一个函数,该函数首先使用 sessionPool 和 proxyConfiguration 创建会话。
export const createSessionFunction = async (
sessionPool,
proxyConfiguration,
) => {
const proxyUrl = await proxyConfiguration.newUrl(Math.random().toString());
const url =
'https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en';
// need url with data to generate token
const response = await gotScraping({ url, proxyUrl });
const headers = await getApiUrlWithVerificationToken(
response.body.toString(),
url,
);
if (!headers) {
throw new Error(`Token generation blocked`);
}
log.info(`Generated API verification headers`, Object.values(headers));
return new Session({
userData: {
headers,
},
sessionPool,
});
};
在此函数中,主要目标是调用 https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en 并获取 headers 作为返回。为了获取标头,我们使用 getApiUrlWithVerificationToken 函数。
在继续之前,我想提一下,Crawlee 使用 JSDOM Crawler 原生支持 JSDOM。它提供了一个使用普通 HTTP 请求和 jsdom DOM 实现并行抓取网页的框架。它使用原始 HTTP 请求来下载网页,数据带宽非常快且高效。
让我们看看如何创建 getApiUrlWithVerificationToken 函数:
const getApiUrlWithVerificationToken = async (body, url) => {
log.info(`Getting API session`);
const virtualConsole = new VirtualConsole();
const { window } = new JSDOM(body, {
url,
contentType: 'text/html',
runScripts: 'dangerously',
resources: 'usable' || new CustomResourceLoader(),
// ^ 'usable' faster than custom and works without canvas
pretendToBeVisual: false,
virtualConsole,
});
virtualConsole.on('error', () => {
// ignore errors cause by fake XMLHttpRequest
});
const apiHeaderKeys = ['anonymous-user-id', 'timestamp', 'user-sign'];
const apiValues = {};
let retries = 10;
// api calls made outside of fetch, hack below is to get URL without actual call
window.XMLHttpRequest.prototype.setRequestHeader = (name, value) => {
if (apiHeaderKeys.includes(name)) {
apiValues[name] = value;
}
if (Object.values(apiValues).length === apiHeaderKeys.length) {
retries = 0;
}
};
window.XMLHttpRequest.prototype.open = (method, urlToOpen) => {
if (
['static', 'scontent'].find((x) =>
urlToOpen.startsWith(`https://${x}`),
)
)
log.debug('urlToOpen', urlToOpen);
};
do {
await sleep(4000);
retries--;
} while (retries > 0);
await window.close();
return apiValues;
};
在此函数中,我们将创建一个虚拟控制台,它使用 CustomResourceLoader 来运行后台进程并用 JSDOM 替换浏览器。
对于这个特定的示例,我们需要三个强制标头来进行 API 调用,它们是匿名用户 ID、时间戳和用户签名。
使用 XMLHttpRequest.prototype.setRequestHeader,我们检查提到的标头是否在响应中,如果是,我们获取这些标头的值,并重复重试,直到获得所有标头。
然后,最重要的部分是我们使用 XMLHttpRequest.prototype.open 提取身份验证数据并进行调用,而无需实际使用浏览器或公开机器人活动。
在 createSessionFunction 的末尾,它返回一个具有所需标头的会话。
现在来到我们的主要代码,我们将使用 CheerioCrawler 并使用 prenavigationHooks 将从前面的函数获取的标头注入到 requestHandler 中。
const crawler = new CheerioCrawler({
sessionPoolOptions: {
maxPoolSize: 1,
createSessionFunction: async (sessionPool) =>
createSessionFunction(sessionPool, proxyConfiguration),
},
preNavigationHooks: [
(crawlingContext) => {
const { request, session } = crawlingContext;
request.headers = {
...request.headers,
...session.userData?.headers,
};
},
],
proxyConfiguration,
});
最后,在请求处理程序中,我们使用标头进行调用,并确保需要多少次调用来获取所有数据处理分页。
async requestHandler(context) {
const { log, request, json } = context;
const { userData } = request;
const { itemsCounter = 0, resultsLimit = 0 } = userData;
if (!json.data) {
throw new Error('BLOCKED');
}
const { data } = json;
const items = data.list;
const counter = itemsCounter items.length;
const dataItems = items.slice(
0,
resultsLimit && counter > resultsLimit
? resultsLimit - itemsCounter
: undefined,
);
await context.pushData(dataItems);
const {
pagination: { page, total },
} = data;
log.info(
`Scraped ${dataItems.length} results out of ${total} from search page ${page}`,
);
const isResultsLimitNotReached =
counter
这里需要注意的一件重要事情是,我们正在以可以进行任意数量的 API 调用的方式编写此代码。
在此特定示例中,我们仅发出了一个请求和一个会话,但如果需要,您可以发出更多请求。当第一个 API 调用完成时,它将创建第二个 API 调用。同样,如果需要,您可以拨打更多电话,但我们只打了两个电话。
为了让事情更清楚,代码流程如下:
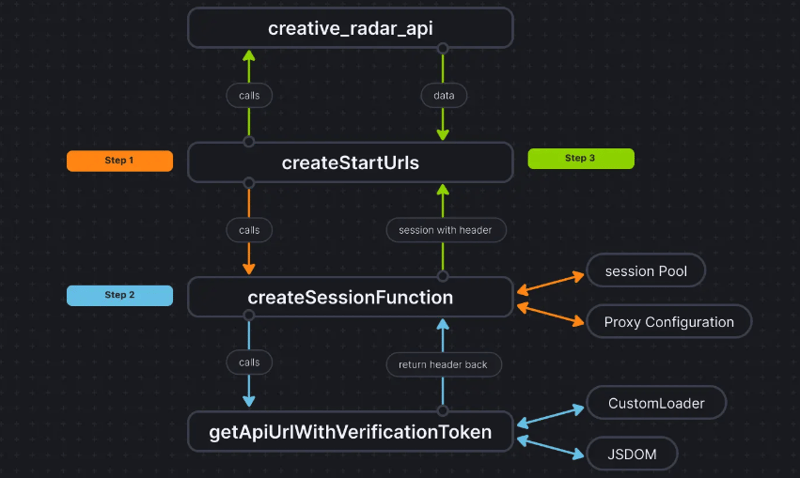
结论
这种方法帮助我们获得第三种方法来提取身份验证数据,而无需实际使用浏览器并将数据传递给 CheerioCrawler。这显着提高了性能,并将 RAM 要求降低了 50%,虽然基于浏览器的抓取性能比纯 Cheerio 慢十倍,但 JSDOM 仅慢 3-4 倍,这使其比浏览器快 2-3 倍 -基于抓取。
该项目的代码库已上传至此处。代码是作为 Apify Actor 编写的;您可以在此处找到有关它的更多信息,但您也可以在不使用 Apify SDK 的情况下运行它。
如果您对此方法有任何疑问或疑问,请通过我们的 Discord 服务器联系我们。
-
 如何在GO编译器中自定义编译优化?在GO编译器中自定义编译优化 GO中的默认编译过程遵循特定的优化策略。 However, users may need to adjust these optimizations for specific requirements.Optimization Control in Go Compi...编程 发布于2025-04-09
如何在GO编译器中自定义编译优化?在GO编译器中自定义编译优化 GO中的默认编译过程遵循特定的优化策略。 However, users may need to adjust these optimizations for specific requirements.Optimization Control in Go Compi...编程 发布于2025-04-09 -
在Java中使用for-to-loop和迭代器进行收集遍历之间是否存在性能差异?For Each Loop vs. Iterator: Efficiency in Collection TraversalIntroductionWhen traversing a collection in Java, the choice arises between using a for-...编程 发布于2025-04-09
-
如何限制动态大小的父元素中元素的滚动范围?在交互式接口中实现垂直滚动元素的CSS高度限制,控制元素的滚动行为对于确保用户体验和可访问性是必不可少的。一种这样的方案涉及限制动态大小的父元素中元素的滚动范围。问题:考虑一个布局,其中我们具有与用户垂直滚动一起移动的可滚动地图div,同时与固定的固定sidebar保持一致。但是,地图的滚动无限期...编程 发布于2025-04-09
-
您可以使用CSS在Chrome和Firefox中染色控制台输出吗?在javascript console 中显示颜色是可以使用chrome的控制台显示彩色文本,例如红色的redors,for for for for错误消息?回答是的,可以使用CSS将颜色添加到Chrome和Firefox中的控制台显示的消息(版本31或更高版本)中。要实现这一目标,请使用以下模...编程 发布于2025-04-09
-
为什么不````''{margin:0; }`始终删除CSS中的最高边距?在CSS 问题:不正确的代码: 全球范围将所有余量重置为零,如提供的代码所建议的,可能会导致意外的副作用。解决特定的保证金问题是更建议的。 例如,在提供的示例中,将以下代码添加到CSS中,将解决余量问题: body H1 { 保证金顶:-40px; } 此方法更精确,避免了由全局保证金重置引...编程 发布于2025-04-09
-
如何有效地转换PHP中的时区?在PHP 利用dateTime对象和functions DateTime对象及其相应的功能别名为时区转换提供方便的方法。例如: //定义用户的时区 date_default_timezone_set('欧洲/伦敦'); //创建DateTime对象 $ dateTime = ne...编程 发布于2025-04-09
-
eval()vs. ast.literal_eval():对于用户输入,哪个Python函数更安全?称量()和ast.literal_eval()中的Python Security 在使用用户输入时,必须优先确保安全性。强大的Python功能Eval()通常是作为潜在解决方案而出现的,但担心其潜在风险。 This article delves into the differences betwee...编程 发布于2025-04-09
-
如何将来自三个MySQL表的数据组合到新表中?mysql:从三个表和列的新表创建新表 答案:为了实现这一目标,您可以利用一个3-way Join。 选择p。*,d.content作为年龄 来自人为p的人 加入d.person_id = p.id上的d的详细信息 加入T.Id = d.detail_id的分类法 其中t.taxonomy =...编程 发布于2025-04-09
-
如何在php中使用卷发发送原始帖子请求?如何使用php 创建请求来发送原始帖子请求,开始使用curl_init()开始初始化curl session。然后,配置以下选项: curlopt_url:请求 [要发送的原始数据指定内容类型,为原始的帖子请求指定身体的内容类型很重要。在这种情况下,它是文本/平原。要执行此操作,请使用包含以下标头...编程 发布于2025-04-09
-
-
如何使用Python理解有效地创建字典?在python中,词典综合提供了一种生成新词典的简洁方法。尽管它们与列表综合相似,但存在一些显着差异。与问题所暗示的不同,您无法为钥匙创建字典理解。您必须明确指定键和值。 For example:d = {n: n**2 for n in range(5)}This creates a dicti...编程 发布于2025-04-09
-
可以在纯CS中将多个粘性元素彼此堆叠在一起吗?[2这里: https://webthemez.com/demo/sticky-multi-header-scroll/index.html </main> <section> { display:grid; grid-template-...编程 发布于2025-04-09
-
如何从PHP中的数组中提取随机元素?从阵列中的随机选择,可以轻松从数组中获取随机项目。考虑以下数组:; 从此数组中检索一个随机项目,利用array_rand( array_rand()函数从数组返回一个随机键。通过将$项目数组索引使用此键,我们可以从数组中访问一个随机元素。这种方法为选择随机项目提供了一种直接且可靠的方法。编程 发布于2025-04-09
-
为什么使用Firefox后退按钮时JavaScript执行停止?导航历史记录问题:JavaScript使用Firefox Back Back 此行为是由浏览器缓存JavaScript资源引起的。要解决此问题并确保在后续页面访问中执行脚本,Firefox用户应设置一个空功能。 警报'); }; alert('inline Alert')...编程 发布于2025-04-09















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









