
Mysql資料庫索引初學者詳解
 瀏覽:479
瀏覽:479
Core Concepts
- Primary Key Index / Secondary Index
- Clustered Index / Non-Clustered Index
- Table Lookup / Index Covering
- Index Pushdown
- Composite Index / Leftmost Prefix Matching
- Prefix Index
- Explain
1. [Index Definition]
1. Index Definition
Besides the data itself, the database system also maintains data structures that satisfy specific search algorithms. These structures reference (point to) the data in a certain way, allowing advanced search algorithms to be implemented on them. These data structures are indexes.
2. Data Structures of Indexes
- B-tree / B tree (MySQL's InnoDB engine uses B tree as the default index structure)
- HASH table
- Sorted array
3. Why Choose B Tree Over B Tree
- B-tree structure: Records are stored in the tree nodes.
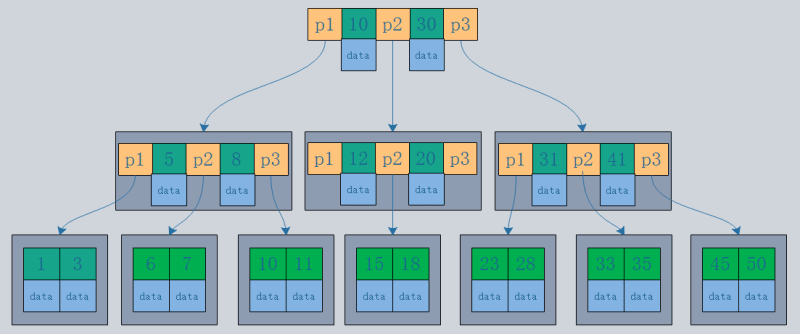
- B tree structure: Records are stored only in the leaf nodes of the tree.
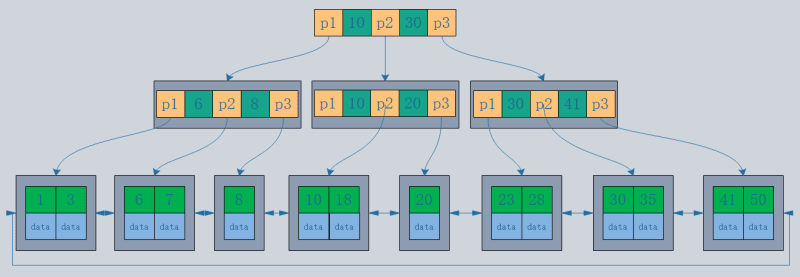
- Assuming a data size of 1KB and an index size of 16B, with the database using disk data pages, and a default disk page size of 16K, the same three I/O operations will yield:
B-tree can fetch 16*16*16=4096 records.
B tree can fetch 1000*1000*1000=1 billion records.
2. [Index Types]
1. Primary Key Index and Secondary Index
- Primary Key Index: The leaf nodes of the index are data rows.
- Secondary Index: The leaf nodes of the index are KEY fields plus primary key index. Therefore, when querying through a secondary index, it first finds the primary key value, and then InnoDB finds the corresponding data block through the primary key index.
- In InnoDB, the primary index file directly stores the data row, called clustered index, while secondary indexes point to the primary key reference.
- In MyISAM, both primary and secondary indexes point to physical rows (disk positions).
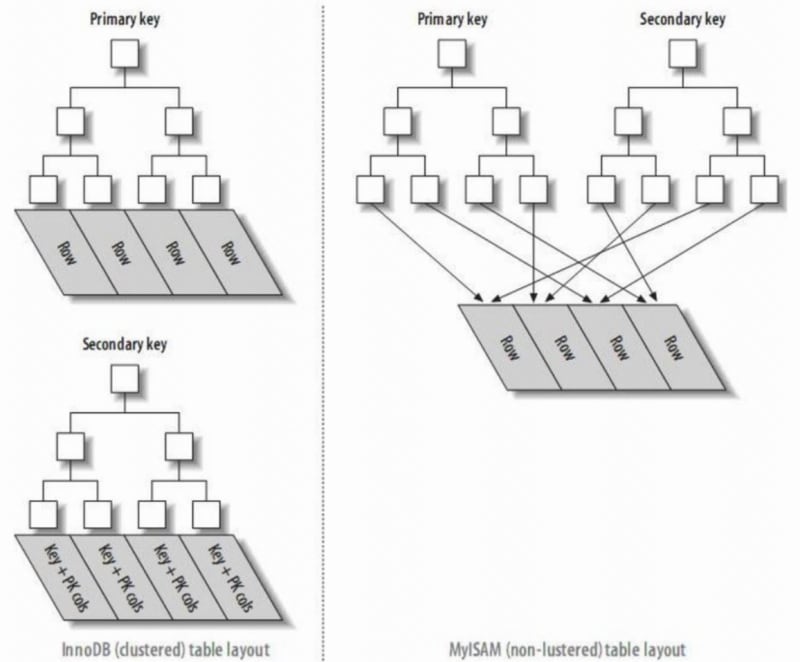
2. Clustered Index and Non-Clustered Index
- A clustered index reorganizes the actual data on the disk to be sorted by one or more specified column values. The characteristic is that the storage order of the data and the index order are consistent. Generally, the primary key will default to creating a clustered index, and a table only allows one clustered index (reason: data can only be stored in one order). As shown in the image, InnoDB's primary and secondary indexes are clustered indexes.
- Compared to the leaf nodes of a clustered index being data records, the leaf nodes of a non-clustered index are pointers to the data records. The biggest difference is that the order of data records does not match the index order.
3. Advantages and Disadvantages of Clustered Index
- Advantage: When querying entries by primary key, it does not need to perform a table lookup (data is under the primary key node).
- Disadvantage: Frequent page splits can occur with irregular data insertion.
3. [Extended Index Concepts]
1. Table Lookup
The concept of table lookup involves the difference between primary key index and non-primary key index queries.
- If the query is select * from T where ID=500, a primary key query only needs to search the ID tree.
- If the query is select * from T where k=5, a non-primary key index query needs to first search the k index tree to get the ID value of 500, then search the ID index tree again.
- The process of moving from the non-primary key index back to the primary key index is called table lookup.
Queries based on non-primary key indexes require scanning an additional index tree. Therefore, we should try to use primary key queries in applications. From the perspective of storage space, since the leaf nodes of the non-primary key index tree store primary key values, it is advisable to keep the primary key fields as short as possible. This way, the leaf nodes of the non-primary key index tree are smaller, and the non-primary key index occupies less space. Generally, it is recommended to create an auto-increment primary key to minimize the space occupied by non-primary key indexes.
2. Index Covering
- If a WHERE clause condition is a non-primary key index, the query will first locate the primary key index through the non-primary key index (the primary key is located at the leaf nodes of the non-primary key index search tree), and then locate the query content through the primary key index. In this process, moving back to the primary key index tree is called table lookup.
- However, when our query content is the primary key value, we can directly provide the query result without table lookup. In other words, the non-primary key index has already "covered" our query requirement in this query, hence it is called a covering index.
- A covering index can directly obtain query results from the auxiliary index without table lookup to the primary index, thereby reducing the number of searches (not needing to move from the auxiliary index tree to the clustered index tree) or reducing IO operations (the auxiliary index tree can load more nodes from the disk at once), thereby improving performance.
3. Composite Index
A composite index refers to indexing multiple columns of a table.
Scenario 1:
A composite index (a, b) is sorted by a, b (first sorted by a, if a is the same then sorted by b). Therefore, the following statements can directly use the composite index to get results (in fact, it uses the leftmost prefix principle):
- select … from xxx where a=xxx;
- select … from xxx where a=xxx order by b;
The following statements cannot use composite queries:
- select … from xxx where b=xxx;
Scenario 2:
For a composite index (a, b, c), the following statements can directly get results through the composite index:
- select … from xxx where a=xxx order by b;
- select … from xxx where a=xxx and b=xxx order by c;
The following statements cannot use the composite index and require a filesort operation:
- select … from xxx where a=xxx order by c;
Summary:
Using the composite index (a, b, c) as an example, creating such an index is equivalent to creating indexes a, ab, and abc. Having one index replace three indexes is certainly beneficial, as each additional index increases the overhead of write operations and disk space usage.
4. Leftmost Prefix Principle
- From the above composite index example, we can understand the leftmost prefix principle.
- Not just the full definition of the index, as long as it meets the leftmost prefix, it can be used to speed up retrieval. This leftmost prefix can be the leftmost N fields of the composite index or the leftmost M characters of the string index. Use the "leftmost prefix" principle of the index to locate records and avoid redundant index definitions.
- Therefore, based on the leftmost prefix principle, it is crucial to consider the field order within the index when defining composite indexes! The evaluation criterion is the reusability of the index. For example, when there is already an index on (a, b), there is generally no need to create a separate index on a.
5. Index Pushdown
MySQL 5.6 introduced the index pushdown optimization, which can filter out records that do not meet the conditions based on the fields included in the index during index traversal, reducing the number of table lookups.
- Create table
CREATE TABLE `test` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Auto-increment primary key', `age` int(11) NOT NULL DEFAULT '0', `name` varchar(255) CHARACTER SET utf8 NOT NULL DEFAULT '', PRIMARY KEY (`id`), KEY `idx_name_age` (`name`,`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
- SELECT * from user where name like 'Chen%' Leftmost prefix principle, hitting idx_name_age index
-
SELECT * from user where name like 'Chen%' and age=20
- Before version 5.6, it would first match 2 records based on the name index (ignoring the age=20 condition at this point), find the corresponding 2 IDs, perform table lookups, and then filter based on age=20.
- After version 5.6, index pushdown is introduced. After matching 2 records based on name, it will not ignore the age=20 condition before performing table lookups, filtering based on age before table lookup. This index pushdown can reduce the number of table lookups and improve query performance.
6. Prefix Index
When an index is a long character sequence, it can take up a lot of memory and be slow. In this case, prefix indexes can be used. Instead of indexing the entire value, we index the first few characters to save space and achieve good performance. Prefix index uses the first few letters of the index. However, to reduce the index duplication rate, we must evaluate the uniqueness of the prefix index.
- First, calculate the uniqueness ratio of the current string field: select 1.0*count(distinct name)/count(*) from test
- Then, calculate the uniqueness ratio for different prefixes:
- select 1.0*count(distinct left(name,1))/count(*) from test for the first character of the name as the prefix index
- select 1.0*count(distinct left(name,2))/count(*) from test for the first two characters of the name as the prefix index
- ...
- When left(str, n) does not significantly increase, select n as the prefix index cut-off value.
- Create the index alter table test add key(name(n));
4. [Viewing Indexes]
After adding indexes, how do we view them? Or, if statements are slow to execute, how do we troubleshoot?
Explain is commonly used to check if an index is effective.
After obtaining the slow query log, observe which statements are slow. Add explain before the statement and execute it again. Explain sets a flag on the query, causing it to return information about each step in the execution plan instead of executing the statement. It returns one or more rows of information showing each part of the execution plan and the execution order.
Important fields returned by explain:
- type: Shows the search method (full table scan or index scan)
- key: The index field used, null if not used
Explain's type field:
- ALL: Full table scan
- index: Full index scan
- range: Index range scan
- ref: Non-unique index scan
- eq_ref: Unique index scan
-
 在Python中如何創建動態變量?在Python 中,動態創建變量的功能可以是一種強大的工具,尤其是在使用複雜的數據結構或算法時,Dynamic Variable Creation的動態變量創建。 Python提供了幾種創造性的方法來實現這一目標。 利用dictionaries 一種有效的方法是利用字典。字典允許您動態創建密鑰並...程式設計 發佈於2025-07-12
在Python中如何創建動態變量?在Python 中,動態創建變量的功能可以是一種強大的工具,尤其是在使用複雜的數據結構或算法時,Dynamic Variable Creation的動態變量創建。 Python提供了幾種創造性的方法來實現這一目標。 利用dictionaries 一種有效的方法是利用字典。字典允許您動態創建密鑰並...程式設計 發佈於2025-07-12 -
表單刷新後如何防止重複提交?在Web開發中預防重複提交 在表格提交後刷新頁面時,遇到重複提交的問題是常見的。要解決這個問題,請考慮以下方法: 想像一下具有這樣的代碼段,看起來像這樣的代碼段:)){ //數據庫操作... 迴聲“操作完成”; 死(); } ? > ...程式設計 發佈於2025-07-12
-
Python中嵌套函數與閉包的區別是什麼嵌套函數與python 在python中的嵌套函數不被考慮閉合,因為它們不符合以下要求:不訪問局部範圍scliables to incling scliables在封裝範圍外執行範圍的局部範圍。 make_printer(msg): DEF打印機(): 打印(味精) ...程式設計 發佈於2025-07-12
-
Android如何向PHP服務器發送POST數據?在android apache httpclient(已棄用) httpclient httpclient = new defaulthttpclient(); httppost httppost = new httppost(“ http://www.yoursite.com/script.p...程式設計 發佈於2025-07-12
-
在細胞編輯後,如何維護自定義的JTable細胞渲染?在JTable中維護jtable單元格渲染後,在JTable中,在JTable中實現自定義單元格渲染和編輯功能可以增強用戶體驗。但是,至關重要的是要確保即使在編輯操作後也保留所需的格式。 在設置用於格式化“價格”列的“價格”列,用戶遇到的數字格式丟失的“價格”列的“價格”之後,問題在設置自定義單元...程式設計 發佈於2025-07-12
-
如何為PostgreSQL中的每個唯一標識符有效地檢索最後一行?postgresql:為每個唯一標識符提取最後一行,在Postgresql中,您可能需要遇到與在數據庫中的每個不同標識相關的信息中提取信息的情況。考慮以下數據:[ 1 2014-02-01 kjkj 在數據集中的每個唯一ID中檢索最後一行的信息,您可以在操作員上使用Postgres的有效效率: ...程式設計 發佈於2025-07-12
-
查找當前執行JavaScript的腳本元素方法如何引用當前執行腳本的腳本元素在某些方案中理解問題在某些方案中,開發人員可能需要將其他腳本動態加載其他腳本。但是,如果Head Element尚未完全渲染,則使用document.getElementsbytagname('head')[0] .appendChild(v)的常規方...程式設計 發佈於2025-07-12
-
input: Why Does "Warning: mysqli_query() expects parameter 1 to be mysqli, resource given" Error Occur and How to Fix It? output: 解決“Warning: mysqli_query() 參數應為 mysqli 而非 resource”錯誤的解析與修復方法mysqli_query()期望參數1是mysqli,resource給定的,嘗試使用mysql Query進行執行MySQLI_QUERY_QUERY formation,be be yessqli:sqli:sqli:sqli:sqli:sqli:sqli: mysqli,給定的資源“可能發...程式設計 發佈於2025-07-12
-
為什麼不使用CSS`content'屬性顯示圖像?在Firefox extemers屬性為某些圖像很大,&& && && &&華倍華倍[華氏華倍華氏度]很少見,卻是某些瀏覽屬性很少,尤其是特定於Firefox的某些瀏覽器未能在使用內容屬性引用時未能顯示圖像的情況。這可以在提供的CSS類中看到:。 googlepic { 內容:url(&...程式設計 發佈於2025-07-12
-
Java中如何使用觀察者模式實現自定義事件?在Java 中創建自定義事件的自定義事件在許多編程場景中都是無關緊要的,使組件能夠基於特定的觸發器相互通信。本文旨在解決以下內容:問題語句我們如何在Java中實現自定義事件以促進基於特定事件的對象之間的交互,定義了管理訂閱者的類界面。 以下代碼片段演示瞭如何使用觀察者模式創建自定義事件: args...程式設計 發佈於2025-07-12
-
如何在鼠標單擊時編程選擇DIV中的所有文本?在鼠標上選擇div文本單擊帶有文本內容,用戶如何使用單個鼠標單擊單擊div中的整個文本?這允許用戶輕鬆拖放所選的文本或直接複製它。 在單個鼠標上單擊的div元素中選擇文本,您可以使用以下Javascript函數: function selecttext(canduterid){ if(d...程式設計 發佈於2025-07-12
-
如何正確使用與PDO參數的查詢一樣?在pdo 中使用類似QUERIES在PDO中的Queries時,您可能會遇到類似疑問中描述的問題:此查詢也可能不會返回結果,即使$ var1和$ var2包含有效的搜索詞。錯誤在於不正確包含%符號。 通過將變量包含在$ params數組中的%符號中,您確保將%字符正確替換到查詢中。沒有此修改,PD...程式設計 發佈於2025-07-12
-
如何處理PHP文件系統功能中的UTF-8文件名?在PHP的Filesystem functions中處理UTF-8 FileNames 在使用PHP的MKDIR函數中含有UTF-8字符的文件很多flusf-8字符時,您可能會在Windows Explorer中遇到comploreer grounder grounder grounder gro...程式設計 發佈於2025-07-12
-
JavaScript計算兩個日期之間天數的方法How to Calculate the Difference Between Dates in JavascriptAs you attempt to determine the difference between two dates in Javascript, consider this s...程式設計 發佈於2025-07-12
-
Java的Map.Entry和SimpleEntry如何簡化鍵值對管理?A Comprehensive Collection for Value Pairs: Introducing Java's Map.Entry and SimpleEntryIn Java, when defining a collection where each element com...程式設計 發佈於2025-07-12















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









