
我使用 Snowflake (SiS) 中的 Streamlit 製作了一個令牌計數檢查應用程式
 瀏覽:616
瀏覽:616
介紹
您好,我是 Snowflake 的銷售工程師。我想透過各種貼文與大家分享我的一些經驗和實驗。在本文中,我將向您展示如何使用 Snowflake 中的 Streamlit 建立應用程式來檢查令牌計數並估算 Cortex LLM 的成本。
註:本文僅代表個人觀點,不代表Snowflake的觀點。
Snowflake (SiS) 中的 Streamlit 是什麼?
Streamlit 是一個 Python 函式庫,可讓您使用簡單的 Python 程式碼建立 Web UI,無需 HTML/CSS/JavaScript。您可以在應用程式庫中查看範例。
Snowflake 中的 Streamlit 使您能夠直接在 Snowflake 上開發和運行 Streamlit Web 應用程式。只需一個 Snowflake 帳戶即可輕鬆使用,非常適合將 Snowflake 表資料整合到 Web 應用程式中。
關於 Snowflake 中的 Streamlit(官方 Snowflake 文件)
什麼是雪花皮層?
Snowflake Cortex 是 Snowflake 中的一套生成式 AI 功能。 Cortex LLM 允許您使用 SQL 或 Python 中的簡單函數呼叫在 Snowflake 上執行的大型語言模型。
大語言模型 (LLM) 函數 (Snowflake Cortex)(官方 Snowflake 文件)
功能概述
影像
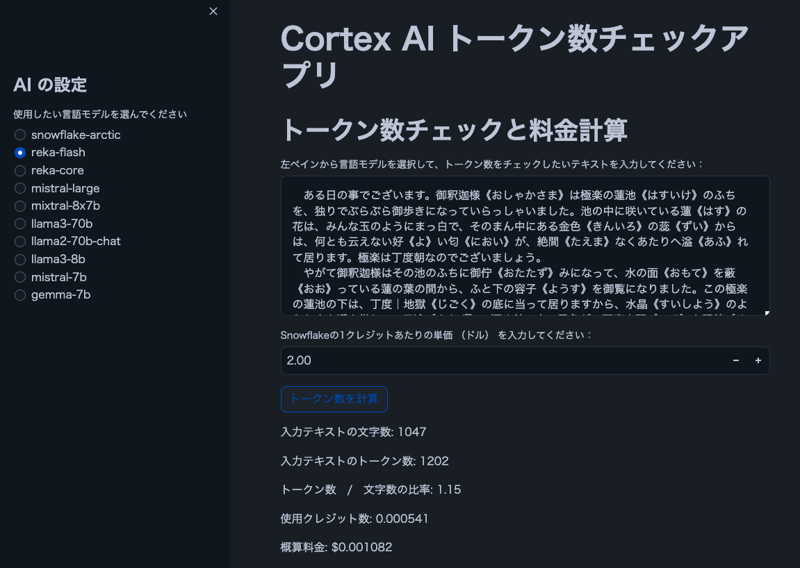
註:圖中文字來自芥川龍之介的《蜘蛛絲》。
特徵
- 使用者可以選擇Cortex LLM模型
- 顯示使用者輸入文字的字元和標記計數
- 顯示標記與字元的比例
- 根據 Snowflake 信用定價計算預估成本
附註:Cortex LLM 定價表 (PDF)
先決條件
- 具有 Cortex LLM 存取權限的 Snowflake 帳戶
- snowflake-ml-python 1.1.2 或更高版本
注意:Cortex LLM 區域可用性(官方 Snowflake 文件)
原始碼
import streamlit as st
from snowflake.snowpark.context import get_active_session
import snowflake.snowpark.functions as F
# Get current session
session = get_active_session()
# Application title
st.title("Cortex AI Token Count Checker")
# AI settings
st.sidebar.title("AI Settings")
lang_model = st.sidebar.radio("Select the language model you want to use",
("snowflake-arctic", "reka-core", "reka-flash",
"mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b",
"llama3.1-405b", "llama3.1-70b", "llama3.1-8b",
"llama3-70b", "llama3-8b", "llama2-70b-chat",
"jamba-instruct", "gemma-7b")
)
# Function to count tokens (using Cortex's token counting function)
def count_tokens(model, text):
result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect()
return result[0]['TOKEN_COUNT']
# Token count check and cost calculation
st.header("Token Count Check and Cost Calculation")
input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200)
# Let user input the price per credit
credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01)
# Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported)
model_credits = {
"snowflake-arctic": 0.84,
"reka-core": 5.5,
"reka-flash": 0.45,
"mistral-large2": 1.95,
"mistral-large": 5.1,
"mixtral-8x7b": 0.22,
"mistral-7b": 0.12,
"llama3.1-405b": 3,
"llama3.1-70b": 1.21,
"llama3.1-8b": 0.19,
"llama3-70b": 1.21,
"llama3-8b": 0.19,
"llama2-70b-chat": 0.45,
"jamba-instruct": 0.83,
"gemma-7b": 0.12
}
if st.button("Calculate Token Count"):
if input_text:
# Calculate character count
char_count = len(input_text)
st.write(f"Character count of input text: {char_count}")
if lang_model in model_credits:
# Calculate token count
token_count = count_tokens(lang_model, input_text)
st.write(f"Token count of input text: {token_count}")
# Ratio of tokens to characters
ratio = token_count / char_count if char_count > 0 else 0
st.write(f"Token count / Character count ratio: {ratio:.2f}")
# Cost calculation
credits_used = (token_count / 1000000) * model_credits[lang_model]
cost = credits_used * credit_price
st.write(f"Credits used: {credits_used:.6f}")
st.write(f"Estimated cost: ${cost:.6f}")
else:
st.warning("The selected model is not supported by Snowflake's token counting feature.")
else:
st.warning("Please enter some text.")
結論
這個應用程式可以更輕鬆地估計 LLM 工作負載的成本,特別是在處理日語等語言時,字元數和標記數之間經常存在差距。希望您覺得有用!
公告
Snowflake 最新動態 X 更新
我正在分享 Snowflake 在 X 上的最新動態。如果您有興趣,請隨時關注!
英文版
Snowflake What's New Bot (英文版)
https://x.com/snow_new_en
日文版
Snowflake What's New Bot(日文版)
https://x.com/snow_new_jp
變更歷史記錄
(20240914) 初始貼文
日本原創文章
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
-
 Bootstrap 4 Beta 中的列偏移發生了什麼事?Bootstrap 4 Beta:列偏移的刪除和恢復Bootstrap 4 在其Beta 1 版本中引入了重大更改柱子偏移了。然而,隨著 Beta 2 的後續發布,這些變化已經逆轉。 從 offset-md-* 到 ml-auto在 Bootstrap 4 Beta 1 中, offset-md-*...程式設計 發佈於2024-12-29
Bootstrap 4 Beta 中的列偏移發生了什麼事?Bootstrap 4 Beta:列偏移的刪除和恢復Bootstrap 4 在其Beta 1 版本中引入了重大更改柱子偏移了。然而,隨著 Beta 2 的後續發布,這些變化已經逆轉。 從 offset-md-* 到 ml-auto在 Bootstrap 4 Beta 1 中, offset-md-*...程式設計 發佈於2024-12-29 -
如何在 PHP 中組合兩個關聯數組,同時保留唯一 ID 並處理重複名稱?在 PHP 中組合關聯數組在 PHP 中,將兩個關聯數組組合成一個數組是常見任務。考慮以下請求:問題描述:提供的代碼定義了兩個關聯數組,$array1 和 $array2。目標是建立一個新陣列 $array3,它合併兩個陣列中的所有鍵值對。 此外,提供的陣列具有唯一的 ID,而名稱可能重疊。要求是建...程式設計 發佈於2024-12-29
-
儘管程式碼有效,為什麼 POST 請求無法擷取 PHP 中的輸入?解決PHP 中的POST 請求故障在提供的程式碼片段中:action=''而非:action="<?php echo $_SERVER['PHP_SELF'];?>";?>"檢查$_POST陣列:表單提交後使用 var_dump 檢查 $_POST 陣列的內...程式設計 發佈於2024-12-29
-
插入資料時如何修復「常規錯誤:2006 MySQL 伺服器已消失」?插入記錄時如何解決「一般錯誤:2006 MySQL 伺服器已消失」介紹:將資料插入MySQL 資料庫有時會導致錯誤「一般錯誤:2006 MySQL 伺服器已消失」。當與伺服器的連線遺失時會出現此錯誤,通常是由於 MySQL 配置中的兩個變數之一所致。 解決方案:解決此錯誤的關鍵是調整wait_tim...程式設計 發佈於2024-12-29
-
如何在 Python 中檢查 NaN(不是數字)?檢查 NaN(不是數字)在 Python 中,NaN(不是數字)由 float('nan') 表示。它用於表示無法表示為實數的值。若要檢查值是否為 NaN,請使用 math.isnan 函數。 範例:import math x = float('nan') if math.isnan...程式設計 發佈於2024-12-29
-
在 Go 中使用 WebSocket 進行即時通信构建需要实时更新的应用程序(例如聊天应用程序、实时通知或协作工具)需要一种比传统 HTTP 更快、更具交互性的通信方法。这就是 WebSockets 发挥作用的地方!今天,我们将探讨如何在 Go 中使用 WebSocket,以便您可以向应用程序添加实时功能。 在这篇文章中,我们将介绍: WebSoc...程式設計 發佈於2024-12-29
-
如何在 React 中有條件地應用類別屬性?在React 中有條件地應用類別屬性在React 中,根據從父組件傳遞的props 來顯示或隱藏元素是很常見的。為此,您可以有條件地應用 CSS 類別。然而,當使用語法 {this.props.condition ? 'show' : 'hidden'} 直接在字串中...程式設計 發佈於2024-12-28
-
如何在Java中執行系統命令並與其他應用程式互動?Java 中運行進程在 Java 中,啟動進程的能力是執行系統命令和與其他應用程式互動的關鍵功能。為了啟動一個流程,Java提供了一個相當於.Net System.Diagnostics.Process.Start方法。 解決方案:取得本地路徑對於執行至關重要Java 中的程序。幸運的是,Java ...程式設計 發佈於2024-12-28
-
如何在 C++ 中建立多行字串文字?C 中的多行字串文字 在 C 中,定義多行字串文字並不像 Perl 等其他語言那麼簡單。但是,您可以使用一些技術來實現此目的:連接字串文字一種方法是利用 C 中相鄰字串文字由編譯器連接的事實。將字串分成多行,您可以建立單一多行字串:const char *text = "This te...程式設計 發佈於2024-12-28
-
如何準確地透視具有不同記錄的資料以避免遺失資訊?有效地透視不同記錄透視查詢在將資料轉換為表格格式、實現輕鬆資料分析方面發揮著至關重要的作用。但是,在處理不同記錄時,資料透視查詢的預設行為可能會出現問題。 問題:忽略不同值考慮下表:------------------------------------------------------ | Id...程式設計 發佈於2024-12-27
-
為什麼 C 和 C++ 忽略函式簽章中的陣列長度?將陣列傳遞給C 和C 中的函數問題:為什麼C和C 編譯器允許在函數簽章中宣告數組長度,例如int dis(char a[1])(當它們不允許時)強制執行? 答案:C 和C 中用於將數組傳遞給函數的語法是歷史上的奇怪現象,它允許將指針傳遞給第一個元素詳細說明:在C 和C 中,數組不是透過函數的引用傳遞...程式設計 發佈於2024-12-26
-
如何刪除 MySQL 中的重音符號以改進自動完成搜尋?在MySQL 中刪除重音符號以實現高效的自動完成搜尋管理大型地名資料庫時,確保準確和高效至關重要資料檢索。使用自動完成功能時,地名中的重音可能會帶來挑戰。為了解決這個問題,一個自然的問題出現了:如何在 MySQL 中刪除重音符號以改善自動完成功能? 解決方案在於為資料庫列使用適當的排序規則設定。透過...程式設計 發佈於2024-12-26
-
如何在MySQL中實作複合外鍵?在 SQL 中實作複合外鍵一個常見的資料庫設計涉及使用複合鍵在表之間建立關係。複合鍵是多個列的組合,唯一標識表中的記錄。在這個場景中,你有兩個表,tutorial和group,你需要將tutorial中的複合唯一鍵連結到group中的欄位。 根據MySQL文檔,MySQL支援外鍵對應到複合鍵。但是,...程式設計 發佈於2024-12-26















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









