
FireDucks:以零學習成本獲得超越 pandas 的效能!
 瀏覽:480
瀏覽:480
Pandas 是最受歡迎的庫之一,當我在尋找一種更簡單的方法來加速其性能時,我發現了 FireDucks 並對它產生了興趣!
與 pandas 的比較:為什麼選擇 FireDucks?
Pandas 程式可能會遇到嚴重的效能問題,這取決於其編寫方式。然而,作為一名數據科學家,我想花越來越多的時間分析數據,而不是提高程式碼效能。因此,如果它能夠執行諸如交換進程順序並自動加速程式效能之類的事情,那就太好了。例如,Process A =>Process B 會比較慢,所以我們將其替換為 Process B =>Process A。 (當然,結果保證是一樣的。)據說資料科學家花費了大約 45%他們準備資料的時間,當我考慮做一些事情來加速這個過程時,我遇到了一個名為 FireDucks 的模組。
從 FireDucks 文件來看,它似乎只支援 Linux 平台。由於我在我的主機上使用 Windows,因此我想從 WSL2(Windows Subsystem for Linux)嘗試一下,這是一個可以在 Windows 上運行 Linux 的環境。
我嘗試的環境如下
- 作業系統 Microsoft Windows 11 Pro
- 版本 10.0.22631 內部版本 22631
- 系統型號 Z690 Pro RS
- 系統類型基於 x64
- PC 處理器第 12 代 Intel(R) Core(TM) i3–12100、3300 Mhz、4 核心、8 個邏輯處理器
- 底板產品 Z690 Pro RS
- 平台角色桌面
- 安裝的實體記憶體 (RAM)64.0 GB
安裝與設定 FireDuck
安裝 WSL
WSL 是在以下 Microsoft 文件的幫助下安裝的; Linux 發行版是 Ubuntu 22.04.1 LTS。
安裝 FireDucks
然後實際安裝FireDucks。不過安裝起來非常容易。
pip install fireducks
安裝 FireDucks(以及 pyarrow、pandas 和其他庫)需要幾分鐘時間。
我嘗試執行下面的程式碼,載入速度非常快,pandas 花了 4 秒,fireDucks 只花了 74.5 ns。
# 1. analysis based on time period and creative duration # convert timestamp to date/time object df['timestamp_converted'] = pd.to_datetime(df['timestamp'], unit='s ') # define time period def get_part_of_day(hour): if 5所有這些數據預處理和分析在 pandas 中大約需要 8 秒,而使用 FireDucks 時可以在 4 秒內完成。幾乎可以實現2倍的加速。
提高性能
使用pandas最有壓力的事情之一是載入大數據集時的等待,然後我必須等待像groupby這樣的複雜操作。另一方面,由於FireDucks進行惰性評估,加載本身根本不需要時間,因此在需要的地方進行處理,我覺得這非常重要,大大減少了總等待時間。
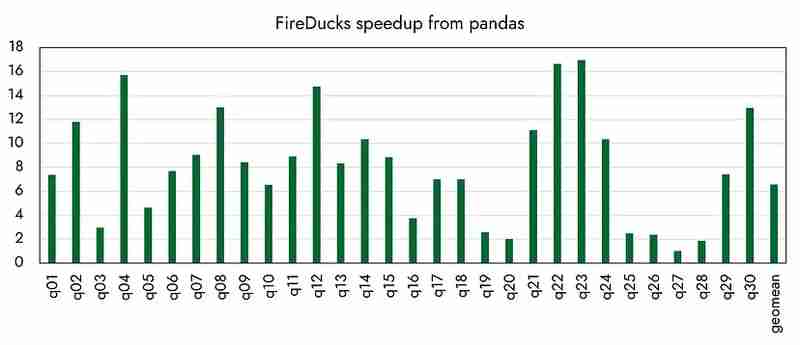
至於其他性能,據該組織官方宣布,與 pandas 相比,似乎已經實現了高達 16 倍的速度提升。 (下次我將與各種競爭庫進行效能比較。)
零學習成本
無需考慮任何事情就能遵循精確的 pandas 符號的能力是一個巨大的優勢。除了FireDucks之外,還有其他資料幀加速庫,但它們學習成本太高且太容易被遺忘。
例如,如果你想添加帶有極坐標的列,你必須這樣寫。
# pandas df["new_col"] = df["A"] 1 # polars df = df.with_columns((pl.col("A") 1).alias("new_col"))幾乎不需要更改現有程式碼
我有幾個 ETL 和其他使用 pandas 的項目,如果僅通過安裝 FireDucks 並替換 import 語句就能看到性能改進,那就太好了。
如果您想進一步添加,請隨時在下面評論。
-
 將圖片浮動到底部右側並環繞文字的技巧在Web設計中圍繞在Web設計中,有時可以將圖像浮動到頁面右下角,從而使文本圍繞它纏繞。這可以在有效地展示圖像的同時創建一個吸引人的視覺效果。 css位置在右下角,使用css float and clear properties: img { 浮點:對; ...程式設計 發佈於2025-04-30
將圖片浮動到底部右側並環繞文字的技巧在Web設計中圍繞在Web設計中,有時可以將圖像浮動到頁面右下角,從而使文本圍繞它纏繞。這可以在有效地展示圖像的同時創建一個吸引人的視覺效果。 css位置在右下角,使用css float and clear properties: img { 浮點:對; ...程式設計 發佈於2025-04-30 -
如何在無序集合中為元組實現通用哈希功能?在未訂購的集合中的元素要糾正此問題,一種方法是手動為特定元組類型定義哈希函數,例如: template template template 。 struct std :: hash { size_t operator()(std :: tuple const&tuple)const {...程式設計 發佈於2025-04-30
-
找到最大計數時,如何解決mySQL中的“組函數\”錯誤的“無效使用”?如何在mySQL中使用mySql 檢索最大計數,您可能會遇到一個問題,您可能會在嘗試使用以下命令:理解錯誤正確找到由名稱列分組的值的最大計數,請使用以下修改後的查詢: 計數(*)為c 來自EMP1 按名稱組 c desc訂購 限制1 查詢說明 select語句提取名稱列和每個名稱...程式設計 發佈於2025-04-30
-
如何在Java字符串中有效替換多個子字符串?在java 中有效地替換多個substring,需要在需要替換一個字符串中的多個substring的情況下,很容易求助於重複應用字符串的刺激力量。 However, this can be inefficient for large strings or when working with nu...程式設計 發佈於2025-04-30
-
如何使用Java.net.urlConnection和Multipart/form-data編碼使用其他參數上傳文件?使用http request 上傳文件上傳到http server,同時也提交其他參數,java.net.net.urlconnection and Multipart/form-data Encoding是普遍的。 Here's a breakdown of the process:Mu...程式設計 發佈於2025-04-30
-
如何避免Go語言切片時的內存洩漏?,a [j:] ...雖然通常有效,但如果使用指針,可能會導致內存洩漏。這是因為原始的備份陣列保持完整,這意味著新切片外部指針引用的任何對象仍然可能佔據內存。 copy(a [i:] 對於k,n:= len(a)-j i,len(a); k程式設計 發佈於2025-04-30
-
如何解決由於Android的內容安全策略而拒絕加載腳本... \”錯誤?揭開神秘:content Security Policy Directive errors 遇到Enigmatic錯誤“拒絕加載腳本...此問題源於內容安全策略(CSP)指令,該指令限制了不受信任來源的資源加載。 However, resolving this challenge can be s...程式設計 發佈於2025-04-30
-
如何在GO編譯器中自定義編譯優化?在GO編譯器中自定義編譯優化 GO中的默認編譯過程遵循特定的優化策略。 However, users may need to adjust these optimizations for specific requirements.Optimization Control in Go Compi...程式設計 發佈於2025-04-30
-
Python元類工作原理及類創建與定制python中的metaclasses是什麼? Metaclasses負責在Python中創建類對象。就像類創建實例一樣,元類也創建類。他們提供了對類創建過程的控制層,允許自定義類行為和屬性。 在Python中理解類作為對象的概念,類是描述用於創建新實例或對象的藍圖的對象。這意味著類本身是使用...程式設計 發佈於2025-04-30
-
如何干淨地刪除匿名JavaScript事件處理程序?刪除匿名事件偵聽器將匿名事件偵聽器添加到元素中會提供靈活性和簡單性,但是當要刪除它們時,可以構成挑戰,而無需替換元素本身就可以替換一個問題。 element? element.addeventlistener(event,function(){/在這里工作/},false); 要解決此問題,請考...程式設計 發佈於2025-04-30
-
Java字符串非空且非null的有效檢查方法檢查字符串是否不是null而不是空的 if(str!= null && str.isementy())二手: if(str!= null && str.length()== 0) option 3:trim()。 isement(Isement() trim whitespace whites...程式設計 發佈於2025-04-30
-
解決MySQL錯誤1153:數據包超出'max_allowed_packet'限制mysql錯誤1153:故障排除比“ max_allowed_packet” bytes 更大的數據包,用於面對陰謀mysql錯誤1153,同時導入數據capase doft a Database dust?讓我們深入研究罪魁禍首並探索解決方案以糾正此問題。 理解錯誤此錯誤表明在導入過程中...程式設計 發佈於2025-04-30
-
如何使用Regex在PHP中有效地提取括號內的文本php:在括號內提取文本在處理括號內的文本時,找到最有效的解決方案是必不可少的。一種方法是利用PHP的字符串操作函數,如下所示: 作為替代 $ text ='忽略除此之外的一切(text)'; preg_match('#((。 &&& [Regex使用模式來搜索特...程式設計 發佈於2025-04-30
-
如何使用替換指令在GO MOD中解析模塊路徑差異?在使用GO MOD時,在GO MOD 中克服模塊路徑差異時,可能會遇到衝突,其中可能會遇到一個衝突,其中3派對軟件包將另一個帶有導入套件的path package the Imptioned package the Imptioned package the Imported tocted pac...程式設計 發佈於2025-04-30
-
編譯器報錯“usr/bin/ld: cannot find -l”解決方法錯誤:“ usr/bin/ld:找不到-l “ 此錯誤表明鏈接器在鏈接您的可執行文件時無法找到指定的庫。為了解決此問題,我們將深入研究如何指定庫路徑並將鏈接引導到正確位置的詳細信息。 添加庫搜索路徑的一個可能的原因是,此錯誤是您的makefile中缺少庫搜索路徑。要解決它,您可以在鏈接器命令中添...程式設計 發佈於2025-04-30















學習中文
- 1 走路用中文怎麼說? 走路中文發音,走路中文學習
- 2 坐飛機用中文怎麼說? 坐飞机中文發音,坐飞机中文學習
- 3 坐火車用中文怎麼說? 坐火车中文發音,坐火车中文學習
- 4 坐車用中文怎麼說? 坐车中文發音,坐车中文學習
- 5 開車用中文怎麼說? 开车中文發音,开车中文學習
- 6 游泳用中文怎麼說? 游泳中文發音,游泳中文學習
- 7 騎自行車用中文怎麼說? 骑自行车中文發音,骑自行车中文學習
- 8 你好用中文怎麼說? 你好中文發音,你好中文學習
- 9 謝謝用中文怎麼說? 谢谢中文發音,谢谢中文學習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









