
从数据到决策:数据分析和机器学习如何推动业务增长
 浏览:867
浏览:867
In this article, we explore and analyze a sales dataset to gain valuable insights and drive business growth. We have undertaken various steps, from data preprocessing to machine learning model training, to extract meaningful information and make informed decisions. Through this documentation, we aim to present our findings, methodologies, and recommendations to enhance sales performance, identify key customer segments, and optimize marketing strategies.
Dataset Overview
In this dataset, we have the following features:
- ORDER_ID: Unique identifier for each order.
- CUSTOMER_ID: Identifier for the customer who made the order.
- PRODUCT_ID: Identifier for the product in the order.
- ORDER_DATE: Date the order was made.
- QUANTITY: Quantity of the product in the order.
- UNIT_PRICE: Unit price of the product in the order.
- TOTAL_SALES: Total sales for this order (calculated as QUANTITY * UNIT_PRICE).
- CUSTOMER_FEATURE_1, CUSTOMER_FEATURE_2: Synthetic features representing customer properties.
- PRODUCT_FEATURE_1, PRODUCT_FEATURE_2: Synthetic features representing product properties.
What You'll Learn
In this article, we guide you through:
. Data Cleaning and Preprocessing: How we cleaned the dataset and handled missing values, with an explanation of the chosen methods.
. Exploratory Data Analysis: Insights on sales distribution, relationships between features, and the identification of patterns or anomalies.
. Model Development and Evaluation: Training a machine learning model to forecast TOTAL_SALES, evaluating its performance with relevant metrics.
. Business Insights: Key findings to enhance sales performance, optimize marketing strategies, and identify top-performing product categories and customer segments.
Let's dive into the analysis and discover how these insights can drive business growth.
. Data Cleaning and Preprocessing
1. A Deep Dive into Dataset: Detecting Null Values
To ensure the accuracy of our analysis, we began by thoroughly examining the dataset to identify columns with missing or null values. We counted the number of null values in each column to assess the extent of missing data. This step is crucial as missing values can significantly impact the quality of our analysis.
2. Categorizing Data: Identifying Categorical Columns
Next, we identified the categorical columns within our dataset. These columns typically contain discrete values representing different categories or labels. By evaluating the number of unique values in each categorical column, we gained insights into the diversity of categories present, which helps us understand potential grouping patterns and relationships within the data.
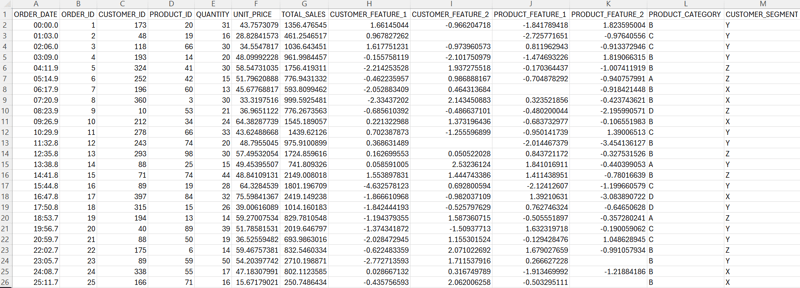
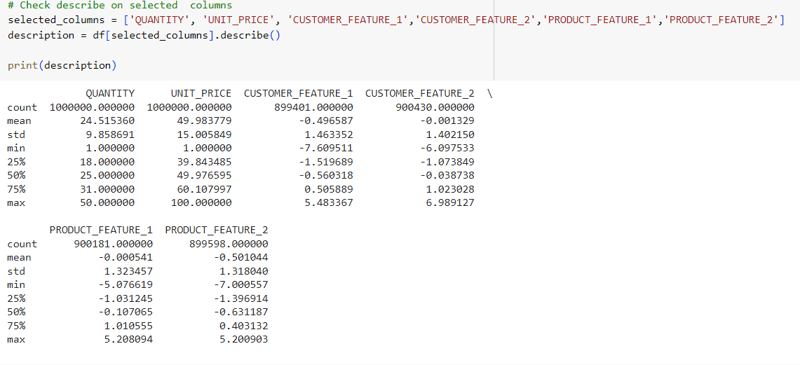
3. Dataset Overview and Handling Missing Data
We utilized the describe() function to obtain a concise summary of the dataset's numerical columns. This function provides essential statistical properties, including count, mean, standard deviation, quartiles, minimum, and maximum values. Our histogram and box plot analyses revealed that the numerical columns did not exhibit significant skewness. Therefore, to handle missing values, we opted to replace them with the mean value of each respective column. This approach helps maintain data integrity for subsequent analysis.
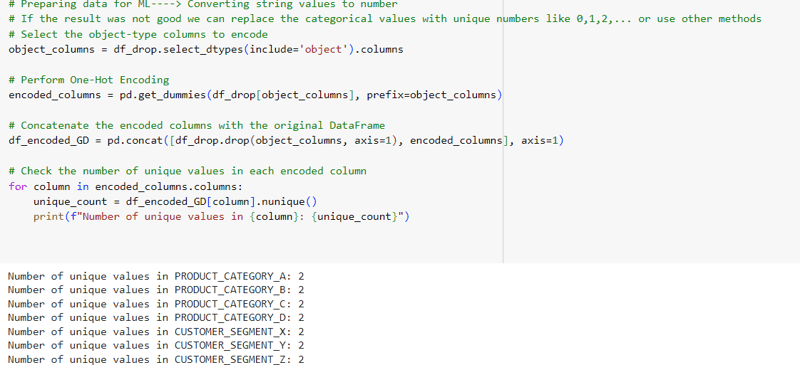
4. Converting Categorical Columns: Creating Numerical Representations
To prepare the categorical data for machine learning algorithms, we employed techniques such as one-hot encoding and the get_dummies() function. These methods convert categorical columns into numerical formats by creating binary variables, allowing algorithms to effectively process and analyze the data.
5. Feature Selection: Removing Unnecessary Columns
Finally, we examined the 'ORDER_DATE' and 'ORDER_ID' columns. Since these columns contain unique values for each row, they do not provide meaningful patterns or relationships for machine learning models. Including them in the model would not contribute valuable information for predicting the target variable. Consequently, we decided to exclude these columns from the feature set used for ML modeling. We made a copy of the original dataframe before removing these columns. This copy will be utilized for visualization and analyzing feature relationships, while the modified dataframe, with the unnecessary columns dropped, will be used for model training to enhance prediction performance.
. Exploratory Data Analysis
In this section, we delve into an in-depth exploration of the dataset to understand the relationships between various features and sales. Our analysis focuses on customer segments, product categories, and seasonal trends to uncover insights that can enhance sales performance.
To reveal meaningful patterns, we employed various visualization techniques, including bar plots, line plots, and descriptive statistics. This exploration aimed to identify dominant customer segments, popular product categories, and variations in sales behavior over time.
Here are the key findings from our exploratory analysis:
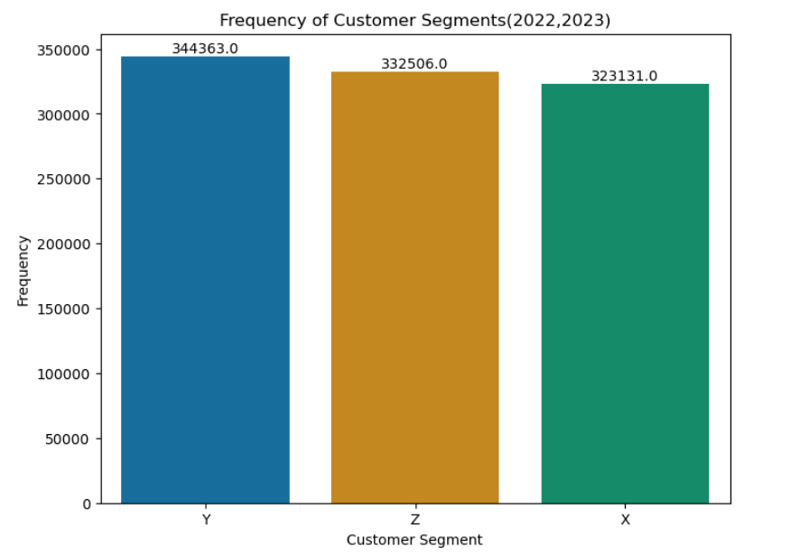
1. Customer Segments Frequency
- The 'Y' customer segment emerged as the most frequent, followed by 'Z' and 'X.' Each segment differed by approximately 10,000 occurrences in orders.
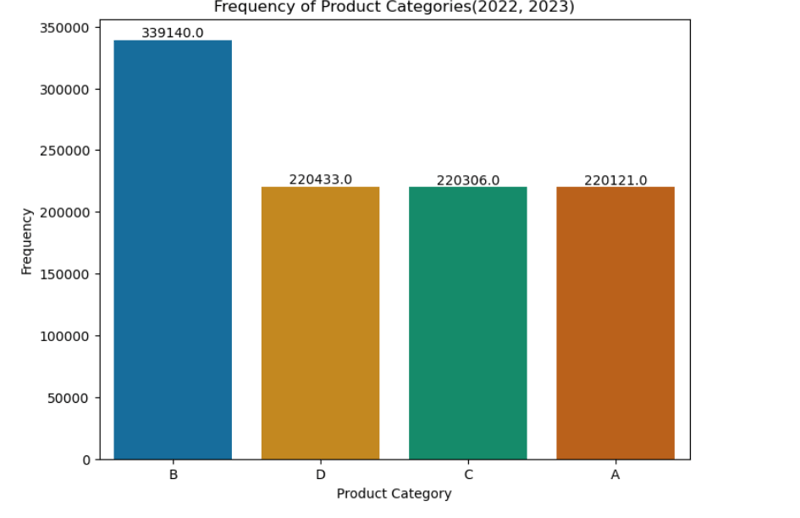
2. Product Categories Frequency
- The 'B' product category had the highest frequency, with approximately 110,000 more occurrences than the other categories ('A,' 'C,' and 'D'), which were relatively close in frequency.
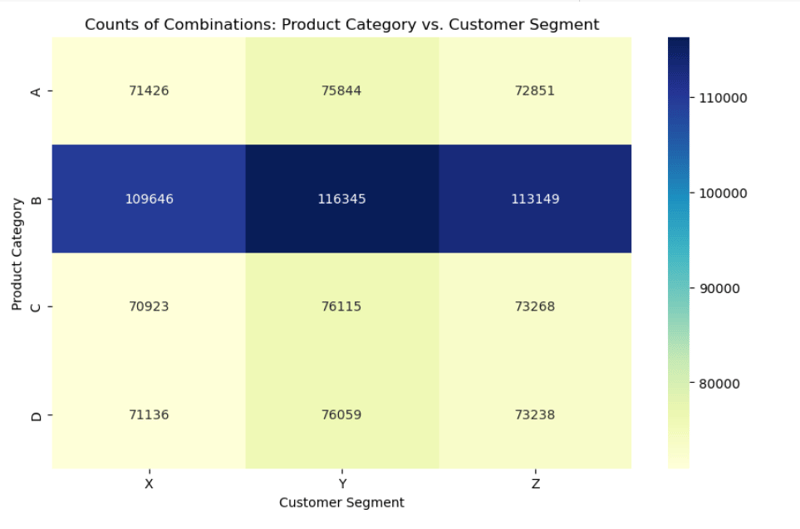
3. Product Category and Customer Segment Combination Frequency
- The combination of the 'Y' customer segment and 'B' product category was the most frequent.
4. Total Sales Amount for Each Product
- Product 78 recorded the highest total sales amount at 12,533,460, while product 21 had the lowest at 11,956,700. This indicates that total sales amounts are relatively close for different products.
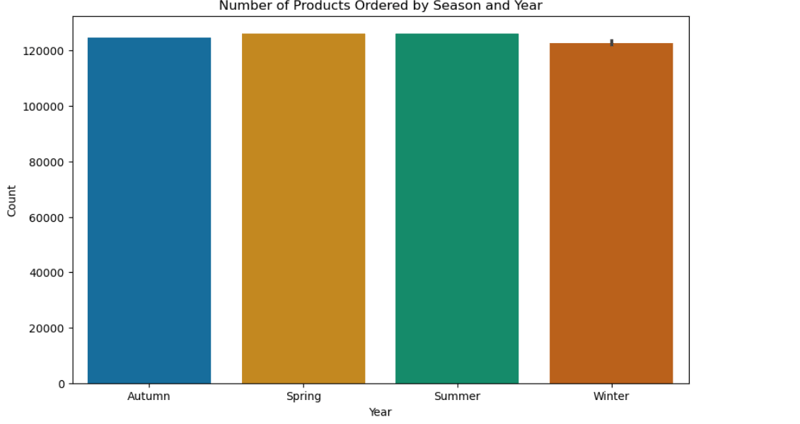
5. Number of Products Ordered by Season and Year (Bar Plot)
- Orders were notably lower in winter compared to other seasons. Additionally, the number of orders for each season in 2022 and 2023 was similar, except for winter, where 2023 saw fewer orders than 2022.
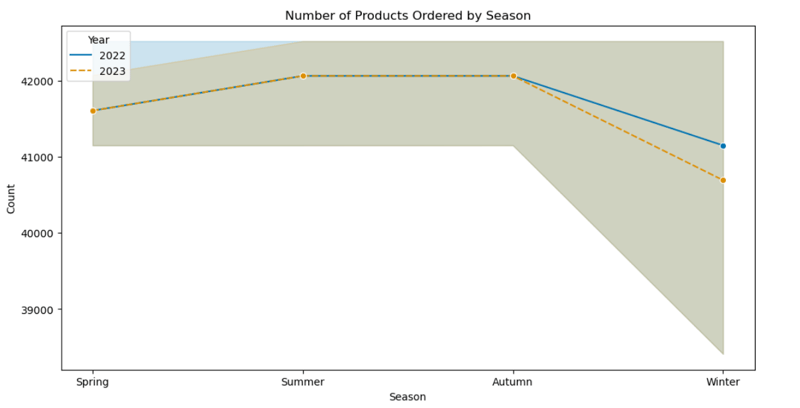
6. Number of Products Ordered by Season (Line Plot)
- A general decrease in product orders was observed during winter. The year 2023 showed a decline in orders compared to 2022, particularly in winter.
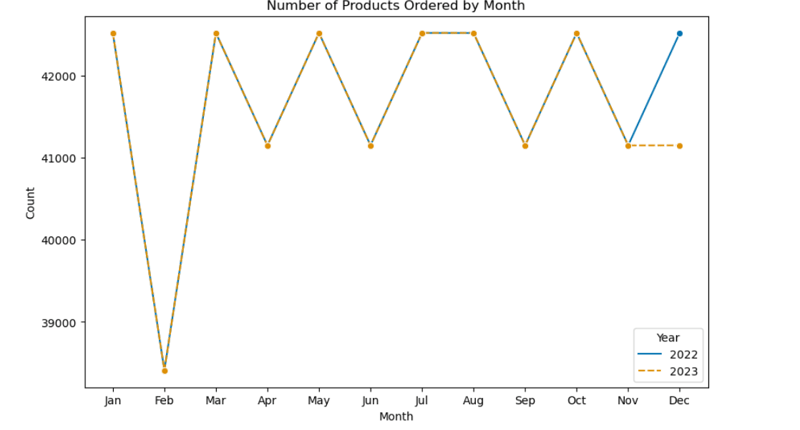
7. Number of Products Ordered by Month
- February recorded the lowest order rate. Orders were higher for odd months in the first half of the year and for even months in the second half, except for December 2023, which matched November 2023 in order volume.
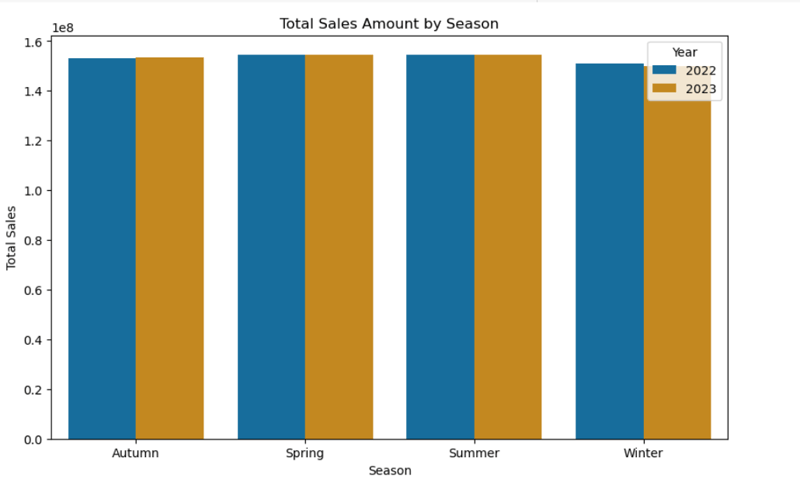
8. Total Sales Amount by Season
- Winter months in both 2022 and 2023 experienced lower total sales compared to other seasons. Additionally, total sales in winter 2023 were slightly lower than in winter 2022.
These exploratory analyses provide valuable insights into the dynamics of sales and customer behavior. By understanding these patterns, we can make informed decisions and develop strategies to optimize sales performance and drive revenue growth.
. Model Development and Evaluation
In this section, we detail the process of training and evaluating machine learning models to forecast total sales. The following steps outline our approach:
1. Data Preprocessing
We began by cleaning and preparing the dataset, handling missing values, and encoding categorical variables. This preparation was crucial for ensuring the dataset was suitable for modeling.
- Splitting the Data: We divided the preprocessed data into training and testing sets, allocating 70% for training and 30% for testing. This split helps us evaluate the model's performance on unseen data, ensuring a reliable assessment of its ability to generalize.
Although we initially aimed to use k-fold cross-validation for a more robust evaluation, memory limitations and the complexity of certain models like MLP, RBF, and XGBoost led us to use the train-test split method. Despite its simplicity, this method provides a viable alternative for assessing model performance.
2. Model Selection
We selected the following machine learning algorithms based on the complexity of the sales dataset and the nature of the problem:
MLP (Multi-Layer Perceptron): Suitable for capturing non-linear interactions and hidden patterns in the data, MLP can effectively handle the complexity of various customer segments, product categories, and seasonal patterns.
XGBoost: Known for its robustness against overfitting and ability to handle structured data, XGBoost helps identify feature importance and understand the factors affecting sales.
Random Forest: With its ensemble approach, Random Forest manages high-dimensional data well and reduces the risk of overfitting, offering stable predictions even with noisy data.
Gradient Boosting: By combining weak learners sequentially, Gradient Boosting captures complex feature relationships and improves model performance iteratively.
3. Training the Model
Each selected model was trained using the training dataset with the .fit() method.
4. Model Evaluation
We evaluated the trained models using several metrics:
Mean Squared Error (MSE): Measures the average of the squared differences between predicted and actual values. A lower MSE indicates better accuracy.
Mean Absolute Error (MAE): Calculates the average of the absolute differences between predicted and actual values, reflecting the average magnitude of errors. A lower MAE also indicates better performance.
R-squared Score: Represents the proportion of variance in the target variable (TOTAL_SALES) explained by the model. An R-squared score closer to 1 suggests a better fit.
Results Interpretation:
MLP (Multi-Layer Perceptron): Achieved very low MSE and MAE, with an R-squared score nearing 1, indicating excellent performance in predicting TOTAL_SALES.
XGBoost: Also performed well with relatively low MSE and MAE values and a high R-squared score, showing strong correlation between predicted and actual values.
Random Forest: Delivered the lowest MSE and MAE among all models and a high R-squared score, making it the most accurate for forecasting TOTAL_SALES.
Gradient Boosting: While it had higher MSE and MAE compared to other models, it still demonstrated a strong correlation between predictions and actual values with a high R-squared score.
In summary, the Random Forest model emerged as the best performer, with the lowest MSE and MAE and the highest R-squared score.

5. Hyperparameter Tuning
We performed hyperparameter tuning using techniques like grid search or random search to optimize the models' performance further.
6. Prediction
The trained models were used to make predictions on new data with the .predict() method.
7. Model Deployment
We deployed the best-performing model in a production environment to facilitate real-world use.
8. Model Monitoring and Maintenance
Continuous monitoring of the model’s performance is essential. We will update the model as needed to maintain accuracy over time.
9. Interpretation and Analysis
Finally, we analyzed the model’s results to gain actionable insights and make informed business decisions.
This comprehensive approach ensures that we develop robust, accurate models that can effectively forecast sales and support strategic decision-making.
. Business Insights
Our data analysis has uncovered several key insights that can drive sales growth and optimize business strategies:
1. Targeted Marketing
- The 'Y' customer segment demonstrated a higher purchase frequency compared to 'Z' and 'X.' To capitalize on this, we recommend implementing targeted marketing campaigns specifically designed for segment 'Y.' This approach can further engage this high-potential customer group and boost sales.
2. Product Promotion
- Product category 'B' showed the highest purchase frequency among all categories. Focusing promotional efforts on products within category 'B' can leverage its popularity and drive additional sales. Tailored marketing campaigns and special offers for this category can amplify its success.
3. Customer Rewards and Incentives
- Introducing a rewards program aimed at customer segments 'X' and 'Z' can encourage repeat purchases and build customer loyalty. Personalized discounts or incentives can motivate these segments to increase their purchase frequency and enhance overall sales.
4. Product Recommendations
- Utilizing data analytics to offer personalized product recommendations to customers in segment 'Y' and for products in category 'B' can significantly improve the shopping experience. Enhanced recommendations are likely to increase cross-selling opportunities and drive additional sales.
5. Improving Customer Experience
- Enhancing the overall customer experience—through exceptional customer support, intuitive interfaces, and seamless interactions—can positively influence all customer segments and product categories. A superior customer experience encourages conversions and fosters repeat business.
By leveraging these insights, we can tailor strategies to effectively target specific customer segments and product categories, optimizing sales performance and driving revenue growth. Continuous monitoring and adaptation based on ongoing data analysis will be crucial for maintaining success and achieving business objectives.
-
 如何为 DOM 元素生成精确的 CSS 路径?以增强的精度从 DOM 元素检索 CSS 路径提供的函数尝试为给定 DOM 元素生成 CSS 路径。然而,它的输出缺乏特异性,无法捕获元素在其兄弟元素中的位置。为了解决这个问题,我们需要一种更复杂的方法。改进的 CSS 路径函数下面介绍的增强函数解决了原来的限制:var cssPath = func...编程 发布于2024-11-03
如何为 DOM 元素生成精确的 CSS 路径?以增强的精度从 DOM 元素检索 CSS 路径提供的函数尝试为给定 DOM 元素生成 CSS 路径。然而,它的输出缺乏特异性,无法捕获元素在其兄弟元素中的位置。为了解决这个问题,我们需要一种更复杂的方法。改进的 CSS 路径函数下面介绍的增强函数解决了原来的限制:var cssPath = func...编程 发布于2024-11-03 -
如何将单个 Python 字典写入具有精确标题和值行的 CSV 文件?探索将 Python 字典写入 CSV 文件的细微差别您对将 Python 字典无缝写入 CSV 文件的追求给您带来了意想不到的挑战。虽然您设想在作为标题的字典键和作为第二行的值之间进行清晰的划分,但您当前的方法似乎还不够。让我们深入细节,解锁解决方案。问题在于方法的选择。 DictWriter.w...编程 发布于2024-11-03
-
如何处理 Go 中延迟函数的错误返回值?处理 Go 中返回值错误的延迟函数当返回变量的函数在没有延迟的情况下被延迟时,gometalinter 和 errcheck 正确地发出警告检查其返回的错误。这可能会导致未处理的错误和潜在的运行时问题。处理这种情况的习惯用法不是推迟函数本身,而是将其包装在另一个检查返回值的函数中。这是一个例子:de...编程 发布于2024-11-03
-
为什么程序员不能总是记住代码:背后的科学如果您曾经想知道为什么程序员很难回忆起他们编写的确切代码,那么您并不孤单。尽管花费了数小时编码,许多开发人员经常忘记细节。这并不是因为缺乏知识或经验,而是因为工作本身的性质。我们来探究一下这种现象背后的原因。 编程的本质 通过记忆解决问题 这比仅仅记忆语法更能解决问题...编程 发布于2024-11-03
-
你并不孤单:在社区的支持下掌握 Python加入 Python 社区可获得:社区论坛:向经验丰富的开发者获取支持和建议(如 Stack Overflow)。Discord 服务器:实时聊天室,提供即时支持和指导(如 Python Discord)。在线课程和研讨会:来自专家的指导,涵盖各种主题(如 Udemy 上的 Python NumPy ...编程 发布于2024-11-03
-
前端开发 + 数据结构和算法:DSA 如何为您的 React 应用程序提供动力 ⚡专注于前端的面试通常根本不关心 DSA。 对于我们这些记得在学校/大学学习过 DSA 的人来说,所有的例子都感觉纯粹是算法(有充分的理由),但几乎没有任何例子或指导来说明我们每天使用的产品如何利用这个概念。 “我需要这个吗?” 你已经问过很多次这个问题了,不是吗? ? 以下是您今天可以在 React...编程 发布于2024-11-03
-
为什么表行上的框阴影在不同浏览器中表现不同?跨浏览器表行上的框阴影外观不一致应用于表行 () 的 CSS 框阴影可能表现出不一致的行为跨各种浏览器。尽管 CSS 相同,但某些浏览器可能会按预期显示阴影,而其他浏览器则可能不会。要解决此问题,建议将 Transform 属性与 box-shadow 属性结合使用。将scale(1,1)添加到tr...编程 发布于2024-11-03
-
探索 PHP 中的并发性和并行性:实践教程和技巧理解并发性和并行性对于编写高效的 PHP 应用程序至关重要,特别是在处理需要同时处理的多个任务或操作时。这是理解和实现 PHP 并发性和并行性的分步指南,包含实践示例和说明。 1.并发与并行 并发:指系统通过交错执行同时处理多个任务的能力。这并不一定意味着任务是同时执行的,只是对它们...编程 发布于2024-11-03
-
ReactJs 与 AngularReact 和 Angular 是用于构建 Web 应用程序的两个最流行的框架/库,但它们在关键方面有所不同。以下是 React 和 Angular 之间主要区别的细分: 1. 类型:库与框架 React:一个用于构建用户界面的库,主要关注视图层。它允许开发人员将其与其他库集成以处理...编程 发布于2024-11-03
-
如何使用变量中存储的类名动态实例化 JavaScript 对象?使用动态类名实例化 JavaScript 对象假设您需要使用存储在变量中的类名实例化 JavaScript 对象。下面是一个说明性示例:// Define the class MyClass = Class.extend({}); // Store the class name in a strin...编程 发布于2024-11-03
-
Spring Boot 中的 OAuth 身份验证:Google 和 GitHub 登录集成指南使用 OAuth 2.0 增强安全性:在 Spring Boot 中实现社交登录 在现代 Web 开发的世界中,保护您的应用程序并使用户的身份验证尽可能顺利是首要任务。这就是 OAuth 2.0 的用武之地——它是一个强大的工具,不仅可以帮助保护您的 API,还可以让用户使用现有帐户从 Google...编程 发布于2024-11-03
-
热点图——巴西 vs 意大利世界杯决赛)在这篇文章中,我开始尝试使用 Python 和 Seaborn 和 Matplotlib 创建 1970 年世界杯决赛中巴西运动的热图 。这个想法是根据那场比赛的比赛风格特征来代表巴西队在场上占据的空间。 1. 绘制场地 场地设计为比例坐标(130x90),包括边线、球门区和中心圈,...编程 发布于2024-11-03
-
如何在 C++ 中连接字符串文字和字符文字?C 中的字符串文字和字符文字 尝试在 C 中连接字符串文字与字符文字时,可能会出现意外行为。例如:string str = "ab" 'c'; cout << str << endl;此代码会产生不可预测的输出,因为没有定义“”运算符来组合字符串文字和...编程 发布于2024-11-03
-
通过“Go 练习挑战”课程释放您的算法潜力通过 LabEx 的“Go Practice Challenges”课程踏上激动人心的旅程,提高您的编程技能。这门综合课程旨在帮助您掌握解决问题的艺术和提高编码效率,为您提供应对各种算法挑战的工具和技术。 深入算法世界 “围棋实践挑战”课程提供了一系列实际挑战,将突破您的算法思维界限...编程 发布于2024-11-03















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









