
亚马逊产品数据集
发布于2024-08-29
 浏览:225
浏览:225
嗨,我在 Kaggle 中找到了亚马逊产品的数据集,并决定找到价格和星级之间的关系。
完整代码:
https://github.com/victordalet/Kaggle_analysis/tree/feat/amazon_products
I-准备数据
为此,我使用 SQLAlchemy 将 csv 文件转换为小型数据库,并以绘图方式显示信息。
pip install SQLAlchemy pip install plotly
在下面的脚本中,我提取数据并获得:
- 价格与星星数量的比率
- 最终评分和星星数量
- 价格和星星数量
import pandas as pd
from sqlalchemy import create_engine, text
import plotly.express as px
class Main:
def __init__(self):
self.result = None
self.connection = None
self.engine = create_engine("sqlite:///my_database.db", echo=False)
self.df = pd.read_csv("amazon_product.csv")
self.df.to_sql("products", self.engine, index=False, if_exists="append")
self.get_data()
self.transform_data()
self.display_graph()
self.get_data_number_start_and_price()
self.transform_data()
self.display_graph()
self.get_data_number_start_and_start()
self.display_graph()
def get_data(self):
self.connection = self.engine.connect()
query = text(
"SELECT product_price, product_star_rating FROM products where product_price != '$0.00'"
)
self.result = self.connection.execute(query).fetchall()
def get_data_number_start_and_price(self):
query = text(
"SELECT product_price, product_num_ratings FROM products where product_price != '$0.00'"
)
self.result = self.connection.execute(query).fetchall()
def get_data_number_start_and_start(self):
query = text(
"SELECT product_star_rating, product_num_ratings FROM products where product_price != '$0.00'"
)
self.result = self.connection.execute(query).fetchall()
for i in range(len(self.result)):
self.result[i] = [self.result[i][0], self.result[i][1]]
def transform_data(self):
for i in range(len(self.result)):
self.result[i] = [float(self.result[i][0].split("$")[1]), self.result[i][1]]
def display_graph(self):
fig = px.scatter(
self.result, x=0, y=1, title="Amazon Product Price vs Star Rating"
)
fig.show()
Main()
II - 结果
价格和符号
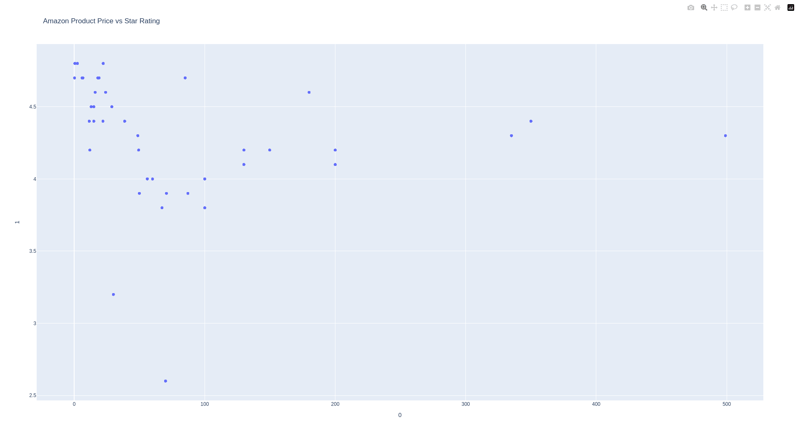
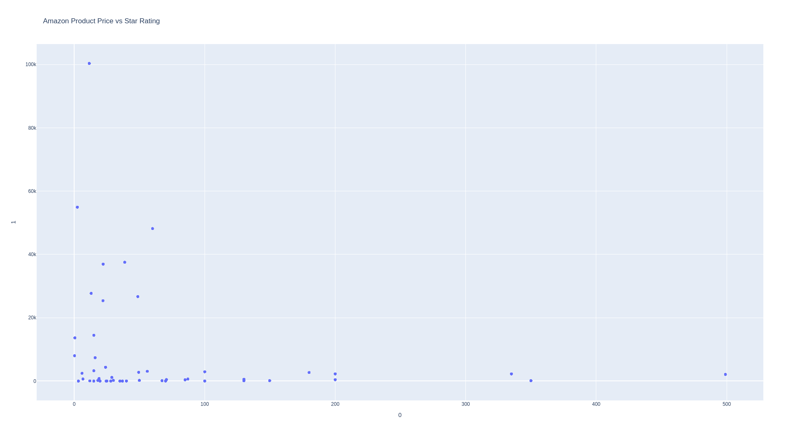
价格和符号数量
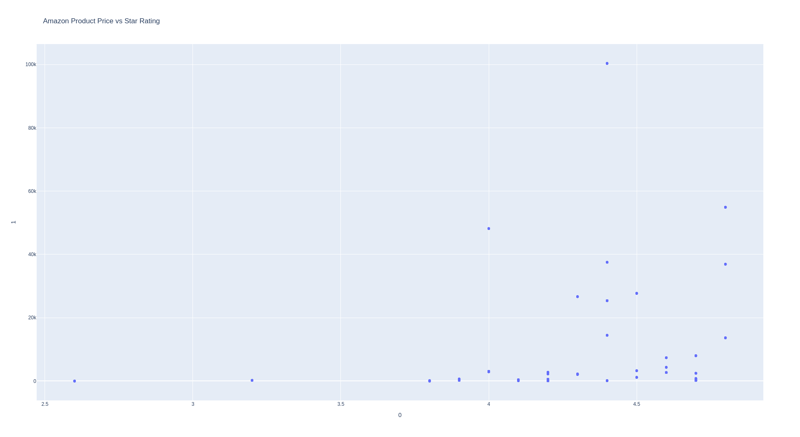
注释和意见数量
三、结论
我们可以看到,价格和评分之间没有必然的关系,但是价格越高,评分越低,评论越多,评分越高。
这似乎很合乎逻辑,因为如果一种产品被大量购买,则意味着它很受欢迎。
版本声明
本文转载于:https://dev.to/victordalet/amazon-product-dataset-h00?1如有侵犯,请联系[email protected]删除
最新教程
更多>
-
 什么是“export default”以及它与“module.exports”有何不同?ES6 的“默认导出”解释JavaScript 的 ES6 模块系统引入了“默认导出”,这是一种定义默认导出的独特方式。 module.在提供的示例中,文件 SafeString.js 定义了一个 SafeString 类并将其导出为默认导出using:export default SafeStri...编程 发布于2024-11-07
什么是“export default”以及它与“module.exports”有何不同?ES6 的“默认导出”解释JavaScript 的 ES6 模块系统引入了“默认导出”,这是一种定义默认导出的独特方式。 module.在提供的示例中,文件 SafeString.js 定义了一个 SafeString 类并将其导出为默认导出using:export default SafeStri...编程 发布于2024-11-07 -
SafeLine 如何通过高级动态保护保护您的网站SafeLine 由长亭科技在过去十年中开发,是一款最先进的 Web 应用程序防火墙 (WAF),它利用先进的语义分析算法来提供针对在线威胁的顶级保护。 SafeLine 在专业网络安全圈中享有盛誉并值得信赖,已成为保护网站安全的可靠选择。 SafeLine 社区版源自企业级 Ray Shield ...编程 发布于2024-11-07
-
在 React 中创建自定义 Hook 的最佳技巧React 的自定义 Hooks 是从组件中删除可重用功能的有效工具。它们支持代码中的 DRY(不要重复)、可维护性和整洁性。但开发有用的自定义钩子需要牢牢掌握 React 的基本思想和推荐程序。在这篇文章中,我们将讨论在 React 中开发自定义钩子的一些最佳策略,并举例说明如何有效地应用它们。 ...编程 发布于2024-11-07
-
如何解决 PHPMailer 中的 HTML 渲染问题?PHPmailer的HTML渲染问题及其解决方法在PHPmailer中,当尝试发送HTML格式的电子邮件时,用户可能会遇到一个意想不到的问题:显示实际的HTML代码在电子邮件正文中而不是预期内容中。为了有效地解决这个问题,方法调用的特定顺序至关重要。正确的顺序包括在调用 isHTML() 方法之前设...编程 发布于2024-11-07
-
通过 REST API 上的 GraphQL 增强 React 应用程序In the rapidly changing world of web development, optimizing and scaling applications is always an issue. React.js had an extraordinary success for fr...编程 发布于2024-11-07
-
为什么我的登录表单无法连接到我的数据库?登录表单的数据库连接问题尽管结合使用 PHP 和 MySQL 以及 HTML 和 Dreamweaver,您仍无法建立正确的数据库连接问题。登录表单和数据库之间的连接。缺少错误消息可能会产生误导,因为登录尝试仍然不成功。连接失败的原因:数据库凭据不正确: 确保用于连接数据库的主机名、数据库名称、用...编程 发布于2024-11-07
-
为什么嵌套绝对定位会导致元素引用其父级而不是祖父母?嵌套定位:绝对内的绝对嵌套的绝对定位元素可能会在 CSS 中表现出意想不到的行为。考虑这种情况:第一个 div (#1st) 位置:相对第二个 div (#2nd) 相对于 #1st 绝对定位A第三个div(#3rd)绝对定位在#2nd内问:为什么#3rd相对于#2nd而不是#1st绝对定位?A: ...编程 发布于2024-11-07
-
如何高效地从字符串中剥离特定文本?高效剥离字符串:如何删除特定文本片段遇到操作字符串值的需求是编程中的常见任务。经常面临的一项特殊挑战是删除特定文本片段,同时保留特定部分。在本文中,我们将深入研究此问题的实用解决方案。考虑这样一个场景,您有一个字符串“data-123”,您的目标是消除“data-”前缀,只留下“123”值。为了实现...编程 发布于2024-11-07
-
如何将通讯录与手机同步?在 Go 中实现 CardDAV!假设您帮助管理一个小型组织或俱乐部,并拥有一个存储所有会员详细信息(姓名、电话、电子邮件...)的数据库。 在您需要的任何地方都可以访问这些最新信息不是很好吗?好吧,有了 CardDAV,你就可以! CardDAV 是一个得到良好支持的联系人管理开放标准;它在 iOS 联系人应用程序和许多适用于 A...编程 发布于2024-11-07
-
C/C++ 开发的最佳编译器警告级别是多少?C/C 开发的最佳编译器警告级别编译器在检测代码中的潜在问题方面发挥着至关重要的作用。通过利用适当的警告级别,您可以尽早识别并解决漏洞或编码错误。本文探讨了各种 C/C 编译器的建议警告级别,以提高代码质量。GCC 和 G 对于 GCC 和 G,广泛推荐的警告级别是“-墙”。此选项会激活一组全面的警...编程 发布于2024-11-07
-
如何使用 Vite 和 Axios 在 React 中实现 MUI 文件上传:综合指南Introduction In modern web applications, file uploads play a vital role, enabling users to upload documents, images, and more, directly to a ...编程 发布于2024-11-07
-
为什么 `justify-content: center` 不将 Flex 容器中的文本居中?带有 justify-content 的非居中文本:center在 Flex 容器中, justify-content 属性使 Flex 项目水平居中,但是它无法直接控制这些项目中的文本。当文本在项目内换行时,它会保留其默认的 text-align: start 值,从而导致文本不居中。Flex 容...编程 发布于2024-11-07
-
情感人工智能和人工智能陪伴:人类与技术关系的未来情感人工智能和人工智能陪伴:人类与技术关系的未来 人工智能(AI)不再只是数据分析或自动化的工具。随着情感人工智能的进步,机器不再只是功能助手,而是演变成情感伴侣。利用情商 (EI) 的人工智能陪伴正在改变我们与技术互动的方式,提供情感支持,减少孤独感,甚至增强心理健康。但这些人工智能伴侣在复制人类...编程 发布于2024-11-07
-
## Go 中的空接口:什么时候它们是个好主意?Go 中空接口的最佳实践:注意事项和用例在 Go 中,空接口(interface{})是一个强大的工具,它允许抽象不同类型。然而,它们的使用引发了关于最佳实践以及何时适合使用它们的问题。空接口的缺点引起的一个担忧是类型安全性的损失。使用空接口时,编译器无法在编译时强制执行类型检查,从而导致潜在的运行...编程 发布于2024-11-07
-
Tailwindcss 不是 Bootstrap 也不是 MaterializeTailwind CSS 席卷了 Web 开发世界?️,但对其本质的误解仍然存在。在最近的一次设计系统规划讨论中,当一位同事随意将 Tailwind CSS 与 Bootstrap 和 Materialise 进行比较时,我差点没喝茶☕(对不起,我不喝咖啡)。这个令人震惊的发现就像发现我的猫认为自己...编程 发布于2024-11-07















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









