
使用 faker 和 pandas Python 库创建用于测试的综合数据
 浏览:261
浏览:261
介绍:
全面的测试对于数据驱动的应用程序至关重要,但它通常依赖于拥有正确的数据集,而这些数据集可能并不总是可用。无论您是开发 Web 应用程序、机器学习模型还是后端系统,真实且结构化的数据对于正确验证和确保稳健的性能至关重要。由于隐私问题、许可限制或仅仅是相关数据的不可用,获取真实世界数据可能会受到限制。这就是合成数据变得有价值的地方。
在本博客中,我们将探讨如何使用Python为不同场景生成合成数据,包括:
- 相关表:表示一对多关系。
- 分层数据:常用于组织结构。
- 复杂关系:如招生系统中的多对多关系。
我们将利用 faker 和 pandas 库为这些用例创建真实的数据集。
示例 1:为客户和订单创建综合数据(一对多关系)
在许多应用中,数据存储在具有外键关系的多个表中。让我们为客户及其订单生成综合数据。一个客户可以下多个订单,代表一对多的关系。
生成客户表
Customers 表包含基本信息,例如 CustomerID、姓名和电子邮件地址。
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
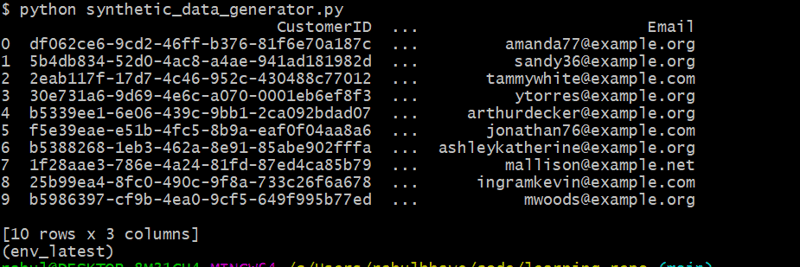
此代码使用 Faker 生成 10 个随机客户,以创建真实的姓名和电子邮件地址。
生成订单表
现在,我们生成 Orders 表,其中每个订单通过 CustomerID 与客户关联。
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
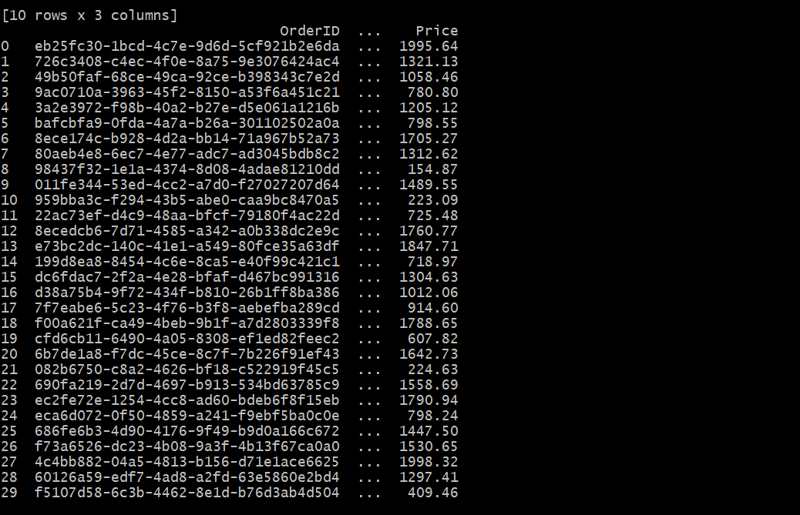
在本例中,Orders 表使用 CustomerID 将每个订单链接到客户。每个客户可以下多个订单,形成一对多的关系。
示例 2:生成部门和员工的层次结构数据
层次结构数据通常用于部门有多名员工的组织环境中。让我们模拟一个具有部门的组织,每个部门都有多名员工。
生成部门表
Departments 表包含每个部门唯一的 DepartmentID、名称和经理。
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
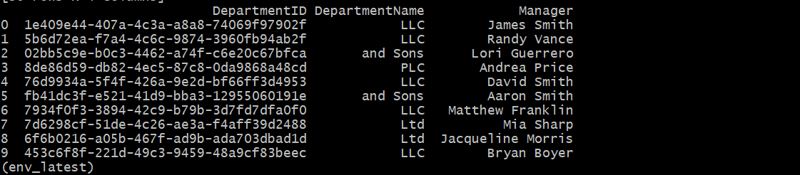
生成员工表
接下来,我们生成Employees表,其中每个员工通过DepartmentID与一个部门相关联。
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
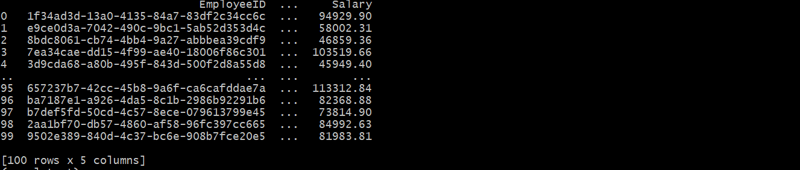
这种层次结构通过DepartmentID将每个员工与一个部门联系起来,形成父子关系。
示例 3:模拟课程注册的多对多关系
在某些场景中,存在多对多关系,其中一个实体与许多其他实体相关。让我们用注册多个课程的学生来模拟这一点,其中每个课程都有多个学生。
生成课程表
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
生成学生表
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
生成课程报名表
CourseEnrollments 表捕获学生和课程之间的多对多关系。
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
在此示例中,我们创建一个链接表来表示学生和课程之间的多对多关系。
结论:
使用 Python 以及 Faker 和 Pandas 等库,您可以生成真实且多样化的合成数据集,以满足各种测试需求。在此博客中,我们介绍了:
- 相关表:展示客户和订单之间的一对多关系。
- 分层数据:说明部门和员工之间的父子关系。
- 复杂关系:模拟学生和课程之间的多对多关系。
这些示例为生成适合您需求的合成数据奠定了基础。进一步的增强功能,例如创建更复杂的关系、为特定数据库定制数据或扩展数据集以进行性能测试,可以将合成数据生成提升到一个新的水平。
这些示例为生成合成数据提供了坚实的基础。然而,可以进行进一步的增强以增加复杂性和特异性,例如:
- 数据库特定数据:为不同数据库系统定制数据生成(例如,SQL 与 NoSQL)。
- 更复杂的关系:创建额外的相互依赖关系,例如时间关系、多级层次结构或唯一约束。
- 扩展数据:生成更大的数据集以进行性能测试或压力测试,确保系统能够大规模处理现实世界的条件。 通过生成根据您的需求定制的合成数据,您可以模拟开发、测试和优化应用程序的实际条件,而无需依赖敏感或难以获取的数据集。
如果您喜欢这篇文章,请与您的朋友和同事分享。您可以在 LinkedIn 上与我联系,讨论任何进一步的想法。
-
 Python中嵌套函数与闭包的区别是什么嵌套函数与python 在python中的嵌套函数不被考虑闭合,因为它们不符合以下要求:不访问局部范围scliables to incling scliables在封装范围外执行范围的局部范围。 make_printer(msg): DEF打印机(): 打印(味精) ...编程 发布于2025-07-16
Python中嵌套函数与闭包的区别是什么嵌套函数与python 在python中的嵌套函数不被考虑闭合,因为它们不符合以下要求:不访问局部范围scliables to incling scliables在封装范围外执行范围的局部范围。 make_printer(msg): DEF打印机(): 打印(味精) ...编程 发布于2025-07-16 -
左连接为何在右表WHERE子句过滤时像内连接?左JOIN CONUNDRUM:WITCHING小时在数据库Wizard的领域中变成内在的加入很有趣,当将c.foobar条件放置在上面的Where子句中时,据说左联接似乎会转换为内部连接。仅当满足A.Foo和C.Foobar标准时,才会返回结果。为什么要变形?关键在于其中的子句。当左联接的右侧值...编程 发布于2025-07-16
-
在GO中构造SQL查询时,如何安全地加入文本和值?在go中构造文本sql查询时,在go sql queries 中,在使用conting and contement和contement consem per时,尤其是在使用integer per当per当per时,per per per当per. 在GO中实现这一目标的惯用方法是使用fmt.spr...编程 发布于2025-07-16
-
如何从PHP中的Unicode字符串中有效地产生对URL友好的sl。为有效的slug生成首先,该函数用指定的分隔符替换所有非字母或数字字符。此步骤可确保slug遵守URL惯例。随后,它采用ICONV函数将文本简化为us-ascii兼容格式,从而允许更广泛的字符集合兼容性。接下来,该函数使用正则表达式删除了不需要的字符,例如特殊字符和空格。此步骤可确保slug仅包含...编程 发布于2025-07-16
-
`console.log`显示修改后对象值异常的原因foo = [{id:1},{id:2},{id:3},{id:4},{id:id:5},],]; console.log('foo1',foo,foo.length); foo.splice(2,1); console.log('foo2', foo, foo....编程 发布于2025-07-16
-
\“(1)vs.(;;):编译器优化是否消除了性能差异?\”答案: 在大多数现代编译器中,while(1)和(1)和(;;)之间没有性能差异。编译器: perl: 1 输入 - > 2 2 NextState(Main 2 -E:1)V-> 3 9 Leaveloop VK/2-> A 3 toterloop(next-> 8 last-> 9 ...编程 发布于2025-07-16
-
Go语言如何动态发现导出包类型?与反射软件包中的有限类型的发现能力相反,本文探讨了在运行时发现所有包装类型(尤其是struntime go import( “ FMT” “去/进口商” ) func main(){ pkg,err:= incorter.default()。导入(“ time”) ...编程 发布于2025-07-16
-
如何解决AppEngine中“无法猜测文件类型,使用application/octet-stream...”错误?appEngine静态文件mime type override ,静态文件处理程序有时可以覆盖正确的mime类型,在错误消息中导致错误消息:“无法猜测mimeType for for file for file for [File]。 application/application/octet...编程 发布于2025-07-16
-
如何使用替换指令在GO MOD中解析模块路径差异?在使用GO MOD时,在GO MOD 中克服模块路径差异时,可能会遇到冲突,其中可能会遇到一个冲突,其中3派对软件包将另一个带有导入套件的path package the Imptioned package the Imptioned package the Imported tocted pac...编程 发布于2025-07-16
-
如何使用“ JSON”软件包解析JSON阵列?parsing JSON与JSON软件包 QUALDALS:考虑以下go代码:字符串 } func main(){ datajson:=`[“ 1”,“ 2”,“ 3”]`` arr:= jsontype {} 摘要:= = json.unmarshal([] byte(...编程 发布于2025-07-16
-
Android如何向PHP服务器发送POST数据?在android apache httpclient(已弃用) httpclient httpclient = new defaulthttpclient(); httppost httppost = new httppost(“ http://www.yoursite.com/script.p...编程 发布于2025-07-16
-
PHP阵列键值异常:了解07和08的好奇情况PHP数组键值问题,使用07&08 在给定数月的数组中,键值07和08呈现令人困惑的行为时,就会出现一个不寻常的问题。运行print_r($月份)返回意外结果:键“ 07”丢失,而键“ 08”分配给了9月的值。此问题源于PHP对领先零的解释。当一个数字带有0(例如07或08)的前缀时,PHP将...编程 发布于2025-07-16
-
PHP与C++函数重载处理的区别作为经验丰富的C开发人员脱离谜题,您可能会遇到功能超载的概念。这个概念虽然在C中普遍,但在PHP中构成了独特的挑战。让我们深入研究PHP功能过载的复杂性,并探索其提供的可能性。在PHP中理解php的方法在PHP中,函数超载的概念(如C等语言)不存在。函数签名仅由其名称定义,而与他们的参数列表无关。...编程 发布于2025-07-16
-
input: Why Does "Warning: mysqli_query() expects parameter 1 to be mysqli, resource given" Error Occur and How to Fix It? output: 解决“Warning: mysqli_query() 参数应为 mysqli 而非 resource”错误的解析与修复方法mysqli_query()期望参数1是mysqli,resource给定的,尝试使用mysql Query进行执行MySQLI_QUERY_QUERY formation,be be yessqli:sqli:sqli:sqli:sqli:sqli:sqli: mysqli,给定的资源“可能发...编程 发布于2025-07-16
-
用户本地时间格式及时区偏移显示指南在用户的语言环境格式中显示日期/时间,并使用时间偏移在向最终用户展示日期和时间时,以其localzone and格式显示它们至关重要。这确保了不同地理位置的清晰度和无缝用户体验。以下是使用JavaScript实现此目的的方法。方法:推荐方法是处理客户端的Javascript中的日期/时间格式化和时...编程 发布于2025-07-16















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









