
優化網頁抓取:使用 JSDOM 抓取身份驗證數據
 瀏覽:811
瀏覽:811
作为抓取开发人员,我们有时需要提取临时密钥等身份验证数据来执行我们的任务。然而,事情并没有那么简单。通常,它位于 HTML 或 XHR 网络请求中,但有时,会计算身份验证数据。在这种情况下,我们可以对计算进行逆向工程,这需要花费大量时间来对脚本进行反混淆,或者运行计算它的 JavaScript。通常,我们使用浏览器,但这很昂贵。 Crawlee 支持并行运行浏览器抓取工具和 Cheerio Scraper,但这在计算资源使用方面非常复杂且昂贵。 JSDOM 帮助我们以比浏览器更少的资源运行页面 JavaScript,并且比 Cheerio 略高。
本文将讨论一种新方法,我们在一个 Actor 中使用该方法,从浏览器 Web 应用程序生成的 TikTok 广告创意中心获取身份验证数据,而无需实际运行浏览器,而是使用 JSDOM。
分析网站
当您访问此网址时:
https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pc/en
您将看到主题标签列表,其中包含其实时排名、帖子数量、趋势图、创建者和分析。您还可以注意到,我们可以筛选行业、设置时间段,并使用复选框来筛选趋势是否新进入前 100 名。
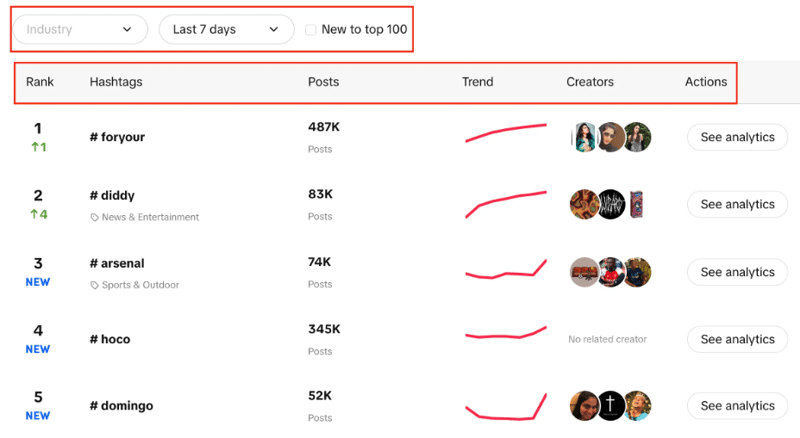
我们的目标是使用给定的过滤器从列表中提取前 100 个主题标签。
两种可能的方法是使用 CheerioCrawler,第二种方法是基于浏览器的抓取。 Cheerio 可以更快地提供结果,但不适用于 JavaScript 渲染的网站。
Cheerio 在这里不是最佳选择,因为 Creative Center 是一个 Web 应用程序,数据源是 API,因此我们只能获取最初出现在 HTML 结构中的主题标签,而不能获取我们需要的 100 个主题标签中的每一个。
第二种方法可以使用 Puppeteer、Playwright 等库来进行基于浏览器的抓取,并使用自动化来抓取所有主题标签,但根据以前的经验,这么小的任务需要花费大量时间。
现在我们开发了新方法,使这个过程比基于浏览器的抓取要好得多,并且非常接近基于 CheerioCrawler 的抓取。
JSDOM 方法
在深入研究这种方法之前,我想感谢 Apify 的 Web 自动化工程师 Alexey Udovydchenko 开发了这种方法。向他致敬!
在此方法中,我们将对 https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list 进行 API 调用以获取所需的数据。
在调用此 API 之前,我们需要一些必需的标头(身份验证数据),因此我们将首先调用 https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad /en.
我们将通过创建一个函数来开始这种方法,该函数将为我们创建 API 调用的 URL,然后进行调用并获取数据。
export const createStartUrls = (input) => {
const {
days = '7',
country = '',
resultsLimit = 100,
industry = '',
isNewToTop100,
} = input;
const filterBy = isNewToTop100 ? 'new_on_board' : '';
return [
{
url: `https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list?page=1&limit=50&period=${days}&country_code=${country}&filter_by=${filterBy}&sort_by=popular&industry_id=${industry}`,
headers: {
// required headers
},
userData: { resultsLimit },
},
];
};
在上面的函数中,我们创建 API 调用的起始 URL,其中包含我们之前讨论过的各种参数。根据参数创建URL后,它将调用creative_radar_api并获取所有结果。
但是在我们获得标头之前它不会起作用。因此,让我们创建一个函数,该函数首先使用 sessionPool 和 proxyConfiguration 创建会话。
export const createSessionFunction = async (
sessionPool,
proxyConfiguration,
) => {
const proxyUrl = await proxyConfiguration.newUrl(Math.random().toString());
const url =
'https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en';
// need url with data to generate token
const response = await gotScraping({ url, proxyUrl });
const headers = await getApiUrlWithVerificationToken(
response.body.toString(),
url,
);
if (!headers) {
throw new Error(`Token generation blocked`);
}
log.info(`Generated API verification headers`, Object.values(headers));
return new Session({
userData: {
headers,
},
sessionPool,
});
};
在此函数中,主要目标是调用 https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en 并获取 headers 作为返回。为了获取标头,我们使用 getApiUrlWithVerificationToken 函数。
在继续之前,我想提一下,Crawlee 使用 JSDOM Crawler 原生支持 JSDOM。它提供了一个使用普通 HTTP 请求和 jsdom DOM 实现并行抓取网页的框架。它使用原始 HTTP 请求来下载网页,数据带宽非常快且高效。
让我们看看如何创建 getApiUrlWithVerificationToken 函数:
const getApiUrlWithVerificationToken = async (body, url) => {
log.info(`Getting API session`);
const virtualConsole = new VirtualConsole();
const { window } = new JSDOM(body, {
url,
contentType: 'text/html',
runScripts: 'dangerously',
resources: 'usable' || new CustomResourceLoader(),
// ^ 'usable' faster than custom and works without canvas
pretendToBeVisual: false,
virtualConsole,
});
virtualConsole.on('error', () => {
// ignore errors cause by fake XMLHttpRequest
});
const apiHeaderKeys = ['anonymous-user-id', 'timestamp', 'user-sign'];
const apiValues = {};
let retries = 10;
// api calls made outside of fetch, hack below is to get URL without actual call
window.XMLHttpRequest.prototype.setRequestHeader = (name, value) => {
if (apiHeaderKeys.includes(name)) {
apiValues[name] = value;
}
if (Object.values(apiValues).length === apiHeaderKeys.length) {
retries = 0;
}
};
window.XMLHttpRequest.prototype.open = (method, urlToOpen) => {
if (
['static', 'scontent'].find((x) =>
urlToOpen.startsWith(`https://${x}`),
)
)
log.debug('urlToOpen', urlToOpen);
};
do {
await sleep(4000);
retries--;
} while (retries > 0);
await window.close();
return apiValues;
};
在此函数中,我们将创建一个虚拟控制台,它使用 CustomResourceLoader 来运行后台进程并用 JSDOM 替换浏览器。
对于这个特定的示例,我们需要三个强制标头来进行 API 调用,它们是匿名用户 ID、时间戳和用户签名。
使用 XMLHttpRequest.prototype.setRequestHeader,我们检查提到的标头是否在响应中,如果是,我们获取这些标头的值,并重复重试,直到获得所有标头。
然后,最重要的部分是我们使用 XMLHttpRequest.prototype.open 提取身份验证数据并进行调用,而无需实际使用浏览器或公开机器人活动。
在 createSessionFunction 的末尾,它返回一个具有所需标头的会话。
现在来到我们的主要代码,我们将使用 CheerioCrawler 并使用 prenavigationHooks 将从前面的函数获取的标头注入到 requestHandler 中。
const crawler = new CheerioCrawler({
sessionPoolOptions: {
maxPoolSize: 1,
createSessionFunction: async (sessionPool) =>
createSessionFunction(sessionPool, proxyConfiguration),
},
preNavigationHooks: [
(crawlingContext) => {
const { request, session } = crawlingContext;
request.headers = {
...request.headers,
...session.userData?.headers,
};
},
],
proxyConfiguration,
});
最后,在请求处理程序中,我们使用标头进行调用,并确保需要多少次调用来获取所有数据处理分页。
async requestHandler(context) {
const { log, request, json } = context;
const { userData } = request;
const { itemsCounter = 0, resultsLimit = 0 } = userData;
if (!json.data) {
throw new Error('BLOCKED');
}
const { data } = json;
const items = data.list;
const counter = itemsCounter items.length;
const dataItems = items.slice(
0,
resultsLimit && counter > resultsLimit
? resultsLimit - itemsCounter
: undefined,
);
await context.pushData(dataItems);
const {
pagination: { page, total },
} = data;
log.info(
`Scraped ${dataItems.length} results out of ${total} from search page ${page}`,
);
const isResultsLimitNotReached =
counter
这里需要注意的一件重要事情是,我们正在以可以进行任意数量的 API 调用的方式编写此代码。
在此特定示例中,我们仅发出了一个请求和一个会话,但如果需要,您可以发出更多请求。当第一个 API 调用完成时,它将创建第二个 API 调用。同样,如果需要,您可以拨打更多电话,但我们只打了两个电话。
为了让事情更清楚,代码流程如下:
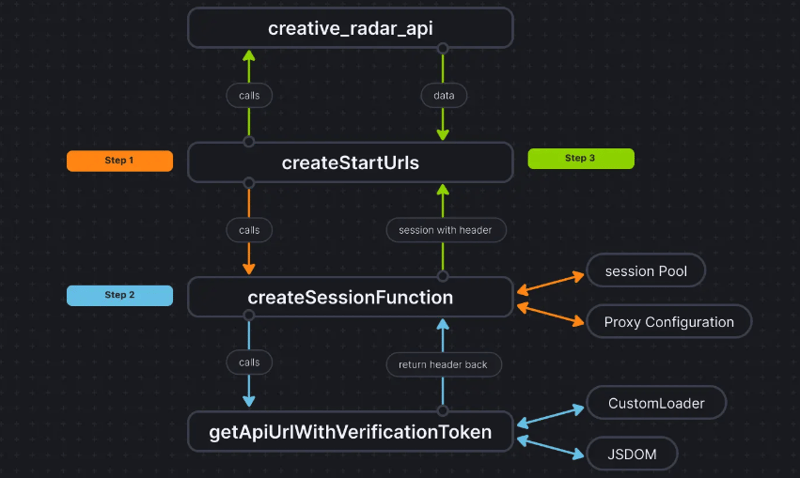
结论
这种方法帮助我们获得第三种方法来提取身份验证数据,而无需实际使用浏览器并将数据传递给 CheerioCrawler。这显着提高了性能,并将 RAM 要求降低了 50%,虽然基于浏览器的抓取性能比纯 Cheerio 慢十倍,但 JSDOM 仅慢 3-4 倍,这使其比浏览器快 2-3 倍 -基于抓取。
该项目的代码库已上传至此处。代码是作为 Apify Actor 编写的;您可以在此处找到有关它的更多信息,但您也可以在不使用 Apify SDK 的情况下运行它。
如果您对此方法有任何疑问或疑问,请通过我们的 Discord 服务器联系我们。
-
 哪種方法更有效地用於點 - 填點檢測:射線跟踪或matplotlib \的路徑contains_points?在Python Matplotlib's path.contains_points FunctionMatplotlib's path.contains_points function employs a path object to represent the polygon.它...程式設計 發佈於2025-07-12
哪種方法更有效地用於點 - 填點檢測:射線跟踪或matplotlib \的路徑contains_points?在Python Matplotlib's path.contains_points FunctionMatplotlib's path.contains_points function employs a path object to represent the polygon.它...程式設計 發佈於2025-07-12 -
為什麼HTML無法打印頁碼及解決方案無法在html頁面上打印頁碼? @page規則在@Media內部和外部都無濟於事。 HTML:Customization:@page { margin: 10%; @top-center { font-family: sans-serif; font-weight: ...程式設計 發佈於2025-07-12
-
如何使用FormData()處理多個文件上傳?)處理多個文件輸入時,通常需要處理多個文件上傳時,通常是必要的。 The fd.append("fileToUpload[]", files[x]); method can be used for this purpose, allowing you to send multi...程式設計 發佈於2025-07-12
-
Java為何無法創建泛型數組?通用陣列創建錯誤 arrayList [2]; JAVA報告了“通用數組創建”錯誤。為什麼不允許這樣做? 答案:Create an Auxiliary Class:public static ArrayList<myObject>[] a = new ArrayList<my...程式設計 發佈於2025-07-12
-
C++成員函數指針正確傳遞方法如何將成員函數置於c 的函數時,接受成員函數指針的函數時,必須同時提供對象的指針,並提供指針和指針到函數。需要具有一定簽名的功能指針。要通過成員函數,您需要同時提供對象指針(此)和成員函數指針。這可以通過修改Menubutton :: SetButton()(如下所示:[&& && && &&華)...程式設計 發佈於2025-07-12
-
如何正確使用與PDO參數的查詢一樣?在pdo 中使用類似QUERIES在PDO中的Queries時,您可能會遇到類似疑問中描述的問題:此查詢也可能不會返回結果,即使$ var1和$ var2包含有效的搜索詞。錯誤在於不正確包含%符號。 通過將變量包含在$ params數組中的%符號中,您確保將%字符正確替換到查詢中。沒有此修改,PD...程式設計 發佈於2025-07-12
-
解決MySQL插入Emoji時出現的\\"字符串值錯誤\\"異常Resolving Incorrect String Value Exception When Inserting EmojiWhen attempting to insert a string containing emoji characters into a MySQL database us...程式設計 發佈於2025-07-12
-
Java的Map.Entry和SimpleEntry如何簡化鍵值對管理?A Comprehensive Collection for Value Pairs: Introducing Java's Map.Entry and SimpleEntryIn Java, when defining a collection where each element com...程式設計 發佈於2025-07-12
-
如何使用Depimal.parse()中的指數表示法中的數字?在嘗試使用Decimal.parse(“ 1.2345e-02”中的指數符號表示法表示的字符串時,您可能會遇到錯誤。這是因為默認解析方法無法識別指數符號。 成功解析這樣的字符串,您需要明確指定它代表浮點數。您可以使用numbersTyles.Float樣式進行此操作,如下所示:[&& && && ...程式設計 發佈於2025-07-12
-
為什麼在我的Linux服務器上安裝Archive_Zip後,我找不到“ class \” class \'ziparchive \'錯誤?Class 'ZipArchive' Not Found Error While Installing Archive_Zip on Linux ServerSymptom:When attempting to run a script that utilizes the ZipAr...程式設計 發佈於2025-07-12
-
圖片在Chrome中為何仍有邊框? `border: none;`無效解決方案在chrome 中刪除一個頻繁的問題時,在與Chrome and IE9中的圖像一起工作時,遇到了一個頻繁的問題。和“邊境:無;”在CSS中。要解決此問題,請考慮以下方法: Chrome具有忽略“ border:none; none;”的已知錯誤,風格。要解決此問題,請使用以下CSS ID塊創建帶...程式設計 發佈於2025-07-12
-
為什麼Microsoft Visual C ++無法正確實現兩台模板的實例?The Mystery of "Broken" Two-Phase Template Instantiation in Microsoft Visual C Problem Statement:Users commonly express concerns that Micro...程式設計 發佈於2025-07-12
-
對象擬合:IE和Edge中的封面失敗,如何修復?To resolve this issue, we employ a clever CSS solution that solves the problem:position: absolute;top: 50%;left: 50%;transform: translate(-50%, -50%)...程式設計 發佈於2025-07-12
-
如何在JavaScript對像中動態設置鍵?在嘗試為JavaScript對象創建動態鍵時,如何使用此Syntax jsObj['key' i] = 'example' 1;不工作。正確的方法採用方括號: jsobj ['key''i] ='example'1; 在JavaScript中,數組是一...程式設計 發佈於2025-07-12
-
如何實時捕獲和流媒體以進行聊天機器人命令執行?在開發能夠執行命令的chatbots的領域中,實時從命令執行實時捕獲Stdout,一個常見的需求是能夠檢索和顯示標準輸出(stdout)在cath cath cant cant cant cant cant cant cant cant interfaces in Chate cant inter...程式設計 發佈於2025-07-12















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









