
掌握影像分割:傳統技術如何在數位時代仍然大放異彩
 瀏覽:909
瀏覽:909
介绍
图像分割是计算机视觉中最基本的过程之一,它允许系统分解和分析图像内的各个区域。无论您是在处理对象识别、医学成像还是自动驾驶,分割都可以将图像分解为有意义的部分。
尽管深度学习模型在这项任务中越来越受欢迎,但数字图像处理中的传统技术仍然强大且实用。本文回顾的方法包括阈值处理、边缘检测、基于区域和通过实施公认的细胞图像分析数据集(MIVIA HEp-2 图像数据集)进行聚类。
MIVIA HEp-2 图像数据集
MIVIA HEp-2 图像数据集是一组细胞图片,用于分析 HEp-2 细胞中的抗核抗体 (ANA) 模式。它由通过荧光显微镜拍摄的二维图片组成。这使得它非常适合分割任务,最重要的是那些与医学图像分析有关的任务,其中细胞区域检测是最重要的。
现在,让我们继续讨论用于处理这些图像的分割技术,根据 F1 分数比较它们的性能。
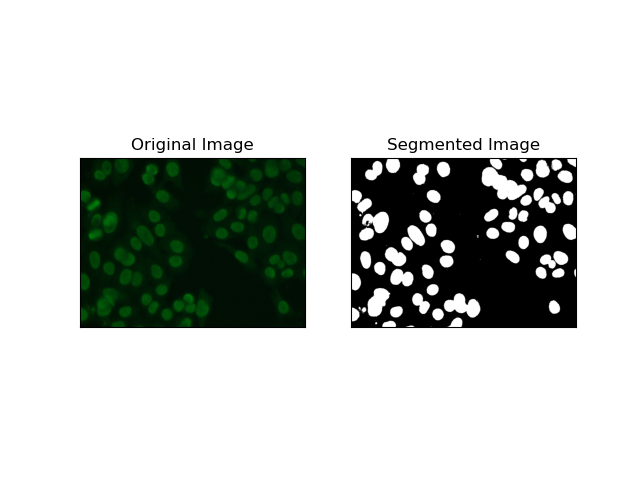
1. 阈值分割
阈值处理是根据像素强度将灰度图像转换为二值图像的过程。在 MIVIA HEp-2 数据集中,此过程对于从背景中提取细胞非常有用。它在很大程度上是简单有效的,特别是使用大津方法,因为它会自动计算最佳阈值。
Otsu 的方法 是一种自动阈值方法,它试图找到最佳阈值以产生最小的类内方差,从而分离两个类:前景(细胞)和背景。该方法检查图像直方图并计算完美阈值,其中每个类别中的像素强度方差的总和最小化。
# Thresholding Segmentation
def thresholding(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return thresh
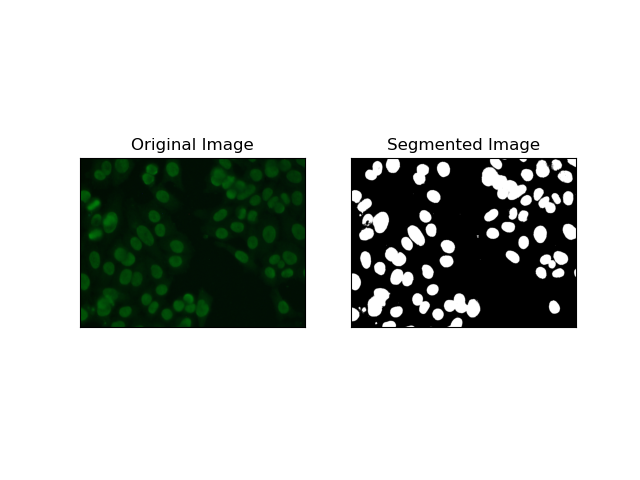
2. 边缘检测分割
边缘检测涉及识别对象或区域的边界,例如 MIVIA HEp-2 数据集中的细胞边缘。在用于检测突然强度变化的许多可用方法中,Canny 边缘检测器 是最好的,因此也是最适合用于检测细胞边界的方法。
Canny 边缘检测器 是一种多阶段算法,可以通过检测强度梯度较强的区域来检测边缘。该过程包括使用高斯滤波器进行平滑、计算强度梯度、应用非极大值抑制来消除寄生响应,以及最终的双阈值操作以仅保留显着边缘。
# Edge Detection Segmentation
def edge_detection(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Gaussian blur
gray = cv.GaussianBlur(gray, (3, 3), 0)
# Calculate lower and upper thresholds for Canny edge detection
sigma = 0.33
v = np.median(gray)
lower = int(max(0, (1.0 - sigma) * v))
upper = int(min(255, (1.0 sigma) * v))
# Apply Canny edge detection
edges = cv.Canny(gray, lower, upper)
# Dilate the edges to fill gaps
kernel = np.ones((5, 5), np.uint8)
dilated_edges = cv.dilate(edges, kernel, iterations=2)
# Clean the edges using morphological opening
cleaned_edges = cv.morphologyEx(dilated_edges, cv.MORPH_OPEN, kernel, iterations=1)
# Find connected components and filter out small components
num_labels, labels, stats, _ = cv.connectedComponentsWithStats(
cleaned_edges, connectivity=8
)
min_size = 500
filtered_mask = np.zeros_like(cleaned_edges)
for i in range(1, num_labels):
if stats[i, cv.CC_STAT_AREA] >= min_size:
filtered_mask[labels == i] = 255
# Find contours of the filtered mask
contours, _ = cv.findContours(
filtered_mask, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE
)
# Create a filled mask using the contours
filled_mask = np.zeros_like(gray)
cv.drawContours(filled_mask, contours, -1, (255), thickness=cv.FILLED)
# Perform morphological closing to fill holes
final_filled_image = cv.morphologyEx(
filled_mask, cv.MORPH_CLOSE, kernel, iterations=2
)
# Dilate the final filled image to smooth the edges
final_filled_image = cv.dilate(final_filled_image, kernel, iterations=1)
return final_filled_image
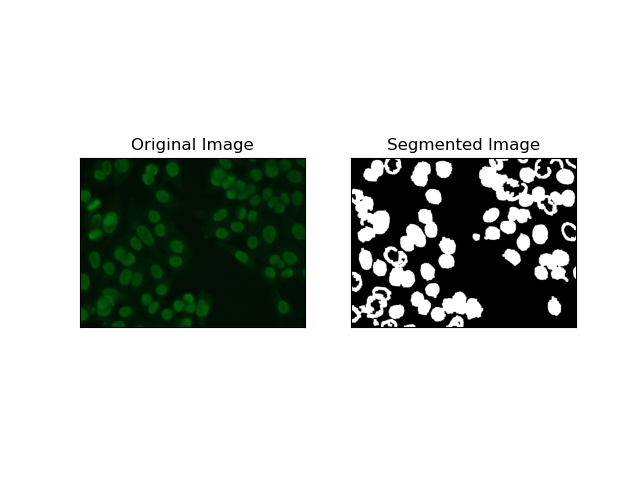
3. 基于区域的分割
基于区域的分割根据某些标准(例如强度或颜色)将相似的像素分组到区域中。 分水岭分割技术可用于帮助分割 HEp-2 细胞图像,以便能够检测代表细胞的那些区域;它将像素强度视为地形表面并勾勒出区分区域的轮廓。
分水岭分割将像素的强度视为地形表面。该算法识别“盆地”,在其中识别局部最小值,然后逐渐淹没这些盆地以扩大不同的区域。当人们想要分离触摸物体时(例如显微图像中的细胞),这种技术非常有用,但它可能对噪声敏感。该过程可以通过标记来指导,并且通常可以减少过度分割。
# Region-Based Segmentation
def region_based(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV cv.THRESH_OTSU)
# Apply morphological opening to remove noise
kernel = np.ones((3, 3), np.uint8)
opening = cv.morphologyEx(thresh, cv.MORPH_OPEN, kernel, iterations=2)
# Dilate the opening to get the background
sure_bg = cv.dilate(opening, kernel, iterations=3)
# Calculate the distance transform
dist_transform = cv.distanceTransform(opening, cv.DIST_L2, 5)
# Threshold the distance transform to get the foreground
_, sure_fg = cv.threshold(dist_transform, 0.2 * dist_transform.max(), 255, 0)
sure_fg = np.uint8(sure_fg)
# Find the unknown region
unknown = cv.subtract(sure_bg, sure_fg)
# Label the markers for watershed algorithm
_, markers = cv.connectedComponents(sure_fg)
markers = markers 1
markers[unknown == 255] = 0
# Apply watershed algorithm
markers = cv.watershed(img, markers)
# Create a mask for the segmented region
mask = np.zeros_like(gray, dtype=np.uint8)
mask[markers == 1] = 255
return mask
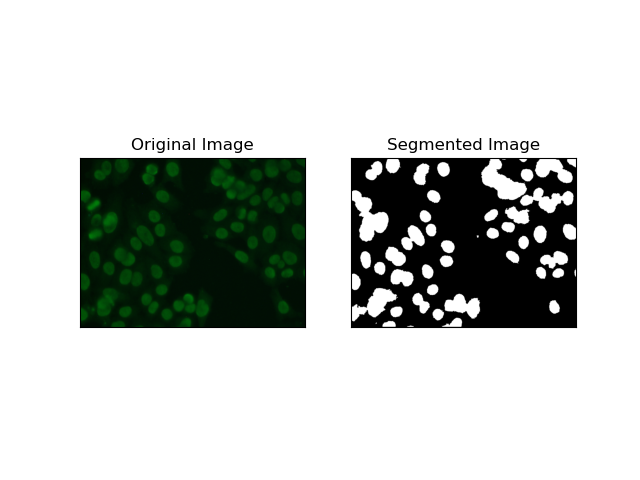
4. 基于聚类的分割
诸如K-Means之类的聚类技术倾向于将像素分组到相似的聚类中,当想要在多色或复杂环境中分割细胞时,这种方法效果很好,如 HEp-2 细胞图像中所示。从根本上讲,这可以代表不同的类别,例如细胞区域与背景。
K-means 是一种基于颜色或强度的像素相似性对图像进行聚类的无监督学习算法。该算法随机选择K个质心,将每个像素分配给最近的质心,并迭代更新质心直至收敛。它对于分割具有多个彼此非常不同的感兴趣区域的图像特别有效。
# Clustering Segmentation
def clustering(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Reshape the image
Z = gray.reshape((-1, 3))
Z = np.float32(Z)
# Define the criteria for k-means clustering
criteria = (cv.TERM_CRITERIA_EPS cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# Set the number of clusters
K = 2
# Perform k-means clustering
_, label, center = cv.kmeans(Z, K, None, criteria, 10, cv.KMEANS_RANDOM_CENTERS)
# Convert the center values to uint8
center = np.uint8(center)
# Reshape the result
res = center[label.flatten()]
res = res.reshape((gray.shape))
# Apply thresholding to the result
_, res = cv.threshold(res, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return res
使用 F1 分数评估技术
F1 分数 是一种将精度和召回率结合在一起的度量,用于将预测分割图像与地面真实图像进行比较。它是精度和召回率的调和平均值,在数据高度不平衡的情况下非常有用,例如在医学成像数据集中。
我们通过展平地面实况和分割图像并计算加权 F1 分数来计算每种分割方法的 F1 分数。
def calculate_f1_score(ground_image, segmented_image):
ground_image = ground_image.flatten()
segmented_image = segmented_image.flatten()
return f1_score(ground_image, segmented_image, average="weighted")
然后我们使用简单的条形图可视化不同方法的 F1 分数:
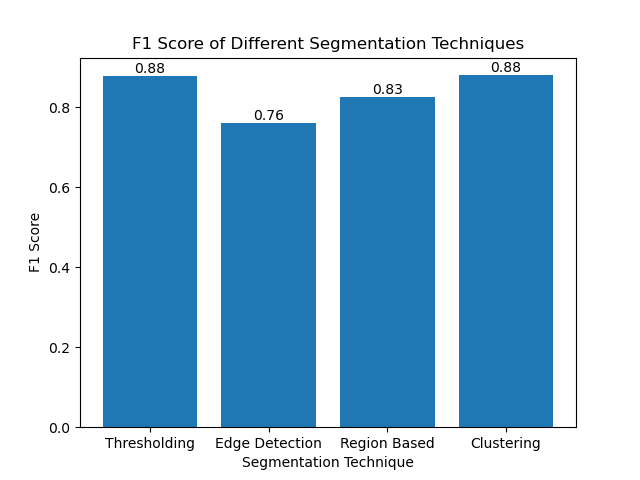
结论
尽管最近出现了许多图像分割方法,但阈值处理、边缘检测、基于区域的方法和聚类等传统分割技术在应用于 MIVIA HEp-2 图像数据集等数据集时非常有用。
每种方法都有其优点:
- 阈值适用于简单的二进制分割。
- 边缘检测是边界检测的理想技术。
- 基于区域的分割对于将连接的组件与其邻居分离非常有用。
- 聚类方法非常适合多区域分割任务。
通过使用 F1 分数评估这些方法,我们了解了每个模型的权衡。这些方法可能不像最新的深度学习模型中开发的那么复杂,但它们仍然快速、可解释且可在广泛的应用中使用。
感谢您的阅读!我希望对传统图像分割技术的探索能够启发您的下一个项目。欢迎在下面的评论中分享您的想法和经验!
-
 如何在JavaScript對像中動態設置鍵?在嘗試為JavaScript對象創建動態鍵時,如何使用此Syntax jsObj['key' i] = 'example' 1;不工作。正確的方法採用方括號: jsobj ['key''i] ='example'1; 在JavaScript中,數組是一...程式設計 發佈於2025-04-07
如何在JavaScript對像中動態設置鍵?在嘗試為JavaScript對象創建動態鍵時,如何使用此Syntax jsObj['key' i] = 'example' 1;不工作。正確的方法採用方括號: jsobj ['key''i] ='example'1; 在JavaScript中,數組是一...程式設計 發佈於2025-04-07 -
如何使用Depimal.parse()中的指數表示法中的數字?在嘗試使用Decimal.parse(“ 1.2345e-02”中的指數符號表示法表示的字符串時,您可能會遇到錯誤。這是因為默認解析方法無法識別指數符號。 成功解析這樣的字符串,您需要明確指定它代表浮點數。您可以使用numbersTyles.Float樣式進行此操作,如下所示:[&& && && ...程式設計 發佈於2025-04-07
-
為什麼我會收到MySQL錯誤#1089:錯誤的前綴密鑰?mySQL錯誤#1089:錯誤的前綴鍵錯誤descript [#1089-不正確的前綴鍵在嘗試在表中創建一個prefix鍵時會出現。前綴鍵旨在索引字符串列的特定前綴長度長度,以便更快地搜索這些前綴。 理解prefix keys `這將在整個Movie_ID列上創建標準主鍵。主密鑰對於唯一識...程式設計 發佈於2025-04-07
-
為什麼使用Firefox後退按鈕時JavaScript執行停止?導航歷史記錄問題:JavaScript使用Firefox Back Back 此行為是由瀏覽器緩存JavaScript資源引起的。要解決此問題並確保在後續頁面訪問中執行腳本,Firefox用戶應設置一個空功能。 警報'); }; alert('inline Alert')...程式設計 發佈於2025-04-07
-
eval()vs. ast.literal_eval():對於用戶輸入,哪個Python函數更安全?稱量()和ast.literal_eval()中的Python Security 在使用用戶輸入時,必須優先確保安全性。強大的python功能eval()通常是作為潛在解決方案而出現的,但擔心其潛在風險。 This article delves into the differences betwee...程式設計 發佈於2025-04-07
-
如何使用不同數量列的聯合數據庫表?合併列數不同的表 當嘗試合併列數不同的數據庫表時,可能會遇到挑戰。一種直接的方法是在列數較少的表中,為缺失的列追加空值。 例如,考慮兩個表,表 A 和表 B,其中表 A 的列數多於表 B。為了合併這些表,同時處理表 B 中缺失的列,請按照以下步驟操作: 確定表 B 中缺失的列,並將它們添加到表的...程式設計 發佈於2025-04-07
-
如何克服PHP的功能重新定義限制?克服PHP的函數重新定義限制在PHP中,多次定義一個相同名稱的函數是一個no-no。嘗試這樣做,如提供的代碼段所示,將導致可怕的“不能重新列出”錯誤。 但是,PHP工具腰帶中有一個隱藏的寶石:runkit擴展。它使您能夠靈活地重新定義函數。 runkit_function_renction_...程式設計 發佈於2025-04-07
-
為什麼不````''{margin:0; }`始終刪除CSS中的最高邊距?在CSS 問題:不正確的代碼: 全球範圍將所有餘量重置為零,如提供的代碼所建議的,可能會導致意外的副作用。解決特定的保證金問題是更建議的。 例如,在提供的示例中,將以下代碼添加到CSS中,將解決餘量問題: body H1 { 保證金頂:-40px; } 此方法更精確,避免了由全局保證金重置...程式設計 發佈於2025-04-07
-
如何在其容器中為DIV創建平滑的左右CSS動畫?通用CSS動畫,用於左右運動 ,我們將探索創建一個通用的CSS動畫,以向左和右移動DIV,從而到達其容器的邊緣。該動畫可以應用於具有絕對定位的任何div,無論其未知長度如何。 問題:使用左直接導致瞬時消失 更加流暢的解決方案:混合轉換和左 [並實現平穩的,線性的運動,我們介紹了線性的轉換。...程式設計 發佈於2025-04-07
-
如何解決由於Android的內容安全策略而拒絕加載腳本... \”錯誤?Unveiling the Mystery: Content Security Policy Directive ErrorsEncountering the enigmatic error "Refused to load the script..." when deployi...程式設計 發佈於2025-04-07
-
版本5.6.5之前,使用current_timestamp與時間戳列的current_timestamp與時間戳列有什麼限制?在時間戳列上使用current_timestamp或MySQL版本中的current_timestamp或在5.6.5 此限制源於遺留實現的關注,這些限制需要對當前的_timestamp功能進行特定的實現。 創建表`foo`( `Productid` int(10)unsigned not ...程式設計 發佈於2025-04-07
-
如何使用Java.net.urlConnection和Multipart/form-data編碼使用其他參數上傳文件?使用http request 上傳文件上傳到http server,同時也提交其他參數,java.net.net.urlconnection and Multipart/form-data Encoding是普遍的。 Here's a breakdown of the process:Mu...程式設計 發佈於2025-04-07
-
如何在Java中執行命令提示命令,包括目錄更改,包括目錄更改?在java 通過Java通過Java運行命令命令可能很具有挑戰性。儘管您可能會找到打開命令提示符的代碼段,但他們通常缺乏更改目錄並執行其他命令的能力。 solution:使用Java使用Java,使用processBuilder。這種方法允許您:啟動一個過程,然後將其標準錯誤重定向到其標準輸出...程式設計 發佈於2025-04-07
-
如何檢查對像是否具有Python中的特定屬性?方法來確定對象屬性存在尋求一種方法來驗證對像中特定屬性的存在。考慮以下示例,其中嘗試訪問不確定屬性會引起錯誤: >>> a = someClass() >>> A.property Trackback(最近的最新電話): 文件“ ”,第1行, attributeError:SomeClass實...程式設計 發佈於2025-04-07















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









