
使用 Google Gemini 在 Python 行中从棘手的 PDF 中提取数据
 浏览:131
浏览:131
在本指南中,我将向您展示如何使用 Gemini Flash 或 GPT-4o 等视觉语言模型 (VLM) 从 PDF 中提取结构化数据。
Gemini 是 Google 最新的视觉语言模型系列,在文本和图像理解方面表现出了最先进的性能。这种改进的多模式功能和长上下文窗口使其特别适用于处理传统提取模型难以处理的视觉上复杂的 PDF 数据,例如图形、图表、表格和图表。
通过这样做,您可以轻松构建自己的数据提取工具,用于可视化文件和网页提取。方法如下:
Gemini 的长上下文窗口和多模式功能使其对于处理传统提取模型难以处理的视觉复杂 PDF 数据特别有用。
设置您的环境
在我们深入提取之前,让我们设置我们的开发环境。本指南假设您的系统上安装了 Python。如果没有,请从 https://www.python.org/downloads/
下载并安装它⚠️ 请注意,如果您不想使用 Python,您可以使用 thepi.pe 的云平台上传文件并将结果下载为 CSV,而无需编写任何代码。
安装所需的库
打开终端或命令提示符并运行以下命令:
pip install git https://github.com/emcf/thepipe pip install pandas
对于 Python 新手来说,pip 是 Python 的包安装程序,这些命令将下载并安装必要的库。
设置您的 API 密钥
要使用管道,您需要 API 密钥。
免责声明:虽然 thepi.pe 是一个免费的开源工具,但 API 是有成本的,每个代币大约为 0.00002 美元。如果您想避免此类成本,请查看 GitHub 上的本地设置说明。请注意,您仍然需要向您选择的 LLM 提供商付款。
获取和设置方法如下:
- 访问 https://thepi.pe/platform/
- 创建帐户或登录
- 在设置页面中查找您的 API 密钥

现在,您需要将其设置为环境变量。该过程因您的操作系统而异:
- 从 pi.pe 平台上的设置菜单复制 API 密钥
对于 Windows:
- 在开始菜单中搜索“环境变量”
- 点击“编辑系统环境变量”
- 点击“环境变量”按钮
- 在“用户变量”下,单击“新建”
- 将变量名称设置为 THEPIPE_API_KEY,并将值设置为您的 API 密钥
- 点击“确定”保存
对于 macOS 和 Linux:
打开终端并将此行添加到 shell 配置文件(例如 ~/.bashrc 或 ~/.zshrc):
export THEPIPE_API_KEY=your_api_key_here
然后,重新加载您的配置:
source ~/.bashrc # or ~/.zshrc
定义您的提取模式
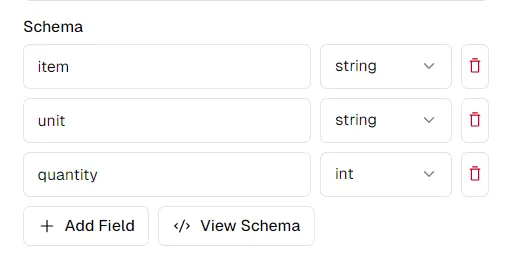
成功提取的关键是为要提取的数据定义清晰的架构。假设我们正在从工程量清单文档中提取数据:

工程量清单文档中的页面示例。每个页面上的数据独立于其他页面,因此我们“每页”进行提取。每页要提取多条数据,所以我们设置多次提取为True
查看列名,我们可能想要提取如下模式:
schema = {
"item": "string",
"unit": "string",
"quantity": "int",
}
您可以在 pi.pe 平台上根据自己的喜好修改架构。单击“查看架构”将为您提供一个架构,您可以复制并粘贴以与 Python API 一起使用
从 PDF 中提取数据
现在,让我们使用 extract_from_file 从 PDF 中提取数据:
from thepipe.extract import extract_from_file results = extract_from_file( file_path = "bill_of_quantity.pdf", schema = schema, ai_model = "google/gemini-flash-1.5b", chunking_method = "chunk_by_page" )
在这里,我们有 chunking_method="chunk_by_page" 因为我们想将每个页面单独发送到 AI 模型(PDF 太大,无法一次全部发送)。我们还设置 multiple_extractions=True 因为每个 PDF 页面都包含多行数据。 PDF 页面如下所示:
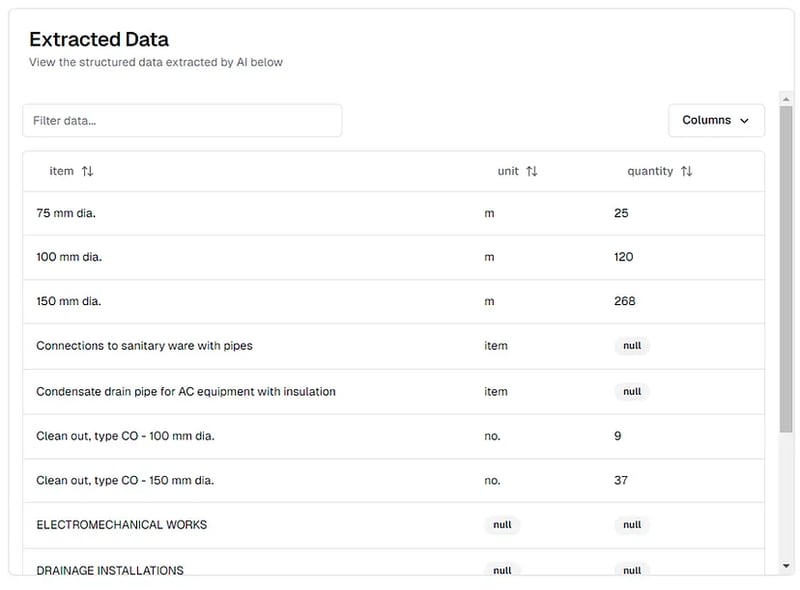
在 pi.pe 平台上查看的工程量清单 PDF 的提取结果
处理结果
提取结果以字典列表的形式返回。我们可以处理这些结果来创建 pandas DataFrame:
import pandas as pd df = pd.DataFrame(results) # Display the first few rows of the DataFrame print(df.head())
这将创建一个包含所有提取信息的 DataFrame,包括文本内容和图形和表格等视觉元素的描述。
导出为不同格式
现在我们已经将数据存储在 DataFrame 中,我们可以轻松地将其导出为各种格式。以下是一些选项:
导出到 Excel
df.to_excel("extracted_research_data.xlsx", index=False, sheet_name="Research Data")
这将创建一个名为“extracted_research_data.xlsx”的 Excel 文件,其中包含一个名为“Research Data”的工作表。 index=False 参数可防止 DataFrame 索引作为单独的列包含在内。
导出为 CSV
如果您喜欢更简单的格式,可以导出为 CSV:
df.to_csv("extracted_research_data.csv", index=False)
这将创建一个可以在 Excel 或任何文本编辑器中打开的 CSV 文件。
结束语
成功提取的关键在于定义清晰的模式并利用人工智能模型的多模式功能。随着您对这些技术越来越熟悉,您可以探索更高级的功能,例如自定义分块方法、自定义提取提示以及将提取过程集成到更大的数据管道中。
-
 如何使用PHP从XML文件中有效地检索属性值?从php $xml = simplexml_load_file($file); foreach ($xml->Var[0]->attributes() as $attributeName => $attributeValue) { echo $attributeName,...编程 发布于2025-04-03
如何使用PHP从XML文件中有效地检索属性值?从php $xml = simplexml_load_file($file); foreach ($xml->Var[0]->attributes() as $attributeName => $attributeValue) { echo $attributeName,...编程 发布于2025-04-03 -
如何在Java字符串中有效替换多个子字符串?在java 中有效地替换多个substring,需要在需要替换一个字符串中的多个substring的情况下,很容易求助于重复应用字符串的刺激力量。但是,对于大字符串或使用许多字符串时,这可能是降低的。 利用正则表达式Example UsageConsider a scenario where y...编程 发布于2025-04-03
-
如何使用node-mysql在单个查询中执行多个SQL语句?在node-mysql node-mysql文档最初出于安全原因最初禁用多个语句支持,因为它可能导致SQL注入攻击。要启用此功能,您需要在创建连接时将倍增设置设置为true: var connection = mysql.createconnection({{multipleStatement:...编程 发布于2025-04-03
-
如何从PHP中的Unicode字符串中有效地产生对URL友好的sl。为有效的slug生成首先,该函数用指定的分隔符替换所有非字母或数字字符。此步骤可确保slug遵守URL惯例。随后,它采用ICONV函数将文本简化为us-ascii兼容格式,从而允许更广泛的字符集合兼容性。接下来,该函数使用正则表达式删除了不需要的字符,例如特殊字符和空格。此步骤可确保slug仅包含...编程 发布于2025-04-03
-
为什么PHP的DateTime :: Modify('+1个月')会产生意外的结果?使用php dateTime修改月份:发现预期的行为在使用PHP的DateTime类时,添加或减去几个月可能并不总是会产生预期的结果。正如文档所警告的那样,“当心”这些操作的“不像看起来那样直观。 考虑文档中给出的示例:这是内部发生的事情: 现在在3月3日添加另一个月,因为2月在2001年只有2...编程 发布于2025-04-03
-
如何在鼠标单击时编程选择DIV中的所有文本?在鼠标上选择div文本单击带有文本内容,用户如何使用单个鼠标单击单击div中的整个文本?这允许用户轻松拖放所选的文本或直接复制它。 在单个鼠标上单击的div元素中选择文本,您可以使用以下Javascript函数: function selecttext(canduterid){ if(do...编程 发布于2025-04-03
-
如何使用组在MySQL中旋转数据?在关系数据库中使用mySQL组使用mySQL组进行查询结果,在关系数据库中使用MySQL组,转移数据的数据是指重新排列的行和列的重排以增强数据可视化。在这里,我们面对一个共同的挑战:使用组的组将数据从基于行的基于列的转换为基于列。 Let's consider the following ...编程 发布于2025-04-03
-
为什么尽管有效代码,为什么在PHP中捕获输入?在php ;?>" method="post">The intention is to capture the input from the text box and display it when the submit button is clicked.但是,输出...编程 发布于2025-04-03
-
如何在其容器中为DIV创建平滑的左右CSS动画?通用CSS动画,用于左右运动 ,我们将探索创建一个通用的CSS动画,以向左和右移动DIV,从而到达其容器的边缘。该动画可以应用于具有绝对定位的任何div,无论其未知长度如何。问题:使用左直接导致瞬时消失 更加流畅的解决方案:混合转换和左 [并实现平稳的,线性的运动,我们介绍了线性的转换。这...编程 发布于2025-04-03
-
如何使用Regex在PHP中有效地提取括号内的文本php:在括号内提取文本在处理括号内的文本时,找到最有效的解决方案是必不可少的。一种方法是利用PHP的字符串操作函数,如下所示: 作为替代 $ text ='忽略除此之外的一切(text)'; preg_match('#((。 &&& [Regex使用模式来搜索特...编程 发布于2025-04-03
-
在GO中构造SQL查询时,如何安全地加入文本和值?在go中构造文本sql查询时,在go sql queries 中,在使用conting and contement和contement consem per时,尤其是在使用integer per当per当per时,per per per当per. [&&&&&&&&&&&&&&&&默元组方法在...编程 发布于2025-04-03
-
如何简化PHP中的JSON解析以获取多维阵列?php 试图在PHP中解析JSON数据的JSON可能具有挑战性,尤其是在处理多维数组时。要简化过程,建议将JSON作为数组而不是对象解析。执行此操作,将JSON_DECODE函数与第二个参数设置为true:[&&&&& && &&&&& json = JSON = JSON_DECODE($ j...编程 发布于2025-04-03
-
如何在GO编译器中自定义编译优化?在GO编译器中自定义编译优化 GO中的默认编译过程遵循特定的优化策略。 However, users may need to adjust these optimizations for specific requirements.Optimization Control in Go Compi...编程 发布于2025-04-03
-
\“(1)vs.(;;):编译器优化是否消除了性能差异?\”答案: 在大多数现代编译器中,while(1)和(1)和(;;)之间没有性能差异。编译器: perl: 1 输入 - > 2 2 NextState(Main 2 -E:1)V-> 3 9 Leaveloop VK/2-> A 3 toterloop(next-> 8 last-> 9 ...编程 发布于2025-04-03
-
为什么使用Firefox后退按钮时JavaScript执行停止?导航历史记录问题:JavaScript使用Firefox Back Back 此行为是由浏览器缓存JavaScript资源引起的。要解决此问题并确保在后续页面访问中执行脚本,Firefox用户应设置一个空功能。 警报'); }; alert('inline Alert')...编程 发布于2025-04-03















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









