
使用 LlamaIndex.ts 和 Azure OpenAI 构建 RAG 应用程序:入门!
 浏览:457
浏览:457
随着人工智能继续塑造我们的工作方式以及与技术交互的方式,许多企业正在寻找在智能应用程序中利用自己的数据的方法。如果你使用过 ChatGPT 或 Azure OpenAI 等工具,那么你已经熟悉生成式 AI 如何改进流程并增强用户体验。然而,为了真正定制和相关的响应,您的应用程序需要合并您的专有数据。
这就是检索增强生成 (RAG) 的用武之地,它提供了一种结构化方法,将数据检索与人工智能驱动的响应相集成。借助 LlamaIndex 等框架,您可以轻松地将这种功能构建到您的解决方案中,从而释放业务数据的全部潜力。
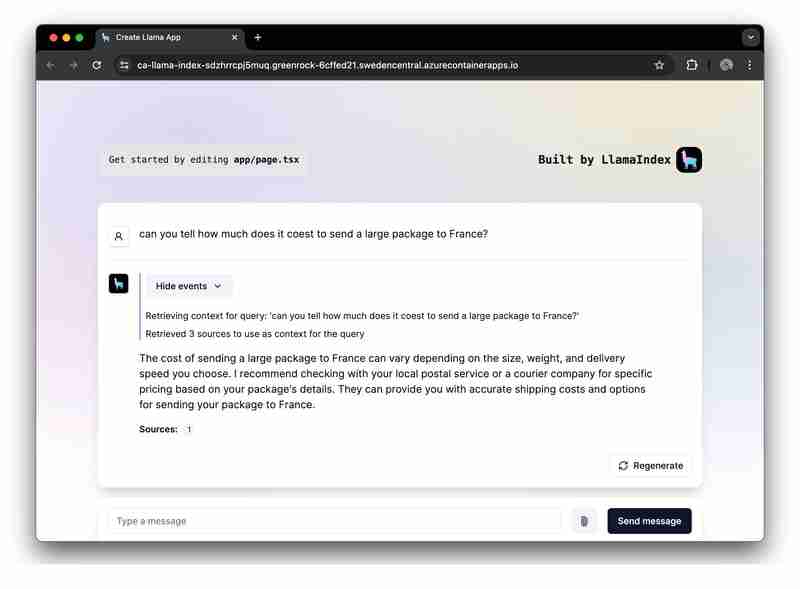
想要快速运行并探索该应用程序?点击这里。
什么是 RAG - 检索增强生成?
检索增强生成 (RAG) 是一种神经网络框架,通过包含检索组件来访问相关信息并集成您自己的数据,从而增强 AI 文本生成。它由两个主要部分组成:
- Retriever:密集检索器模型(例如,基于 BERT),用于搜索大型文档语料库以查找与给定查询相关的相关段落或信息。
- 生成器:序列到序列模型(例如,基于 BART 或 T5),它将查询和检索到的文本作为输入,并生成连贯的、上下文丰富的响应。
检索器查找相关文档,生成器使用它们来创建更准确、信息更丰富的响应。这种组合允许 RAG 模型有效地利用外部知识,提高生成文本的质量和相关性。
LlamaIndex 如何实现 RAG?
要使用 LlamaIndex 实现 RAG 系统,请遵循以下一般步骤:
数据摄取:
- 使用 SimpleDirectoryReader 等文档加载器将文档加载到 LlamaIndex.ts 中,这有助于从 PDF、API 或 SQL 数据库等各种来源导入数据。
- 使用 SentenceSplitter 将大型文档分解为更小的、可管理的块。
索引创建:
- 使用 VectorStoreIndex 创建这些文档块的向量索引,从而允许基于嵌入进行高效的相似性搜索。
- 对于复杂的数据集,可以选择使用递归检索技术来管理分层结构化数据并根据用户查询检索相关部分。
查询引擎设置:
- 使用asQueryEngine将向量索引转换为查询引擎,并使用similarityTopK等参数来定义应检索多少个顶级文档。
- 对于更高级的设置,创建一个多代理系统,其中每个代理负责特定文档,并且顶级代理协调整个检索过程。
检索和生成:
- 通过定义根据用户查询检索相关文档块的目标函数来实现 RAG 管道。
- 使用 RetrieverQueryEngine 执行实际的检索和查询处理,以及可选的后处理步骤,例如使用 CohereRerank 等工具对检索到的文档重新排名。
作为实际示例,我们提供了一个示例应用程序来演示使用 Azure OpenAI 的完整 RAG 实现。
实用 RAG 示例应用程序
我们现在将重点使用 LlamaIndex.ts(LlamaIndex 的 TypeScipt 实现)和 Azure OpenAI 构建 RAG 应用程序,并将其部署为 Azure 容器应用程序上的无服务器 Web 应用程序。
运行示例的要求
- Azure Developer CLI (azd):一个命令行工具,可轻松部署整个应用程序,包括后端、前端和数据库。
- Azure 帐户:您需要一个 Azure 帐户来部署应用程序。获取一个带有一些积分的免费 Azure 帐户即可开始使用。
您将在 GitHub 上找到入门项目。我们建议您分叉此模板,以便您可以在需要时自由编辑它:

高层架构
入门项目应用程序基于以下架构构建:
- Azure OpenAI:处理用户查询的 AI 提供程序。
- LlamaIndex.ts:帮助提取、转换和矢量化内容 (PDF) 以及创建搜索索引的框架。
- Azure Container Apps:托管无服务器应用程序的容器环境。
- Azure 托管身份:确保一流的安全性并消除处理凭据和 API 密钥的需要。
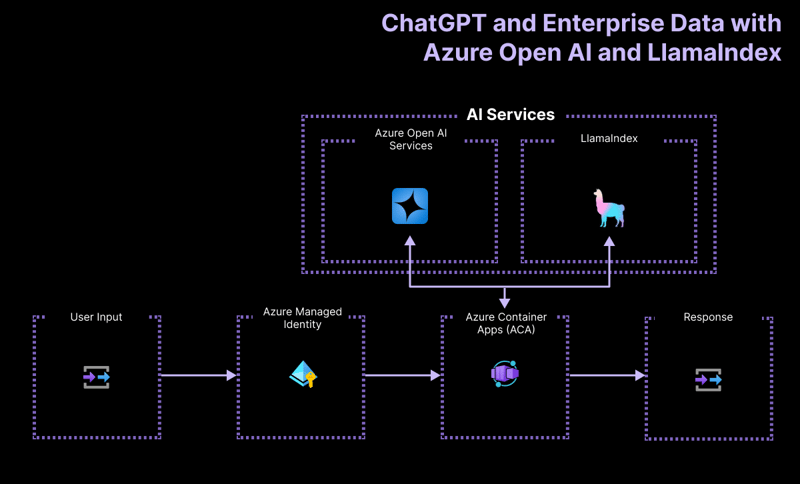
有关部署哪些资源的更多详细信息,请检查我们所有示例中提供的 infra 文件夹。
用户工作流程示例
示例应用程序包含两个工作流程的逻辑:
-
数据摄取:获取数据、向量化并创建搜索索引。如果您想添加更多文件,例如 PDF 或 Word 文件,您应该在此处添加它们。
npm run generate
服务提示请求:应用程序接收用户提示,将其发送到 Azure OpenAI,并使用向量索引作为检索器来增强这些提示。
运行示例
运行示例之前,请确保您已预配必要的 Azure 资源。
要在 GitHub Codespace 中运行 GitHub 模板,只需单击
在您的 Codespaces 实例中,从终端登录您的 Azure 帐户:
azd auth login
使用单个命令配置、打包示例应用程序并将其部署到 Azure:
azd up
要在本地运行并尝试应用程序,请安装 npm 依赖项并运行应用程序:
npm install npm run dev
应用程序将在您的 Codespaces 实例中的端口 3000 或浏览器中的 http://localhost:3000 上运行。
结论
本指南演示了如何使用 LlamaIndex.ts 和 Azure OpenAI 构建部署在 Microsoft Azure 上的无服务器 RAG(检索增强生成)应用程序。通过遵循本指南,您可以利用 Azure 的基础架构和 LlamaIndex 的功能来创建强大的 AI 应用程序,这些应用程序可根据您的数据提供上下文丰富的响应。
我们很高兴看到您使用这个入门应用程序构建的内容。请随意 fork 它并喜欢 GitHub 存储库以接收最新的更新和功能。
-
 如何使用组在MySQL中旋转数据?在关系数据库中使用mySQL组使用mySQL组进行查询结果,在关系数据库中使用MySQL组,转移数据的数据是指重新排列的行和列的重排以增强数据可视化。在这里,我们面对一个共同的挑战:使用组的组将数据从基于行的基于列的转换为基于列。 Let's consider the following ...编程 发布于2025-04-05
如何使用组在MySQL中旋转数据?在关系数据库中使用mySQL组使用mySQL组进行查询结果,在关系数据库中使用MySQL组,转移数据的数据是指重新排列的行和列的重排以增强数据可视化。在这里,我们面对一个共同的挑战:使用组的组将数据从基于行的基于列的转换为基于列。 Let's consider the following ...编程 发布于2025-04-05 -
如何为PostgreSQL中的每个唯一标识符有效地检索最后一行?postgresql:为每个唯一标识符在postgresql中提取最后一行,您可能需要遇到与数据集合中每个不同标识的信息相关的信息。考虑以下数据:[ 1 2014-02-01 kjkj 在数据集中的每个唯一ID中检索最后一行的信息,您可以在操作员上使用Postgres的有效效率: id dat...编程 发布于2025-04-05
-
如何配置Pytesseract以使用数字输出的单位数字识别?Pytesseract OCR具有单位数字识别和仅数字约束 在pytesseract的上下文中,在配置tesseract以识别单位数字和限制单个数字和限制输出对数字可能会提出质疑。 To address this issue, we delve into the specifics of Te...编程 发布于2025-04-05
-
如何同步迭代并从PHP中的两个等级阵列打印值?同步的迭代和打印值来自相同大小的两个数组使用两个数组相等大小的selectbox时,一个包含country代码的数组,另一个包含乡村代码,另一个包含其相应名称的数组,可能会因不当提供了exply for for for the uncore for the forsion for for ytry...编程 发布于2025-04-05
-
如何在GO编译器中自定义编译优化?在GO编译器中自定义编译优化 GO中的默认编译过程遵循特定的优化策略。 However, users may need to adjust these optimizations for specific requirements.Optimization Control in Go Compi...编程 发布于2025-04-05
-
如何在其容器中为DIV创建平滑的左右CSS动画?通用CSS动画,用于左右运动 ,我们将探索创建一个通用的CSS动画,以向左和右移动DIV,从而到达其容器的边缘。该动画可以应用于具有绝对定位的任何div,无论其未知长度如何。问题:使用左直接导致瞬时消失 更加流畅的解决方案:混合转换和左 [并实现平稳的,线性的运动,我们介绍了线性的转换。这...编程 发布于2025-04-05
-
如何在Java的全屏独家模式下处理用户输入?Handling User Input in Full Screen Exclusive Mode in JavaIntroductionWhen running a Java application in full screen exclusive mode, the usual event ha...编程 发布于2025-04-05
-
为什么Microsoft Visual C ++无法正确实现两台模板的实例?在Microsoft Visual C 中,Microsoft consions用户strate strate strate strate strate strate strate strate strate strate strate strate strate strate strate st...编程 发布于2025-04-05
-
如何从PHP中的数组中提取随机元素?从阵列中的随机选择,可以轻松从数组中获取随机项目。考虑以下数组:; 从此数组中检索一个随机项目,利用array_rand( array_rand()函数从数组返回一个随机键。通过将$项目数组索引使用此键,我们可以从数组中访问一个随机元素。这种方法为选择随机项目提供了一种直接且可靠的方法。编程 发布于2025-04-05
-
如何使用“ JSON”软件包解析JSON阵列?parsing JSON与JSON软件包 QUALDALS:考虑以下go代码:字符串 } func main(){ datajson:=`[“ 1”,“ 2”,“ 3”]`` arr:= jsontype {} 摘要:= = json.unmarshal([] byte(...编程 发布于2025-04-05
-
如何使用Python理解有效地创建字典?在python中,词典综合提供了一种生成新词典的简洁方法。尽管它们与列表综合相似,但存在一些显着差异。与问题所暗示的不同,您无法为钥匙创建字典理解。您必须明确指定键和值。 For example:d = {n: n**2 for n in range(5)}This creates a dicti...编程 发布于2025-04-05
-
如何使用PHP从XML文件中有效地检索属性值?从php PHP陷入困境。使用simplexmlelement :: attributes()函数提供了简单的解决方案。此函数可访问对XML元素作为关联数组的属性: - > attributes()为$ attributeName => $ attributeValue){ echo ...编程 发布于2025-04-05
-
如何从Python中的字符串中删除表情符号:固定常见错误的初学者指南?从python import codecs import codecs import codecs 导入 text = codecs.decode('这狗\ u0001f602'.encode('utf-8'),'utf-8') 印刷(文字)#带有...编程 发布于2025-04-05
-
为什么使用Firefox后退按钮时JavaScript执行停止?导航历史记录问题:JavaScript使用Firefox Back Back 此行为是由浏览器缓存JavaScript资源引起的。要解决此问题并确保在后续页面访问中执行脚本,Firefox用户应设置一个空功能。 警报'); }; alert('inline Alert')...编程 发布于2025-04-05
-
为什么不使用CSS`content'属性显示图像?在Firefox extemers属性为某些图像很大,&& && && &&华倍华倍[华氏华倍华氏度]很少见,却是某些浏览属性很少,尤其是特定于Firefox的某些浏览器未能显示图像时未能显示图像时遇到了一个问题。这可以在提供的CSS类中看到:。googlepic { 内容:url(&#...编程 发布于2025-04-05















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









