
Go 中的機率提前過期
 瀏覽:708
瀏覽:708
关于缓存踩踏
我经常遇到需要缓存这个或那个的情况。通常,这些值会被缓存一段时间。您可能熟悉这种模式。您尝试从缓存中获取一个值,如果成功,则将其返回给调用者并结束。如果该值不存在,您将获取它(很可能从数据库中)或计算它并将其放入缓存中。在大多数情况下,这非常有效。但是,如果您用于缓存条目的密钥被频繁访问,并且计算数据的操作需要一段时间,您最终会遇到多个并行请求同时发生缓存未命中的情况。所有这些请求都将从源独立加载并将值存储在缓存中。这会导致资源浪费,甚至可能导致拒绝服务。
让我举个例子来说明一下。我将使用 Redis 进行缓存,并在顶部使用一个简单的 Go http 服务器。完整代码如下:
package main
import (
"errors"
"log"
"net/http"
"time"
"github.com/redis/go-redis/v9"
)
type handler struct {
rdb *redis.Client
cacheTTL time.Duration
}
func (ch *handler) simple(w http.ResponseWriter, r *http.Request) {
cacheKey := "my_cache_key"
// we'll use 200 to signify a cache hit & 201 to signify a miss
responseCode := http.StatusOK
cachedData, err := ch.rdb.Get(r.Context(), cacheKey).Result()
if err != nil {
if !errors.Is(err, redis.Nil) {
log.Println("could not reach redis", err.Error())
http.Error(w, "could not reach redis", http.StatusInternalServerError)
return
}
// cache miss - fetch & store
res := longRunningOperation()
responseCode = http.StatusCreated
err = ch.rdb.Set(r.Context(), cacheKey, res, ch.cacheTTL).Err()
if err != nil {
log.Println("failed to set cache value", err.Error())
http.Error(w, "failed to set cache value", http.StatusInternalServerError)
return
}
cachedData = res
}
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
}
func longRunningOperation() string {
time.Sleep(time.Millisecond * 500)
return "hello"
}
func main() {
ttl := time.Second * 3
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
handler := &handler{
rdb: rdb,
cacheTTL: ttl,
}
http.HandleFunc("/simple", handler.simple)
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatalf("Could not start server: %s\n", err.Error())
}
}
让我们在 /simple 端点上施加一些负载,看看会发生什么。我将使用 vegeta 来实现此目的。
我运行 vegeta Attack -duration=30s -rate=500 -targets=./targets_simple.txt > res_simple.bin。 Vegeta 最终每秒发出 500 个请求,持续 30 秒。我将它们绘制为 HTTP 结果代码的直方图,其中每个桶的跨度为 100 毫秒。结果如下图。
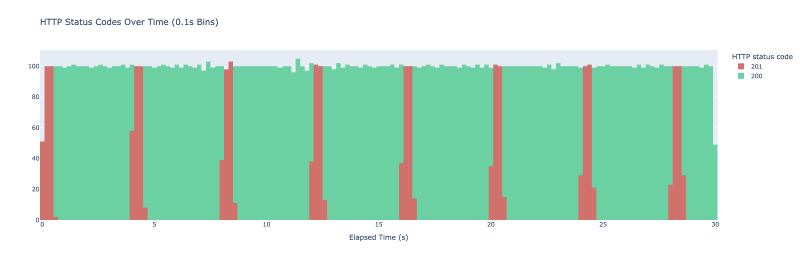
当我们开始实验时,缓存是空的——我们没有存储任何值。当一堆请求到达我们的服务器时,我们得到了最初的踩踏。他们都检查缓存,没有发现任何内容,调用 longRunningOperation 并将其存储在缓存中。由于 longRunningOperation 大约需要 500 毫秒才能完成前 500 毫秒内发出的任何请求,最终都会调用 longRunningOperation。一旦其中一个请求设法将值存储在缓存中,所有后续请求都会从缓存中获取该值,我们开始看到状态代码为 200 的响应。然后,随着 Redis 上的过期机制启动,该模式每 3 秒重复一次。
在这个玩具示例中,这不会导致任何问题,但在生产环境中,这可能会导致系统上不必要的负载、用户体验下降,甚至自我诱导的拒绝服务。那么我们怎样才能防止这种情况发生呢?嗯,有几种方法。我们可以引入锁——任何缓存未命中都会导致代码尝试实现锁。分布式锁定并不是一件简单的事情,通常它们有微妙的边缘情况,需要微妙的处理。我们还可以使用后台作业定期重新计算该值,但这需要运行一个额外的进程,引入另一个需要在我们的代码中维护和监视的齿轮。如果您有动态缓存键,则此方法也可能不可行。还有另一种方法,称为概率提前过期,这是我想进一步探索的方法。
概率提前到期
这种技术允许人们根据概率重新计算该值。从缓存中获取值时,您还可以根据概率计算是否需要重新生成缓存值。越接近现有价值到期,概率就越高。
我的具体实现基于 A. Vattani、F.Chierichetti 和 K. Lowenstein 在《最佳概率缓存踩踏预防》中的 XFetch。
我将在 HTTP 服务器上引入一个新端点,该端点也将执行昂贵的计算,但这次在缓存时使用 XFetch。为了使 XFetch 工作,我们需要存储昂贵的操作花费了多长时间(增量)以及缓存键何时过期。为了实现这一目标,我将引入一个结构体来保存这些值以及消息本身:
type probabilisticValue struct {
Message string
Expiry time.Time
Delta time.Duration
}
我添加一个函数来用这些属性包装原始消息并将其序列化以存储在redis中:
func wrapMessage(message string, delta, cacheTTL time.Duration) (string, error) {
bts, err := json.Marshal(probabilisticValue{
Message: message,
Delta: delta,
Expiry: time.Now().Add(cacheTTL),
})
if err != nil {
return "", fmt.Errorf("could not marshal message: %w", err)
}
return string(bts), nil
}
我们还编写一个方法来重新计算并将值存储到redis中:
func (ch *handler) recomputeValue(ctx context.Context, cacheKey string) (string, error) {
start := time.Now()
message := longRunningOperation()
delta := time.Since(start)
wrapped, err := wrapMessage(message, delta, ch.cacheTTL)
if err != nil {
return "", fmt.Errorf("could not wrap message: %w", err)
}
err = ch.rdb.Set(ctx, cacheKey, wrapped, ch.cacheTTL).Err()
if err != nil {
return "", fmt.Errorf("could not save value: %w", err)
}
return message, nil
}
为了确定是否需要根据概率更新值,我们可以在 probabilisticValue 中添加一个方法:
func (pv probabilisticValue) shouldUpdate() bool {
// suggested default param in XFetch implementation
// if increased - results in earlier expirations
beta := 1.0
now := time.Now()
scaledGap := pv.Delta.Seconds() * beta * math.Log(rand.Float64())
return now.Sub(pv.Expiry).Seconds() >= scaledGap
}
如果我们将其全部连接起来,我们最终会得到以下处理程序:
func (ch *handler) probabilistic(w http.ResponseWriter, r *http.Request) {
cacheKey := "probabilistic_cache_key"
// we'll use 200 to signify a cache hit & 201 to signify a miss
responseCode := http.StatusOK
cachedData, err := ch.rdb.Get(r.Context(), cacheKey).Result()
if err != nil {
if !errors.Is(err, redis.Nil) {
log.Println("could not reach redis", err.Error())
http.Error(w, "could not reach redis", http.StatusInternalServerError)
return
}
res, err := ch.recomputeValue(r.Context(), cacheKey)
if err != nil {
log.Println("could not recompute value", err.Error())
http.Error(w, "could not recompute value", http.StatusInternalServerError)
return
}
responseCode = http.StatusCreated
cachedData = res
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
return
}
pv := probabilisticValue{}
err = json.Unmarshal([]byte(cachedData), &pv)
if err != nil {
log.Println("could not unmarshal probabilistic value", err.Error())
http.Error(w, "could not unmarshal probabilistic value", http.StatusInternalServerError)
return
}
if pv.shouldUpdate() {
_, err := ch.recomputeValue(r.Context(), cacheKey)
if err != nil {
log.Println("could not recompute value", err.Error())
http.Error(w, "could not recompute value", http.StatusInternalServerError)
return
}
responseCode = http.StatusAccepted
}
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
}
处理程序的工作方式与第一个处理程序非常相似,但是,在获得缓存命中后,我们就掷骰子。根据结果,我们要么只返回刚刚获取的值,要么提前更新该值。
我们将使用 HTTP 状态代码来确定 3 种情况:
- 200 - 我们从缓存返回值
- 201 - 缓存未命中,不存在值
- 202 - 缓存命中,触发概率更新
这次我再次启动 vegeta 在新端点上运行,结果如下:
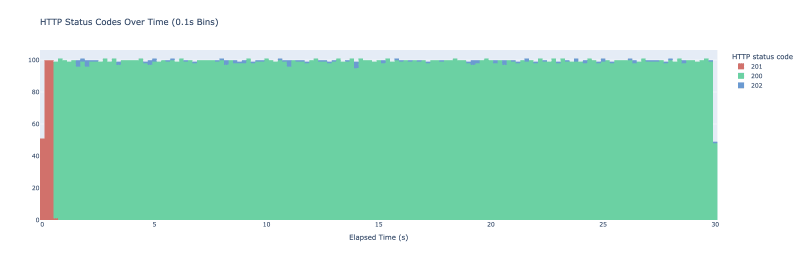
那里的微小蓝色斑点表明我们实际上何时提前结束了缓存值的更新。在初始预热期后,我们不再看到缓存未命中。为了避免初始峰值,如果这对您的用例很重要,您可以预先存储缓存值。
如果您想更积极地进行缓存并更频繁地刷新值,您可以使用 beta 参数。以下是将 beta 参数设置为 2 时相同实验的结果:
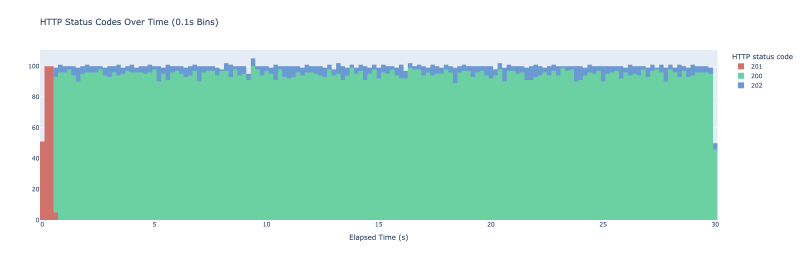
我们现在看到概率更新更加频繁。
总而言之,这是一个巧妙的小技术,可以帮助避免缓存踩踏。但请记住,这仅在您定期从缓存中获取相同密钥时才有效 - 否则您不会看到太多好处。
有另一种方法来处理缓存踩踏吗?注意到一个错误吗?请在下面的评论中告诉我!
-
 如何在 PHP 中有效率地計算兩個日期之間的月份數?有效找出日期之間的月份計數一個常見的程式設計挑戰是確定兩個日期之間的月份數。在 PHP 中,有許多方法可以解決這個問題。 使用 DateTime 類別 (PHP >= 5.3):PHP 5.3 中引入的 DateTime 類別提供了方便的方法用於日期操作。計算月份差異:$d1 = new DateT...程式設計 發佈於2024-11-08
如何在 PHP 中有效率地計算兩個日期之間的月份數?有效找出日期之間的月份計數一個常見的程式設計挑戰是確定兩個日期之間的月份數。在 PHP 中,有許多方法可以解決這個問題。 使用 DateTime 類別 (PHP >= 5.3):PHP 5.3 中引入的 DateTime 類別提供了方便的方法用於日期操作。計算月份差異:$d1 = new DateT...程式設計 發佈於2024-11-08 -
Bootstrap:建立和自訂導覽列介紹 Bootstrap 是一個開源框架,廣泛用於 Web 開發,用於建立響應式且適合行動裝置的網站。 Bootstrap 的關鍵元件之一是導覽欄,它是一個水平導覽欄,用於組織和導覽網站的內容。在本文中,我們將討論使用 Bootstrap 建立和自訂導覽列的優點和缺點及其功能。 ...程式設計 發佈於2024-11-08
-
將 WebSocket 與 Python 結合使用什麼是 WebSocket? WebSocket 是一種支援瀏覽器和伺服器之間即時、雙向通訊的協定。傳統的 HTTP 通訊涉及客戶端發送請求和伺服器回應以交換資料。相較之下,使用 WebSocket,一旦建立了初始連接,客戶端和伺服器都可以相互發送和接收訊息,而無需重複建立新連接。...程式設計 發佈於2024-11-08
-
如何在 PHP 中從子網域中提取網域?在PHP 中從子域中提取域名在當代Web 開發中,必須解析和檢索域名,甚至是從子域中解析和檢索網域名稱。一個簡單的範例可能包括諸如“here.example.com”或“example.org”之類的網域。為了滿足這一需求,我們提出了一個全面的 PHP 函數,旨在從任何給定的輸入中提取根域名。 結合...程式設計 發佈於2024-11-08
-
如何在多執行緒程式設計中連接向量以獲得最佳效率?連結向量:深入分析在多執行緒程式設計中,合併結果是一個常見的挑戰。這通常涉及將多個向量組合成單一綜合向量。讓我們探索連接向量以獲得最大效率的最佳方法。 最佳連接方法為了高效的向量連接,最佳實踐是利用保留和插入方法:AB.reserve(A.size() B.size()); // Preallo...程式設計 發佈於2024-11-08
-
如何優化FastAPI以實現高效的JSON資料回傳?FastAPI 傳回大型 JSON 資料的最佳化透過 FastAPI 傳回大量 JSON 資料集可能是一項耗時的任務。為了解決這個瓶頸,我們探索提高效能的替代方法。 識別瓶頸:使用 json.dumps 將 Parquet 檔案解析為 JSON 的初始方法( ) 和 json.loads() 效率低...程式設計 發佈於2024-11-08
-
React:狀態 X 派生狀態什麼是派生狀態?考慮文字的一種狀態,然後考慮大寫文字的另一種狀態。 匯出狀態 function Foo() { const [text, setText] = useState('hello, za warudo!'); const [uppercaseText, ...程式設計 發佈於2024-11-08
-
如何使用自訂使用者類型將 PostgreSQL JSON 欄位對應到 Hibernate 實體?將 PostgreSQL JSON 欄位對應到 Hibernate 實體使用 PostgreSQL 資料庫時,常常會遇到以 JSON 格式儲存資料的資料列。為了使用 Hibernate 有效地將這些欄位對應到 Java 實體,選擇適當的資料類型至關重要。 在這種情況下,目前的問題圍繞著將 Postg...程式設計 發佈於2024-11-08
-
確保整個團隊的 Node.js 版本一致.nvmrc 和 package.json 綜合指南 在現今動態的開發環境中,跨不同專案管理多個 Node.js 版本通常是一項複雜且容易出錯的任務。 Node.js 版本不一致可能會導致許多問題,從意外行為到應用程式完全失敗。 利用 .nvmrc 檔案進行版本控制 在專案中保持一...程式設計 發佈於2024-11-08
-
何時在 JavaScript Promise 中使用 Promise.reject 與 Throw?JavaScript Promise:Reject 與Throw 之謎使用JavaScript Promise 時,開發人員經常面臨一個困境:他們是否應該使用Promise . reject 或者只是拋出一個錯誤?雖然這兩種方法具有相似的目的,但關於它們的差異和潛在優勢仍然存在混淆。 探索相似之處最...程式設計 發佈於2024-11-08
-
建立 Chrome 擴充功能:快速概述模组——修改? 如果您喜欢游戏,您就会知道没有什么比玩模组游戏更好的了。这是您最喜欢的游戏,但具有额外的功能、功能和乐趣。现在,想象一下为您的网络浏览体验带来同样的兴奋。这正是浏览器扩展的作用——它们就像浏览器的模组,以您从未想过的方式增强浏览器的功能。 通过 Chrome 扩展程序,您可以调整浏览...程式設計 發佈於2024-11-08
-
如何使用 CSS 設定表格列寬?設定表格列寬表格通常用於呈現表格數據,但調整列寬對於確保可讀性和正確性至關重要結盟。在本文中,我們將探討如何使用 CSS 設定表格列的寬度。 使用 CSS 寬度屬性的方法表格列的寬度可以使用 col 元素的 width 屬性進行設定。寬度值可以以像素為單位指定(例如 width: 200px;),也...程式設計 發佈於2024-11-08
-
如何從 Python 中的巢狀函數存取非局部變數?存取嵌套函數作用域中的非局部變數在Python 中,嵌套函數作用域提供對封閉作用域的訪問。但是,嘗試修改巢狀函數內封閉範圍內的變數可能會導致 UnboundLocalError。 要解決此問題,您有多種選擇:1。使用 'nonlocal' 關鍵字 (Python 3 ):對於 Pyt...程式設計 發佈於2024-11-08
-
使用 CSS 將漸層應用於文字。文字漸變 現在你可以在很多地方看到像文字漸變這樣的好技巧......但是呢?你有沒有想過它們是如何製作的?今天就讓我來教你。 .text-gradient { background: linear-gradient(-25deg, #5662f6 0%, #7fffd4 10...程式設計 發佈於2024-11-08
-
如何在Python中執行自訂區間舍入?Python 中捨入為自訂間隔在 Python 中,內建 round() 函數通常用於對數值進行舍入。然而,它採用以 10 為基數的捨入方案,這可能並不總是適合特定要求。例如,如果您想將數字四捨五入到最接近的 5 倍數,則標準 round() 函數不合適。 要解決此問題,可以建立自訂函數,將數值四捨...程式設計 發佈於2024-11-08















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









