Os dados climáticos desempenham um papel crucial em diversos setores, auxiliando em estudos e previsões que impactam áreas como agricultura, planejamento urbano, e gestão de recursos naturais.
O Instituto Nacional de Meteorologia (INMET) oferece, mensalmente, o Banco de Dados Meteorológicos (BDMEP) em seu site. Este banco de dados contém uma série histórica de informações climáticas coletadas por centenas de estações de medição distribuídas por todo o Brasil. No BDMEP, você encontrará dados detalhados sobre pluviometria, temperatura, umidade do ar e velocidade do vento.
Com atualizações horárias, esses dados são bastante volumosos, proporcionando uma base rica para análises detalhadas e tomadas de decisão informadas.
Neste post vou mostrar como coletar e tratar os dados climáticos do INMET-BDMEP. Vamos coletar os arquivos de dados brutos disponíveis no site do INMET e depois vamos tratar esses dados para facilitar a análise.
1. Pacotes Python necessários
Para alcançar os objetivos mencionados será preciso ter instalado apenas três pacotes:
httpx para fazer as requisições HTTP
Pandas para a leitura e tratamento dos dados
tqdm para mostrar uma barra de progresso amigável no terminal enquanto o programa baixa ou lê os arquivos
Para instalar os pacotes necessários execute o seguinte comando no terminal:
pip install httpx pandas tqdm
Se estiver usando um ambiente virtual (venv) com poetry, por exemplo, use o seguinte comando:
poetry add httpx pandas tqdm
2. Coleta dos arquivos
2.1 Padrão da URL dos arquivos
O endereço dos arquivos de dados do BDMEP seguem um padrão bem simples. O padrão é o seguinte:
A única parte que muda é o nome do arquivo que é, simplesmente, o ano de referência dos dados. Mensalmente, o arquivo para o ano mais recente (corrente) é substituído com dados atualizados.
Assim fica fácil criar um código para coletar automaticamente os arquivos de dados de todos os anos disponíveis.
Aliás, a série histórica disponível começa no ano 2000.
2.2 Estratégia de coleta
Para a coleta dos arquivos de dados do INMET-BDMEP vamos usar a biblioteca httpx para fazer as requisições HTTP e a biblioteca tqdm para mostrar uma barra de progresso amigável no terminal.
Primeiro, vamos importar os pacotes necessários:
import datetime as dt
from pathlib import Path
import httpx
from tqdm import tqdm
Já identificamos o padrão da URL dos arquivos de dados do INMET-BDMEP. Agora vamos criar uma função que aceita um ano como argumento e devolve a URL do arquivo referente a esse ano.
Para checar se o arquivo da URL foi atualizado podemos utilizar a informação presente no cabeçalho retornado por uma requisição HTTP. Em servidores bem configurados, podemos pedir apenas esse cabeçalho com o método HEAD. Nesse o servidor foi bem configurado e podemos usar desse método.
A resposta à requisição HEAD terá o seguinte formato:
Mon, 01 Sep 2024 00:01:00 GMT
Para parsear essa data/hora fiz a seguinte função em Python, que aceita uma string e devolve um objeto datetime:
Dessa forma, é possível verificar facilmente se o arquivo com os dados mais recentes já existe no nosso sistema de arquivos local. Se o arquivo já existir, o programa pode ser encerrado; caso contrário, devemos prosseguir com a coleta do arquivo, fazendo a requisição ao servidor.
A função download_year abaixo faz o download do arquivo referente a um ano específico. Se o arquivo já existe no diretório de destino, a função simplesmente retorna sem fazer nada.
Note como usamos o tqdm para mostrar uma barra de progresso amigável no terminal enquanto o arquivo é baixado.
def download_year(
year: int,
destdirpath: Path,
blocksize: int = 2048,
) -> None:
if not destdirpath.exists():
destdirpath.mkdir(parents=True)
url = build_url(year)
headers = httpx.head(url).headers
last_modified = parse_last_modified(headers["Last-Modified"])
file_size = int(headers.get("Content-Length", 0))
destfilename = build_local_filename(year, last_modified)
destfilepath = destdirpath / destfilename
if destfilepath.exists():
return
with httpx.stream("GET", url) as r:
pb = tqdm(
desc=f"{year}",
dynamic_ncols=True,
leave=True,
total=file_size,
unit="iB",
unit_scale=True,
)
with open(destfilepath, "wb") as f:
for data in r.iter_bytes(blocksize):
f.write(data)
pb.update(len(data))
pb.close()
2.3 Coleta dos arquivos
Agora que temos todas as funções necessárias, podemos fazer a coleta dos arquivos de dados do INMET-BDMEP.
Usando um loop for podemos baixar os arquivos de todos os anos disponíveis. O código a seguir faz exatamente isso. Começando do ano 2000 até o ano corrente.
destdirpath = Path("data")
for year in range(2000, dt.datetime.now().year 1):
download_year(year, destdirpath)
3. Leitura e tratamento dos dados
Com os arquivos de dados brutos do INMET-BDMEP baixados, agora podemos fazer a leitura e o tratamento dos dados.
Vamos importar os pacotes necessários:
import csv
import datetime as dt
import io
import re
import zipfile
from pathlib import Path
import numpy as np
import pandas as pd
from tqdm import tqdm
3.1 Estrutura dos arquivos
Dentro do arquivo ZIP disponibilizado pelo INMET encontramos diversos arquivos CSV, um para cada estação meteorológica.
Porém, nas primeiras linhas desses arquivos CSV encontramos informações sobre a estação, como a região, a unidade federativa, o nome da estação, o código WMO, as coordenadas geográficas (latitude e longitude), a altitude e a data de fundação. Vamos extrair essas informações para usar como metadados.
3.2 Leitura dos dados com pandas
A leitura dos arquivos será feita em duas partes: primeiro, será feita a leitura dos metadados das estações meteorológicas; depois, será feita a leitura dos dados históricos propriamente ditos.
3.2.1 Metadados
Para extrair os metadados nas primeiras 8 linhas do arquivo CSV vamos usar o pacote embutido csv do Python.
Para entender a função a seguir é necessário ter um conhecimento um pouco mais avançado de como funciona handlers de arquivos (open), iteradores (next) e expressões regulares (re.match).
Em resumo, a função read_metadata definida acima lê as primeiras oito linhas do arquivo, processa os dados e retorna um dicionário com as informações extraídas.
3.2.2 Dados históricos
Aqui, finalmente, veremos como fazer a leitura do arquivo CSV. Na verdade é bastante simples. Basta usar a função read_csv do Pandas com os argumentos certos.
A seguir está exposto a chamada da função com os argumentos que eu determinei para a correta leitura do arquivo.
Primeiro é preciso dizer que o caractere separador das colunas é o ponto-e-vírgula (;), o separador de número decimal é a vírgula (,) e o encoding é latin-1, muito comum no Brasil.
Também é preciso dizer para pular as 8 primeiras linhas do arquivo (skiprows=8), que contém os metadados da estação), e usar apenas as 19 primeiras colunas (usecols=range(19)).
Por fim, vamos considerar o valor -9999 como sendo nulo (na_values="-9999").
3.3 Tratamento dos dados
Os nomes das colunas dos arquivos CSV do INMET-BDMEP são bem descritivos, mas um pouco longos. E os nomes não são consistentes entre os arquivos e ao longo do tempo. Vamos renomear as colunas para padronizar os nomes e facilitar a manipulação dos dados.
A seguinte função será usada para renomear as colunas usando expressões regulares (RegEx):
def columns_renamer(name: str) -> str:
name = name.lower()
if re.match(r"data", name):
return "data"
if re.match(r"hora", name):
return "hora"
if re.match(r"precipita[çc][ãa]o", name):
return "precipitacao"
if re.match(r"press[ãa]o atmosf[ée]rica ao n[íi]vel", name):
return "pressao_atmosferica"
if re.match(r"press[ãa]o atmosf[ée]rica m[áa]x", name):
return "pressao_atmosferica_maxima"
if re.match(r"press[ãa]o atmosf[ée]rica m[íi]n", name):
return "pressao_atmosferica_minima"
if re.match(r"radia[çc][ãa]o", name):
return "radiacao"
if re.match(r"temperatura do ar", name):
return "temperatura_ar"
if re.match(r"temperatura do ponto de orvalho", name):
return "temperatura_orvalho"
if re.match(r"temperatura m[áa]x", name):
return "temperatura_maxima"
if re.match(r"temperatura m[íi]n", name):
return "temperatura_minima"
if re.match(r"temperatura orvalho m[áa]x", name):
return "temperatura_orvalho_maxima"
if re.match(r"temperatura orvalho m[íi]n", name):
return "temperatura_orvalho_minima"
if re.match(r"umidade rel\. m[áa]x", name):
return "umidade_relativa_maxima"
if re.match(r"umidade rel\. m[íi]n", name):
return "umidade_relativa_minima"
if re.match(r"umidade relativa do ar", name):
return "umidade_relativa"
if re.match(r"vento, dire[çc][ãa]o", name):
return "vento_direcao"
if re.match(r"vento, rajada", name):
return "vento_rajada"
if re.match(r"vento, velocidade", name):
return "vento_velocidade"
Agora que temos os nomes das colunas padronizados, vamos tratar a data/hora. Os arquivos CSV do INMET-BDMEP têm duas colunas separadas para data e hora. Isso é inconveniente, pois é mais prático ter uma única coluna de data/hora. Além disso existem inconsistências nos horários, que às vezes têm minutos e às vezes não.
As três funções a seguir serão usadas para criar uma única coluna de data/hora:
Existe um problema com os dados do INMET-BDMEP que é a presença de linhas vazias. Vamos remover essas linhas vazias para evitar problemas futuros. O código a seguir faz isso:
Tem um problema com a função acima. Ela não lida com arquivos ZIP.
Criamos, então, a função read_zipfile para a leitura de todos os arquivos contidos no arquivo ZIP. Essa função itera sobre todos os arquivos CSV no arquivo zipado, faz a leitura usando a função read_data e os metadados usando a função read_metadata, e depois junta os dados e os metadados em um único DataFrame.
def read_zipfile(filepath: Path) -> pd.DataFrame:
data = pd.DataFrame()
with zipfile.ZipFile(filepath) as z:
files = [zf for zf in z.infolist() if not zf.is_dir()]
for zf in tqdm(files):
d = read_data(z.open(zf.filename))
meta = read_metadata(z.open(zf.filename))
d = d.assign(**meta)
data = pd.concat((data, d), ignore_index=True)
return data
No final, basta usar essa última função definida (read_zipfile) para fazer a leitura dos arquivos ZIP baixados do site do INMET. (. ❛ ᴗ ❛.)
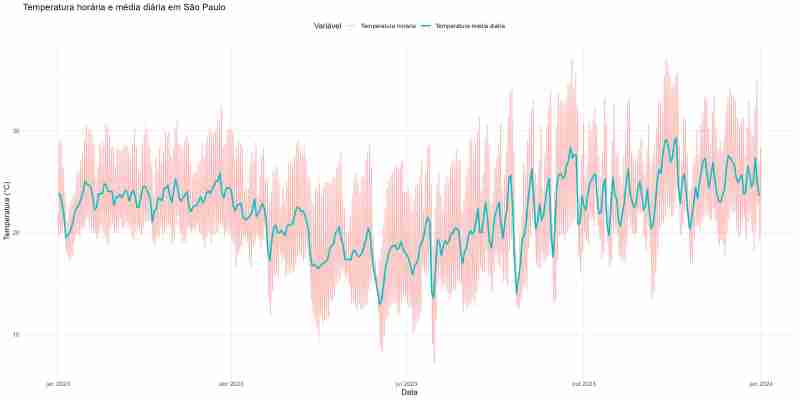
Para finalizar, nada mais satisfatório do que fazer gráficos com os dados que coletamos e tratamos. ヾ(≧▽≦*)o
Nessa parte uso o R com o pacote tidyverse para fazer um gráfico combinando a temperatura horária e a média diária em São Paulo.
library(tidyverse)
dados filter(uf == "SP")
# Temperatura horária em São Paulo
dados_sp_h
group_by(data_hora) |>
summarise(
temperatura_ar = mean(temperatura_ar, na.rm = TRUE),
)
# Temperatura média diária em São Paulo
dados_sp_d
group_by(data = floor_date(data_hora, "day")) |>
summarise(
temperatura_ar = mean(temperatura_ar, na.rm = TRUE),
)
# Gráfico combinando temperatura horária e média diária em São Paulo
dados_sp_h |>
ggplot(aes(x = data_hora, y = temperatura_ar))
geom_line(
alpha = 0.5,
aes(
color = "Temperatura horária"
)
)
geom_line(
data = dados_sp_d,
aes(
x = data,
y = temperatura_ar,
color = "Temperatura média diária"
),
linewidth = 1
)
labs(
x = "Data",
y = "Temperatura (°C)",
title = "Temperatura horária e média diária em São Paulo",
color = "Variável"
)
theme_minimal()
theme(legend.position = "top")
ggsave("temperatura_sp.png", width = 16, height = 8, dpi = 300)
Temperatura horária e média diária em São Paulo em 2023
5. Conclusão
Neste texto mostrei como coletar e tratar os dados climáticos do INMET-BDMEP. Os dados coletados são muito úteis para estudos e previsões nas mais variadas áreas. Com os dados tratados, é possível fazer análises e gráficos como o que mostrei no final.
Espero que tenha gostado do texto e que tenha sido útil para você.
Criei um pacote Python com as funções que mostrei neste texto. O pacote está disponível no meu repositório Git. Se quiser, pode baixar o pacote e usar as funções no seu próprio código.
在java 中有效地替换多个substring,需要在需要替换一个字符串中的多个substring的情况下,很容易求助于重复应用字符串的刺激力量。 However, this can be inefficient for large strings or when working with nu...

 浏览:532
浏览:532
 CSS强类型语言解析您可以通过其强度或弱输入的方式对编程语言进行分类的方式之一。在这里,“键入”意味着是否在编译时已知变量。一个例子是一个场景,将整数(1)添加到包含整数(“ 1”)的字符串: result = 1 "1";包含整数的字符串可能是由带有许多运动部件的复杂逻辑套件无意间生成的。它也可以是故意从单个真理...编程 发布于2025-07-14
CSS强类型语言解析您可以通过其强度或弱输入的方式对编程语言进行分类的方式之一。在这里,“键入”意味着是否在编译时已知变量。一个例子是一个场景,将整数(1)添加到包含整数(“ 1”)的字符串: result = 1 "1";包含整数的字符串可能是由带有许多运动部件的复杂逻辑套件无意间生成的。它也可以是故意从单个真理...编程 发布于2025-07-14























