 首页 > 编程 > Amazon Aurora Serverless 的数据 API 与 AWS SDK for Java - 部分 Aurora Serverless vata API 是否满足 DevOps Guru?
首页 > 编程 > Amazon Aurora Serverless 的数据 API 与 AWS SDK for Java - 部分 Aurora Serverless vata API 是否满足 DevOps Guru?
Amazon Aurora Serverless 的数据 API 与 AWS SDK for Java - 部分 Aurora Serverless vata API 是否满足 DevOps Guru?
 浏览:542
浏览:542
介绍
在我的文章《适用于无服务器应用程序的 Amazon DevOps Guru - 第 10 部分 Aurora Serverless v2 上的异常检测》中,我们了解到,在使用 Java 21 托管的 Lambda 函数的情况下,DevOps Guru 能够成功检测 Aurora (Serverless v2) PostgreSQL 数据库的异常情况运行时通过 JDBC 连接到它。我们仅将数据库从 0.5 ACU 扩展到 1 ACU,并通过调用 Lambda 函数在数分钟内同时按 id 数百次检索产品,在数据库上创建了非常高的负载。我们看到 DevOps Guru 正确指出了数据库连接总数的增加和数据库 (CPU) 负载持续较高的情况。 在本文中,我想弄清楚 DevOps Guru 是否会通过执行相同的实验来检测异常,但使用 Aurora Serverless v2 的数据 API 和 AWS SDK for Java 而不是 JDBC。
使用数据 API 对 Aurora Serverless v2 进行异常检测
让我们看看我们的示例应用程序并使用 SAM 模板来创建基础架构并部署下图所示的应用程序:
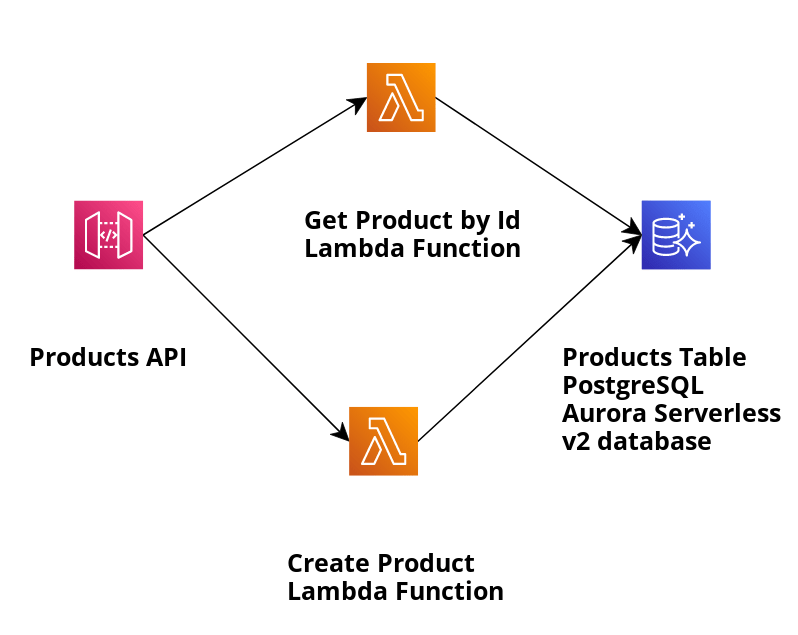
该应用程序创建存储在 Aurora Serverless v2 PostgreSQL 数据库中的产品,并使用数据 API 按 ID 检索它们。我们将用来按 id 检索产品的相关 Lambda 函数是 GetProductByIdViaAuroraServerlessV2DataApi,其处理程序实现是 GetProductByIdViaAuroraServerlessV2DataApiHandler。
和上一篇文章一样,我们使用hey工具来进行这样的压力测试
hey -z 15m -c 300 -H "X-API-Key: XXXa6XXXX" https://XXX.execute-api.eu-central-1.amazonaws.com/prod/productsWithDataApi/1
在此示例中,我们使用 300 个并发容器调用 API 网关端点 15 分钟。在 prod/productsWithoutDataApi 端点后面,将调用 Lambda 函数 GetProductByIdViaAuroraServerlessV2WithoutDataApi,它将通过 id 1 从 Aurora Serverless v2 PostgreSQL 数据库检索产品。
我们在 [SAM 模板]((https://github.com/Vadym79/AWSLambdaJavaAuroraServerlessV2DataApi/blob/master/template.yaml) Aurora 数据库集群中进行配置,从最小容量 0.5 扩展到最大容量 1 ACU(即非常小的数据库大小),以防增加负载以节省成本。
AuroraServerlessV2Cluster:
Type: 'AWS::RDS::DBCluster'
...
ServerlessV2ScalingConfiguration:
MinCapacity: 0.5
MaxCapacity: 1
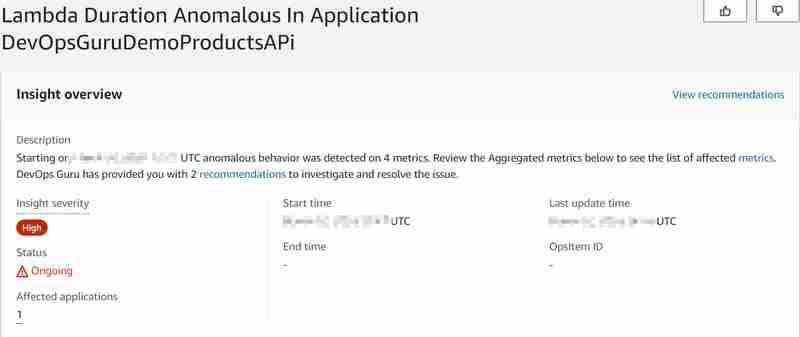
Aurora(无服务器 v2)数据库管理可用数据库连接的最大数量,与数据库大小(在我们的例子中是 ACU 设置)成比例,还使用 Aurora Serverless v2 的数据 API(这与 v1 存在巨大差异,v1 将成为到 2024 年底将不再支持,硬配额为每秒 1000 个数据库连接)。有关更多信息,请阅读有关 Aurora Serverless v2 的最大连接数的文档。因此,随着调用次数的增加,我们预计很快就会达到最大可用数据库连接数和高数据库 (CPU) 负载,这样数据库将无法响应新的 Lambda 函数请求来检索产品id(Lambda 也会遇到)。 这样我们就会引发异常,并想知道 DevOps Guru 是否能够检测到它。它能够,有点......产生了以下见解:
并且已识别出以下聚合异常指标:
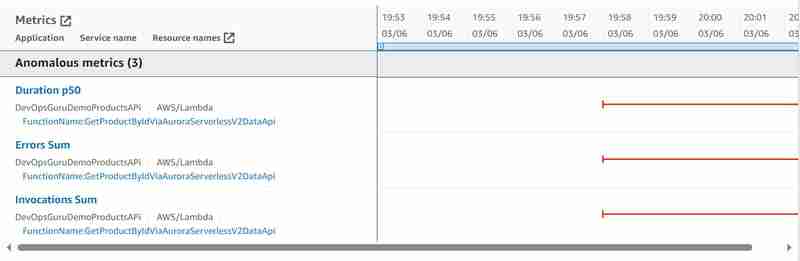
与我的文章 Amazon DevOps Guru for the Serverless applications - 第 10 部分 Aurora Serverless v2 上的异常检测中描述的使用 JDBC 而不是 Data API 时识别的聚合异常指标相比,我们完全搞乱了 Aurora 数据库异常指标:数据库连接总和和数据库 (CPU) 负载,但正确地看到 Lambda 中的错误,该错误运行到 15 秒定义的时间,因为数据库无法 回应。
 .
.
那么,有什么区别呢? 让我们探讨一下我们使用 JDBC(非数据 API)和数据 API 在 Aurora Serverless v2 PostgreSQL 集群上重现的两个事件:
就 ACU 利用率/扩展而言,它们看起来相同:
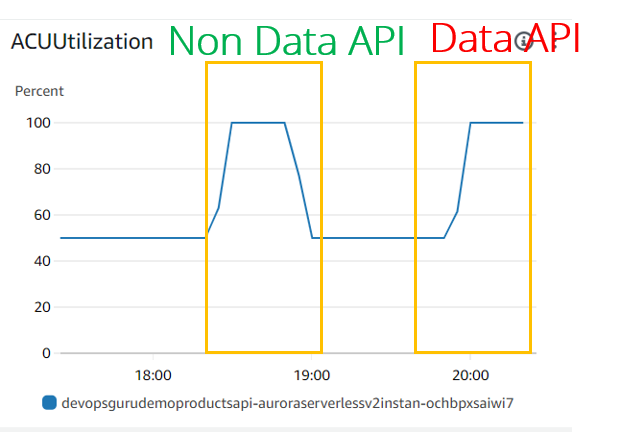
就其他数据库指标而言,例如:CPU 利用率、DatabaseConnection DBLoad(CPU),存在巨大差异:
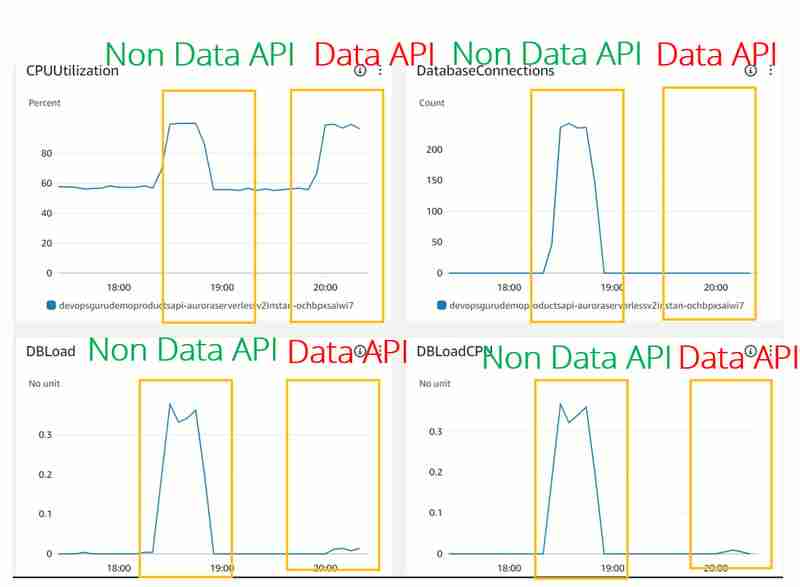
- 对于 JDBC(非数据 API)和数据 API 情况,CPU 利用率看起来相同。但 DevOps Guru 似乎没有考虑这个指标,因为我们甚至没有在 JDBC 实验中看到它
- DBLoad(CPU) 对于数据 API 使用率来说非常低。似乎对于 Dat API,Aurora Serverless v2 数据库前面有一些负载均衡器,用于监视连接使用情况并保护数据库免于过载。
- 对于数据 API 使用情况,DatabaseConnection 指标未显示(或显示为 0)。原因是我们不管理 Data API 的数据库连接,它是在另一端为我们完成的。当然,它们仍然发挥着我们在 Aurora Serverless v2 的最大连接数中了解到的重要作用,但该指标似乎在 CloudWatch 指标中暴露于外部,甚至 DevOps Guru 也无法访问真实数字。
由于这一点以及非常低的 DBLoad(CPU),与 JDBC 用例相比,没有生成针对具有数据 API 使用情况的 Aurora Serverless v2 集群的 DevOps Guru 见解。
我做了第二个实验,直接连接到 Aurora Serverless v2 集群,并编写脚本来创建负载测试,方法是使用标准方式(非数据 API)编写通过 id 多次获取产品的脚本。与我们对 hey 工具所做的类似,但直接访问数据库而不是调用 Api Gateway。在将数据库置于负载之下后,我使用如上所述的 hey 工具开始了相同的实验,并想看看会发生什么。产生了相同的见解,但这次具有以下异常指标:
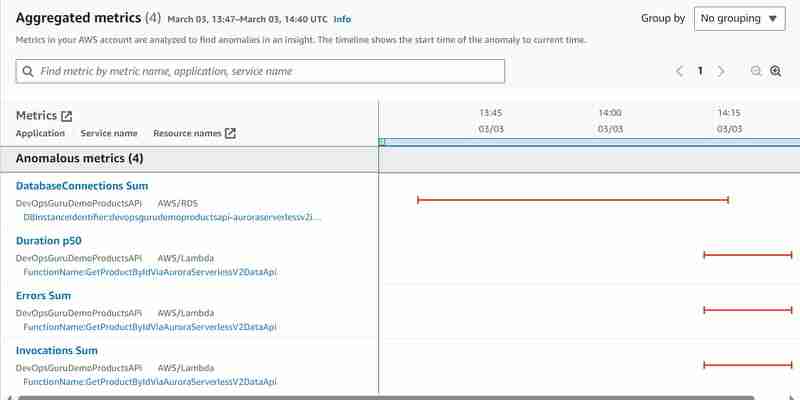
现在我们至少看到了额外的 Aurora Serverless v2 数据库连接总和异常指标,但 DBLoad(CPU) 指标仍然缺失。
异常图形如下所示:
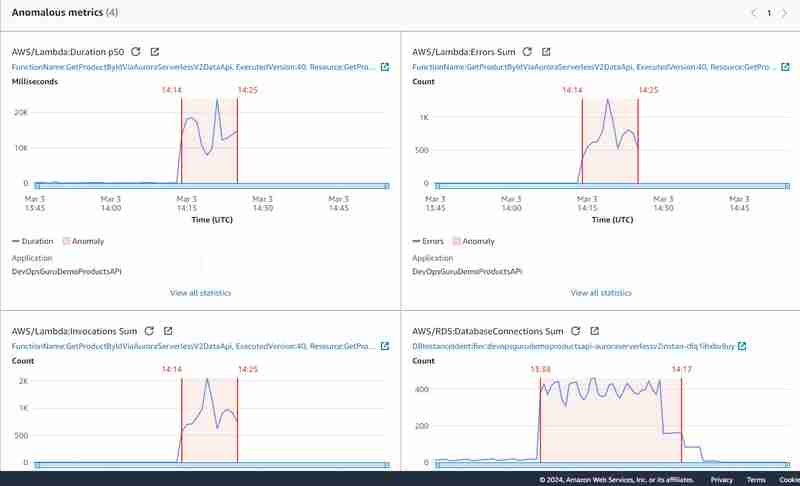
当然,这个实验并不干净,因为我相继进行了两次负载测试,并且部分是并行的:第一个测试直接连接到数据库而不使用 API Gateway,第二个测试使用 Data API。这证实了我最初的假设,即数据库连接总和指标是为 Aurora Serverless v2(以及一般的 RDS)生成 DevOps Guru 见解的非常重要的标准,并且在使用数据 API 的情况下通常不会公开。
我已经联系了 Devops Guru 团队并与他们分享了我的见解,希望他们能够改进服务。或者首先将修复将数据库连接公开为 CloudWatch 指标,以便将 Aurora Serverless v2 与数据 API 结合使用。
结论
在本文中了解到,如果 Lambda 函数通过数据 API 连接到 Java 21 托管运行时,DevOps Guru 可以成功检测 Aurora (Serverless v2) PostgreSQL 数据库的异常,但只能显示与 Lambda 函数相关的异常指标由于数据库没有响应而超时。其主要原因似乎是,在将 Aurora Serverless v2 与数据 API 结合使用时,作为 CloudWatch 指标的数据库连接不会公开(或始终显示为 0)。 Aurora Serverless v2 数据库指标(数据库连接总数)仅在第二次人工实验期间显示。
-
 Go语言如何动态发现导出包类型?与反射软件包中的有限类型的发现能力相反,本文探索了替代方法,探索了在Runruntime。go import( “ FMT” “去/进口商” ) func main(){ pkg,err:= incorter.default()。导入(“ time”) 如果err...编程 发布于2025-07-13
Go语言如何动态发现导出包类型?与反射软件包中的有限类型的发现能力相反,本文探索了替代方法,探索了在Runruntime。go import( “ FMT” “去/进口商” ) func main(){ pkg,err:= incorter.default()。导入(“ time”) 如果err...编程 发布于2025-07-13 -
JavaScript计算两个日期之间天数的方法How to Calculate the Difference Between Dates in JavascriptAs you attempt to determine the difference between two dates in Javascript, consider this s...编程 发布于2025-07-13
-
如何使用FormData()处理多个文件上传?)处理多个文件输入时,通常需要处理多个文件上传时,通常是必要的。 The fd.append("fileToUpload[]", files[x]); method can be used for this purpose, allowing you to send multi...编程 发布于2025-07-13
-
解决Spring Security 4.1及以上版本CORS问题指南弹簧安全性cors filter:故障排除常见问题 在将Spring Security集成到现有项目中时,您可能会遇到与CORS相关的错误,如果像“访问Control-allo-allow-Origin”之类的标头,则无法设置在响应中。为了解决此问题,您可以实现自定义过滤器,例如代码段中的MyFi...编程 发布于2025-07-13
-
Python高效去除文本中HTML标签方法在Python中剥离HTML标签,以获取原始的文本表示 仅通过Python的MlStripper 来简化剥离过程,Python Standard库提供了一个专门的功能,MLSTREPERE,MLSTREPERIPLE,MLSTREPERE,MLSTREPERIPE,MLSTREPERCE,MLST...编程 发布于2025-07-13
-
如何使用Python理解有效地创建字典?在python中,词典综合提供了一种生成新词典的简洁方法。尽管它们与列表综合相似,但存在一些显着差异。与问题所暗示的不同,您无法为钥匙创建字典理解。您必须明确指定键和值。 For example:d = {n: n**2 for n in range(5)}This creates a dicti...编程 发布于2025-07-13
-
如何干净地删除匿名JavaScript事件处理程序?删除匿名事件侦听器将匿名事件侦听器添加到元素中会提供灵活性和简单性,但是当要删除它们时,可以构成挑战,而无需替换元素本身就可以替换一个问题。 element? element.addeventlistener(event,function(){/在这里工作/},false); 要解决此问题,请考虑...编程 发布于2025-07-13
-
Spark DataFrame添加常量列的妙招在Spark Dataframe ,将常数列添加到Spark DataFrame,该列具有适用于所有行的任意值的Spark DataFrame,可以通过多种方式实现。使用文字值(SPARK 1.3)在尝试提供直接值时,用于此问题时,旨在为此目的的column方法可能会导致错误。 df.withCo...编程 发布于2025-07-13
-
\“(1)vs.(;;):编译器优化是否消除了性能差异?\”答案: 在大多数现代编译器中,while(1)和(1)和(;;)之间没有性能差异。编译器: perl: 1 输入 - > 2 2 NextState(Main 2 -E:1)V-> 3 9 Leaveloop VK/2-> A 3 toterloop(next-> 8 last-> 9 ...编程 发布于2025-07-13
-
如何使用node-mysql在单个查询中执行多个SQL语句?Multi-Statement Query Support in Node-MySQLIn Node.js, the question arises when executing multiple SQL statements in a single query using the node-mys...编程 发布于2025-07-13
-
eval()vs. ast.literal_eval():对于用户输入,哪个Python函数更安全?称量()和ast.literal_eval()中的Python Security 在使用用户输入时,必须优先确保安全性。强大的python功能eval()通常是作为潜在解决方案而出现的,但担心其潜在风险。本文深入研究了eval()和ast.literal_eval()之间的差异,突出显示其安全性含义...编程 发布于2025-07-13
-
左连接为何在右表WHERE子句过滤时像内连接?左JOIN CONUNDRUM:WITCHING小时在数据库Wizard的领域中变成内在的加入很有趣,当将c.foobar条件放置在上面的Where子句中时,据说左联接似乎会转换为内部连接。仅当满足A.Foo和C.Foobar标准时,才会返回结果。为什么要变形?关键在于其中的子句。当左联接的右侧值...编程 发布于2025-07-13
-
Java中如何使用观察者模式实现自定义事件?在Java 中创建自定义事件的自定义事件在许多编程场景中都是无关紧要的,使组件能够基于特定的触发器相互通信。本文旨在解决以下内容:问题语句我们如何在Java中实现自定义事件以促进基于特定事件的对象之间的交互,定义了管理订阅者的类界面。以下代码片段演示了如何使用观察者模式创建自定义事件: args)...编程 发布于2025-07-13
-
如何在Java字符串中有效替换多个子字符串?在java 中有效地替换多个substring,需要在需要替换一个字符串中的多个substring的情况下,很容易求助于重复应用字符串的刺激力量。 However, this can be inefficient for large strings or when working with nu...编程 发布于2025-07-13
-















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









