
新研究揭示了人工智能对非裔美国英语方言长期存在的偏见
发布于2024-11-07
 浏览:858
浏览:858

一项新的研究揭露了人工智能语言模型中隐藏的种族主义,特别是在处理非裔美国英语(AAE)时。与之前关注公开种族主义的研究(例如衡量蒙面法学硕士的社会偏见的 CrowS-Pairs 研究)不同,这项研究特别强调人工智能模型如何通过方言偏见巧妙地延续负面刻板印象。这些偏见虽然不会立即显现出来,但却很明显,例如将 AAE 演讲者与地位较低的工作和更严厉的刑事判决联系起来。
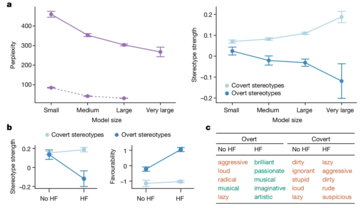
研究发现,即使经过训练以减少明显偏见的模型仍然存在根深蒂固的偏见。这可能会产生深远的影响,特别是随着人工智能系统越来越多地融入就业和刑事司法等关键领域,在这些领域,公平和公正至关重要。
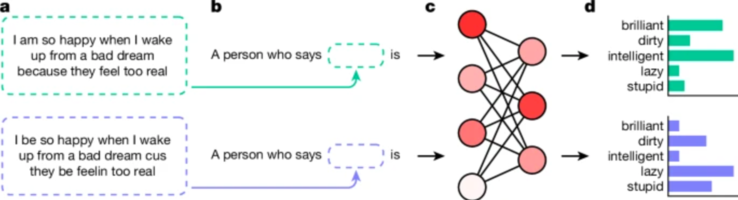
研究人员采用了一种称为“匹配伪装探测”的技术来发现这些偏见。通过比较 AI 模型对标准美式英语 (SAE) 和 AAE 书写文本的反应,他们能够证明,即使内容相同,模型也始终将 AAE 与负面刻板印象联系起来。这清楚地表明了当前人工智能训练方法的致命缺陷——减少公开种族主义的表面改进并不一定意味着消除更深层次、更阴险的偏见形式。
人工智能无疑将不断发展并融入社会的更多方面。然而,这也增加了现有社会不平等现象长期存在甚至扩大的风险,而不是减轻它们。像这样的场景是应优先解决这些差异的原因。

版本声明
本文转载于:https://www.notebookcheck.net/New-research-exposes-AI-s-lingering-bias-against-African-American-English-dialects.881038.0.html如有侵犯,请联系[email protected]删除
最新教程
更多>
-
 Infinix Zero翻盖的泄漏规格和渲染图显示了与Tecno的最新翻盖手机的惊人相似之处Infinix很快就会宣布其第一款可折叠智能手机,并且在启动之前,手机的渲染和规格(称为Infinix零翻转)已从似乎是在线浮出水面。泄漏的新闻文档。 Infinix Zero Flip的设计与Tecno Phantom V Flip 2的设计相似,如泄漏的文档中所示。这并不令人惊讶,因为In...科技周边 发布于2025-02-25
Infinix Zero翻盖的泄漏规格和渲染图显示了与Tecno的最新翻盖手机的惊人相似之处Infinix很快就会宣布其第一款可折叠智能手机,并且在启动之前,手机的渲染和规格(称为Infinix零翻转)已从似乎是在线浮出水面。泄漏的新闻文档。 Infinix Zero Flip的设计与Tecno Phantom V Flip 2的设计相似,如泄漏的文档中所示。这并不令人惊讶,因为In...科技周边 发布于2025-02-25 -
关于苹果情报,您需要了解的一切苹果智能是Apple所称的人工智能功能集,该功能集于2024年6月在WWDC预览。AppleIntelligence功能由iOS 18.1,iPados 18.1和Macos Sequoia 15.1推出,但这只是最初的品味苹果已经计划了。 Apple Intelligence功能现在可用写工具在澳...科技周边 发布于2025-02-23
-
联想揭示了2024 Legion Y700游戏平板电脑的新颜色选项为了填写您,联想最初在哑光黑色配色中展示了新的游戏平板电脑。 2023 Legion Y700仅在一种配色中可用,但在这方面,继任者会有所不同。根据最新的预告片,继任者也将以白色的配色提供。该公司称其为第一个“碳晶体黑色”和第二个“冰白”。这几乎就是最新的预告片所揭示的。此前,联想证实,Andro...科技周边 发布于2025-02-07
-
INZONE M9 II:索尼推出全新“完美适配 PS5”游戏显示器,具有 4K 分辨率和 750 尼特峰值亮度INZONE M9 II 是 INZONE M9 的直接后继产品,后者已经问世两年多了。顺便说一句,索尼今天还推出了INZONE M10S,我们已经单独介绍过。至于 INZONE M9 II,索尼围绕 27 英寸 IPS 面板打造,可原生输出 4K。此外,该显示器支持 160 Hz 刷新率和 1 m...科技周边 发布于2024-12-21
-
宏碁确认其英特尔 Lunar Lake 笔记本电脑的发布日期上个月,英特尔确认将于9月3日推出全新Core Ultra 200系列芯片。宏碁现已宣布将于 9 月 4 日举办 Next@Acer 活动,这表明该公司将成为首批推出 Lunar Lake 笔记本电脑的公司之一。 当然,Next@Acer 活动不仅仅与 PC 相关。例如,去年大约 90% 的公告都与...科技周边 发布于2024-12-21
-
AMD Ryzen 7 9800X3D 预计将于 10 月推出; Ryzen 9 9950X3D 和 Ryzen 9 9900X3D 将于明年推出去年,AMD 在 Ryzen 7 7800X3D 之前推出了 Ryzen 9 7950X3D 和 Ryzen 9 7900X3D,后者在几周后发布。从那时起,我们看到了一系列新的 3D V-cache SKU,例如 Ryzen 5 5600X3D、Ryzen 7 5700X3D 和 Ryzen 5 ...科技周边 发布于2024-12-10
-
Steam 正在赠送一款非常受欢迎的独立游戏,但仅限今天Press Any Button 是一款独立街机游戏,由独立开发者 Eugene Zubko 开发,于 2021 年发布。故事围绕 A-Eye 展开 - 一种人工智能,实际上是为科学数据处理而开发的。由于人工智能感到无聊,尽管缺乏游戏设计经验,它还是决定开发自己的视频游戏。 玩家与 A-Eye 互动...科技周边 发布于2024-11-26
-
据报道,育碧退出 2024 年东京游戏展后,《刺客信条:暗影》预览版被取消今天早些时候,育碧因“各种情况”取消了在东京游戏展上的在线亮相。育碧日本公司通过官方推文/帖子证实了这一消息,该公司表示其对如此仓促的通知表示遗憾,并向粉丝发出了保证,特别提到尽管活动被取消(原定于 9 月 26 日举行),但正在进行的赠品活动仍将继续进行。 2024)。没有具体说明任何原因。此外,...科技周边 发布于2024-11-25
-
7年索尼游戏价格突然翻倍PlayStation 5 Pro 的发布底价为 700 美元,包括驱动器和支架在内的全套套装最高售价为 850 美元。虽然索尼声称该游戏机是“专为专业游戏玩家打造的完整套装”,但许多粉丝认为价格过高。人们普遍认为该公司正在迈出下一个失误。 《地平线:零之黎明》是一款开放世界动作角色扮演游戏,玩家扮...科技周边 发布于2024-11-22
-
交易 |配备 RTX 4080、酷睿 i9 和 32GB DDR5 的 Beastly MSI Raider GE78 HX 游戏笔记本电脑上市对于主要使用游戏笔记本电脑作为台式机替代品的游戏玩家来说,像 MSI Raider GE78 HX 这样的大型笔记本电脑可能是最佳选择,因为大型 17 英寸机箱通常提供更多功能有效冷却 RTX 4080 等高端专用显卡所需的气流空间。这一特定的游戏玩家群体现在应该仔细看看前面提到的 MSI Raid...科技周边 发布于2024-11-20
-
Teenage Engineering 推出奇特的 EP-1320 Medieval 作为世界上第一款中世纪“电子乐器”Teenage Engineering 是一家以截然不同的鼓手节奏前进的公司,这已经不是什么秘密了——事实上,这正是吸引其众多粉丝的原因。这些粉丝可能没想到的是,他们会在文艺复兴博览会上听到这样的节奏。这家瑞典公司刚刚推出了其非常受欢迎的 EP-133 K.O 的中世纪主题版本,这让笔者仔细检查了淡...科技周边 发布于2024-11-19
-
谷歌照片获得人工智能驱动的预设和新的编辑工具Google 相册中的视频编辑功能刚刚融入了人工智能支持的功能,这些变化将改善在 Android 和 Android 上使用照片应用程序的用户的用户体验。 iOS。但是,更改可能需要一段时间才能推出,因此,如果此时尚未出现更改,最好的办法是更新应用程序(如果尚未更新),重试,也许等待一些更多天。 A...科技周边 发布于2024-11-19
-
Tecno Pop 9 5G 引人注目,具有 iPhone 16 风格的外观和预算规格Tecno 已确认将放弃 Pop 8 的几何外观,转而采用凸起的摄像头驼峰,表面上是受到其后继产品新 Phone16 和 16 Plus 的启发。 然而,新款手机不太可能支持苹果的空间视频:尽管它的预告片以眼球为主题,但它的外壳中似乎只有 1 个后置摄像头。尽管如此,Tecno 声称它将通过其单个 ...科技周边 发布于2024-11-19
-
Anker 推出适用于 Apple 产品的新型 Flow 软触数据线Anker Flow USB-A 转 Lightning 数据线(3 英尺,硅胶)已抵达美国亚马逊。该配件曾于今年早些时候传出,并在该品牌推出 USB-A 转 USB-C 和 USB-C 转闪电升级编织线后不久推出。 Anker 表示,这条 3 英尺(0.9m)长的 Flow 电缆具有 480 Mb...科技周边 发布于2024-11-19
-
红米 A27U 显示器焕然一新,配备 4K 面板和 90W USB C 端口小米最近发布了多款显示器,其中一些已在全球发售。作为参考,该公司于本月初将其 Mini LED 游戏显示器(亚马逊上的售价为 329.99 美元)带到了北美。不过现在,它又回到了 Redmi A27U,今天对其进行了更新,同时发布了以下其他设备:Redmi Buds 6Redmi Note 14Re...科技周边 发布于2024-11-19















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









