
NestJS + Opentelemetry(採樣)
 瀏覽:487
瀏覽:487
格拉法納雲
在上一篇文章中,我在 Grafana Cloud 中拍攝、保存和查看了 Opentelemetry 資料
。如果您使用免費版本的 Grafana Cloud,您每月可以獲得約 50GB 的日誌和追蹤。如果是因為使用者不多所以不累積痕跡(或不記錄日誌)的服務,直接使用就可以了,但是如果小範圍引入的話,恐怕會累積太多的日誌而無法使用。爆炸。
取樣抽樣是指從整體中抽取一部分。因此,任務是減少儲存的遙測資料的數量。
為什麼需要抽樣
為什麼需要採樣?
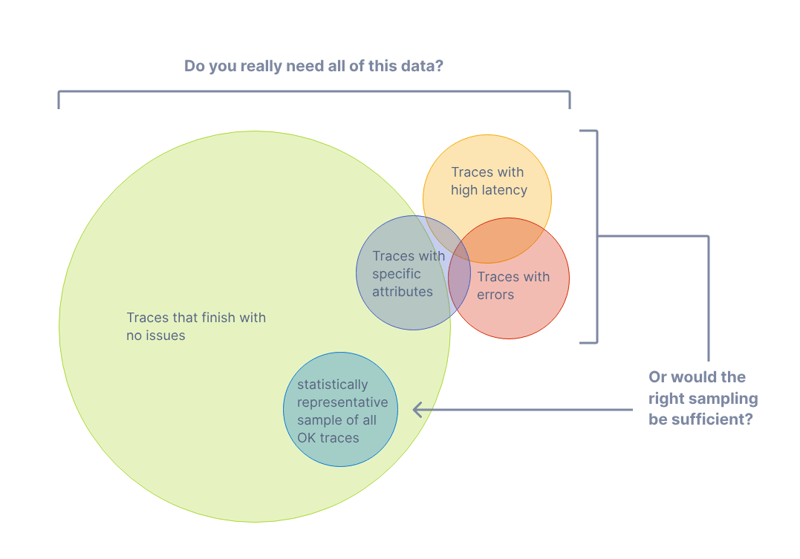
抽樣類型
採樣大致可分為頭部採樣和尾部採樣。
頭部採樣
指最開始的採樣。一個典型的例子就是機率抽樣。只留下了總痕跡的10%,其餘的都沒有追蹤。
- JavaScript
預設提供TraceIdRatioBasedSampler。
從'@opentelemetry/sdk-trace-node'導入{TraceIdRatioBasedSampler};
常量樣本百分比 = 0.1;
const sdk = 新 NodeSDK({
// 其他SDK設定參數放這裡
取樣器:新的 TraceIdRatioBasedSampler(samplePercentage);
});
import { TraceIdRatioBasedSampler } from '@opentelemetry/sdk-trace-node';
const samplePercentage = 0.1;
const sdk = new NodeSDK({
// Other SDK configuration parameters go here
sampler: new TraceIdRatioBasedSampler(samplePercentage),
});
有時重要的痕跡會被丟棄,因為他們不經詢問就丟棄了東西。
- 尾部取樣
- 從後面採樣。此時,由於可用資訊較多,您可以根據想要的邏輯進行過濾。
- 實施可能會很困難。當系統改變、條件改變時,它總是需要改變
。
很難執行,因為必須維護狀態狀態才能進行取樣。
讓我們透過實作自訂跨度處理器來實現尾部採樣
SamplingSpanProcessor 實現
建立sampling-span-processor.ts檔案
從“@opentelemetry/api”導入{Context};
進口 {
跨度處理器,
可讀跨度,
跨度,
來自“@opentelemetry/sdk-trace-node”;
/**
* 採樣跨度處理器(包括所有誤差跨度和其他跨度的比率)
*/
導出類別 SamplingSpanProcessor 實作 SpanProcessor {
構造函數(
私有_spanProcessor:SpanProcessor;
私人比:數字
){}
/**
* 強制導出所有完成的跨度
*/
ForceFlush(): Promise
import { Context } from "@opentelemetry/api";
import {
SpanProcessor,
ReadableSpan,
Span,
} from "@opentelemetry/sdk-trace-node";
/**
* Sampling span processor (including all error span and ratio of other spans)
*/
export class SamplingSpanProcessor implements SpanProcessor {
constructor(
private _spanProcessor: SpanProcessor,
private _ratio: number
) {}
/**
* Forces to export all finished spans
*/
forceFlush(): Promise {
return this._spanProcessor.forceFlush();
}
onStart(span: Span, parentContext: Context): void {
this._spanProcessor.onStart(span, parentContext);
}
shouldSample(traceId: string): boolean {
let accumulation = 0;
for (let idx = 0; idx {
return this._spanProcessor.shutdown();
}
}
導出
OtelSDK更新
更新 main.ts 中的 spanProcessors。
跨度處理器:[
新的取樣跨度處理器(
新的 BatchSpanProcessor(traceExporter);
樣本百分比
),
],
spanProcessors: [
new SamplingSpanProcessor(
new BatchSpanProcessor(traceExporter),
samplePercentage
),
],
-
 如何將來自三個MySQL表的數據組合到新表中?mysql:從三個表和列的新表創建新表 答案:為了實現這一目標,您可以利用一個3-way Join。 選擇p。 *,d.content作為年齡 來自人為p的人 加入d.person_id = p.id上的d的詳細信息 加入T.Id = d.detail_id的分類法 其中t.taxonomy ...程式設計 發佈於2025-07-09
如何將來自三個MySQL表的數據組合到新表中?mysql:從三個表和列的新表創建新表 答案:為了實現這一目標,您可以利用一個3-way Join。 選擇p。 *,d.content作為年齡 來自人為p的人 加入d.person_id = p.id上的d的詳細信息 加入T.Id = d.detail_id的分類法 其中t.taxonomy ...程式設計 發佈於2025-07-09 -
為什麼我在Silverlight Linq查詢中獲得“無法找到查詢模式的實現”錯誤?查詢模式實現缺失:解決“無法找到”錯誤在Silverlight應用程序中,嘗試使用LINQ建立LINQ連接以錯誤而實現的數據庫”,無法找到查詢模式的實現。”當省略LINQ名稱空間或查詢類型缺少IEnumerable 實現時,通常會發生此錯誤。 解決問題來驗證該類型的質量是至關重要的。在此特定實例...程式設計 發佈於2025-07-09
-
使用jQuery如何有效修改":after"偽元素的CSS屬性?在jquery中了解偽元素的限制:訪問“ selector 嘗試修改“:”選擇器的CSS屬性時,您可能會遇到困難。 This is because pseudo-elements are not part of the DOM (Document Object Model) and are th...程式設計 發佈於2025-07-09
-
在Pandas中如何將年份和季度列合併為一個週期列?pandas data frame thing commans date lay neal and pree pree'和pree pree pree”,季度 2000 q2 這個目標是通過組合“年度”和“季度”列來創建一個新列,以獲取以下結果: [python中的concate...程式設計 發佈於2025-07-09
-
C++20 Consteval函數中模板參數能否依賴於函數參數?[ consteval函數和模板參數依賴於函數參數在C 17中,模板參數不能依賴一個函數參數,因為編譯器仍然需要對非contexexpr futcoriations contim at contexpr function進行評估。 compile time。 C 20引入恆定函數,必須在編譯時進...程式設計 發佈於2025-07-09
-
Python中嵌套函數與閉包的區別是什麼嵌套函數與python 在python中的嵌套函數不被考慮閉合,因為它們不符合以下要求:不訪問局部範圍scliables to incling scliables在封裝範圍外執行範圍的局部範圍。 make_printer(msg): DEF打印機(): 打印(味精) ...程式設計 發佈於2025-07-09
-
為什麼Microsoft Visual C ++無法正確實現兩台模板的實例?The Mystery of "Broken" Two-Phase Template Instantiation in Microsoft Visual C Problem Statement:Users commonly express concerns that Micro...程式設計 發佈於2025-07-09
-
如何使用替換指令在GO MOD中解析模塊路徑差異?在使用GO MOD時,在GO MOD 中克服模塊路徑差異時,可能會遇到衝突,其中3個Party Package將另一個PAXPANCE帶有導入式套件之間的另一個軟件包,並在導入式套件之間導入另一個軟件包。如迴聲消息所證明的那樣: go.etcd.io/bbolt [&&&&&&&&&&&&&&&&...程式設計 發佈於2025-07-09
-
找到最大計數時,如何解決mySQL中的“組函數\”錯誤的“無效使用”?如何在mySQL中使用mySql 檢索最大計數,您可能會遇到一個問題,您可能會在嘗試使用以下命令:理解錯誤正確找到由名稱列分組的值的最大計數,請使用以下修改後的查詢: 計數(*)為c 來自EMP1 按名稱組 c desc訂購 限制1 查詢說明 select語句提取名稱列和每個名稱...程式設計 發佈於2025-07-09
-
人臉檢測失敗原因及解決方案:Error -215錯誤處理:解決“ error:((-215)!empty()in Function Multultiscale中的“ openCV 要解決此問題,必須確保提供給HAAR CASCADE XML文件的路徑有效。在提供的代碼片段中,級聯分類器裝有硬編碼路徑,這可能對您的系統不准確。相反,OPENCV提...程式設計 發佈於2025-07-09
-
表單刷新後如何防止重複提交?在Web開發中預防重複提交 在表格提交後刷新頁面時,遇到重複提交的問題是常見的。要解決這個問題,請考慮以下方法: 想像一下具有這樣的代碼段,看起來像這樣的代碼段:)){ //數據庫操作... 迴聲“操作完成”; 死(); } ? > ...程式設計 發佈於2025-07-09
-
Python元類工作原理及類創建與定制python中的metaclasses是什麼? Metaclasses負責在Python中創建類對象。就像類創建實例一樣,元類也創建類。他們提供了對類創建過程的控制層,允許自定義類行為和屬性。 在Python中理解類作為對象的概念,類是描述用於創建新實例或對象的藍圖的對象。這意味著類本身是使用...程式設計 發佈於2025-07-09
-
CSS可以根據任何屬性值來定位HTML元素嗎?靶向html元素,在CSS 中使用任何屬性值,在CSS中,可以基於特定屬性(如下所示)基於特定屬性的基於特定屬性的emants目標元素: 字體家庭:康斯拉斯(Consolas); } 但是,出現一個常見的問題:元素可以根據任何屬性值而定位嗎?本文探討了此主題。 的目標元素有任何任何屬性值,...程式設計 發佈於2025-07-09
-
如何使用不同數量列的聯合數據庫表?合併列數不同的表 當嘗試合併列數不同的數據庫表時,可能會遇到挑戰。一種直接的方法是在列數較少的表中,為缺失的列追加空值。 例如,考慮兩個表,表 A 和表 B,其中表 A 的列數多於表 B。為了合併這些表,同時處理表 B 中缺失的列,請按照以下步驟操作: 確定表 B 中缺失的列,並將它們添加到表的...程式設計 發佈於2025-07-09
-
C++中如何將獨占指針作為函數或構造函數參數傳遞?在構造函數和函數中將唯一的指數管理為參數 unique pointers( unique_ptr [2啟示。通過值: base(std :: simelor_ptr n) :next(std :: move(n)){} 此方法將唯一指針的所有權轉移到函數/對象。指針的內容被移至功能中,在操作...程式設計 發佈於2025-07-09















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









