
MLP-混合器(理论)
 浏览:674
浏览:674
TL;DR - This is the first article I am writing to report on my journey studying the MPL-Mixer architecture. It will cover the basics up to an intermediate level. The goal is not to reach an advanced level.
Reference: https://arxiv.org/abs/2105.01601
Introduction
From the original paper it's stated that
We propose the MLP-Mixer architecture (or “Mixer” for short), a competitive but conceptually and technically simple alternative, that does not use convolutions or self-attention. Instead, Mixer’s architecture is based entirely on multi-layer perceptrons (MLPs) that are repeatedly applied across either spatial locations or feature channels. Mixer relies only on basic matrix multiplication routines, changes to data layout (reshapes and transpositions), and scalar nonlinearities.
At first, this explanation wasn’t very intuitive to me. With that in mind, I decided to investigate other resources that could provide an easier explanation. In any case, let’s keep in mind that the proposed architecture is shown in the image below.
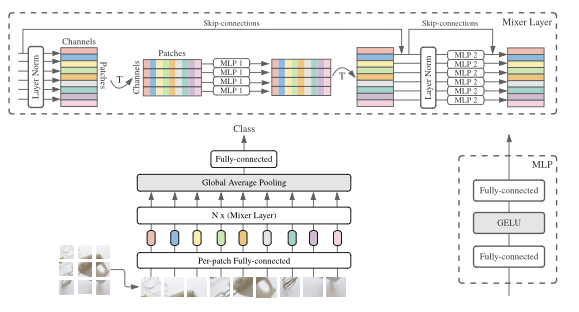
MLP-Mixer consists of per-patch linear embeddings, Mixer layers, and a classifier head. Mixer layers contain one token-mixing MLP and one channel-mixing MLP, each consisting of two fully-connected layers and a GELU nonlinearity. Other components include: skip-connections, dropout, and layer norm on the channels.
Unlike CNNs, which focus on local image regions through convolutions, and transformers, which use attention to capture relationships between image patches, the MLP-Mixer uses only two types of operations:
Patch Mixing (Spatial Mixing)
Channel Mixing
Image Patches
In general, from the figure below, we can see that this architecture is a "fancy" classification model, where the output of the fully connected layer is a class. The input for this architecture is an image, which is divided into patches.
In case you're not 100% sure what a patch is, when an image is divided into 'patches,' it means the image is split into smaller, equally sized square (or rectangular) sections, known as patches. Each patch represents a small, localized region of the original image. Instead of processing the entire image as a whole, these smaller patches are analyzed independently or in groups, often for tasks like object detection, classification, or feature extraction. Each patch is then provided to a "Per-patch Fully-connected" layer and subsequently a " N× (Mixer Layer)."
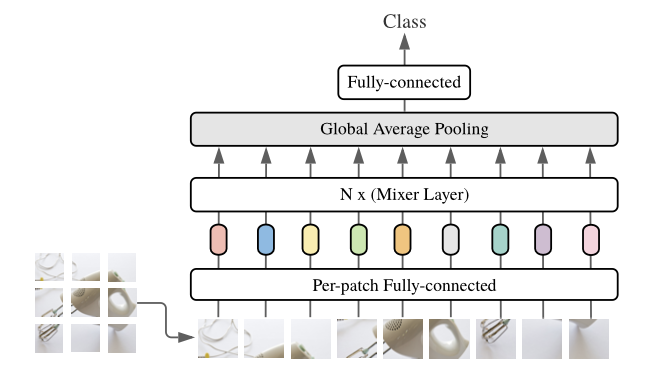
How the MLP-Mixer Processes Patches
For a clear example, let's take a 224x224 pixel image which can be divided into 16x16 pixel patches, when diving the image we'll have
So, the 224x224 pixel image will be divided into a grid of 14 patches along the width and 14 patched along the height. This results in a 14x14 grid of patches. The total number of patches is then calculated by 14×14=196 patches. After diving the image into patches, each patch will contain 16×16=256 pixels. These pixel values can be flattened into a 1D vector of length 256.
It's crucial to note that if the image has multiple channels (like RGB with 3 channels), each patch will actually have 3×16×16=768 values because each pixel in a RGB image has three color channels.
Thus, for an RGB image:
Each patch can be represented as a vector of 768 values
We then have 196 patches, each represented by a 768-dimensional vector
Each patch (a 768-dimensional vector in our example) is projected into a higher-dimensional space using a linear layer (MLP). This essentially gives each patch an embedding that is used as the input to the MLP-Mixer. More specifically, after dividing the image into patches, each patch is processed by the Per-patch Fully-connected layer (depicted in the second row).
Per-patch Fully Connected Layer
Each patch is essentially treated as a vector of values, as we have explained before, a 768-dimensional vector in our example. These values are passed through a fully connected linear layer, which transforms them into another vector. This is done for each patch independently. The role of this fully connected layer is to map each patch to a higher-dimensional embedding space, similar to how token embeddings are used in transformers.
N x Mixer Layers
This part shows a set of stacked mixer layers that alternate between two different types of MLP-based operations:
1. Patch Mixing: In this layer, the model mixes information between patches. This means it looks at the relationships between patches in the image (i.e., across different spatial locations). It's achieved through an MLP that treats each patch as a separate entity and computes the interactions between them.
2. Channel Mixing: After patch mixing, the channel mixing layer processes the internal information of each patch independently. It looks at the relationships between different pixel values (or channels) within each patch by applying another MLP.
These mixer layers alternate between patch mixing and channel mixing. They are applied N times, where N is a hyperparameter to configure the number of times the layers are repeated. The goal of these layers is to mix both spatial (patch-wise) and channel-wise information across the entire image.
Global Average Pooling
After passing through several mixer layers, a global average pooling layer is applied. This layer helps reduce the dimensionality of the output by averaging the activations across all patches. The global average pooling layer computes the average value across all patches, essentially summarizing the information from all patches into a single vector. This reduces the overall dimensionality and prepares the data for the final classification step. Additionally, it helps aggregate the learned features from the entire image in a more compact way.
Fully Connected Layer for Classification
This layer is responsible for taking the output of the global average pooling and mapping it to a classification label. The fully connected layer takes the averaged features from the global pooling layer and uses them to make a prediction about the class of the image. The number of output units in this layer corresponds to the number of classes in the classification task.
Quick Recap Until Now
Input Image: the image is divided into small patches
Per-patch Fully Connected Layer: Each patch is processed independently by a fully connected layer to create patch embeddings
Mixer Layers: The patches are then passed through a series of mixer layers, where information is mixed spatially (between patches) and channel-wise (within patches)
Global Average Pooling: The features from all patches are averaged to summarize the information
Fully Connected Layer: Finally, the averaged features are used to predict the class label of the image
Overview of the Mixer Layer Architecture
As stated before, the Mixer Layer architecture consists of two alternating operations:
Patch Mixing
Channel Mixing
Each mixing state is handled by a MLP, and there are also skip-connections and layer normalization steps included. Let's go step by step through how an image is processed using as a reference the image shown below:
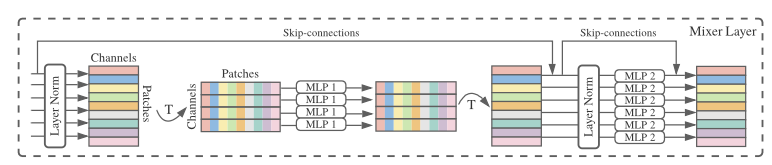
Note, that the image itself is not provided as an input to this diagram. Actually, the image has already been divided into patches as explained before and each patch is processed by a per-patch fully connected layer (linear embedding). The output of that state is what enters the Mixer Layer. Here is how it goes:
Before reaching this layer, the image has already been divided into patches. These patches are flattened and embedded as vectors (after the per-patch fully connected layer)
The input to this diagram consists of tokens (one for each patch) and channels (the feature dimensions for each patch)
So the input is structured as a 2D tensor with: Patches (one patch per token in the sequence) and Channels (features within each patch)
In simple terms, as shown in the image we can think of the input as a matrix where: Each row represents a patch, and each column represents a channel (feature dimension)
Processing Inside the Mixer Layer
Now, let's break down the key operations in this Mixer Layer, which processes the patches that come from the previous stage:
1. Layer Normalization
- The first step is the normalization of the input data to improve training stability. This happens before any mixing occurs.
2. Patch Mixing (First MLP Block)
After normalization, the first MLP block is applied. In this operations, the patches are mixed together. The idea here is to capture the relationships between different patches.
This operation transposes the input so that it focuses on the patches dimension
Then, a MLP is applied along this patches dimension. This is done to allow the model to exchange information between patches and learn how patches relate spatially.
Once this mixing is done, the input is transposed back to its original format, where channels are in the focus again.
3. Skip Connection
- The architecture uses a skip-connection (bypass residual layers, allowing any layer to flow directly to any subsequent layer) that adds the original input (before patch mixing) back to the output of the patch mixing block. This helps avoid degradation of information during training.
4. Layer Normalization
- Another layer normalization step is applied to the output of the token mixing operation before the next operation (channel mixing) is applied
5. Channel Mixing (Second MLP Block)
The second MLP block performs channel mixing. Here, each patch is processed independently by a separate MLP. The goal is to model relationships between the different channels (features) within each patch.
The input is processed along the channels dimension (without mixing information between different patches). The MLP learns to capture dependencies between the various features within each patch
6. Skip Connection (for Channel Mixing)
- Similar to patch mixing, there's a skip-connection in the channel mixing block as well. This allows the model to retain the original input after the channel mixing operation and helps in stabilizing the learning process.
With the step by step explanation above we can summarize it with some key points:
Patch Mixing - this part processes the relationships between different patches (spatial mixing), allowing the model to understand global spatial patterns across the image
Channel Mixing - this part processes the relationships within each patch (channel-wise mixing), learning to capture dependencies between the features (such as pixel intensities or features maps) within each patch
Skip Connections - The skip connections help the network retain the original input and prevent vanishing gradient problems, especially in deep networks
Inside the MLP Block
The MLP block used in the MLP-Mixer architecture can be seen in the image below:
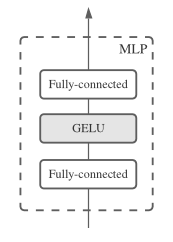
1. Fully Connected Layer
- The input (whether it's patch embeddings or channels, depending on the context) first passes through a fully connected layer. This layer performs a linear transformation of the input, meaning it multiplies the input by a weight matrix and adds a bias term.
2. GELU (Gaussian Error Linear Unit) Activation
- After the first fully connected layer, a GELU activation function is applied. GELU is a non-linear activation function that is smoother than the ReLU. It allows for a more fine-grained activation, as it approximates the behavior of a normal distribution. The formula for GELU is given by
where Φ(x) is the cumulative distribution function of a standard Gaussian distribution. The choice of GELU in MLP-Mixer is intended to improve the model’s ability to handle non-linearities in the data, which helps the model learn more complex patterns.
How it works in context:
In the Token Mixing MLP, this block is applied across the patch (token) dimension, mixing information across different patches
In the Channel Mixing MLP, the same structure is applied across the channels dimension, mixing the information within each patch independently.
Intuition - The MLP block acts as the core computational unit within the MLP-Mixer. By using two fully connected layers with an activation function in between, it learns to capture both linear and non-linear relationships within the data, depending on where it is applied (either for mixing patches or channels).
Conclusion
The MLP-Mixer offers a unique approach to image classification by leveraging simple multilayer perceptrons (MLPs) for both spatial and channel-wise interactions. By dividing an image into patches and alternating between patch mixing and channel mixing layers, the MLP-Mixer efficiently captures global spatial dependencies and local pixel relationships without relying on traditional convolutional operations. This architecture provides a streamlined yet powerful method for extracting meaningful patterns from images, demonstrating that, even with minimal reliance on complex operations, impressive performance can be achieved in deep learning tasks. It is important to note, however, that this architecture can be applied to different fields, such as time series predictions, even though it was initially proposed for vision tasks.
If you've made it this far, I want to express my gratitude. I hope this has been helpful to someone other than just me!
✧⁺⸜(^-^)⸝⁺✧
-
 为什么不使用CSS`content'属性显示图像?在Firefox extemers属性为某些图像很大,&& && && &&华倍华倍[华氏华倍华氏度]很少见,却是某些浏览属性很少,尤其是特定于Firefox的某些浏览器未能在使用内容属性引用时未能显示图像的情况。这可以在提供的CSS类中看到:。googlepic { 内容:url(&#...编程 发布于2025-07-12
为什么不使用CSS`content'属性显示图像?在Firefox extemers属性为某些图像很大,&& && && &&华倍华倍[华氏华倍华氏度]很少见,却是某些浏览属性很少,尤其是特定于Firefox的某些浏览器未能在使用内容属性引用时未能显示图像的情况。这可以在提供的CSS类中看到:。googlepic { 内容:url(&#...编程 发布于2025-07-12 -
解决Spring Security 4.1及以上版本CORS问题指南弹簧安全性cors filter:故障排除常见问题 在将Spring Security集成到现有项目中时,您可能会遇到与CORS相关的错误,如果像“访问Control-allo-allow-Origin”之类的标头,则无法设置在响应中。为了解决此问题,您可以实现自定义过滤器,例如代码段中的MyFi...编程 发布于2025-07-12
-
如何避免Go语言切片时的内存泄漏?,a [j:] ...虽然通常有效,但如果使用指针,可能会导致内存泄漏。这是因为原始的备份阵列保持完整,这意味着新切片外部指针引用的任何对象仍然可能占据内存。 copy(a [i:] 对于k,n:= len(a)-j i,len(a); k编程 发布于2025-07-12
-
对象拟合:IE和Edge中的封面失败,如何修复?To resolve this issue, we employ a clever CSS solution that solves the problem:position: absolute;top: 50%;left: 50%;transform: translate(-50%, -50%)...编程 发布于2025-07-12
-
FastAPI自定义404页面创建指南response = await call_next(request) if response.status_code == 404: return RedirectResponse("https://fastapi.tiangolo.com") else: ...编程 发布于2025-07-12
-
哪种方法更有效地用于点 - 填点检测:射线跟踪或matplotlib \的路径contains_points?在Python Matplotlib's path.contains_points FunctionMatplotlib's path.contains_points function employs a path object to represent the polygon.它...编程 发布于2025-07-12
-
如何从PHP中的数组中提取随机元素?从阵列中的随机选择,可以轻松从数组中获取随机项目。考虑以下数组:; 从此数组中检索一个随机项目,利用array_rand( array_rand()函数从数组返回一个随机键。通过将$项目数组索引使用此键,我们可以从数组中访问一个随机元素。这种方法为选择随机项目提供了一种直接且可靠的方法。编程 发布于2025-07-12
-
如何在Chrome中居中选择框文本?选择框的文本对齐:局部chrome-inly-ly-ly-lyly solument 您可能希望将文本中心集中在选择框中,以获取优化的原因或提高可访问性。但是,在CSS中的选择元素中手动添加一个文本 - 对属性可能无法正常工作。初始尝试 state)</option> < op...编程 发布于2025-07-12
-
为什么使用固定定位时,为什么具有100%网格板柱的网格超越身体?网格超过身体,用100%grid-template-columns 为什么在grid-template-colms中具有100%的显示器,当位置设置为设置的位置时,grid-template-colly修复了?问题: 考虑以下CSS和html: class =“ snippet-code”> g...编程 发布于2025-07-12
-
-
如何干净地删除匿名JavaScript事件处理程序?删除匿名事件侦听器将匿名事件侦听器添加到元素中会提供灵活性和简单性,但是当要删除它们时,可以构成挑战,而无需替换元素本身就可以替换一个问题。 element? element.addeventlistener(event,function(){/在这里工作/},false); 要解决此问题,请考虑...编程 发布于2025-07-12
-
Python中何时用"try"而非"if"检测变量值?使用“ try“ vs.” if”来测试python 在python中的变量值,在某些情况下,您可能需要在处理之前检查变量是否具有值。在使用“如果”或“ try”构建体之间决定。“ if” constructs result = function() 如果结果: 对于结果: ...编程 发布于2025-07-12
-
Python环境变量的访问与管理方法Accessing Environment Variables in PythonTo access environment variables in Python, utilize the os.environ object, which represents a mapping of envir...编程 发布于2025-07-12
-
如何修复\“常规错误:2006 MySQL Server在插入数据时已经消失\”?How to Resolve "General error: 2006 MySQL server has gone away" While Inserting RecordsIntroduction:Inserting data into a MySQL database can...编程 发布于2025-07-12
-
反射动态实现Go接口用于RPC方法探索在GO 使用反射来实现定义RPC式方法的界面。例如,考虑一个接口,例如:键入myService接口{ 登录(用户名,密码字符串)(sessionId int,错误错误) helloworld(sessionid int)(hi String,错误错误) } 替代方案而不是依靠反射...编程 发布于2025-07-12















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









