
ClassiSage:基于 Terraform IaC 自动化 AWS SageMaker HDFS 日志分类模型
 浏览:774
浏览:774
ClassiSage
A Machine Learning model made with AWS SageMaker and its Python SDK for Classification of HDFS Logs using Terraform for automation of infrastructure setup.
Link: GitHub
Language: HCL (terraform), Python
Content
- Overview: Project Overview.
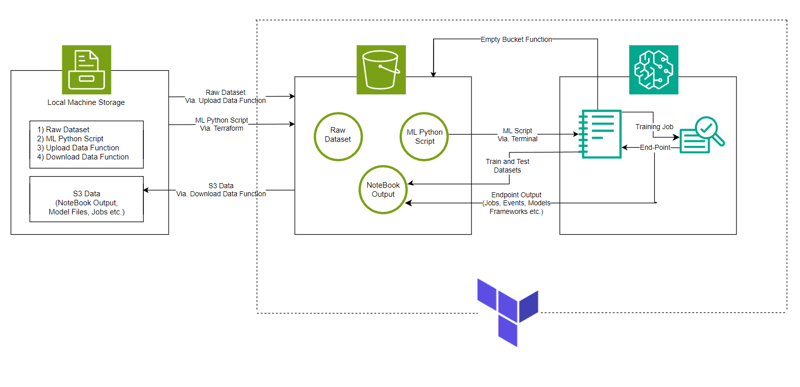
- System Architecture: System Architecture Diagram
- ML Model: Model Overview.
- Getting Started: How to run the project.
- Console Observations: Changes in instances and infrastructure that can be observed while running the project.
- Ending and Cleanup: Ensuring no additional charges.
- Auto Created Objects: Files and Folders created during execution process.
- Firstly follow the Directory Structure for better project setup.
- Take major reference from the ClassiSage's Project Repository uploaded in GitHub for better understanding.
Overview
- The model is made with AWS SageMaker for Classification of HDFS Logs along with S3 for storing dataset, Notebook file (containing code for SageMaker instance) and Model Output.
- The Infrastructure setup is automated using Terraform a tool to provide infrastructure-as-code created by HashiCorp
- The data set used is HDFS_v1.
- The project implements SageMaker Python SDK with the model XGBoost version 1.2
System Architecture
ML Model
- Image URI
# Looks for the XGBoost image URI and builds an XGBoost container. Specify the repo_version depending on preference.
container = get_image_uri(boto3.Session().region_name,
'xgboost',
repo_version='1.0-1')

- Initializing Hyper Parameter and Estimator call to the container
hyperparameters = {
"max_depth":"5", ## Maximum depth of a tree. Higher means more complex models but risk of overfitting.
"eta":"0.2", ## Learning rate. Lower values make the learning process slower but more precise.
"gamma":"4", ## Minimum loss reduction required to make a further partition on a leaf node. Controls the model’s complexity.
"min_child_weight":"6", ## Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting.
"subsample":"0.7", ## Fraction of training data used. Reduces overfitting by sampling part of the data.
"objective":"binary:logistic", ## Specifies the learning task and corresponding objective. binary:logistic is for binary classification.
"num_round":50 ## Number of boosting rounds, essentially how many times the model is trained.
}
# A SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=container, # Points to the XGBoost container we previously set up. This tells SageMaker which algorithm container to use.
hyperparameters=hyperparameters, # Passes the defined hyperparameters to the estimator. These are the settings that guide the training process.
role=sagemaker.get_execution_role(), # Specifies the IAM role that SageMaker assumes during the training job. This role allows access to AWS resources like S3.
train_instance_count=1, # Sets the number of training instances. Here, it’s using a single instance.
train_instance_type='ml.m5.large', # Specifies the type of instance to use for training. ml.m5.2xlarge is a general-purpose instance with a balance of compute, memory, and network resources.
train_volume_size=5, # 5GB # Sets the size of the storage volume attached to the training instance, in GB. Here, it’s 5 GB.
output_path=output_path, # Defines where the model artifacts and output of the training job will be saved in S3.
train_use_spot_instances=True, # Utilizes spot instances for training, which can be significantly cheaper than on-demand instances. Spot instances are spare EC2 capacity offered at a lower price.
train_max_run=300, # Specifies the maximum runtime for the training job in seconds. Here, it's 300 seconds (5 minutes).
train_max_wait=600) # Sets the maximum time to wait for the job to complete, including the time waiting for spot instances, in seconds. Here, it's 600 seconds (10 minutes).
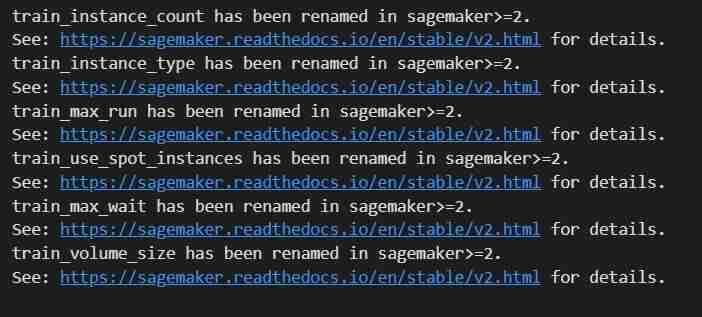
- Training Job
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
- Deployment
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')

- Validation
from sagemaker.serializers import CSVSerializer
import numpy as np
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
# Drop the label column from the test data
test_data_features = test_data_final.drop(columns=['Label']).values
# Set the content type and serializer
xgb_predictor.serializer = CSVSerializer()
xgb_predictor.content_type = 'text/csv'
# Perform prediction
predictions = xgb_predictor.predict(test_data_features).decode('utf-8')
y_test = test_data_final['Label'].values
# Convert the predictions into a array
predictions_array = np.fromstring(predictions, sep=',')
print(predictions_array.shape)
# Converting predictions them to binary (0 or 1)
threshold = 0.5
binary_predictions = (predictions_array >= threshold).astype(int)
# Accuracy
accuracy = accuracy_score(y_test, binary_predictions)
# Precision
precision = precision_score(y_test, binary_predictions)
# Recall
recall = recall_score(y_test, binary_predictions)
# F1 Score
f1 = f1_score(y_test, binary_predictions)
# Confusion Matrix
cm = confusion_matrix(y_test, binary_predictions)
# False Positive Rate (FPR) using the confusion matrix
tn, fp, fn, tp = cm.ravel()
false_positive_rate = fp / (fp tn)
# Print the metrics
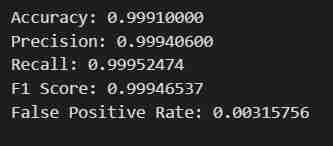
print(f"Accuracy: {accuracy:.8f}")
print(f"Precision: {precision:.8f}")
print(f"Recall: {recall:.8f}")
print(f"F1 Score: {f1:.8f}")
print(f"False Positive Rate: {false_positive_rate:.8f}")
Getting Started
- Clone the repository using Git Bash / download a .zip file / fork the repository.
- Go to your AWS Management Console, click on your account profile on the Top-Right corner and select My Security Credentials from the dropdown.
- Create Access Key: In the Access keys section, click on Create New Access Key, a dialog will appear with your Access Key ID and Secret Access Key.
- Download or Copy Keys: (IMPORTANT) Download the .csv file or copy the keys to a secure location. This is the only time you can view the secret access key.
- Open the cloned Repo. in your VS Code
- Create a file under ClassiSage as terraform.tfvars with its content as
# terraform.tfvars access_key = "" secret_key = " " aws_account_id = " "
- Download and install all the dependancies for using Terraform and Python.
In the terminal type/paste terraform init to initialize the backend.
Then type/paste terraform Plan to view the plan or simply terraform validate to ensure that there is no error.
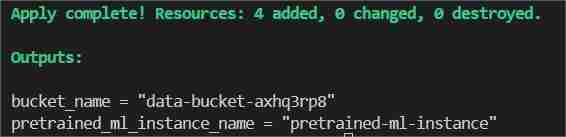
Finally in the terminal type/paste terraform apply --auto-approve
This will show two outputs one as bucket_name other as pretrained_ml_instance_name (The 3rd resource is the variable name given to the bucket since they are global resources ).
- After Completion of the command is shown in the terminal, navigate to ClassiSage/ml_ops/function.py and on the 11th line of the file with code
output = subprocess.check_output('terraform output -json', shell=True, cwd = r'' #C:\Users\Saahen\Desktop\ClassiSage
and change it to the path where the project directory is present and save it.
- Then on the ClassiSage\ml_ops\data_upload.ipynb run all code cell till cell number 25 with the code
# Try to upload the local CSV file to the S3 bucket
try:
print(f"try block executing")
s3.upload_file(
Filename=local_file_path,
Bucket=bucket_name,
Key=file_key # S3 file key (filename in the bucket)
)
print(f"Successfully uploaded {file_key} to {bucket_name}")
# Delete the local file after uploading to S3
os.remove(local_file_path)
print(f"Local file {local_file_path} deleted after upload.")
except Exception as e:
print(f"Failed to upload file: {e}")
os.remove(local_file_path)
to upload dataset to S3 Bucket.
- Output of the code cell execution

- After the execution of the notebook re-open your AWS Management Console.
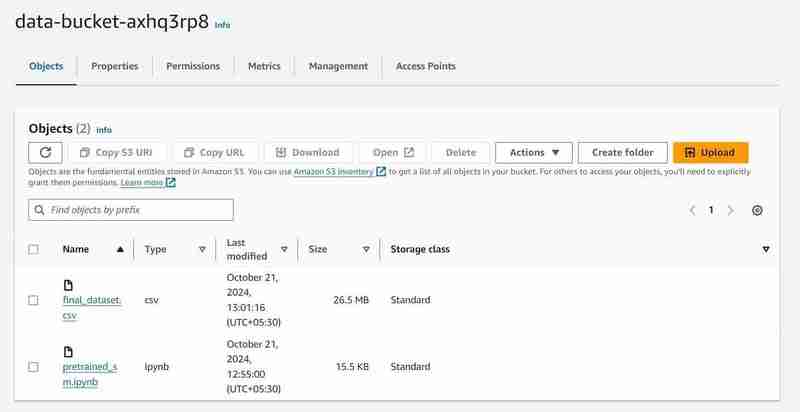
- You can search for S3 and Sagemaker services and will see an instance of each service initiated (A S3 bucket and a SageMaker Notebook)
S3 Bucket with named 'data-bucket-' with 2 objects uploaded, a dataset and the pretrained_sm.ipynb file containing model code.
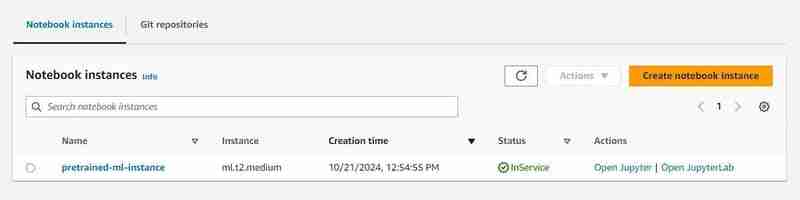
- Go to the notebook instance in the AWS SageMaker, click on the created instance and click on open Jupyter.
- After that click on new on the top right side of the window and select on terminal.
- This will create a new terminal.
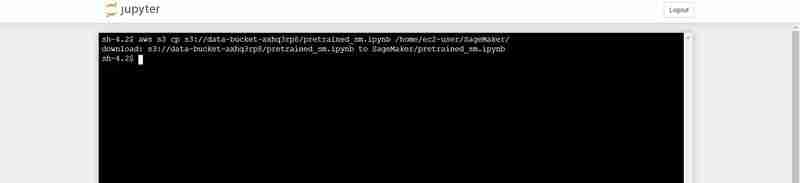
- On the terminal paste the following (Replacing with the bucket_name output that is shown in the VS Code's terminal output):
aws s3 cp s3:///pretrained_sm.ipynb /home/ec2-user/SageMaker/
Terminal command to upload the pretrained_sm.ipynb from S3 to Notebook's Jupyter environment
- Go Back to the opened Jupyter instance and click on the pretrained_sm.ipynb file to open it and assign it a conda_python3 Kernel.
- Scroll Down to the 4th cell and replace the variable bucket_name's value by the VS Code's terminal output for bucket_name = "
"
# S3 bucket, region, session
bucket_name = 'data-bucket-axhq3rp8'
my_region = boto3.session.Session().region_name
sess = boto3.session.Session()
print("Region is " my_region " and bucket is " bucket_name)
Output of the code cell execution

- On the top of the file do a Restart by going to the Kernel tab.
- Execute the Notebook till code cell number 27, with the code
# Print the metrics
print(f"Accuracy: {accuracy:.8f}")
print(f"Precision: {precision:.8f}")
print(f"Recall: {recall:.8f}")
print(f"F1 Score: {f1:.8f}")
print(f"False Positive Rate: {false_positive_rate:.8f}")
- You will get the intended result. The data will be fetched, split into train and test sets after being adjusted for Labels and Features with a defined output path, then a model using SageMaker's Python SDK will be Trained, Deployed as a EndPoint, Validated to give different metrics.
Console Observation Notes
Execution of 8th cell
# Set an output path where the trained model will be saved
prefix = 'pretrained-algo'
output_path ='s3://{}/{}/output'.format(bucket_name, prefix)
print(output_path)
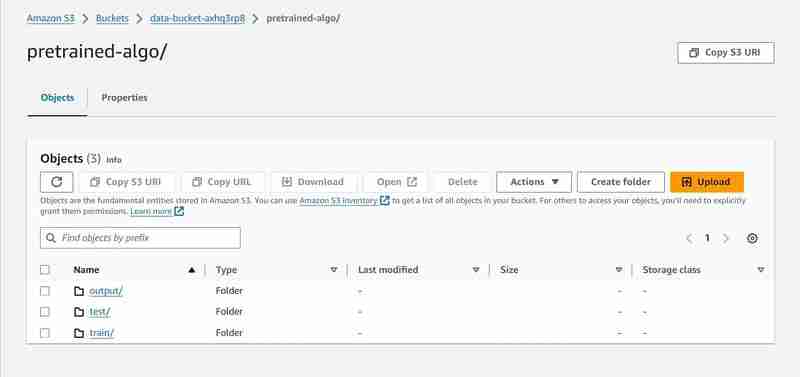
- An output path will be setup in the S3 to store model data.
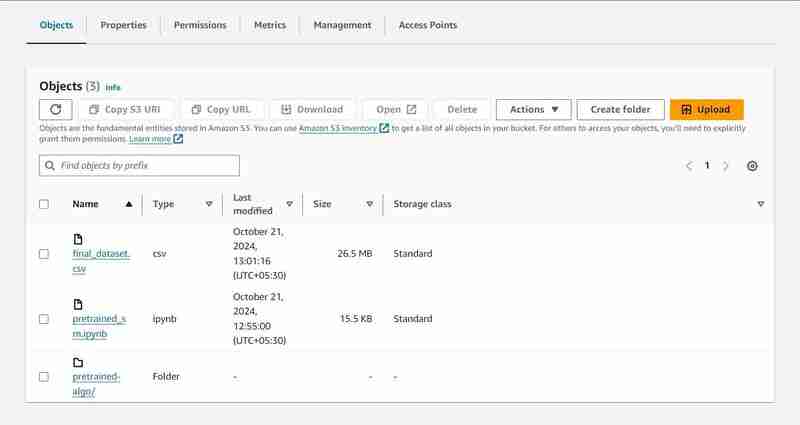
Execution of 23rd cell
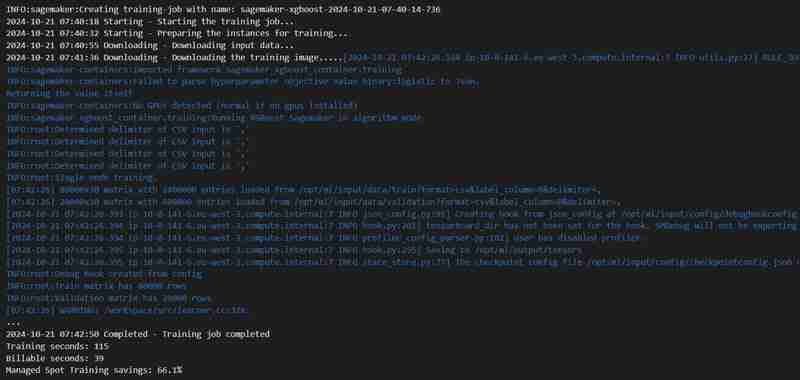
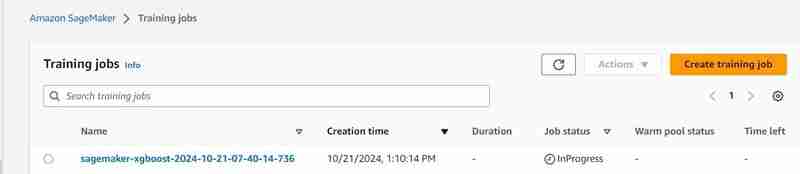
estimator.fit({'train': s3_input_train,'validation': s3_input_test})
- A training job will start, you can check it under the training tab.
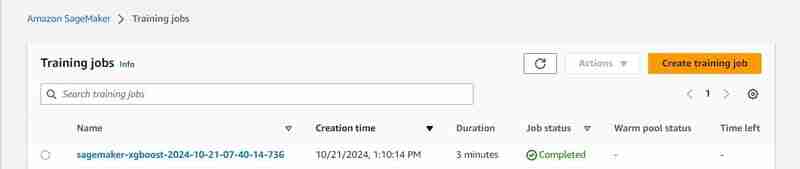
- After some time (3 mins est.) It shall be completed and will show the same.
Execution of 24th code cell
xgb_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large')
- An endpoint will be deployed under Inference tab.
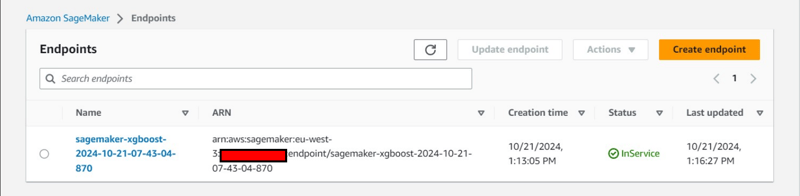
Additional Console Observation:
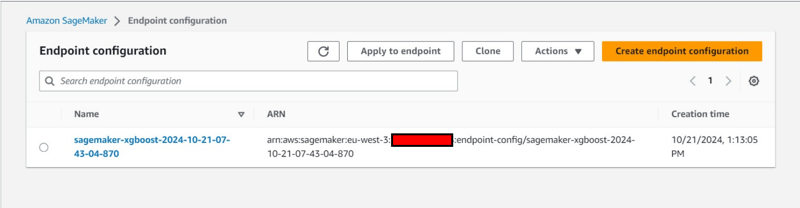
- Creation of an Endpoint Configuration under Inference tab.
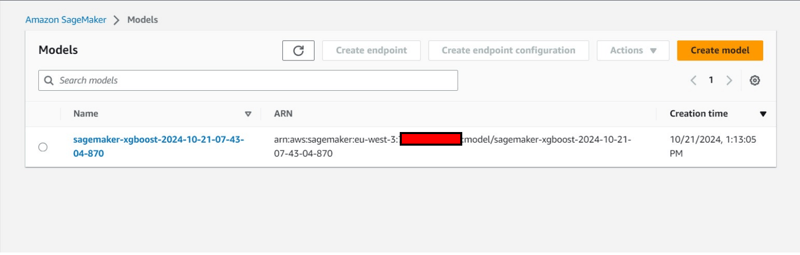
- Creation of an model also under under Inference tab.
Ending and Cleanup
- In the VS Code comeback to data_upload.ipynb to execute last 2 code cells to download the S3 bucket's data into the local system.
- The folder will be named downloaded_bucket_content. Directory Structure of folder Downloaded.
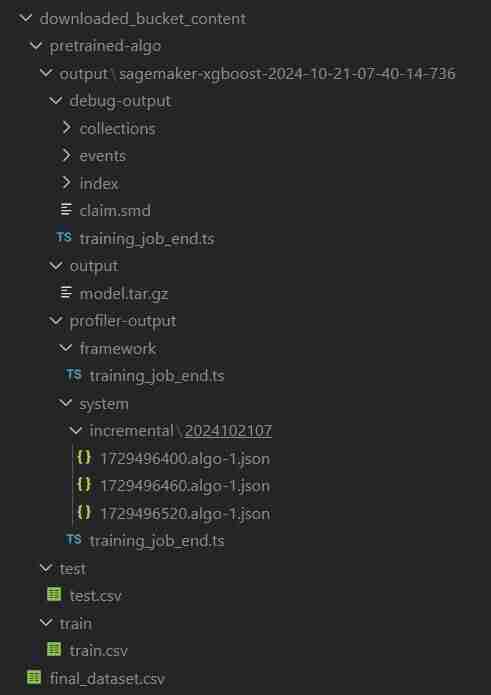
- You will get a log of downloaded files in the output cell. It will contain a raw pretrained_sm.ipynb, final_dataset.csv and a model output folder named 'pretrained-algo' with the execution data of the sagemaker code file.
- Finally go into pretrained_sm.ipynb present inside the SageMaker instance and execute the final 2 code cells. The end-point and the resources within the S3 bucket will be deleted to ensure no additional charges.
- Deleting The EndPoint
sagemaker.Session().delete_endpoint(xgb_predictor.endpoint)

- Clearing S3: (Needed to destroy the instance)
bucket_to_delete = boto3.resource('s3').Bucket(bucket_name)
bucket_to_delete.objects.all().delete()
- Come back to the VS Code terminal for the project file and then type/paste terraform destroy --auto-approve
- All the created resource instances will be deleted.
Auto Created Objects
ClassiSage/downloaded_bucket_content
ClassiSage/.terraform
ClassiSage/ml_ops/pycache
ClassiSage/.terraform.lock.hcl
ClassiSage/terraform.tfstate
ClassiSage/terraform.tfstate.backup
NOTE:
If you liked the idea and the implementation of this Machine Learning Project using AWS Cloud's S3 and SageMaker for HDFS log classification, using Terraform for IaC (Infrastructure setup automation), Kindly consider liking this post and starring after checking-out the project repository at GitHub.
-
 在Ubuntu/linux上安装mysql-python时,如何修复\“ mysql_config \”错误?mysql-python安装错误:“ mysql_config找不到”“ 由于缺少MySQL开发库而出现此错误。解决此问题,建议在Ubuntu上使用该分发的存储库。使用以下命令安装Python-MysqldB: sudo apt-get安装python-mysqldb sudo pip in...编程 发布于2025-07-12
在Ubuntu/linux上安装mysql-python时,如何修复\“ mysql_config \”错误?mysql-python安装错误:“ mysql_config找不到”“ 由于缺少MySQL开发库而出现此错误。解决此问题,建议在Ubuntu上使用该分发的存储库。使用以下命令安装Python-MysqldB: sudo apt-get安装python-mysqldb sudo pip in...编程 发布于2025-07-12 -
`console.log`显示修改后对象值异常的原因foo = [{id:1},{id:2},{id:3},{id:4},{id:id:5},],]; console.log('foo1',foo,foo.length); foo.splice(2,1); console.log('foo2', foo, foo....编程 发布于2025-07-12
-
如何在Java字符串中有效替换多个子字符串?在java 中有效地替换多个substring,需要在需要替换一个字符串中的多个substring的情况下,很容易求助于重复应用字符串的刺激力量。 However, this can be inefficient for large strings or when working with nu...编程 发布于2025-07-12
-
查找当前执行JavaScript的脚本元素方法如何引用当前执行脚本的脚本元素在某些方案中理解问题在某些方案中,开发人员可能需要将其他脚本动态加载其他脚本。但是,如果Head Element尚未完全渲染,则使用document.getElementsbytagname('head')[0] .appendChild(v)的常规方...编程 发布于2025-07-12
-
反射动态实现Go接口用于RPC方法探索在GO 使用反射来实现定义RPC式方法的界面。例如,考虑一个接口,例如:键入myService接口{ 登录(用户名,密码字符串)(sessionId int,错误错误) helloworld(sessionid int)(hi String,错误错误) } 替代方案而不是依靠反射...编程 发布于2025-07-12
-
Java的Map.Entry和SimpleEntry如何简化键值对管理?A Comprehensive Collection for Value Pairs: Introducing Java's Map.Entry and SimpleEntryIn Java, when defining a collection where each element com...编程 发布于2025-07-12
-
哪种方法更有效地用于点 - 填点检测:射线跟踪或matplotlib \的路径contains_points?在Python Matplotlib's path.contains_points FunctionMatplotlib's path.contains_points function employs a path object to represent the polygon.它...编程 发布于2025-07-12
-
为什么HTML无法打印页码及解决方案无法在html页面上打印页码? @page规则在@Media内部和外部都无济于事。 HTML:Customization:@page { margin: 10%; @top-center { font-family: sans-serif; font-weight: bo...编程 发布于2025-07-12
-
如何使用FormData()处理多个文件上传?)处理多个文件输入时,通常需要处理多个文件上传时,通常是必要的。 The fd.append("fileToUpload[]", files[x]); method can be used for this purpose, allowing you to send multi...编程 发布于2025-07-12
-
Java为何无法创建泛型数组?通用阵列创建错误 arrayList [2]; JAVA报告了“通用数组创建”错误。为什么不允许这样做?答案:Create an Auxiliary Class:public static ArrayList<myObject>[] a = new ArrayList<myO...编程 发布于2025-07-12
-
C++成员函数指针正确传递方法如何将成员函数置于c 的函数时,接受成员函数指针的函数时,必须同时提供对象的指针,并提供指针和指针到函数。需要具有一定签名的功能指针。要通过成员函数,您需要同时提供对象指针(此)和成员函数指针。这可以通过修改Menubutton :: SetButton()(如下所示:[&& && && &&华)...编程 发布于2025-07-12
-
如何正确使用与PDO参数的查询一样?在pdo 中使用类似QUERIES在PDO中的Queries时,您可能会遇到类似疑问中描述的问题:此查询也可能不会返回结果,即使$ var1和$ var2包含有效的搜索词。错误在于不正确包含%符号。通过将变量包含在$ params数组中的%符号中,您确保将%字符正确替换到查询中。没有此修改,PDO...编程 发布于2025-07-12
-
解决MySQL插入Emoji时出现的\\"字符串值错误\\"异常Resolving Incorrect String Value Exception When Inserting EmojiWhen attempting to insert a string containing emoji characters into a MySQL database us...编程 发布于2025-07-12
-
如何使用Depimal.parse()中的指数表示法中的数字?在尝试使用Decimal.parse(“ 1.2345e-02”中的指数符号表示法表示的字符串时,您可能会遇到错误。这是因为默认解析方法无法识别指数符号。 成功解析这样的字符串,您需要明确指定它代表浮点数。您可以使用numbersTyles.Float样式进行此操作,如下所示:[&& && && ...编程 发布于2025-07-12
-
为什么在我的Linux服务器上安装Archive_Zip后,我找不到“ class \” class \'ziparchive \'错误?Class 'ZipArchive' Not Found Error While Installing Archive_Zip on Linux ServerSymptom:When attempting to run a script that utilizes the ZipAr...编程 发布于2025-07-12















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









