
比较优化如何使 Python 排序更快
 浏览:922
浏览:922
在本文中,术语 Python 和 CPython(该语言的参考实现)可以互换使用。本文专门讨论 CPython,不涉及 Python 的任何其他实现。
Python 是一种美丽的语言,它允许程序员用简单的术语表达他们的想法,而将实际实现的复杂性抛在脑后。
它抽象出来的事情之一就是排序。
“Python中排序是如何实现的?”这个问题你可以轻松找到答案。这几乎总是回答另一个问题:“Python 使用什么排序算法?”。
然而,这通常会留下一些有趣的实现细节。
有一个实现细节我认为讨论得不够充分,尽管它是七年前在 python 3.7 中引入的:
sorted() 和 list.sort() 已针对常见情况进行了优化,速度提高了 40-75%。 (由 Elliot Gorokhovsky 在 bpo-28685 中贡献。)
但是在我们开始之前...
简要重新介绍 Python 中的排序
当你需要在python中对列表进行排序时,你有两个选择:
- 列表方法:list.sort(*, key=None, reverse=False),对给定列表进行就地排序
- 内置函数:sorted(iterable、/、*、key=None、reverse= False),返回排序列表而不修改其参数
如果需要对任何其他内置迭代进行排序,则无论作为参数传递的迭代或生成器的类型如何,都只能使用排序。
sorted 总是返回一个列表,因为它内部使用了 list.sort。
这是用纯 python 重写的 CPython 排序 C 实现的大致等效项:
def sorted(iterable: Iterable[Any], key=None, reverse=False):
new_list = list(iterable)
new_list.sort(key=key, reverse=reverse)
return new_list
是的,就这么简单。
Python 如何使排序更快
正如 Python 的内部排序文档所说:
有时可以用更快的特定类型比较来代替较慢的通用 PyObject_RichCompareBool
简单来说,这个优化可以描述如下:
当列表是同质的时,Python 使用特定于类型的比较函数
什么是同质列表?
同类列表是仅包含一种类型的元素的列表。
例如:
homogeneous = [1, 2, 3, 4]
另一方面,这不是一个同类列表:
heterogeneous = [1, "2", (3, ), {'4': 4}]
有趣的是,Python官方教程指出:
列表是可变的,并且它们的元素通常是同质的并且通过迭代列表来访问
关于元组的旁注
同一个教程指出:
元组是不可变的,并且通常包含元素的异构序列
因此,如果您想知道何时使用元组或列表,这里有一条经验法则:
如果元素具有相同类型,则使用列表,否则使用元组
等等,那么数组呢?
Python 实现了数值的同构数组容器对象。
但是,从 python 3.12 开始,数组没有实现自己的排序方法。
对它们进行排序的唯一方法是使用排序,它在内部从数组中创建一个列表,并删除该过程中任何与类型相关的信息。
为什么使用特定于类型的比较函数有帮助?
Python 中的比较成本很高,因为 Python 在进行任何实际比较之前会执行各种检查。
以下是在 python 中比较两个值时底层发生的情况的简化解释:
- Python 检查传递给比较函数的值是否不为 NULL
- 如果值的类型不同,但右操作数是左操作数的子类型,Python 使用右操作数的比较函数,但相反(例如,它将使用 )
- 如果值具有相同类型或不同类型但都不是另一个的子类型:
- Python将首先尝试左操作数的比较函数
- 如果失败,它将尝试右操作数的比较函数,但相反。
- 如果也失败,并且比较是相等或不相等,它将返回身份比较(对于引用内存中同一对象的值为 True)
- 否则,会引发 TypeError
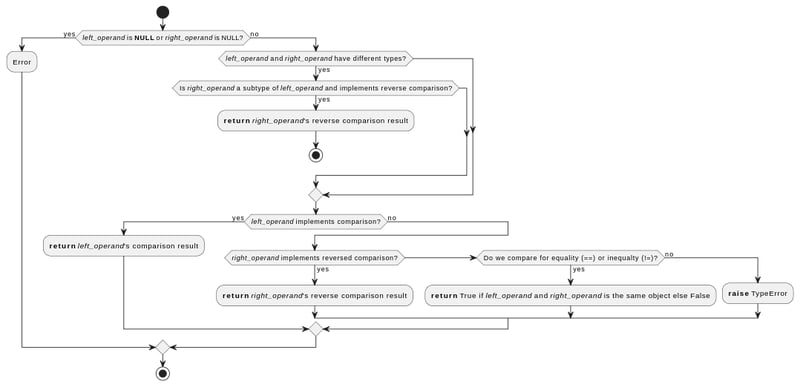
除此之外,每种类型自己的比较函数都会实现额外的检查。
例如,在比较字符串时,Python 会检查字符串字符是否占用超过一个字节的内存,而 float 比较会以不同的方式比较一对 float 以及一个 float 和一个 int。
更详细的解释和图表可以在这里找到:Adding Data-Aware Sort Optimizations to CPython
在引入此优化之前,每次在排序过程中比较两个值时,Python 都必须执行所有这些各种类型特定和非类型特定检查。
提前检查列表元素的类型
除了迭代列表并检查每个元素之外,没有什么神奇的方法可以知道列表中的所有元素是否属于同一类型。
Python 几乎完全做到了这一点 - 检查传递给 list.sort 或作为参数排序的 key 函数生成的排序键的类型
构建键列表
如果提供了 key 函数,Python 使用它来构造键列表,否则它使用列表自己的值作为排序键。
以一种过于简单的方式,键构造可以表示为以下 python 代码。
if key is None:
keys = list_items
else:
keys = [key(list_item) for list_item in list_item]
注意,CPython 内部使用的键是 CPython 对象引用的 C 数组,而不是 Python 列表
一旦构造了键,Python 就会检查它们的类型。
检查密钥类型
检查键的类型时,Python 的排序算法会尝试确定键数组中的所有元素是否都是 str、int、float 或 tuple,或者只是同一类型,但对基本类型有一些限制。
值得注意的是,检查键的类型会预先增加一些额外的工作。 Python 这样做是因为它通常可以通过加快实际排序速度来获得回报,特别是对于较长的列表。
整型约束
int 应该不是bignum
实际上,这意味着要使此优化发挥作用,整数应小于 2^30 - 1(这可能因平台而异)
作为旁注,这里有一篇很棒的文章,解释了 Python 如何处理大整数:# How python Implements super long integers?
强度约束
字符串中的所有字符应占用小于 1 个字节的内存,这意味着它们应由 0-255 范围内的整数值表示
实际上,这意味着字符串应仅包含拉丁字符、空格和 ASCII 表中的一些特殊字符。
浮动约束
为了使此优化发挥作用,浮点数没有任何限制。
元组约束
- 仅检查第一个元素的类型
- 这个元素本身不应该是一个元组
- 如果所有元组的第一个元素具有相同的类型,则比较优化将应用于它们
- 所有其他元素照常比较
我如何应用这些知识?
首先,了解一下是不是很有趣?
其次,在 Python 开发者面试中提及这些知识可能是一个很好的接触。
对于实际的代码开发来说,了解这个优化可以帮助你提高排序性能。
通过明智地选择值类型进行优化
根据引入此优化的 PR 中的基准,对仅由浮点数组成的列表进行排序,而不是对末尾带有单个整数的浮点数列表进行排序,速度几乎快两倍。
所以当需要优化时,像这样转换列表
floats_and_int = [1.0, -1.0, -0.5, 3]
进入看起来像这样的列表
just_floats = [1.0, -1.0, -0.5, 3.0] # note that 3.0 is a float now
可能会提高性能。
使用对象列表的键进行优化
虽然 Python 的排序优化适用于内置类型,但了解它如何与自定义类交互也很重要。
对自定义类的对象进行排序时,Python 依赖于您定义的比较方法,例如 __lt__(小于)或 __gt__(大于)。
但是,特定于类型的优化不适用于自定义类。
Python 将始终对这些对象使用通用比较方法。
这是一个例子:
class MyClass:
def __init__(self, value):
self.value = value
def __lt__(self, other):
return self.value
在这种情况下,Python 将使用 __lt__ 方法进行比较,但它不会从特定于类型的优化中受益。排序仍然可以正常工作,但可能不如排序内置类型那么快。
如果在对自定义对象进行排序时性能至关重要,请考虑使用返回内置类型的关键函数:
sorted_list = sorted(my_list, key=lambda x: x.value)
后记
过早的优化,尤其是在 Python 中,是邪恶的。
您不应该围绕 CPython 中的特定优化来设计整个应用程序,但了解这些优化是有好处的:充分了解您的工具是成为更熟练的开发人员的一种方式。
留意此类优化可以让您在情况需要时利用它们,特别是当性能变得至关重要时:
考虑一个场景,其中您的排序基于时间戳:使用同质整数列表(Unix 时间戳)而不是日期时间对象可以有效地利用此优化。
但是,重要的是要记住,代码的可读性和可维护性应优先于此类优化。
虽然了解这些低级细节很重要,但欣赏 Python 的高级抽象也同样重要,正是这些抽象使其成为一种高效的语言。
Python 是一门令人惊叹的语言,探索其深度可以帮助您更好地理解它并成为一名更好的 Python 程序员。
-
 NextJS 应用程序的 Docker 和 Docker-Compose 最佳实践。Best Practices of Docker & Docker-Compose for NextJS application. To create an optimized Dockerfile for a Next.js 14 application that sup...编程 发布于2024-11-07
NextJS 应用程序的 Docker 和 Docker-Compose 最佳实践。Best Practices of Docker & Docker-Compose for NextJS application. To create an optimized Dockerfile for a Next.js 14 application that sup...编程 发布于2024-11-07 -
数据结构:创建自定义节点类作为一名开发人员,掌握数据结构是一项至关重要的技能,可以释放您解决问题的潜力。虽然 Java 中的标准集合框架提供了坚实的基础,但有时您需要超越内置数据结构并创建自己的自定义解决方案。 在这篇文章中,我们将学习如何创建自定义节点类以及它们如何帮助您有效地解决各种问题。 DATA STRUCTURE...编程 发布于2024-11-07
-
通过专家免费课程掌握编程欢迎来到我的 Udemy 个人资料!如果您对编程充满热情并渴望提高自己的技能,那么您来对地方了。我设计了适合初学者和高级学习者的课程,确保每节课都充满实践知识和实践经验。 您可以期待什么: 内容全面:从基本编程概念到高级算法,我的课程涵盖广泛的主题,适合各个级别。 实践项目:通过实际项目进行学习,这...编程 发布于2024-11-07
-
瓦纳卡aa eyyyy`` 这是我网站的顶部栏或所谓的导航栏。 但事实就是如此。 我们会没事的吧? Ul 检查。 const paymentMethods = [ { supportedMethods: 'basic-card', data: { ...编程 发布于2024-11-07
-
如何使用 CSS 在单个元素上实现多个阴影?使用 CSS 在元素上实现多个阴影尝试在 CSS 中重新创建 Photoshop 按钮设计,您可能会在将多个框阴影应用到一个元素时遇到限制。单一元素。默认情况下,CSS 只允许一个活动的盒子阴影,无论是内部还是外部。要克服这一限制,您可以利用 CSS3 提供的逗号分隔功能。这允许您在同一 box-s...编程 发布于2024-11-07
-
Tailwind CSS 简介 – 实用程序优先的框架Tailwind CSS 简介 – 实用程序优先的框架 在本文中,我们将探索 Tailwind CSS,这是一种流行的实用程序优先 CSS 框架,可让您快速构建现代网站,而无需编写自定义 CSS。与传统的 CSS 框架不同,Tailwind 不附带预先设计的组件,而是提供实用程序类...编程 发布于2024-11-07
-
-
如何使用 jQuery 确定 HTML 元素是否为空?使用 jQuery 查找空 HTML 元素如果您需要在 Web 应用程序中确定 HTML 元素是否为空,jQuery 提供了方便的方法这样做的方法。以下是使用 jQuery 完成此操作的方法:使用 is(':empty') 选择器:is(':empty') 选择器检查...编程 发布于2024-11-07
-
如何在非集成网站的 JavaScript 控制台中包含 jQuery?在 JavaScript 控制台中包含 jQuery在 JavaScript 控制台中包含 jQuery 对于缺乏集成的网站来说是有益的。这使得开发人员能够利用 jQuery 的功能,例如检索表中的行数,甚至在本身不支持 jQuery 的网站上也是如此。要在 JavaScript 控制台中包含 jQ...编程 发布于2024-11-07
-
尽管使用了有效的 INSERT 语句,为什么我的 JDBC 代码仍会抛出 MySQLSyntaxErrorException?JDBC Exception: MySQLSyntaxError with Valid SQL Statement在本文中,我们深入研究使用 JDBC 向数据库插入数据时遇到的问题。 MySQL 数据库。尽管在 MySQL Workbench 中执行了有效的 INSERT 语句,我们还是收到了 My...编程 发布于2024-11-07
-
如何使用数组函数按列值比较对象数组?使用数组函数按列值比较对象数组许多编程语言都提供用于比较数组的内置函数。但是,这些函数通常使用原始数据类型和数组,而不是对象数组。这就提出了如何根据特定属性或列来比较对象数组的问题。为了解决这个问题,PHP 提供了 array_udiff,该函数可以通过指定自定义比较函数来比较对象数组。考虑以下示例...编程 发布于2024-11-07
-
React 的 useEffect Hook 简化:像专业人士一样管理副作用了解 React 中的 useEffect:从零到英雄 React 已成为构建动态用户界面最流行的 JavaScript 库之一。 React 中最重要的钩子之一是 useEffect,它允许开发人员管理功能组件中的副作用。副作用包括获取数据、设置订阅或手动操作 DOM 等操作。在...编程 发布于2024-11-07
-
扩展 Node.js 应用程序:技术、工具和最佳实践随着 Node.js 应用程序的增长,对更好的性能和可扩展性的需求也在增加。 Node.js 旨在处理大规模数据密集型应用程序,但了解如何正确扩展它对于在负载下保持性能和可用性至关重要。在本文中,我们将介绍有效扩展 Node.js 应用程序的关键技术和工具。 为什么要扩展 Node....编程 发布于2024-11-07
-
使用 PHP 的动态图像画廊:在线展示您的作品使用PHP创建动态图像画廊的步骤:安装依赖项:PHP GD库和(可选)ImageMagick。创建画廊页面:循环遍历要显示的图像并生成缩略图(使用createThumbnail()函数)。输出图像缩略图:使用HTML创建一个无序列表来显示缩略图。添加其他功能(可选):分页、排序、过滤、上传表单和灯箱...编程 发布于2024-11-07
-
学习 CSS:我设计网页样式的第一步从周一到今天,我向前迈出了重要的一步,深入研究了 CSS,一种融入网页的样式语言。 ? 首先学习基础知识——选择器、代码块、声明及其值。看到几行代码如何将纯 HTML 转换为具有视觉吸引力的内容是令人兴奋的。在 CSS 中,样式可以通过三种方式实现:内联样式(通过在开始标记中添加 style 属性)...编程 发布于2024-11-07















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









