
建構常規等變 CNN 的原則
 瀏覽:406
瀏覽:406
The one principle is simply stated as 'Let the kernel rotate' and we will focus in this article on how you can apply it in your architectures.
Equivariant architectures allow us to train models which are indifferent to certain group actions.
To understand what this exactly means, let us train this simple CNN model on the MNIST dataset (a dataset of handwritten digits from 0-9).
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.cl1 = nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, padding=1)
self.max_1 = nn.MaxPool2d(kernel_size=2)
self.cl2 = nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, padding=1)
self.max_2 = nn.MaxPool2d(kernel_size=2)
self.cl3 = nn.Conv2d(in_channels=16, out_channels=16, kernel_size=7)
self.dense = nn.Linear(in_features=16, out_features=10)
def forward(self, x: torch.Tensor):
x = nn.functional.silu(self.cl1(x))
x = self.max_1(x)
x = nn.functional.silu(self.cl2(x))
x = self.max_2(x)
x = nn.functional.silu(self.cl3(x))
x = x.view(len(x), -1)
logits = self.dense(x)
return logits
| Accuracy on test | Accuracy on 90-degree rotated test |
|---|---|
| 97.3% | 15.1% |
Table 1: Test accuracy of the SimpleCNN model
As expected, we get over 95% accuracy on the testing dataset, but what if we rotate the image by 90 degrees? Without any countermeasures applied, the results drop to just slightly better than guessing. This model would be useless for general applications.
In contrast, let us train a similar equivariant architecture with the same number of parameters, where the group actions are exactly the 90-degree rotations.
| Accuracy on test | Accuracy on 90-degree rotated test |
|---|---|
| 96.5% | 96.5% |
Table 2: Test accuracy of the EqCNN model with the same amount of parameters as the SimpleCNN model
The accuracy remains the same, and we did not even opt for data augmentation.
These models become even more impressive with 3D data, but we will stick with this example to explore the core idea.
In case you want to test it out for yourself, you can access all code written in both PyTorch and JAX for free under Github-Repo, and training with Docker or Podman is possible with just two commands.
Have fun!
So What is Equivariance?
Equivariant architectures guarantee stability of features under certain group actions. Groups are simple structures where group elements can be combined, reversed, or do nothing.
You can look up the formal definition on Wikipedia if you are interested.
For our purposes, you can think of a group of 90-degree rotations acting on square images. We can rotate an image by 90, 180, 270, or 360 degrees. To reverse the action, we apply a 270, 180, 90, or 0-degree rotation respectively. It is straightforward to see that we can combine, reverse, or do nothing with the group denoted as C4 . The image visualizes all actions on an image.
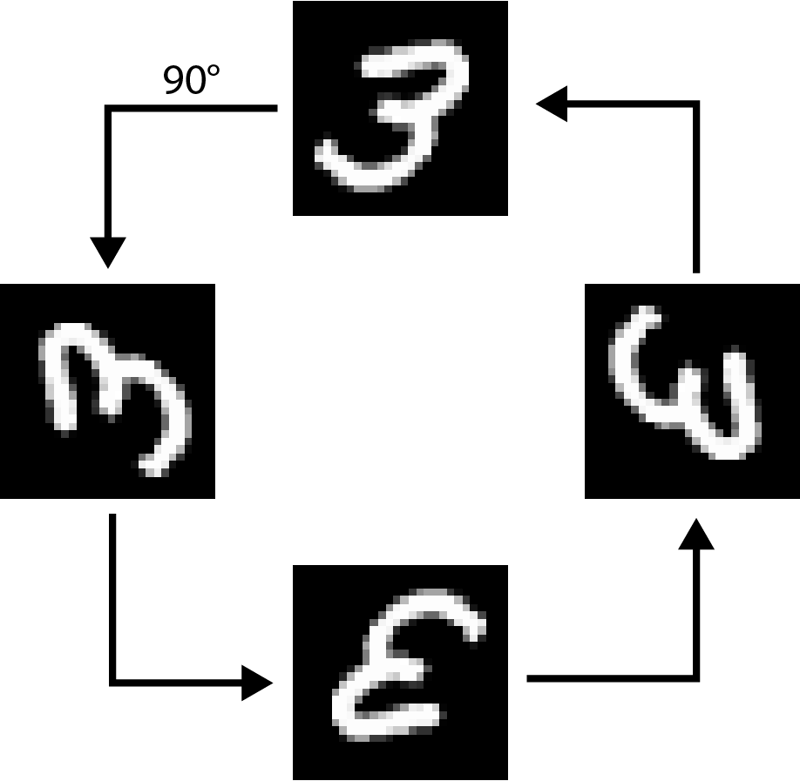
Figure 1: Rotated MNIST image by 90°, 180°, 270°, 360°, respectively
Now, given an input image
x
, our CNN model classifier
fθ
, and an arbitrary 90-degree rotation
g
, the equivariant property can be expressed as
fθ(rotate x by g)=fθ(x)
Generally speaking, we want our image-based model to have the same outputs when rotated.
As such, equivariant models promise us architectures with baked-in symmetries. In the following section, we will see how our principle can be applied to achieve this property.
How to Make Our CNN Equivariant
The problem is the following: When the image rotates, the features rotate too. But as already hinted, we could also compute the features for each rotation upfront by rotating the kernel.
We could actually rotate the kernel, but it is much easier to rotate the feature map itself, thus avoiding interference with PyTorch's autodifferentiation algorithm altogether.
So, in code, our CNN kernel
x = nn.functional.silu(self.cl1(x))
now acts on all four rotated images:
x_0 = x x_90 = torch.rot90(x, k=1, dims=(2, 3)) x_180 = torch.rot90(x, k=2, dims=(2, 3)) x_270 = torch.rot90(x, k=3, dims=(2, 3)) x_0 = nn.functional.silu(self.cl1(x_0)) x_90 = nn.functional.silu(self.cl1(x_90)) x_180 = nn.functional.silu(self.cl1(x_180)) x_270 = nn.functional.silu(self.cl1(x_270))
Or more compactly written as a 3D convolution:
self.cl1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(1, 3, 3)) ... x = torch.stack([x_0, x_90, x_180, x_270], dim=-3) x = nn.functional.silu(self.cl1(x))
The resulting equivariant model has just a few lines more compared to the version above:
class EqCNN(nn.Module):
def __init__(self):
super(EqCNN, self).__init__()
self.cl1 = nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(1, 3, 3))
self.max_1 = nn.MaxPool3d(kernel_size=(1, 2, 2))
self.cl2 = nn.Conv3d(in_channels=8, out_channels=16, kernel_size=(1, 3, 3))
self.max_2 = nn.MaxPool3d(kernel_size=(1, 2, 2))
self.cl3 = nn.Conv3d(in_channels=16, out_channels=16, kernel_size=(1, 5, 5))
self.dense = nn.Linear(in_features=16, out_features=10)
def forward(self, x: torch.Tensor):
x_0 = x
x_90 = torch.rot90(x, k=1, dims=(2, 3))
x_180 = torch.rot90(x, k=2, dims=(2, 3))
x_270 = torch.rot90(x, k=3, dims=(2, 3))
x = torch.stack([x_0, x_90, x_180, x_270], dim=-3)
x = nn.functional.silu(self.cl1(x))
x = self.max_1(x)
x = nn.functional.silu(self.cl2(x))
x = self.max_2(x)
x = nn.functional.silu(self.cl3(x))
x = x.squeeze()
x = torch.max(x, dim=-1).values
logits = self.dense(x)
return logits
But why is this equivariant to rotations?
First, observe that we get four copies of each feature map at each stage. At the end of the pipeline, we combine all of them with a max operation.
This is key, the max operation is indifferent to which place the rotated version of the feature ends up in.
To understand what is happening, let us plot the feature maps after the first convolution stage.
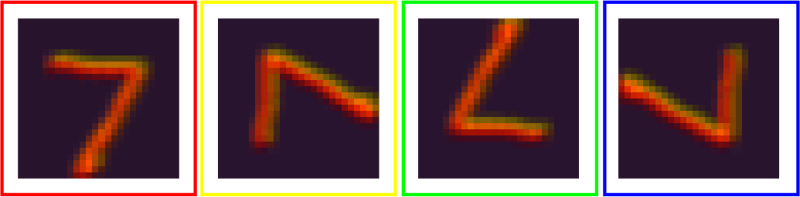
Figure 2: Feature maps for all four rotations
And now the same features after we rotate the input by 90 degrees.
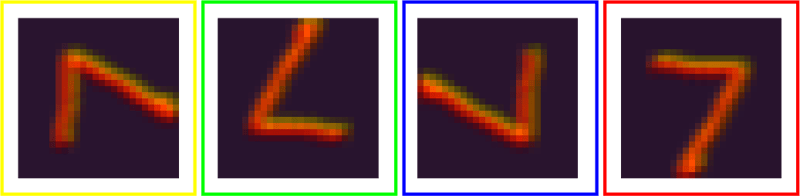
Figure 3: Feature maps for all four rotations after the input image was rotated
I color-coded the corresponding maps. Each feature map is shifted by one. As the final max operator computes the same result for these shifted feature maps, we obtain the same results.
In my code, I did not rotate back after the final convolution, since my kernels condense the image to a one-dimensional array. If you want to expand on this example, you would need to account for this fact.
Accounting for group actions or "kernel rotations" plays a vital role in the design of more sophisticated architectures.
Is it a Free Lunch?
No, we pay in computational speed, inductive bias, and a more complex implementation.
The latter point is somewhat solved with libraries such as E3NN, where most of the heavy math is abstracted away. Nevertheless, one needs to account for a lot during architecture design.
One superficial weakness is the 4x computational cost for computing all rotated feature layers. However, modern hardware with mass parallelization can easily counteract this load. In contrast, training a simple CNN with data augmentation would easily exceed 10x in training time. This gets even worse for 3D rotations where data augmentation would require about 500x the training amount to compensate for all possible rotations.
Overall, equivariance model design is more often than not a price worth paying if one wants stable features.
What is Next?
Equivariant model designs have exploded in recent years, and in this article, we barely scratched the surface. In fact, we did not even exploit the full C4 group yet. We could have used full 3D kernels. However, our model already achieves over 95% accuracy, so there is little reason to go further with this example.
Besides CNNs, researchers have successfully translated these principles to continuous groups, including SO(2) (the group of all rotations in the plane) and SE(3) (the group of all translations and rotations in 3D space).
In my experience, these models are absolutely mind-blowing and achieve performance, when trained from scratch, comparable to the performance of foundation models trained on multiple times larger datasets.
Let me know if you want me to write more on this topic.
Further References
In case you want a formal introduction to this topic, here is an excellent compilation of papers, covering the complete history of equivariance in Machine Learning.
AEN
I actually plan to create a deep-dive, hands-on tutorial on this topic. You can already sign up for my mailing list, and I will provide you with free versions over time, along with a direct channel for feedback and Q&A.
See you around :)
-
 如何在 64 位元機器上安全地將指標轉換為整數?將指標轉換為整數:針對64 位元機器重新檢視將指標轉換為整數:針對64 位元機器重新檢視void function(MESSAGE_ID id, void* param) { if (id == FOO) { int real_param = (int)param; // ......程式設計 發佈於2024-12-23
如何在 64 位元機器上安全地將指標轉換為整數?將指標轉換為整數:針對64 位元機器重新檢視將指標轉換為整數:針對64 位元機器重新檢視void function(MESSAGE_ID id, void* param) { if (id == FOO) { int real_param = (int)param; // ......程式設計 發佈於2024-12-23 -
如何在 Chrome 中安全開啟本機 HTML 檔案?如何在「--allow-file-access-from-files」模式下使用 Chrome 啟動 HTML? 解決此問題需要透過 Google Chrome 以「--allow-file-access-from-files」模式啟動 HTML 檔案。然而,儘管多次嘗試實施以下步驟,但事實證明它並...程式設計 發佈於2024-12-23
-
如何在 JavaScript 中動態產生選擇元素的選項?使用 JavaScript 為選擇元素產生動態選項在 Web 開發中,我們經常遇到為選擇元素創建動態選項的需要。如果手動完成,這可能是一項耗時的任務,尤其是在處理大量選項時。本文提供了使用 JavaScript 自動執行此程序的解決方案。 使用 For 迴圈建立選項一種簡單的方法是使用 for 迴圈...程式設計 發佈於2024-12-23
-
為什麼自動換行在 HTML 表格中不起作用,如何修復?HTML 表格中的自動換行:修復未換行的文字自動換行是CSS 屬性,用於使文字在元素內換行就像div 和span 一樣。但是,它通常無法在表格單元格中工作,導致文字溢出單元格的邊界。 要解決此問題,您可以使用表格的 table-layout:fixed CSS 屬性。此屬性強製表格具有固定佈局,使其...程式設計 發佈於2024-12-23
-
什麼時候應該在 C++ 中使用 `std::size_t` 作為循環計數器?何時在C 碼中使用std::size_t問題:何時使用C 中的循環,特別是在比較數組大小的情況下,最好使用std::size_t而不是像這樣的原始資料類型int?範例:#include <cstdint> int main() { for (std::size_t i = 0; ...程式設計 發佈於2024-12-23
-
我應該對網站上的圖像使用 Base64 編碼嗎?了解以 Base64 編碼圖像的影響將圖像轉換為 Base64 編碼是 Web 開發中的常見做法。然而,重要的是要了解它對檔案大小和網站效能的影響。 Base64 編碼影像的大小增加當影像轉換為 Base64 時,其大小通常會增加約 37%。這是因為Base64編碼使用6位元字元集來表示8位元數據,...程式設計 發佈於2024-12-23
-
插入資料時如何修復「常規錯誤:2006 MySQL 伺服器已消失」?插入記錄時如何解決「一般錯誤:2006 MySQL 伺服器已消失」介紹:將資料插入MySQL 資料庫有時會導致錯誤「一般錯誤:2006 MySQL 伺服器已消失」。當與伺服器的連線遺失時會出現此錯誤,通常是由於 MySQL 配置中的兩個變數之一所致。 解決方案:解決此錯誤的關鍵是調整wait_tim...程式設計 發佈於2024-12-23
-
如何在 PHP 中組合兩個關聯數組,同時保留唯一 ID 並處理重複名稱?在 PHP 中組合關聯數組在 PHP 中,將兩個關聯數組組合成一個數組是常見任務。考慮以下請求:問題描述:提供的代碼定義了兩個關聯數組,$array1 和 $array2。目標是建立一個新陣列 $array3,它合併兩個陣列中的所有鍵值對。 此外,提供的陣列具有唯一的 ID,而名稱可能重疊。要求是建...程式設計 發佈於2024-12-23
-
考慮到版本特定的行為,如何正確地將 Java 陣列轉換為列表?在Java 中將陣列轉換為清單:陣列與清單轉換之旅在資料操作領域,陣列與清單之間的轉換清單是Java 等程式語言中的基礎操作。然而,這種轉換的複雜性可能會帶來挑戰,特別是由於 Java 版本之間行為的微妙變化。 Arrays.asList() 行為的演變The Arrays.asList() 方法從...程式設計 發佈於2024-12-23
-
為什麼 Python 會拋出 UnboundLocalError?UnboundLocalError 是如何發生的:Python 中的未綁定名稱和變數綁定在Python 中,變數綁定決定了變數的作用域和生命週期。當名稱未分配值時,它被視為未綁定。這可能會導致 UnboundLocalError 異常。 了解未綁定局部變數與具有明確宣告的語言不同,Python 允許...程式設計 發佈於2024-12-23
-
透過「jQuery 快速入門」課程釋放您的 Web 開發技能您準備好提升您的 Web 開發專業知識並釋放最受歡迎的 JavaScript 庫 jQuery 的強大功能了嗎? LabEx 提供的「jQuery 快速入門」課程就是您的最佳選擇。這個綜合性的程式將引導您了解 jQuery 的基礎知識,使您能夠操作文件物件模型 (DOM) 並為您的網頁注入迷人的互動...程式設計 發佈於2024-12-23
-
如何在 MySQL WHERE IN() 子句中處理具有多個值的記錄?MySQL IN () 運算子查詢MySQL 資料庫時,WHERE IN () 運算子常用於根據特定條件擷取行列中的值。例如,以下查詢從「table」表中擷取「id」列與任意值(1、2、3、4) 相符的所有行:SELECT * FROM table WHERE id IN (1,2,3,4);但是,...程式設計 發佈於2024-12-23
-
如何根據與特定值相符的列值過濾數組行?基於列值包含的行子集考慮一個具有多個列的數組$arr1 和第二個平面數組$arr2 ,包含特定的id 值。目標是過濾 $arr1 以僅保留列值與 $arr2 中的任何值相符的行。 先前使用篩選函數或 array_search 的嘗試已證明不成功。一個實用的解決方案涉及使用本機 PHP 函數 arra...程式設計 發佈於2024-12-23
-
如何使用 DockerMake 將多個 Docker 映像合併為一個映像?組合多個 Docker 映像Docker 不直接支援將多個 Docker 映像組合成一個統一的映像。但是,可以使用第三方工具來促進此過程。 DockerMake 就是這樣一個工具,可以創造複雜的映像繼承場景。 使用 DockerMake 組合映像DockerMake 透過使用 YAML 檔案定義之間...程式設計 發佈於2024-12-23















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









