
将 AI/ML 与您的自适应分析解决方案连接起来
 浏览:356
浏览:356
在当今的数据环境中,企业遇到了许多不同的挑战。其中之一是在所有消费者可用的统一和协调的数据层之上进行分析。可以为相同问题提供相同答案的层,与所使用的方言或工具无关。
InterSystems IRIS 数据平台通过自适应分析附加功能来解决这个问题,该分析可以提供统一的语义层。 DevCommunity 中有很多关于通过 BI 工具使用它的文章。本文将介绍如何通过人工智能使用它以及如何将一些见解带回来。
让我们一步一步来吧……
什么是自适应分析?
您可以在开发者社区网站轻松找到一些定义
简而言之,它可以将结构化和统一形式的数据传输到您选择的各种工具,以供进一步使用和分析。它为各种 BI 工具提供相同的数据结构。但是...它还可以向您的 AI/ML 工具提供相同的数据结构!
自适应分析有一个名为 AI-Link 的附加组件,可以构建从 AI 到 BI 的桥梁。
AI-Link到底是什么?
它是一个 Python 组件,旨在实现与语义层的编程交互,以简化机器学习 (ML) 工作流程的关键阶段(例如特征工程)。
通过 AI-Link,您可以:
- 以编程方式访问分析数据模型的功能;
- 进行查询,探索维度和度量;
- 提供 ML 管道; ...并将结果传递回您的语义层以供其他人再次使用(例如通过 Tableau 或 Excel)。
由于这是一个Python库,因此它可以在任何Python环境中使用。包括笔记本。
在本文中,我将给出一个在 AI-Link 的帮助下从 Jupyter Notebook 实现自适应分析解决方案的简单示例。
这是 git 存储库,其中包含完整的笔记本作为示例:https://github.com/v23ent/aa-hands-on
先决条件
后续步骤假设您已完成以下先决条件:
- 自适应分析解决方案启动并运行(使用 IRIS 数据平台作为数据仓库)
- Jupyter Notebook 启动并运行
- 1.和2.之间可以建立连接
第 1 步:设置
首先,让我们在我们的环境中安装所需的组件。这将下载进一步工作所需的一些软件包。
'atscale' - 这是我们连接的主要包
'prophet' - 我们需要进行预测的包
pip install atscale prophet
然后我们需要导入代表语义层的一些关键概念的关键类。
客户端 - 我们将用来建立与自适应分析的连接的类;
Project - 代表自适应分析中的项目的类;
DataModel - 代表我们的虚拟多维数据集的类;
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
第 2 步:连接
现在我们应该准备好建立与数据源的连接。
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
继续指定您的 Adaptive Analytics 实例的连接详细信息。一旦系统要求您提供组织,请在对话框中做出回应,然后输入您在 AtScale 实例中的密码。
建立连接后,您需要从服务器上发布的项目列表中选择您的项目。您将获得项目列表作为交互式提示,答案应该是项目的整数 ID。如果数据模型是唯一的,则自动选择数据模型。
project = client.select_project() data_model = project.select_data_model()
第 3 步:探索您的数据集
AI-Link组件库中AtScale准备了多种方法。它们允许探索您拥有的数据目录、查询数据,甚至提取一些数据。 AtScale 文档包含广泛的 API 参考,描述了所有可用的内容。
我们首先通过调用data_model的几个方法来看看我们的数据集是什么:
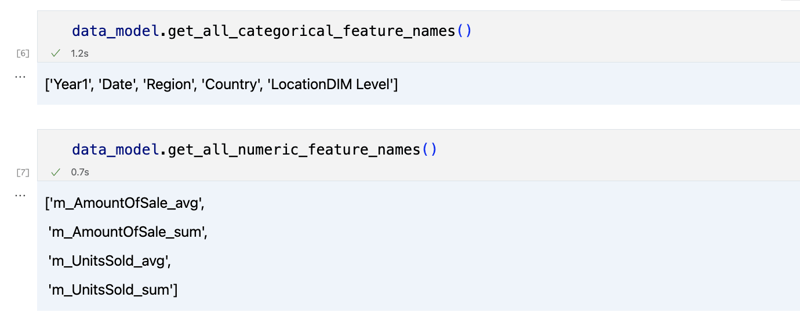
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
输出应如下所示
一旦我们环顾四周,我们就可以使用“get_data”方法查询我们感兴趣的实际数据。它将返回一个包含查询结果的 pandas DataFrame。
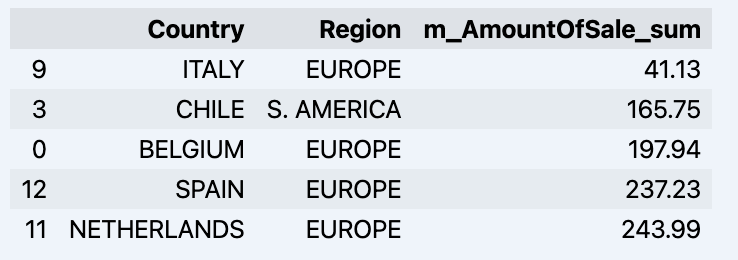
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
这将显示您的数据集:
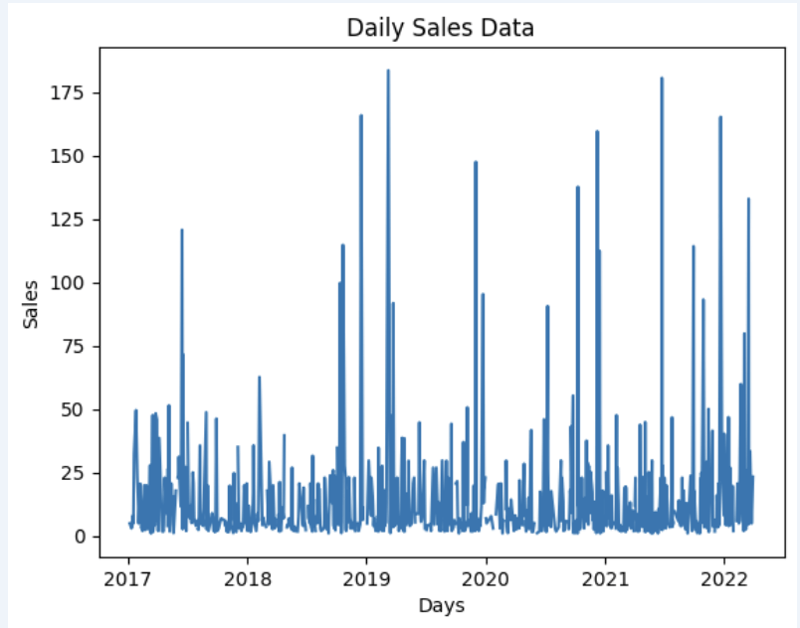
让我们准备一些数据集并快速将其显示在图表上
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
输出:
第四步:预测
下一步是真正从 AI-Link 桥中获得一些价值 - 让我们做一些简单的预测!
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
我们在这里得到 2 个不同的数据集:训练我们的模型并测试它。
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
然后我们创建另一个数据框来容纳我们的预测并将其显示在图表上
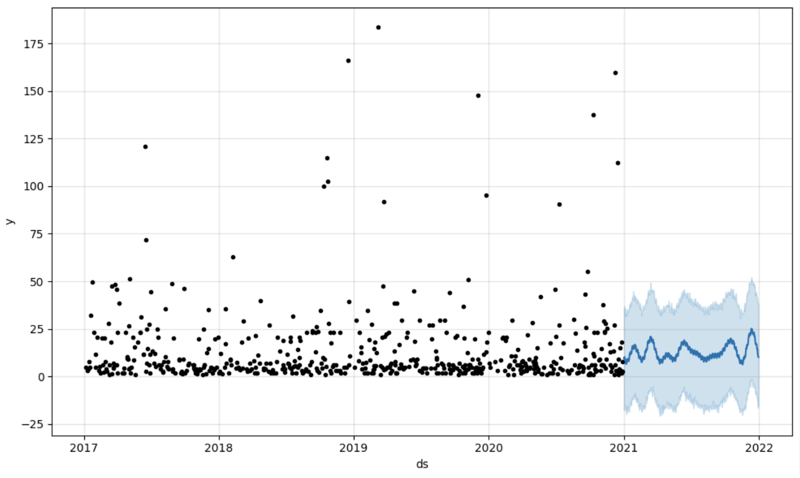
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
输出:
第五步:写回
一旦我们做出了预测,我们就可以将其放回数据仓库,并将聚合添加到我们的语义模型中,以反映给其他消费者。 BI 分析师和业务用户可以通过任何其他 BI 工具进行预测。
预测本身将被放入我们的数据仓库并存储在那里。
from atscale.db.connections import Iris
db = Iris(
username,
host,
namespace,
driver,
schema,
port=1972,
password=None,
warehouse_id=None
)data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
鳍
就是这样!
祝您预测顺利!
-
 如何从PHP中的数组中提取随机元素?从阵列中的随机选择,可以轻松从数组中获取随机项目。考虑以下数组:; 从此数组中检索一个随机项目,利用array_rand( array_rand()函数从数组返回一个随机键。通过将$项目数组索引使用此键,我们可以从数组中访问一个随机元素。这种方法为选择随机项目提供了一种直接且可靠的方法。编程 发布于2025-07-14
如何从PHP中的数组中提取随机元素?从阵列中的随机选择,可以轻松从数组中获取随机项目。考虑以下数组:; 从此数组中检索一个随机项目,利用array_rand( array_rand()函数从数组返回一个随机键。通过将$项目数组索引使用此键,我们可以从数组中访问一个随机元素。这种方法为选择随机项目提供了一种直接且可靠的方法。编程 发布于2025-07-14 -
在GO中构造SQL查询时,如何安全地加入文本和值?在go中构造文本sql查询时,在go sql queries 中,在使用conting and contement和contement consem per时,尤其是在使用integer per当per当per时,per per per当per. 在GO中实现这一目标的惯用方法是使用fmt.spr...编程 发布于2025-07-14
-
在PHP中如何高效检测空数组?在PHP 中检查一个空数组可以通过各种方法在PHP中确定一个空数组。如果需要验证任何数组元素的存在,则PHP的松散键入允许对数组本身进行直接评估:一种更严格的方法涉及使用count()函数: if(count(count($ playerList)=== 0){ //列表为空。 } 对...编程 发布于2025-07-14
-
为什么我的CSS背景图像出现?故障排除:CSS背景图像未出现 ,您的背景图像尽管遵循教程说明,但您的背景图像仍未加载。图像和样式表位于相同的目录中,但背景仍然是空白的白色帆布。而不是不弃用的,您已经使用了CSS样式: bockent {背景:封闭图像文件名:背景图:url(nickcage.jpg); 如果您的html,css...编程 发布于2025-07-14
-
C++中如何将独占指针作为函数或构造函数参数传递?在构造函数和函数中将唯一的指数管理为参数 unique pointers( unique_ptr [2启示。通过值: base(std :: simelor_ptr n) :next(std :: move(n)){} 此方法将唯一指针的所有权转移到函数/对象。指针的内容被移至功能中,在操作...编程 发布于2025-07-14
-
编译器报错“usr/bin/ld: cannot find -l”解决方法错误:“ usr/bin/ld:找不到-l “ 此错误表明链接器在链接您的可执行文件时无法找到指定的库。为了解决此问题,我们将深入研究如何指定库路径并将链接引导到正确位置的详细信息。添加库搜索路径的一个可能的原因是,此错误是您的makefile中缺少库搜索路径。要解决它,您可以在链接器命令中添加...编程 发布于2025-07-14
-
如何避免Go语言切片时的内存泄漏?,a [j:] ...虽然通常有效,但如果使用指针,可能会导致内存泄漏。这是因为原始的备份阵列保持完整,这意味着新切片外部指针引用的任何对象仍然可能占据内存。 copy(a [i:] 对于k,n:= len(a)-j i,len(a); k编程 发布于2025-07-14
-
PHP阵列键值异常:了解07和08的好奇情况PHP数组键值问题,使用07&08 在给定数月的数组中,键值07和08呈现令人困惑的行为时,就会出现一个不寻常的问题。运行print_r($月)返回意外结果:键“ 07”丢失,而键“ 08”分配给了9月的值。此问题源于PHP对领先零的解释。当一个数字带有0(例如07或08)的前缀时,PHP将其...编程 发布于2025-07-14
-
如何有效地选择熊猫数据框中的列?在处理数据操作任务时,在Pandas DataFrames 中选择列时,选择特定列的必要条件是必要的。在Pandas中,选择列的各种选项。选项1:使用列名 如果已知列索引,请使用ILOC函数选择它们。请注意,python索引基于零。 df1 = df.iloc [:,0:2]#使用索引0和1 c...编程 发布于2025-07-14
-
为什么Microsoft Visual C ++无法正确实现两台模板的实例?在Microsoft Visual C 中,Microsoft consions用户strate strate strate strate strate strate strate strate strate strate strate strate strate strate strate st...编程 发布于2025-07-14
-
您如何在Laravel Blade模板中定义变量?在Laravel Blade模板中使用Elegance 在blade模板中如何分配变量对于存储以后使用的数据至关重要。在使用“ {{}}”分配变量的同时,它可能并不总是是最优雅的解决方案。幸运的是,Blade通过@php Directive提供了一种更优雅的方法: $ old_section...编程 发布于2025-07-14
-
Java字符串非空且非null的有效检查方法检查字符串是否不是null而不是空的 if(str!= null && str.isementy())二手: if(str!= null && str.length()== 0) option 3:trim()。isement(Isement() trim whitespace whitesp...编程 发布于2025-07-14
-
Go语言垃圾回收如何处理切片内存?Garbage Collection in Go Slices: A Detailed AnalysisIn Go, a slice is a dynamic array that references an underlying array.使用切片时,了解垃圾收集行为至关重要,以避免潜在的内存泄...编程 发布于2025-07-14
-
如何在Java的全屏独家模式下处理用户输入?Handling User Input in Full Screen Exclusive Mode in JavaIntroductionWhen running a Java application in full screen exclusive mode, the usual event ha...编程 发布于2025-07-14
-
如何在其容器中为DIV创建平滑的左右CSS动画?通用CSS动画,用于左右运动 ,我们将探索创建一个通用的CSS动画,以向左和右移动DIV,从而到达其容器的边缘。该动画可以应用于具有绝对定位的任何div,无论其未知长度如何。问题:使用左直接导致瞬时消失 更加流畅的解决方案:混合转换和左 [并实现平稳的,线性的运动,我们介绍了线性的转换。这...编程 发布于2025-07-14















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









