
MySQL建表必須了解的重點
 瀏覽:668
瀏覽:668

For backend developers, accessing a database is crucial.
Core user data is usually stored securely in databases like MySQL or Oracle.
Daily tasks often involve creating databases and tables to meet business needs, but tables are created much more frequently.
This article will focus on table creation since ignoring key details can lead to costly issues in maintenance after deployment.
By the way, Poor database design practices can also cause your API to respond slowly during high concurrency.The following image shows the performance test results of an API using the EchoAPI tool.
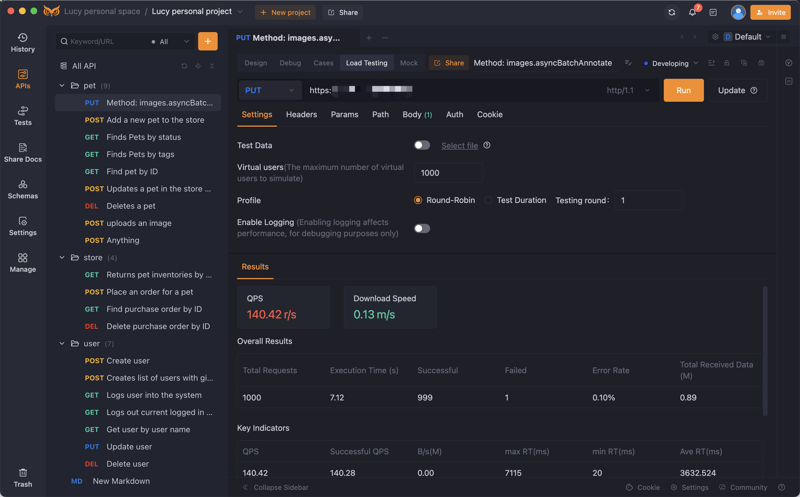
Today, let’s discuss 18 tips for creating tables in a database.
Many of the details mentioned in this article stem from my own experiences and challenges faced during work, and I hope they will be helpful to you.
1. Naming
When creating tables, fields, and indexes, giving them good names is incredibly important.
1.1 Meaningful Names
Names serve as the face of tables, fields, and indexes, leaving a first impression.
Good names are concise and self-descriptive, making communication and maintenance easier.
Poor names are ambiguous and confusing, leading to chaos and frustration.
Bad Examples:
Field names like abc, abc_name, name, user_name_123456789 will leave you baffled.
Good Example:
Field name as user_name.
A gentle reminder: names should also not be too long, ideally kept within 30 characters.
1.2 Case Sensitivity
It’s best to use lowercase letters for names, as they are easier to read visually.
Bad Examples:
Field names like PRODUCT_NAME, PRODUCT_name are not intuitive. A mix of upper and lower case is less pleasant to read.
Good Example:
Field name as product_name looks more comfortable.
1.3 Separators
Often, names may contain multiple words for better understanding.
What separator should be used between multiple words?
Bad Examples:
Field names like productname, productName, product name, or product@name are not recommended.
Good Example:
Field name as product_name.
Using an underscore _ between words is strongly advised.
1.4 Table Names
For table names, it’s recommended to use meaningful, concise names along with a business prefix.
For order-related tables, prepend the table name with order_, such as order_pay, order_pay_detail.
For product-related tables, prepend with product_, like product_spu, product_sku.
This practice helps in categorizing tables related to the same business together quickly.
Additionally, if a non-order business might need to create a table named pay, it can be easily distinguished as finance_pay, preventing name conflicts.
1.5 Field Names
Field names allow for maximum flexibility but can easily lead to confusion.
For example, using flag to denote status in one table while using status in another can create inconsistencies.
Standardizing to status for representing state is advisable.
When a table uses another table's primary key, append _id or _sys_no to the end of the field name, for example, product_spu_id or product_spu_sys_no.
Additionally, standardize creation time as create_time and modification time as update_time, with deletion status fixed as delete_status.
Other common fields should also maintain a uniform naming convention across different tables for better clarity.
1.6 Index Names
In a database, there are various types of indexes, including primary keys, regular indexes, unique indexes, and composite indexes.
A table generally has a single primary key, usually named id or sys_no.
Regular and composite indexes can use the ix_ prefix, for example, ix_product_status.
Unique indexes can use the ux_ prefix, such as ux_product_code.
2. Field Types
When designing tables, ample freedom exists in choosing field types.
Time-formatted fields can be date, datetime, or timestamp, etc.
Character data types include varchar, char, text, etc.
Numeric types comprise int, bigint, smallint, and tinyint.
Selecting an appropriate field type is crucial.
Overestimating types (e.g., using bigint for a field that will only store values between 1 and 10) wastes space; tinyint would suffice.
Conversely, underestimating (e.g., using int for an 18-digit ID) will lead to data storage failures.
Here are some principles for choosing field types:
- Prefer small storage size while meeting normal business needs, selecting from small to large.
- Use char for fixed or similar string lengths, and varchar for varied lengths.
- Use bit for boolean fields.
- Use tinyint for enumeration fields.
- Choose bigint for primary key fields.
- Use decimal for monetary fields.
- Use timestamp or datetime for time fields.
3. Field Length
After defining field names and selecting appropriate field types, the focus should shift to field lengths, like varchar(20) or bigint(20).
What does varchar indicate in terms of length—bytes or characters?
The answer: In MySQL, varchar and char represent character length, while most other types represent byte length.
For example, bigint(4) specifies the display length, not the storage length, which remains 8 bytes.
If the zerofill property is set, numbers less than 4 bytes will be padded, but even if filled, the underlying data storage remains at 8 bytes.
4. Number of Fields
When designing a table, it’s crucial to limit the number of fields.
I’ve seen tables with dozens or even hundreds of fields, leading to large data volumes and low query efficiency.
If this situation arises, consider splitting large tables into smaller ones while retaining common primary keys.
As a rule of thumb, keep the number of fields per table below 20.
5. Primary Keys
Create a primary key when setting up a table.
Primary keys inherently come with primary key indexes, making queries more efficient, as they don’t require additional lookups.
In a single database, primary keys can use AUTO_INCREMENT for automatic growth.
For distributed databases, particularly in sharded architectures, it’s best to use external algorithms (like Snowflake) to ensure globally unique IDs.
Moreover, keep primary keys independent of business values to reduce coupling and facilitate future expansions.
However, for one-to-one relationships, such as user tables and user extension tables, it’s acceptable to directly use the primary key from the user table.
6. Storage Engine
Before MySQL 8, the default storage engine was MyISAM; from MySQL 8 onward, it’s now InnoDB.
Historically, there was much debate about which storage engine to choose.
MyISAM separates index and data storage, enhancing query performance but lacks support for transactions and foreign keys.
InnoDB, while slightly slower in queries, supports transactions and foreign keys, making it more robust.
It was previously advised to use MyISAM for read-heavy and InnoDB for write-heavy scenarios.
However, optimizations in MySQL have reduced performance differences, so using the default InnoDB storage engine in MySQL 8 and later is recommended without any additional modifications.
7. NOT NULL
When creating fields, decide whether they can be NULL.
Defining fields as NOT NULL whenever possible is advisable.
Why?
In InnoDB, storing NULL values requires extra space, and they can also lead to index failures.
NULL values can only be queried using IS NULL or IS NOT NULL, as using = always returns false.
Thus, define fields as NOT NULL wherever feasible.
However, when a field is directly defined as NOT NULL, and a value is forgotten during input, it will prevent data insertion.
This can be an acceptable situation when new fields are added and scripts run before deploying new code, leading to errors without default values.
For newly added NOT NULL fields, setting a default value is crucial:
ALTER TABLE product_sku ADD COLUMN brand_id INT(10) NOT NULL DEFAULT 0;
8. Foreign Keys
Foreign keys in MySQL serve to ensure data consistency and integrity.
For instance:
CREATE TABLE class ( id INT(10) PRIMARY KEY AUTO_INCREMENT, cname VARCHAR(15) );
This creates a class table.
Then, a student table can be constructed that references it:
CREATE TABLE student( id INT(10) PRIMARY KEY AUTO_INCREMENT, name VARCHAR(15) NOT NULL, gender VARCHAR(10) NOT NULL, cid INT, FOREIGN KEY (cid) REFERENCES class(id) );
Here, cid in the student table references id in the class table.
Attempting to delete a record in student without removing the corresponding cid record in class will raise a foreign key constraint error:
a foreign key constraint fails.
Thus, consistency and integrity are preserved.
Note that foreign keys are only usable with the InnoDB storage engine.
If only two tables are linked, it might be manageable, but with several tables, deleting a parent record requires synchronously deleting many child records, which can impact performance.
Thus, for internet systems, it is generally advised to avoid using foreign keys to prioritize performance over absolute data consistency.
In addition to foreign keys, stored procedures and triggers are also discouraged due to their performance impact.
9. Indexes
When creating tables, beyond specifying primary keys, it’s essential to create additional indexes.
For example:
CREATE TABLE product_sku( id INT(10) PRIMARY KEY AUTO_INCREMENT, spu_id INT(10) NOT NULL, brand_id INT(10) NOT NULL, name VARCHAR(15) NOT NULL );
This table includes spu_id (from the product group) and brand_id (from the brand table).
In situations that save IDs from other tables, a regular index can be added:
CREATE TABLE product_sku ( id INT(10) PRIMARY KEY AUTO_INCREMENT, spu_id INT(10) NOT NULL, brand_id INT(10) NOT NULL, name VARCHAR(15) NOT NULL, KEY `ix_spu_id` (`spu_id`) USING BTREE, KEY `ix_brand_id` (`brand_id`) USING BTREE );
Such indexes significantly enhance query efficiency.
However, do not create too many indexes as they can hinder data insertion efficiency due to additional storage requirements.
A single table should ideally have no more than five indexes.
If the number of indexes exceeds five during table creation, consider dropping some regular indexes in favor of composite indexes.
Also, when creating composite indexes, always apply the leftmost matching rule to ensure the indexes are effective.
For fields with high duplication rates (like status), avoid creating separate regular indexes. MySQL may skip the index and choose a full table scan instead if it’s more efficient.
I’ll address index inefficiency issues in a separate article later, so let’s hold off on that for now.
10. Time Fields
The range of types available for time fields in MySQL is fairly extensive: date, datetime, timestamp, and varchar.
Using varchar might be for API consistency where time data is represented as a string.
However, querying data by time ranges can be inefficient with varchar since it cannot utilize indexes.
Date is intended only for dates (e.g., 2020-08-20), while datetime and timestamp are suited for complete date and time.
There are subtle differences between them.
Timestamp: uses 4 bytes and spans from 1970-01-01 00:00:01 UTC to 2038-01-19 03:14:07. It’s also timezone-sensitive.
Datetime: occupies 8 bytes with a range from 1000-01-01 00:00:00 to 9999-12-31 23:59:59, independent of time zones.
Using datetime to save date and time is preferable for its wider range.
As a reminder, when setting default values for time fields, avoid using 0000-00-00 00:00:00, which can cause errors during queries.
11. Monetary Fields
MySQL provides several types for floating-point numbers: float, double, decimal, etc.
Given that float and double may lose precision, it’s recommended to use decimal for monetary values.
Typically, floating numbers are defined as decimal(m,n), where n represents the number of decimal places, and m is the total length of both integer and decimal portions.
For example, decimal(10,2) allows for 8 digits before the decimal point and 2 digits after it.
12. JSON Fields
During table structure design, you may encounter fields needing to store variable data values.
For example, in an asynchronous Excel export feature, a field in the async task table may need to save user-selected query conditions, which can vary per user.
Traditional database fields don’t handle this well.
Using MySQL’s json type enables structured data storage in JSON format for easy saving and querying.
MySQL also supports querying JSON data by field names or values.
13. Unique Indexes
Unique indexes are frequently used in practice.
You can apply unique indexes to individual fields, like an organization’s code, or create composite unique indexes for multiple fields, like category numbers, units, specifications, etc.
Unique indexes on individual fields are straightforward, but for composite unique indexes, if any field is NULL, the uniqueness constraint may fail.
Another common issue is having unique indexes while still producing duplicate data.
Due to its complexity, I’ll elaborate on unique index issues in a later article.
When creating unique indexes, ensure that none of the involved fields contain NULL values to maintain their uniqueness.
14. Character Set
MySQL supports various character sets, including latin1, utf-8, utf8mb4, etc.
Here’s a table summarizing MySQL character sets:
| Character Set | Description | Encoding Size | Notes |
|---|---|---|---|
| latin1 | Encounters encoding issues; rarely used in real projects | 1 byte | Limited support for international characters |
| utf-8 | Efficient in storage but cannot store emoji | 3 bytes | Suitable for most text but lacks emoji support |
| utf8mb4 | Supports all Unicode characters, including emoji | 4 bytes | Recommended for modern applications |
It’s advisable to set the character set to utf8mb4 during table creation to avoid potential issues.
15. Collation
When creating tables in MySQL, the COLLATE parameter can be configured.
For example:
CREATE TABLE `order` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `code` VARCHAR(20) COLLATE utf8mb4_bin NOT NULL, `name` VARCHAR(30) COLLATE utf8mb4_bin NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `un_code` (`code`), KEY `un_code_name` (`code`,`name`) USING BTREE, KEY `idx_name` (`name`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
The collation determines how character sorting and comparison are conducted.
Character collation depends on the character set, which for utf8mb4 would also start with utf8mb4_. Common types include utf8mb4_general_ci and utf8mb4_bin.
The utf8mb4_general_ci collation is case-insensitive for alphabetical characters, while utf8mb4_bin is case-sensitive.
This distinction is important. For example, if the order table contains a record with the name YOYO and you query it using lowercase yoyo under utf8mb4_general_ci, it retrieves the record. Under utf8mb4_bin, it will not.
Choose collation based on the actual business needs to avoid confusion.
16. Large Fields
Special attention is warranted for fields that consume substantial storage space, such as comments.
A user comment field might require limits, like a maximum of 500 characters.
Defining large fields as text can waste storage, thus it’s often better to use varchar for better efficiency.
For much larger data types, like contracts that can take up several MB, it may be unreasonable to store directly in MySQL.
Instead, such data could be stored in MongoDB, with the MySQL business table retaining the MongoDB ID.
17. Redundant Fields
To enhance performance and query speed, some fields can be redundantly stored.
For example, an order table typically contains a userId to identify users.
However, many order query pages also need to display the user ID along with the user’s name.
If both tables are small, a join is feasible, but for large datasets, it can degrade performance.
In that case, creating a redundant userName field in the order table can resolve performance issues.
While this adjustment allows direct querying from the order table without joins, it requires additional storage and may lead to inconsistency if user names change.
Therefore, carefully evaluate if the redundant fields strategy fits your particular business scenario.
18. Comments
When designing tables, ensure to add clear comments for tables and associated fields.
For example:
CREATE TABLE `sys_dept` ( `id` BIGINT NOT NULL AUTO_INCREMENT COMMENT 'ID', `name` VARCHAR(30) NOT NULL COMMENT 'Name', `pid` BIGINT NOT NULL COMMENT 'Parent Department', `valid_status` TINYINT(1) NOT NULL DEFAULT 1 COMMENT 'Valid Status: 1=Valid, 0=Invalid', `create_user_id` BIGINT NOT NULL COMMENT 'Creator ID', `create_user_name` VARCHAR(30) NOT NULL COMMENT 'Creator Name', `create_time` DATETIME(3) DEFAULT NULL COMMENT 'Creation Date', `update_user_id` BIGINT DEFAULT NULL COMMENT 'Updater ID', `update_user_name` VARCHAR(30) DEFAULT NULL COMMENT 'Updater Name', `update_time` DATETIME(3) DEFAULT NULL COMMENT 'Update Time', `is_del` TINYINT(1) DEFAULT '0' COMMENT 'Is Deleted: 1=Deleted, 0=Not Deleted', PRIMARY KEY (`id`) USING BTREE, KEY `index_pid` (`pid`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='Department';
Detailed comments clarify the purpose of tables and fields.
Particularly for fields representing statuses (like valid_status), it immediately conveys the intent behind the data, such as indicating valid versus invalid.
Avoid situations where numerous status fields exist without comments, leading to confusion about what values like 1, 2, or 3 signify.
Initially, one might remember, but after a year of operation, it’s easy to forget, potentially leading to significant pitfalls.
Thus, when designing tables, meticulous commenting and regular updates of these comments are essential.
That wraps up the technical section of this article,If you have a different opinion, let me know?.
-
 將圖片浮動到底部右側並環繞文字的技巧在Web設計中圍繞在Web設計中,有時可以將圖像浮動到頁面右下角,從而使文本圍繞它纏繞。這可以在有效地展示圖像的同時創建一個吸引人的視覺效果。 css位置在右下角,使用css float and clear properties: img { 浮點:對; ...程式設計 發佈於2025-07-07
將圖片浮動到底部右側並環繞文字的技巧在Web設計中圍繞在Web設計中,有時可以將圖像浮動到頁面右下角,從而使文本圍繞它纏繞。這可以在有效地展示圖像的同時創建一個吸引人的視覺效果。 css位置在右下角,使用css float and clear properties: img { 浮點:對; ...程式設計 發佈於2025-07-07 -
如何使用組在MySQL中旋轉數據?在關係數據庫中使用mySQL組使用mySQL組進行查詢結果,在關係數據庫中使用MySQL組,轉移數據的數據是指重新排列的行和列的重排以增強數據可視化。在這裡,我們面對一個共同的挑戰:使用組的組將數據從基於行的基於列的轉換為基於列。 Let's consider the following ...程式設計 發佈於2025-07-07
-
在JavaScript中如何並發運行異步操作並正確處理錯誤?同意操作execution 在執行asynchronous操作時,相關的代碼段落會遇到一個問題,當執行asynchronous操作:此實現在啟動下一個操作之前依次等待每個操作的完成。要啟用並發執行,需要進行修改的方法。 第一個解決方案試圖通過獲得每個操作的承諾來解決此問題,然後單獨等待它們: c...程式設計 發佈於2025-07-07
-
如何使用Depimal.parse()中的指數表示法中的數字?在嘗試使用Decimal.parse(“ 1.2345e-02”中的指數符號表示法表示的字符串時,您可能會遇到錯誤。這是因為默認解析方法無法識別指數符號。 成功解析這樣的字符串,您需要明確指定它代表浮點數。您可以使用numbersTyles.Float樣式進行此操作,如下所示:[&& && && ...程式設計 發佈於2025-07-07
-
如何檢查對像是否具有Python中的特定屬性?方法來確定對象屬性存在尋求一種方法來驗證對像中特定屬性的存在。考慮以下示例,其中嘗試訪問不確定屬性會引起錯誤: >>> a = someClass() >>> A.property Trackback(最近的最新電話): 文件“ ”,第1行, attributeError:SomeClass實...程式設計 發佈於2025-07-07
-
如何使用“ JSON”軟件包解析JSON陣列?parsing JSON與JSON軟件包 QUALDALS:考慮以下go代碼:字符串 } func main(){ datajson:=`[“ 1”,“ 2”,“ 3”]`` arr:= jsontype {} 摘要:= = json.unmarshal([] byte(...程式設計 發佈於2025-07-07
-
如何正確使用與PDO參數的查詢一樣?在pdo 中使用類似QUERIES在PDO中的Queries時,您可能會遇到類似疑問中描述的問題:此查詢也可能不會返回結果,即使$ var1和$ var2包含有效的搜索詞。錯誤在於不正確包含%符號。 通過將變量包含在$ params數組中的%符號中,您確保將%字符正確替換到查詢中。沒有此修改,PD...程式設計 發佈於2025-07-07
-
如何將MySQL數據庫添加到Visual Studio 2012中的數據源對話框中?在Visual Studio 2012 儘管已安裝了MySQL Connector v.6.5.4,但無法將MySQL數據庫添加到實體框架的“ DataSource對話框”中。為了解決這一問題,至關重要的是要了解MySQL連接器v.6.5.5及以後的6.6.x版本將提供MySQL的官方Visual...程式設計 發佈於2025-07-07
-
版本5.6.5之前,使用current_timestamp與時間戳列的current_timestamp與時間戳列有什麼限制?在時間戳列上使用current_timestamp或MySQL版本中的current_timestamp或在5.6.5 此限制源於遺留實現的關注,這些限制需要對當前的_timestamp功能進行特定的實現。 創建表`foo`( `Productid` int(10)unsigned not ...程式設計 發佈於2025-07-07
-
FastAPI自定義404頁面創建指南response = await call_next(request) if response.status_code == 404: return RedirectResponse("https://fastapi.tiangolo.com") else: ...程式設計 發佈於2025-07-07
-
如何避免Go語言切片時的內存洩漏?,a [j:] ...雖然通常有效,但如果使用指針,可能會導致內存洩漏。這是因為原始的備份陣列保持完整,這意味著新切片外部指針引用的任何對象仍然可能佔據內存。 copy(a [i:] 對於k,n:= len(a)-j i,len(a); k程式設計 發佈於2025-07-07
-
如何使用不同數量列的聯合數據庫表?合併列數不同的表 當嘗試合併列數不同的數據庫表時,可能會遇到挑戰。一種直接的方法是在列數較少的表中,為缺失的列追加空值。 例如,考慮兩個表,表 A 和表 B,其中表 A 的列數多於表 B。為了合併這些表,同時處理表 B 中缺失的列,請按照以下步驟操作: 確定表 B 中缺失的列,並將它們添加到表的...程式設計 發佈於2025-07-07
-
PHP SimpleXML解析帶命名空間冒號的XML方法在php 很少,請使用該限制很大,很少有很高。例如:這種技術可確保可以通過遍歷XML樹和使用兒童()方法()方法的XML樹和切換名稱空間來訪問名稱空間內的元素。程式設計 發佈於2025-07-07
-
C++中如何將獨占指針作為函數或構造函數參數傳遞?在構造函數和函數中將唯一的指數管理為參數 unique pointers( unique_ptr [2啟示。通過值: base(std :: simelor_ptr n) :next(std :: move(n)){} 此方法將唯一指針的所有權轉移到函數/對象。指針的內容被移至功能中,在操作...程式設計 發佈於2025-07-07
-
為什麼HTML無法打印頁碼及解決方案無法在html頁面上打印頁碼? @page規則在@Media內部和外部都無濟於事。 HTML:Customization:@page { margin: 10%; @top-center { font-family: sans-serif; font-weight: ...程式設計 發佈於2025-07-07















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









